在学校里,我有一个同班同学,他可以听听汽车在院子里的工作情况,并严肃地面对一个结论:一切都井井有条,或者东西坏了,我迫切需要准备新的零件/机油/工具! 我就像汽车行业中的绝对茶壶一样,总是听到下一次dvenashka发出的通常的嘎嘎声,没有注意到任何差异,只是默默地惊叹于他的听力和技能。
现在,我不太了解汽车的内部,但是我开始处理声音信号和机器学习,在这里我们将尝试了解是否可以教一台计算机来捕捉发动机声音的异常?
至少,这很有意思,而且将来这种技术可以为车主节省很多钱。 至少在我看来,严重的故障是在引擎盖下逐渐发生的,并且在早期阶段,许多故障可以被听到,迅速而廉价地修复,从而节省了时间,金钱和已经动摇的神经。
好吧,也许是时候从言传身教。 走吧
我想马上说,在涉及数学和算法的所有内容中,我将更加强调含义和理解,这里不会有公式和数学计算。 我在这里没有开发任何新算法;对于公式,如果您愿意,最好使用google和Wikipedia,并使用我将在整篇文章中保留的链接。
我将以YouTube上的这段视频为例,说明所有引擎损坏的声音。
从YouTube下载的文件(您可以使用浏览器扩展程序下载文件,也可以通过将youtube链接更改为ssyoutube进行下载),我们使用ffmpeg转换为wav格式:
ffmpeg -i input_video.mp4 -c:a pcm_s16le -ar 16000 -ac 1 engine_sound.wav
在开始处理此文件之前,我先说说什么是声谱图,以及它对我们如何解决此问题有帮助。 可以肯定的是,你们中的许多人都看过类似的图片-这是声音或波形的幅度时间表示。
简单来说,声音就是一个波,并且在给定的时间在波形图上观察到该波的振幅值。
为了从这种表示中获得频谱图,我们需要进行傅立叶变换。 借助它的帮助,您可以获取声音的振幅频率表示或振幅频谱。 这样的频谱显示了所研究信号的频率和幅度。
