哈Ha
相对而言,相对而言,NVIDIA在2019年
宣布了一款与Raspberry Pi尺寸兼容
的单板计算机 ,专注于AI和资源密集型计算。

待售后,看到它的工作原理以及可以完成的工作变得很有趣。 使用标准基准测试不是很有趣,因此我们将提出自己的基准测试;对于所有测试,源代码均在文本中给出。 对于那些对发生的事情感兴趣的人,继续进行下去。
硬体
首先,NVIDIA网站上的规格:

有趣的是,这里有几点。
第一个是分别具有128个内核的GPU,您可以在板上运行面向GPU的任务,例如CUDA(即装即用的受支持和安装的)或Tensorflow。 主处理器为4核,如下所示,性能很好。 CPU和GPU之间共享4GB内存。
第二个是与Raspberry Pi的兼容性。 该开发板有一个40针连接器,带有各种接口(I2C,SPI等),还有一个摄像头连接器,它也与Raspberry Pi兼容。 可以假定许多现有的附件(屏幕,电机控制板等)都可以使用(您可能必须使用延长电缆,因为Jetson Nano的尺寸仍然不同)。
第三,该板有2个视频输出,千兆以太网和USB 3.0,即 整体而言,Jetson Nano的功能甚至比原型机还要多。 可以通过Micro USB和单独的连接器获取5V电源,建议使用此接口来
挖掘资源密集型任务的
比特币 。 与在Raspberry Pi中一样,该软件是从SD卡加载的,必须首先记录其映像。 通常,从意识形态上讲,该板与Raspberry Pi非常相似,后者显然是在NVIDIA中构思的。 但是板上没有WiFi,只有一个负号,那些想要的人将不得不使用USB-WiFi模块。
如果仔细观察,您会发现该设备在结构上由两个模块组成-Jetson Nano模块本身和带连接器的底板,通过连接器进行连接。

