5月27日,在
RIT ++ 2019音乐节的一部分举行的DevOpsConf 2019会议的大厅中,作为“持续交付”部分的一部分,做了报告“ werf是我们在Kubernetes中用于CI / CD的工具”。 它讨论了
每个人在部署到Kubernetes时面临的
问题和挑战,以及可能不会立即注意到的细微差别。 通过分析可能的解决方案,我们展示了如何在
werf开源工具中实现这一点。
自展会以来,我们的实用程序(以前称为dapp)已经克服了
GitHub上1000星的历史限制-我们希望其用户群体的不断增长将简化许多DevOps工程师的生活。

因此,我们为
视频提供了报告 (约47分钟,比文章多得多),并以文本形式提供了其主要摘录。 走吧
Kubernetes中的代码交付
讨论将不再是关于werf的话题,而是关于Kubernetes中的CI / CD的话题,这意味着我们的软件包装在Docker容器中
(我在2016年报告中谈到过) ,而K8将用于在生产中启动它
(关于此) -在2017年 ) 。
Kubernetes交付是什么样的?
- 有一个Git存储库,其中包含构建它的代码和说明。 该应用程序被编译成一个Docker映像并发布到Docker Registry。
- 在同一存储库中,有关于如何部署和运行应用程序的说明。 在部署阶段,这些指令将发送到Kubernetes,后者从注册表接收所需的映像并启动它。
- 另外,通常会有测试。 发布图像时可以执行其中一些操作。 您也可以(按照相同的说明)(在单独的K8s名称空间或单独的群集中)部署应用程序的副本并在其中运行测试。
- 最后,我们需要一个CI系统,该系统从Git接收事件(或单击按钮)并调用所有指示的阶段:构建,发布,部署,测试。

这里有一些重要的注意事项:
- 由于我们拥有不变的基础架构,因此在所有阶段(阶段,生产等)使用的应用程序映像必须是一个 。 我在这里更多地谈论了这一点和例子。
- 由于我们遵循基础架构即代码(IaC)的方法 ,因此构建和运行基础架构的应用程序代码和说明应位于一个存储库中 。 有关更多信息,请参见同一报告 。
- 我们通常会看到这样的交付链(交付) :应用程序已组装,测试,发布(发布阶段) ,仅此而已-交付已经发生。 但是实际上,用户会收到您发布的内容, 而不是您将其交付到生产中时,而是在他能够去那里并且此产品正常工作时才收到。 因此,我相信交付链仅在操作阶段 (运行)结束 ,更确切地说,甚至是在代码从生产中删除(用新代码替换)的那一刻才结束。
让我们回到上面概述的Kubernetes交付方案:它不仅是我们发明的,而且实际上是每个处理此问题的人发明的。 本质上,这种模式现在称为GitOps
(有关该术语及其背后的思想的更多信息,请参见此处 ) 。 让我们看一下方案的各个阶段。
建立阶段
似乎在2019年,当每个人都知道如何编写Dockerfile和运行docker
docker build ?时,您就可以讲述Docker映像的组装了。以下是我要注意的细微差别:
- 图像的重量很重要,因此请使用多阶段操作 ,仅保留图像真正需要的应用程序。
- 应通过组合含义内的
RUN命令链来最大程度地减少层数 。 - 但是,这增加了调试问题,因为当程序集崩溃时,您必须从引起问题的链中找到必要的命令。
- 构建速度很重要,因为我们希望快速推出更改并查看结果。 例如,我不想在每个应用程序构建时都重新组合语言库中的依赖项。
- 通常,从一个Git存储库中需要很多映像 ,这可以通过一组Dockerfile(或一个文件中的命名阶段)和带有顺序装配的Bash脚本来解决。
这只是每个人都面临的冰山一角。 但是还有其他问题,尤其是:
- 通常,在组装阶段,我们需要挂载一些内容(例如,将诸如apt这样的命令的结果缓存到第三方目录中)。
- 我们想要Ansible,而不是在shell上编写。
- 我们想在没有Docker的情况下进行构建 (为什么我们已经需要一个额外的虚拟机,而当您已经有一个可以运行容器的Kubernetes集群时,您需要在其中配置所有内容吗?)
- 并行汇编 ,可以用不同的方式理解:来自Dockerfile的不同命令(如果使用了多阶段),一个存储库的几次提交,多个Dockerfile。
- 分布式程序集 :我们想在“临时”的Pod中收集一些东西,因为 它们的缓存消失了,这意味着它需要单独存储在某个地方。
- 最后,我将欲望称为自动魔术的巅峰之作:理想的是前往存储库,组建一些团队并获得现成的图像,并了解如何正确做事。 但是,我个人不确定是否可以通过这种方式预见所有细微差别。
这是项目:
...并查看他们在GitHub上有多少颗星。 也就是说,一方面,
docker build是并且可以做些事情,但是实际上,这个
问题尚未完全解决 -替代构建器的并行开发证明了这一点,每个构建器都解决了一些问题。
在werf中构建
因此,我们开始使用
werf (以前称为 dapp)-Flant的开源实用程序,我们已经做了很多年了。 这一切都始于大约5年前的Bash脚本,这些脚本优化了Dockerfile的组装,最近3年,在一个拥有自己的Git存储库的项目
(首先在Ruby中,然后重写为Go,同时又重命名)的框架内进行了全面开发。 werf解决了哪些构建问题?