实际上,频谱图是一组短的连续信号频谱的集合。 也许这样的“定义”足以使我们不被任务分心。 如果您查看频谱图的可视化,一切都会变得更加清晰(图片是使用WaveAssistant获得的)。 时间在X轴上绘制,频率在Y轴上绘制,也就是说,此矩阵中的每一列都是给定时间点的频谱模量。
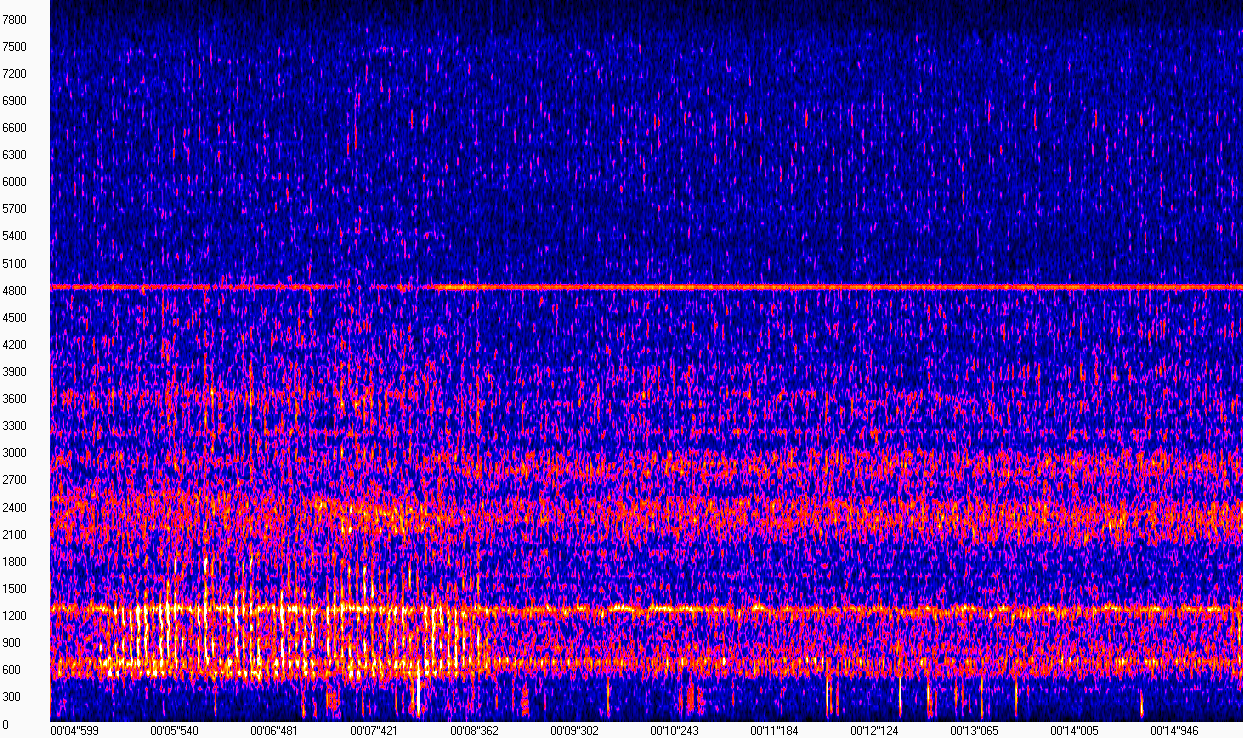
该频谱图表明,在没有轻拍的情况下,发动机的声音“看起来”差不多,并且以600、1200、2400和4800 Hz附近的频率表示。 在600至1200 Hz的频率范围(从5到8秒)内,困扰所有者的敲打声非常不同。 由于录制是在街道上比较嘈杂的条件下进行的,因此这些噪声也会出现在频谱图上,这使我们的工作变得有些复杂。
不过,看看这样一个频谱图,我们可以自信地说出敲门在哪里,而敲门不在哪里。 计算机没有眼睛,因此,我们需要选择一种算法,该算法将能够区分这种偏差(最好不仅是偏差),而且要取决于记录中是否存在噪声。
可以使用librosa库计算频谱图,如下所示:
from librosa.util import buf_to_float from librosa.core import stft
解决方案
严格来说,我们需要解决二进制分类问题,需要确定发动机是否损坏或运转正常。 我和我的同事已经在上一篇文章中描述了类似的任务,其中我们使用了卷积神经网络对声音事件进行分类。 在这里,这样的解决方案几乎是不可能的:当给神经元提供大型数据集时,他们非常喜欢它们。 我们正在处理一个持续一分钟多一点的缩进,这显然不能称为大型数据集。
选择在高斯混合模型(高斯混合物模型)上停止。 可以在此处找到详细介绍此模型的工作原理和训练原理的好文章。该模型的总体思路是使用复杂分布来描述数据,该分布以若干多维正态分布的线性组合形式存在( 此处更多关于多维正态分布)。
由于发动机在其运行期间听起来大致“相同”,因此可以将其运行声音视为固定的,使用这种分布描述这种声音的想法似乎很有意义。 为了了解GMM的本质,我强烈建议您在此处查看训练示例并选择高斯数。
