我们要介绍用于文本标记化的新工具-YouTokenToMe。 在结构上类似于欧洲的语言中,它的工作速度比其他流行版本快7-10倍,在亚洲语言中,它的工作速度是40-50倍。 我们谈论YouTokenToMe并在GitHub上与您共享。 文章末尾的链接!

如今,神经网络算法的大部分任务是文字处理。 但是,由于神经网络可以处理数字,因此在将文本传输到模型之前需要对其进行转换。
我们列出了通常用于此目的的流行解决方案:
- 空格符
- 基于规则的算法:spaCy,NLTK;
- 词根,词根化。
它们每个都有自己的缺点:
- 您无法控制令牌字典的大小。 模型中嵌入层的大小直接取决于此。
- 不使用有关后缀或前缀不同的单词的亲属关系的信息,例如:礼貌-不礼貌;
- 取决于语言。
最近,
字节对编码方法已经流行。 最初,该算法用于文本压缩,但是几年前,它用于在机器翻译中标记文本。 现在,它可用于多种任务,包括BERT和GPT-2模型中使用的任务。
最有效的BPE实现是Google工程师开发的
SentencePiece和Facebook AI Research创建的
fastBPE 。 但是我们设法证明令牌化可以大大加速。 我们优化了BPE算法并发布了源代码,还将完成的软件包发布到了pip存储库中。
您可以在下面比较测量我们的算法和其他版本算法速度的结果。 例如,我们以俄语,英语,日语和中文获取
了Wikipedia数据语料库的前100 MB。
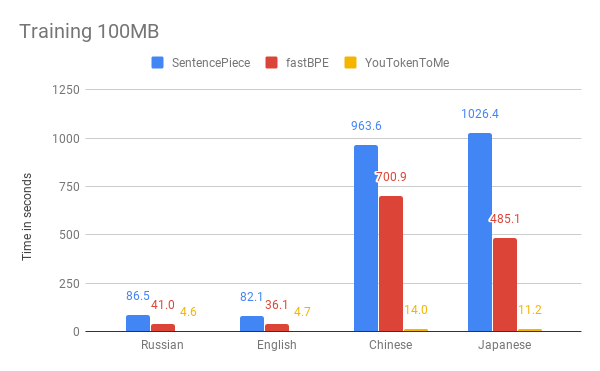

这些图表明,操作时间很大程度上取决于语言。 这是因为亚洲语言具有更多的字母,并且单词之间没有空格。 YouTokenToMe在与欧洲类似的语言中的工作速度提高了7-10倍,在亚洲语言中的工作速度提高了40-50倍。 令牌化至少被加速了两次,在某些测试中被加速了十倍以上。
我们通过以下两个关键思想获得了这些成果:
- 新算法的线性运行时间取决于要训练的案例的大小。 SentencePiece和fastBPE的渐近行为不太有效;
- 新算法可以在学习过程和令牌化过程中有效地使用多个流-这使您获得的加速倍数更高。
您可以通过界面使用YouTokenToMe从命令行直接从Python工作。
您可以在存储库中找到更多信息:
github.com/vkcom/YouTokenToMe