蓝色阴影的问题已经实现,并行组装已在同一主机中完成,我们计划在夏季结束前完成黄色问题。
注册表中的发布阶段(发布)
我们输入了
docker push ...-将映像上传到注册表可能有什么困难? 然后出现一个问题:“要放置图像的标签是什么?” 之所以出现这种情况,是因为我们拥有
Gitflow (或其他Git战略)和Kubernetes,并且业界致力于确保Kubernetes中发生的事情紧随Git中所做的事情。 Git是我们唯一的真理来源。
有什么复杂的?
确保可重现性 :从Git的提交(本质上是
不可变的 )到必须保持相同的Docker映像。
对我们而言,
确定来源也很重要,因为我们想了解在Kubernetes中启动的应用程序是从哪个提交构建的(然后我们可以进行diff和类似的事情)。
标记策略
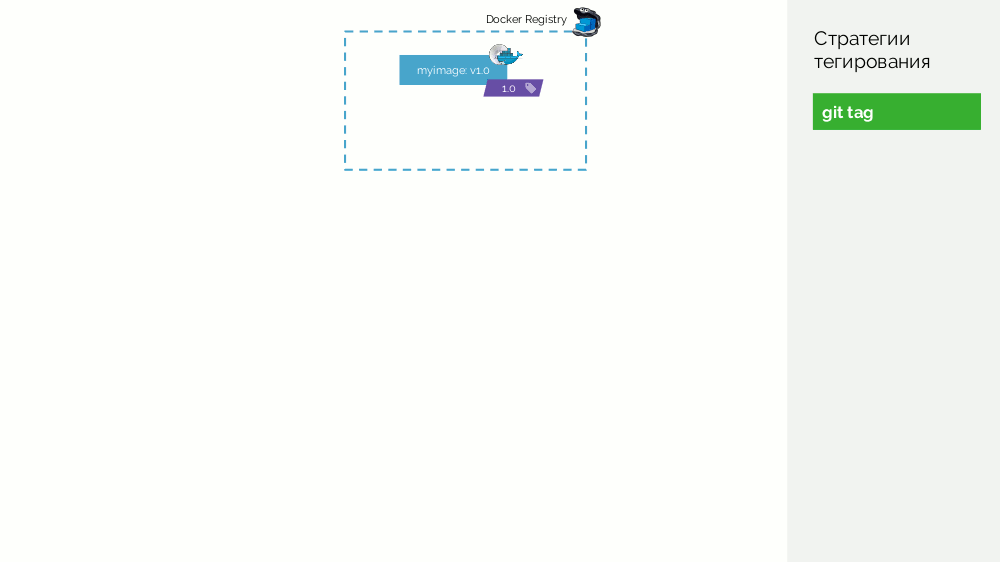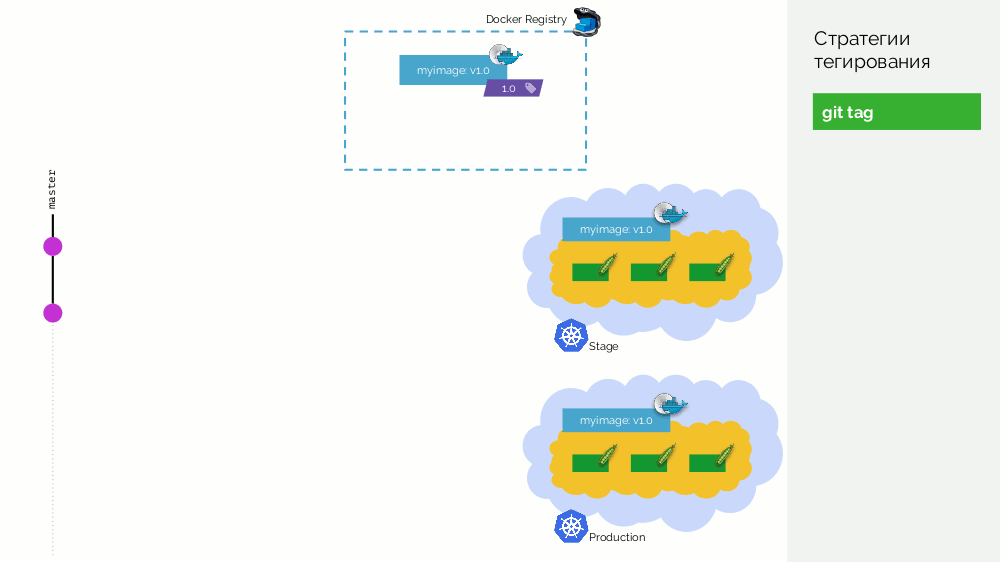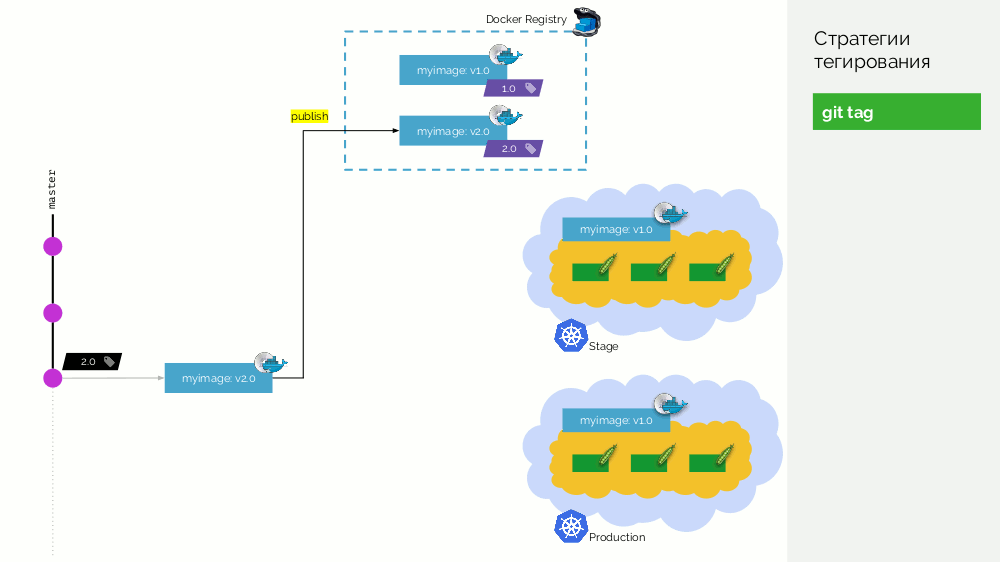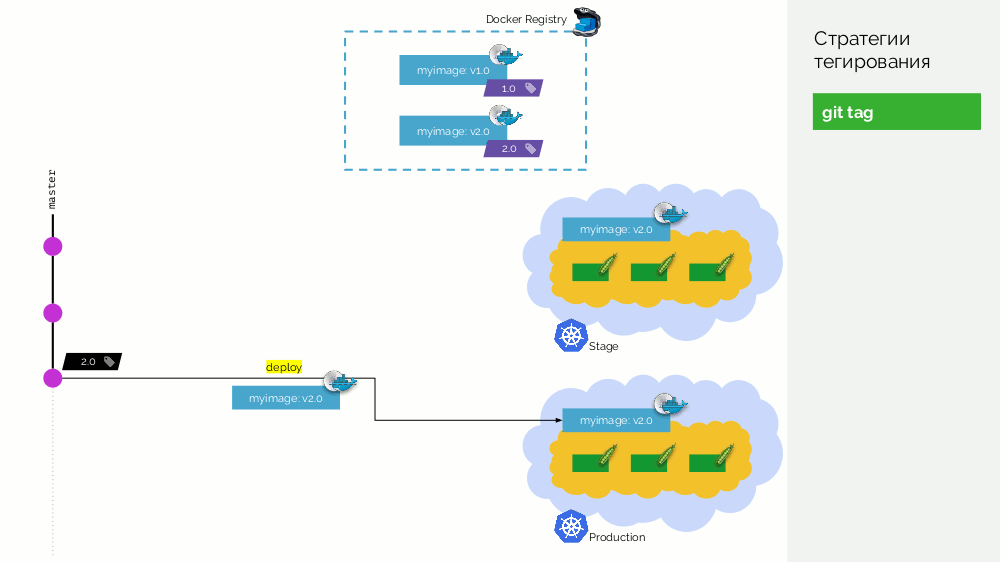
第一个是简单的