即 该板可断开连接并单独使用,可为嵌入式解决方案提供方便。
说到价格。 在美国,Jetson Nano的原始价格为99美元,在欧洲本地商店加价的价格约为130欧元(如果有折扣,您可能会发现更便宜)。 俄罗斯的纳米成本多少是未知的。
软体类
如上所述,下载和安装与Raspberry Pi并没有太大区别。 我们通过Etcher或Win32DiskImager将
映像加载到SD卡上,进入Linux,放入必要的库。 我
在这里使用了出色的分步指南。 让我们立即进行测试-尝试在Nano上运行不同的程序,并查看它们如何工作。 为了进行比较,我使用了三台计算机-我的工作笔记本电脑(Core I7-6500U 2.5GHz),Raspberry Pi 3B +和Jetson Nano。
CPU测试首先,请输入lscpu命令的屏幕截图。
Raspberry Pi 3B +:
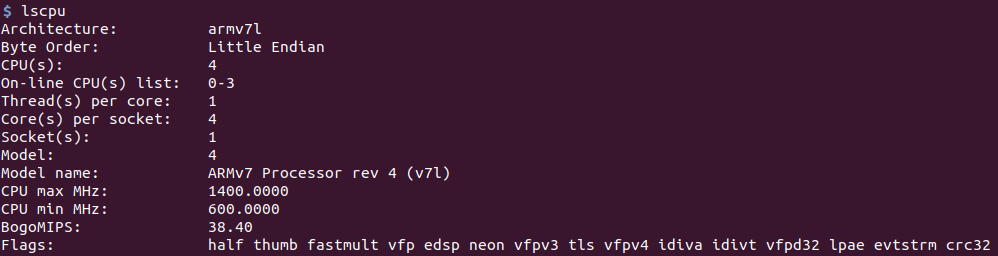
Jetson nano:
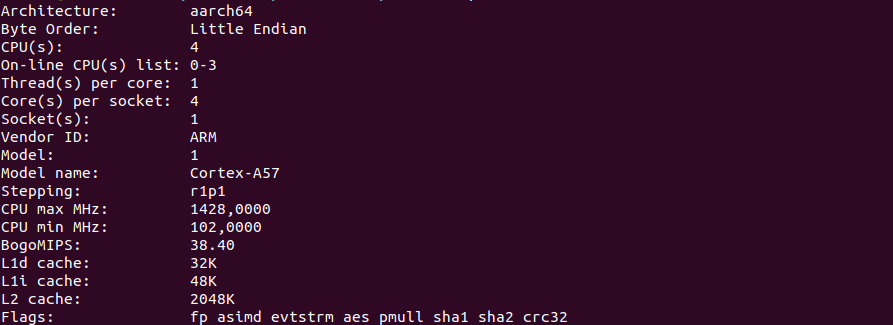
为了进行计算,让我们从简单的事情开始,但是需要处理器时间。 例如,通过计算数字Pi。 我用
stackoverflow编写了一个简单的Python程序。
我不知道它是否是最佳选择,但对我们来说并不重要-我们对
相对时间感兴趣。
如预期的那样,该程序无法快速运行。 Jetson Nano的结果为0.8c。
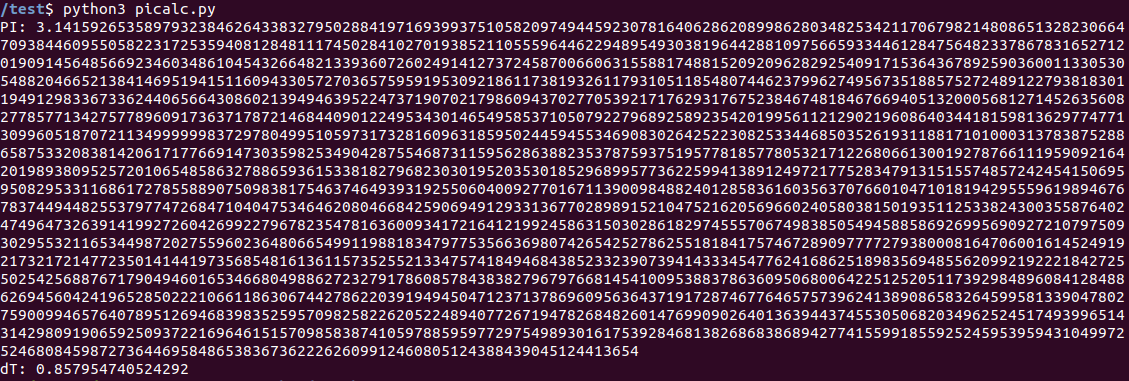
Raspberry Pi 3B +显示了更长的时间:3.06c。 “示例性”笔记本电脑在0.27秒内完成了任务。 通常,即使不使用GPU,Nano中的主处理器在尺寸方面也相当不错。 那些希望可以在Raspberry Pi 4上查看的人,我没有它。
当然,有些人想要在注释中写出Python并不是进行这种计算的最佳选择,我再说一遍,
比较时间对于我们很重要,不需要最小化时间。 显然,有些程序可以更快地计算出Pi数。
毕达让我们继续使用GPU进行更有趣的计算,当然我们将使用CUDA(对于该板(来自NVIDIA))。 PyCUDA库在安装过程中需要一些巫术,它找不到cuda.h,使用命令“ sudo env” PATH = $ PATH“ pip install pycuda”有帮助,也许还有另一种方式(更多选项
在devtalk.nvidia.com论坛上进行了讨论)。
在测试中,我使用了简单的程序
SimpleSpeedTest for PyCUDA,该程序仅计算循环中的罪孽,没有任何用处,但是很有可能对其进行评估,并且其代码简单明了。
如您所见,计算是通过CUDA使用GPU进行的,而通过numpy使用CPU进行的。
结果:
Jetson nano-0.67c GPU,13.3c CPU
Raspberry Pi 3B +-41.85c CPU,GPU-无数据,RPi上的CUDA不起作用。
笔记本电脑-0.05s GPU,3.08c CPU
一切都在意料之中。 GPU上的计算比CPU(仍为128核)上的计算快得多,Raspberry Pi的处理速度明显滞后。 好吧,当然,无论
您喂多少狼,大象仍然拥有比Jetson Nano中的显卡更快
的更大的笔记本电脑图形卡-它中可能包含更多的处理核心。
结论
如您所见,NVIDIA板非常有趣且非常高效。 它比Raspberry Pi更大,更昂贵,但是如果有人需要更紧凑的尺寸的计算能力,那么它是值得的。 当然,这并不总是必要的-例如,要将温度发送给narodmon,Raspberry Pi Zero足够了,并且具有多个边距。 因此,Jetson Nano并不声称要
取代 Raspberry和克隆,但是对于资源密集型任务而言,这非常有趣(它不仅可以是无人机或移动机器人,还可以是例如带有面部识别功能
的门铃摄像头 )。
一方面,设想的一切都不合适。 在第二部分中,将进行AI部分的测试-Keras / Tensorflow的测试以及分类和图像识别的任务。