我们的情况与上述示例的不同之处在于,将使用从信号频谱图中获取的频谱值代替二维平面上的点。 您可以使用BIC标准( 例如 , description )选择分布参数,例如协方差矩阵的类型,但是,在我的情况下,从该标准的角度来看,最优参数显示的性能比下面代码中显示的要差:
from sklearn.mixture import GaussianMixture n_components = 3 gmm_clf = GaussianMixture(n_components) gmm_clf.fit(X_train)
假设正常运行的声音由分布描述,在训练过程中选择了参数,则可以测量任何声音与该分布的接近程度。
为此,您可以计算所研究信号的频谱图各列的平均可能性,然后选择一个阈值,以将良好工作声音的可能性与所有其他声音分开。 每秒的可信度如下:
n_seconds = len(full_wav_data) // sr gmm_scores = []
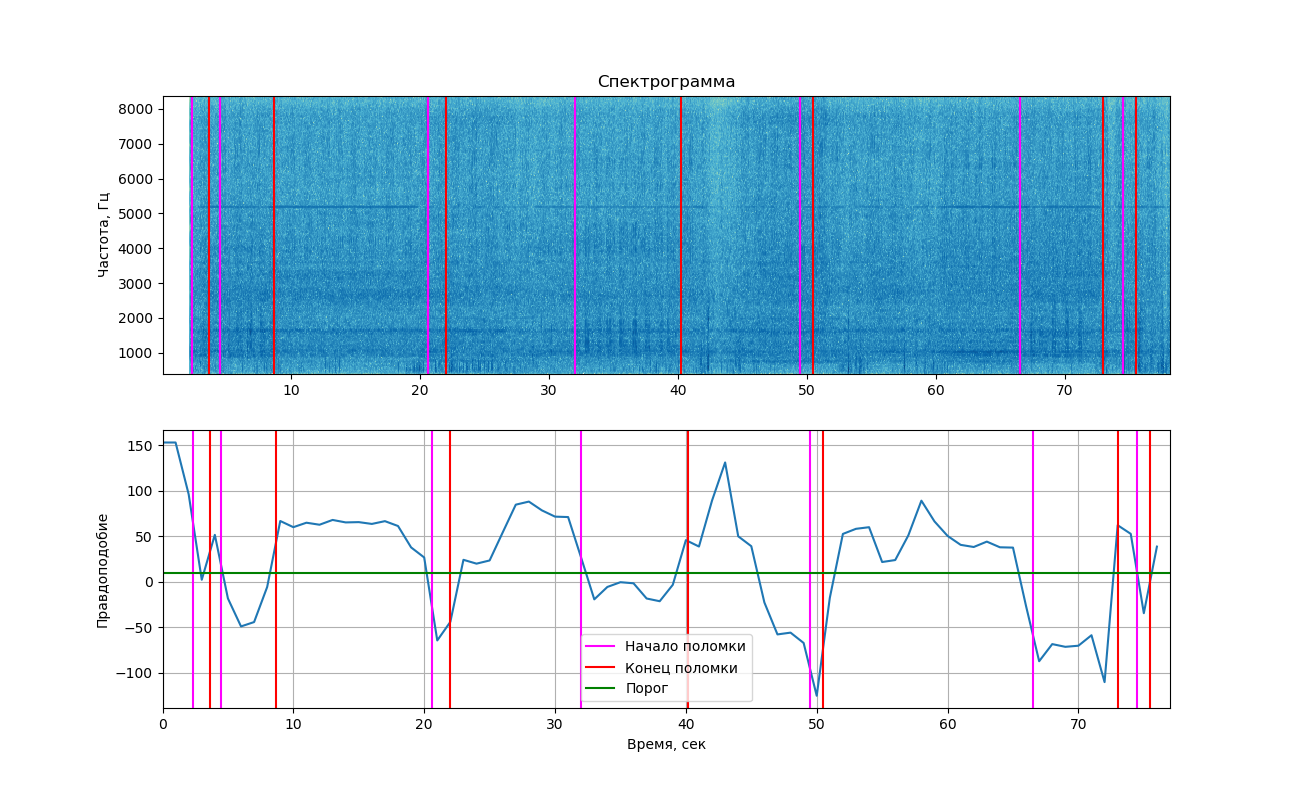
如果您在图表上显示获得的可能性,我们将得到以下图片。
上部显示了使用matplotlib库显示的信号的频谱图。 与上面的示例不同,敲敲引起的变化并不明显(这就是为什么在这里看到2张图像的原因)。 但是,如果您仔细观察,仍然可以看到它们。 垂直线标记了敲打的开始和结束时间。
结论
从图中可以看出,在敲门声时,可能性确实降到了阈值以下,这意味着我们可以将这两个类别分开(有或没有敲门)。 但是我必须说,该值足够接近阈值,并且在没有听到爆震的区域中也是如此。 这是因为在录音中经常会发现外部噪音,这也会影响可能性。
我们在这里添加了仅几秒钟的声音,糟糕的录音条件的培训,并且您已经对实验以某种方式取得的成功感到惊讶!
为了将这种方法付诸实践,并确保其可靠性,您将不得不录制更多的声音,并妥善放置麦克风,以最大程度地减少进入录音的噪音。
本文仅是尝试解决类似问题,而不是主张绝对正确,如果您有想法和建议,或者有问题,让我们在评论中或亲自讨论它们。
完整的github代码在这里