git标签 。 我们有一个注册表,其图像标记为
1.0 。 Kubernetes拥有舞台和产品,在此图像被泵入。 在Git中,我们进行提交,并在某个时刻放置标签
2.0 。 我们根据存储库中的说明收集它,并使用
2.0标记将其放入注册表中。 我们会在舞台上推出该产品,如果一切顺利,则将其投入生产。
这种方法的问题在于,我们首先设置了标签,然后才对其进行测试并将其推出。 怎么了 首先,这完全是不合逻辑的:我们提供了一个甚至没有经过测试的软件版本(我们不能这样做,因为要进行检查,您需要放置一个标签)。 其次,这种方式与Gitflow不兼容。
第二个选项是
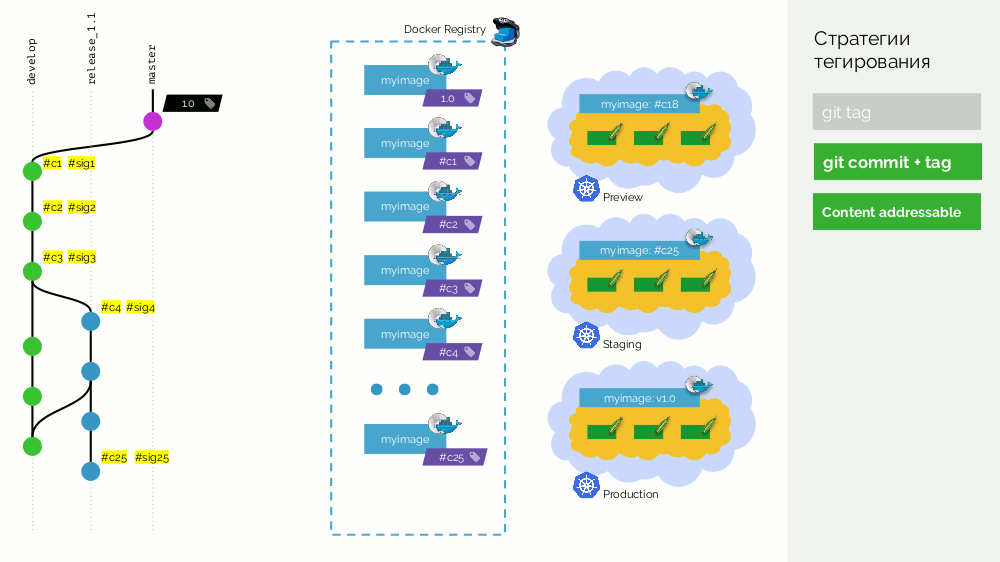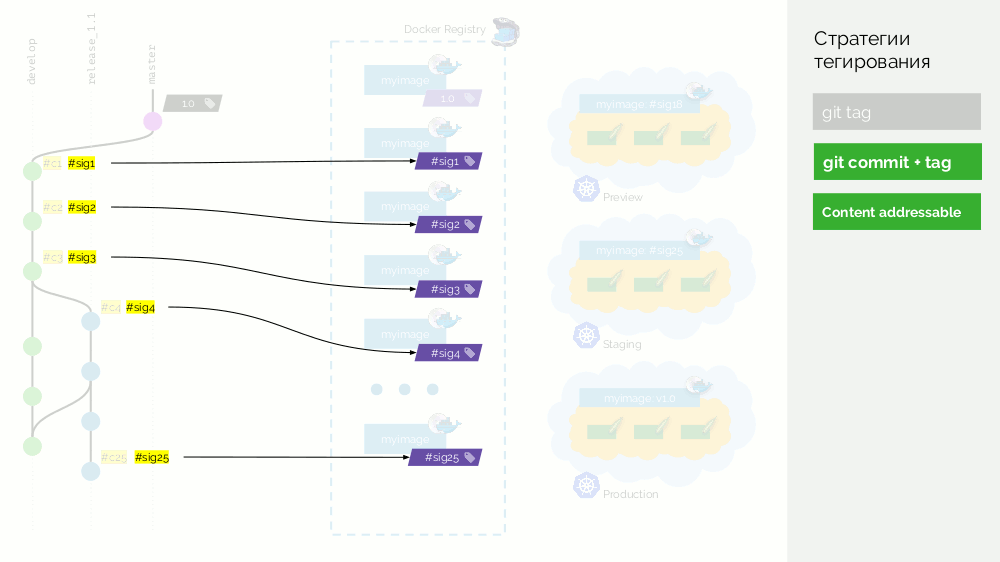
git commit + tag 。 master分支中有一个
1.0标记; 在注册表中为他-部署到生产中的映像。 此外,Kubernetes集群具有预览和登台循环。 此外,我们遵循Gitflow:在开发的主要分支中,我们
develop新功能,因此,存在具有标识符
#c1的提交。 我们收集它并使用此标识符(
#c1 )将其发布在注册表中。 我们推出具有相同标识符的预览。 我们对提交
#c2和
#c3 。
当我们意识到有足够的功能时,我们便开始稳定一切。 在Git中,创建
release_1.1分支(基于
develop #c3 )。 不需要收集此版本,因为 这是在上一步中完成的。 因此,我们可以将其推广到分期。 我们修复了
#c4错误,并类似地在分阶段推出。 同时,development正在
develop ,该版本会定期对
release_1.1进行更改。 在某个时候,我们得到了承诺并被抽出到暂存承诺,我们对此很满意(
#c25 )。
然后,我们在master中对release分支(
release_1.1 )进行合并(使用快进)。 我们在该提交上放置了带有新版本(
1.1 )的标签。 但是此映像已经在注册表中进行了组装,因此为了不再次收集它,我们仅向现有映像添加了第二个标签(现在它在注册表中具有标签
#c25和
1.1 )。 之后,我们将其投入生产。
有一个缺点是,一个映像(
#c25 )在登台时上
#c25 ,而另一个映像(
1.1 )在生产时上
#c25 ,但是我们知道,从物理
#c25 ,它是注册表中的同一映像。
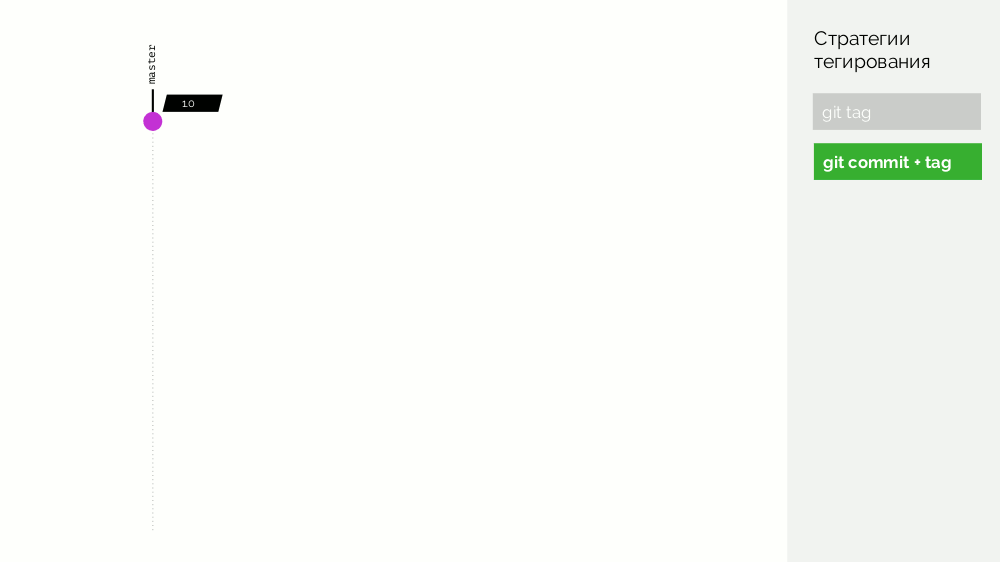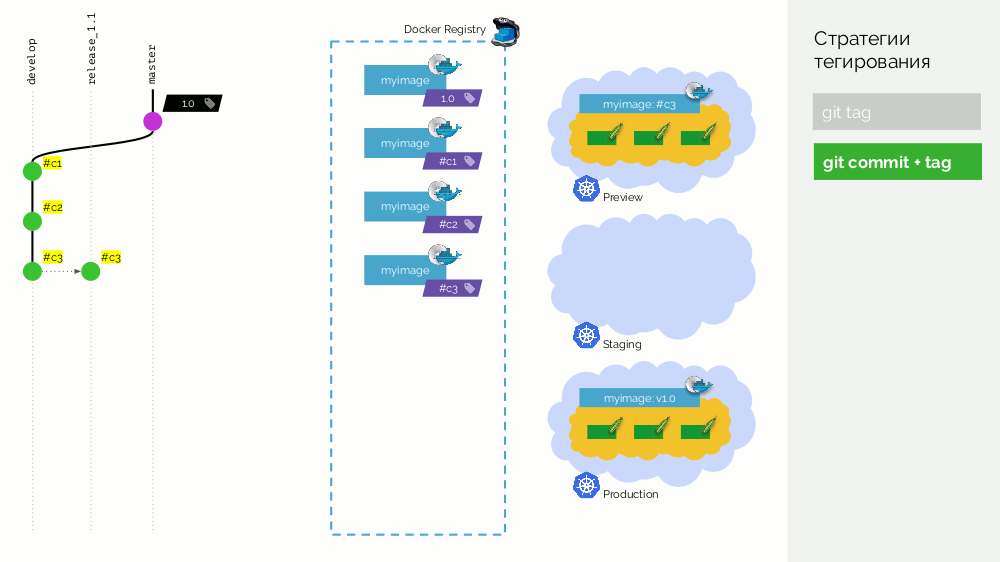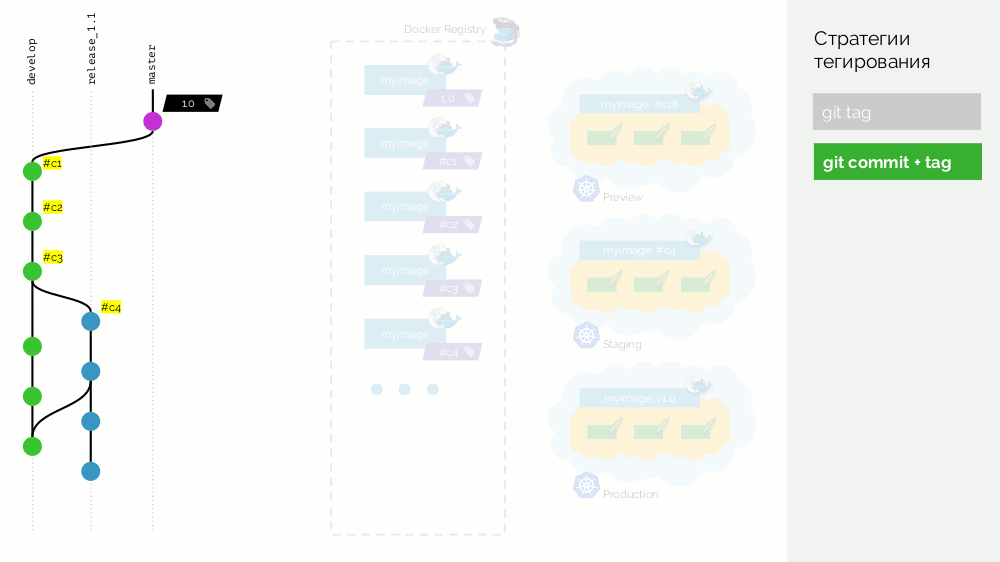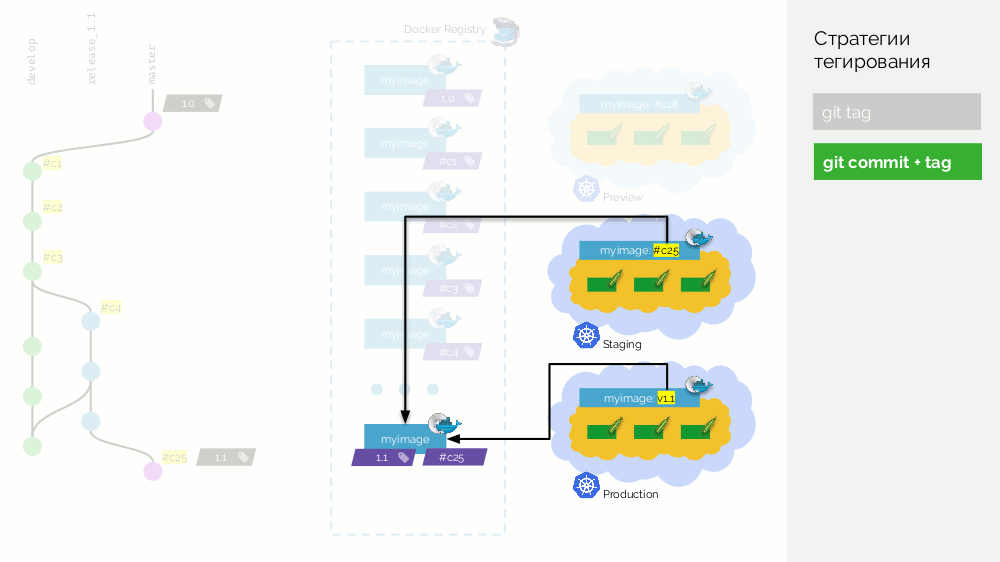
真正的缺点是不支持merge commit'ov,您需要进行快速转发。
您可以继续做下去,以技巧解决...考虑一个简单的Dockerfile的示例:
FROM ruby:2.3 as assets RUN mkdir -p /app WORKDIR /app COPY . ./ RUN gem install bundler && bundle install RUN bundle exec rake assets:precompile CMD bundle exec puma -C config/puma.rb FROM nginx:alpine COPY --from=assets /app/public /usr/share/nginx/www/public
我们根据此原则从中构建文件,我们采取以下措施:
- 来自使用过的图像(
ruby:2.3和nginx:alpine )的标识符的SHA256,它们是其内容的校验和; - 所有团队(
RUN , CMD等); - 已添加文件中的SHA256。
...并从这样的文件中获取校验和(再次为SHA256)。 这是定义Docker映像内容的所有内容的
签名 。

让我们回到该方案,
我们将使用此类签名而不是提交 ,即 用签名标记图像。
现在,例如,当您需要合并从发行版到母版的更改时,我们可以进行真正的合并提交:它将具有不同的标识符,但具有相同的签名。 使用相同的标识符,我们还将在生产中推出该图像。
缺点是现在无法确定已将哪种提交提交到生产中-校验和仅在一个方向上起作用。 这个问题可以通过带有元数据的附加层来解决-我将在以后再介绍。
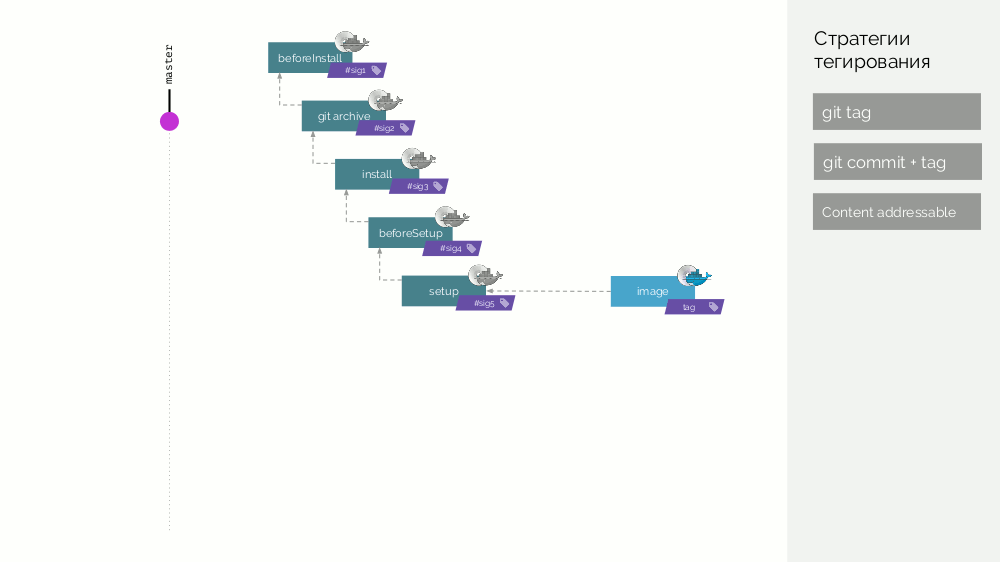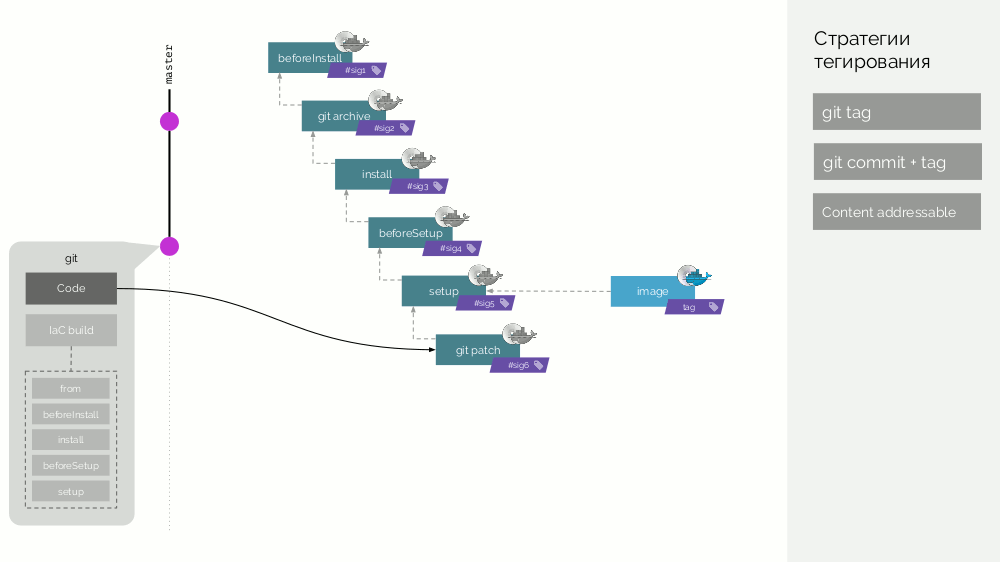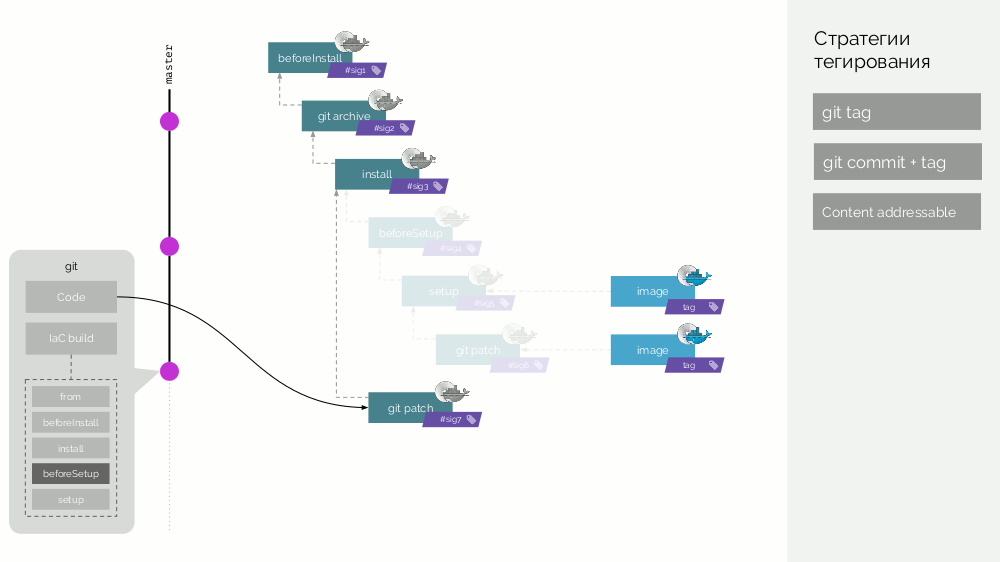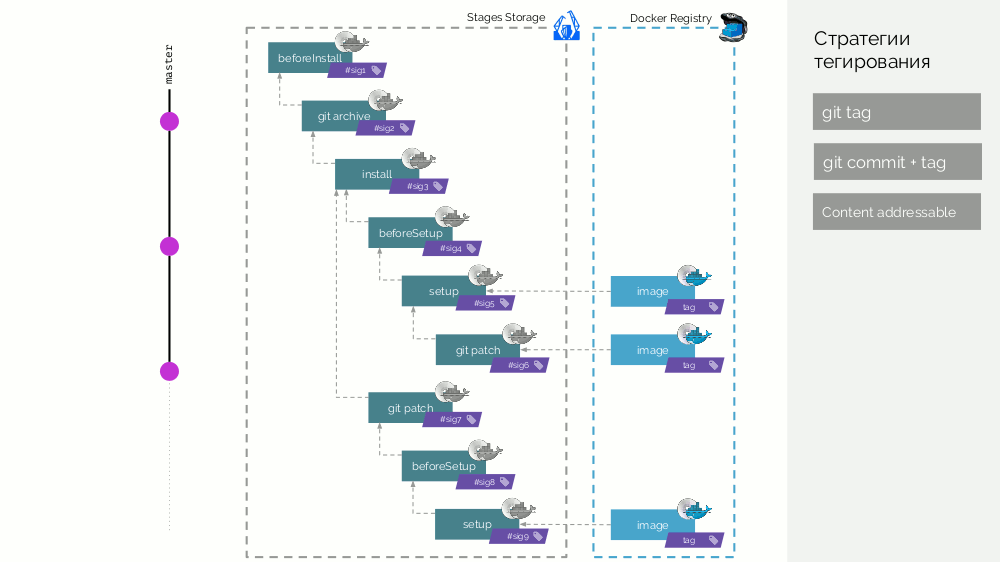
在werf中标记
在werf中,我们甚至走得更远,并准备使用不存储在同一台计算机上的缓存制作分布式程序集。因此,我们有两种类型的Docker映像,我们将它们称为
stage和
image 。
werf Git存储库存储了特定的构建指令,这些指令描述了构建的不同阶段(
beforeInstall ,
install ,
beforeSetup ,
setup )。 我们收集具有签名定义为第一步校验和的第一阶段图像。 然后,我们添加源代码,对于新的阶段映像,我们考虑其校验和...对所有阶段都重复这些操作,结果得到了一组阶段映像。 然后,使最终图像也包含有关其来源的元数据。 并且我们以不同的方式标记该图像(稍后会有详细说明)。

之后,出现一个新的提交,其中仅更改了应用程序代码。 会发生什么? 将创建一个补丁来更改代码,并准备一个新的舞台映像。 它的签名将定义为旧舞台图像和新补丁的校验和。 从该图像将形成新的最终图像。 其他阶段的更改也会发生类似的行为。
因此,阶段映像是可以分布式分布的缓存,并且已经从该映像创建的映像图像被加载到Docker Registry中。
注册表清理
这与删除标签后仍然挂起的图层无关,这是Docker Registry本身的标准功能。 在这种情况下,许多Docker标签都在堆积,我们知道我们不再需要其中的一些标签,它们占用了空间(并且/或者我们为此付费)。
有哪些清洁策略?
- 你什么都不干净 。 有时候,花一点钱购买额外的空间比解开一个巨大的标签球要容易得多。 但这仅在一定程度上起作用。
- 完全重置 。 如果删除所有映像并仅重建CI系统中的相关映像,则可能会出现问题。 如果容器在生产中重新启动,则将为其加载新映像-尚未经过任何人测试的映像。 这扼杀了不变基础设施的想法。
- 蓝绿色 。 一个注册表开始溢出-将图像加载到另一个中。 与以前的方法相同的问题:在什么时候可以清除开始溢出的注册表?
- 按时间 。 删除所有1个月以上的图片? 但是肯定有一个月没有更新过的服务...
- 手动确定可以删除的内容。
实际可行的选择有两种:请勿清洁或手动组合蓝绿色+。 在后一种情况下,我们讨论的是以下内容:当您了解该清理注册表的时候了,请创建一个新注册表并向其中添加所有新映像(例如,一个月)。 一个月后,查看Kubernetes中的哪些Pod仍在使用旧注册表,并将它们也转移到新注册表中。
我们
去哪里了? 我们收集:
- Git头:所有标签,所有分支,-假设需要在Git中测试的所有内容都在图像中(如果没有,则需要在Git本身中删除);
- 现在在Kubernetes中下载的所有Pod;
- 旧的ReplicaSets(最近被淘汰的东西),以及我们计划扫描Helm版本并在那里选择最新的图像。
...,然后从该集合中添加白名单-我们将不会删除的图像列表。 我们清理其他所有内容,然后找到孤立的舞台图像并删除它们。
部署阶段(部署)
健壮的声明性
在部署中,我要引起注意的第一点是推出声明式声明的更新的资源配置。 描述Kubernetes资源的原始YAML文档总是与实际在集群中工作的结果有很大不同。 由于Kubernetes添加了配置:
- 标识符
- 服务信息;
- 许多默认值;
- 具有当前状态的部分;
- 作为入学网钩的一部分进行的更改;
- 各种控制器(和调度程序)工作的结果。
因此,当出现新的资源配置(
new )时,我们不能仅仅采用并覆盖当前的“实时”配置(
live )。 为此,我们必须将
new与上一次应用(
最后应用 )的配置进行比较,并将生成的补丁滚动到
live上 。
这种方法称为
2路合并 。 例如,在Helm中使用它。
还有一个
三向合并 ,其不同之处在于:
- 比较上次使用的和新的 ,我们看一下已删除的内容;
- 比较new和live ,我们看到已添加或更改的内容;
- 应用总结补丁住 。
我们使用Helm部署了1000多个应用程序,因此实际上是2向合并。 但是,他有许多问题已通过我们的补丁解决,这些补丁可以帮助Helm正常工作。
实际推出状态
在下一个事件之后,我们的CI系统为Kubernetes生成了一个新配置,它使用Helm或
kubectl apply其发送到集群。 接下来,发生已经描述的N路合并,Kubernetes API批准CI系统,后者对用户进行响应。

但是,存在一个巨大的问题:毕竟,
成功的应用程序并不意味着成功的推出 。 如果Kubernetes知道要应用哪些更改,请应用它-我们仍然不知道结果如何。 例如,在前端更新和重新启动Pod可能会成功,但在后端却无法成功,并且我们将获得不同版本的正在运行的应用程序映像。
为了正确执行所有操作,此方案中会出现一个附加链接-一个特殊的跟踪器,它将从Kubernetes API接收状态信息并将其传输以进一步分析事物的真实状态。 我们在Go上创建了一个开源库
-kubedog (请参阅此处的公告) ,该库可以解决此问题并将其内置到werf中。
此跟踪器在werf级别上的行为是使用部署或StatefulSet上的注释配置的。 主要注释
fail-mode理解以下含义:
IgnoreAndContinueDeployProcess忽略此组件的IgnoreAndContinueDeployProcess问题并继续部署;FailWholeDeployProcessImmediately此组件中的错误停止了部署过程;HopeUntilEndOfDeployProcess我们希望该组件在部署结束之前可以正常工作。
例如,资源和
fail-mode注释值的组合:

首次部署时,数据库(MongoDB)可能尚未准备好-部署将崩溃。 但是您可以等到它开始的那一刻,部署仍然会通过。
werf中还有kubedog的两个附加注释:
failures-allowed-per-replica每个副本允许的丢弃数;show-logs-until until-调整直到werf显示(从标准输出)所有正在部署的Pod中的日志的时间。 默认情况下,这是PodIsReady (忽略流量开始到达Pod时我们几乎不需要的消息),但是,值ControllerIsReady和EndOfDeploy也EndOfDeploy 。
我们还需要从部署中得到什么?
除了已经描述的两点,我们还要:
- 查看日志 -仅是必需的,而不是全部;
- 跟踪进度 ,因为如果一项工作“默默地”暂停了几分钟,那么了解那里发生的事情很重要;
- 具有自动回滚功能 ,以防万一出现问题(因此了解部署的实际状态至关重要)。 部署必须是原子的:要么结束,要么一切恢复到先前的状态。
总结
作为一家公司,对于我们来说,要在交付的不同阶段(构建,发布,部署)实施所有描述的细微差别,CI系统和
werf实用程序就
足够了 。
而不是结论:

在werf的帮助下,我们在解决DevOps工程师的大量问题方面取得了良好的进展,如果更广泛的社区至少尝试使用该实用程序,我们将感到高兴。 一起获得良好的结果将更加容易。
影片和幻灯片
表演视频(〜47分钟):
报告介绍:
聚苯乙烯
我们博客上的其他Kubernetes报告: