不久前,我面临着为我们公司切换到新的BI系统的任务。 由于我不得不深入和彻底地研究这个问题,因此我决定与知名社区分享我的想法。

互联网上有很多关于该主题的文章,但是令我惊讶的是,他们没有回答我有关选择正确工具的许多问题,而且有些肤浅。 在测试的3周内,我们测试了4种工具:
Tableau,Looker,Periscope / Sisense,模式分析 。 这些工具将在本文中进行主要讨论。 我必须马上说,建议的文章是作者的个人观点,反映了一家小型但发展迅速的IT公司的需求:)
关于市场的几句话
现在,BI市场正在发生相当有趣的变化,整合正在进行中,大型云技术参与者正试图通过垂直整合数据处理的各个方面(数据存储,处理,可视化)来巩固自己的地位。 在过去的几个月中,进行了5次重大收购:Google收购了Looker,Salesforce收购了Tableau,Sisense收购了Periscope Data,Logi Analytics收购了Zoomdata,Alteryx收购了ClearStory Data。 我们不会进一步深入企业的并购领域,值得注意的是
,BI工具新所有者的定价和保护主义政策都有望进一步改变 (因为Alooma工具最近让我们感到高兴,在Google收购之后不久,他们停止支持除Google BigQuery以外的所有数据源:))。
一点理论
所以,我想从一小部分理论开始,因为现在没有理论。 正如Gartner告诉我们的那样,BI系统是一个结合了软件产品,工具,基础架构和最佳实践的术语,它使我们能够改进和优化决策[1]。 此定义还包括数据存储和ETL。 在本文中,我建议重点关注一个狭窄的领域,即用于数据可视化和分析的软件产品。
在为公司创造价值的金字塔中(我有胆量在图0中提出另一种这种明显结构的表述),BI工具位于存储记录和初步数据处理(ETL)的块之后。
了解这一点很重要-
在这种情况下 ,
最佳实践是将ETL和BI任务分开 。 除了处理数据的过程更加透明之外,您也不会局限于一个软件解决方案,并且可以为每个ETL和BI任务选择最合适的工具。 借助结构良好的ETL流程和最佳的数据表体系结构,您通常可以在不使用特殊软件的情况下解决所有紧迫的业务问题中的80%。 当然,这将需要分析师和DS的大量参与。 因此,我们提出了一个主要问题:BI软件产品首先真正需要什么?
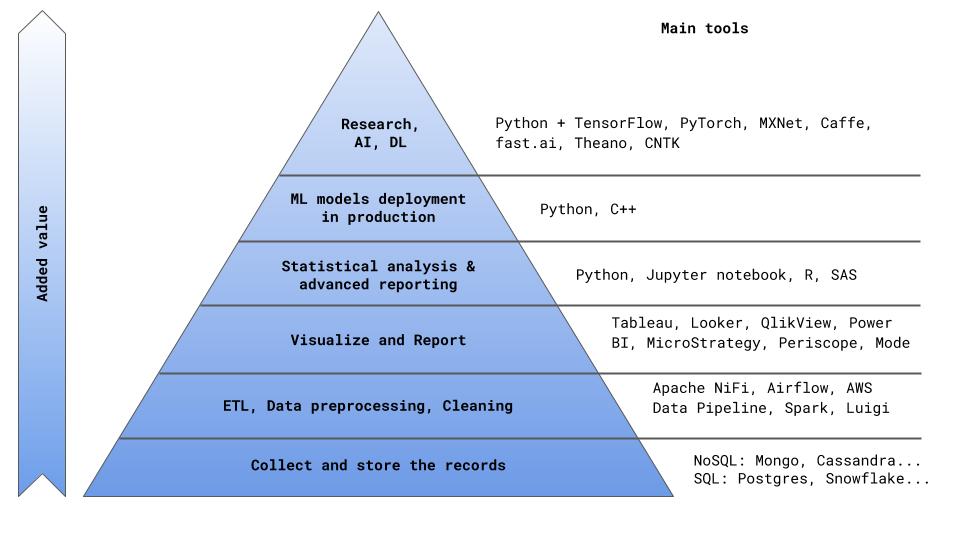
图 0
选择BI软件产品的关键标准
正如我们已经了解的那样,整个公司的所有关键指标和绩效指标都可以直接从以前作为ETL流程一部分准备的数据库中的分析表中获取(我将在下一篇文章中告诉您如何优化构建ETL流程同时,我将简单说明为什么这是如此重要:根据Kaggle的一项民意测验,DS面临的主要困难是肮脏的数据[2]。 显然,在这种情况下,主要问题将是使用分析师时间的复杂性和效率低下。 分析师/ DS不会一直创建成熟的产品,而是会一直准备指标,计算指标,检查数字差异,查找SQL代码中的错误以及执行其他无益的活动。 在这里,我深信分析师/ DS应该做的主要事情是创造一种可以长期为公司带来价值的产品。 这可以是结算/预测性服务,其结果是公司主要产品的一部分(例如,用于计算行程成本/时间的算法),或者可以是用于在客户之间分配订单的算法,也可以是用于确定用户外流原因和MAU减少的完整分析报告。 。
因此,选择分析系统的主要标准应该是
能够从临时性问题和流动性中最大程度地减轻分析师负担。 如何做到这一点? 实际上,有两种选择:a)自动化,b)委托。 在第二段中,我指的是现在流行的短语
自助服务 -使企业有机会深入研究数据本身。
也就是说,分析师一次设置了软件产品:创建数据多维数据集,配置多维数据集的自动更新(例如,每晚),自动发送报告,准备几个仪表板向导并教用户如何使用该产品。 此外,通过使用简单易懂的
拖放选项计算各种数据聚合中的必要指标并进行过滤,该业务可独立满足其额外需求。
除了简化报告过程外,
查询执行速度也很重要 。 没有人会等待上个月的15分钟来加载另一个城市的数据或指标。 为了解决这个问题,有几种普遍接受的方法。 其中之一是
OLAP (在线分析处理)数据多维数据集的创建。 在OLAP多维数据集中,数据类型被划分为维度(维度)-这些是可以进行汇总的字段(例如,城市,国家/地区,产品,时间间隔,付款类型...),并且度量是用于度量的计算度量(例如旅行次数,收入,新用户数量,平均支票等)。 数据多维数据集是一个功能非常强大的工具,可让您使用预聚合的数据和计算的指标非常快速地生成结果。 OLAP多维数据集的另一面是所有数据都已预先收集并且在下一个多维数据集构建之前不会更改的事实。 如果需要数据聚合或最初未计算的度量标准,或者需要更多最新数据,则需要
重新创建数据多维数据集。
提高数据处理速度的另一种解决方案是
内存解决方案 。 内存数据库(IMDB)旨在在有足够的RAM存储数据时提供最佳性能。 关系数据库旨在在数据没有完全放入RAM时提供最佳性能,并且慢速磁盘I / O应该实时执行。 许多现代工具将这两种解决方案结合在一起(例如,Sisense,Tableau,IBM Cognos,MicroStrategy等)。
在此之前,我们谈到了为商业用户使用BI工具的简便性。 为分析师/ DS建立
方便的仪表板开发和发布过程非常重要。 这里的情况与任何其他IT产品类似-您需要快速便捷的部署过程(
快速部署时间 ),以及周到的开发过程,测试,代码审查,发布,版本控制,团队协作。 所有这些都通过工作流的概念结合在一起。
因此,我们得出
了BI软件产品的
关键要求 。 相同的要求构成了速度图的基础,我们最终选择了产品供应商作为基础。
表1. BI工具选择标准。
我们团队内部的最终表决结果表如下:
表2.选择BI工具的投票结果。
对于企业用户(他们也参与了产品的选择),Tableau和Looker的票数大致相等。 结果,选择了Looker。 我们现在将讨论为什么使用Looker以及这些工具之间的根本区别是什么。
详细的工具说明
因此,让我们从BI工具的描述开始。
画面
(这里我们将讨论扩展服务包:Tableau Online)
- UX +拖放。
自2003年以来,Tableau在市场上已经是相当老的工具,并且感觉界面从那时起并没有太大变化。 您可能会害怕Windows XP风格的弹出和下拉选项(图1,图2)。 但是很快您就可以习惯并掌握该工具的基本功能。 Tableau使人想起了许多高级版本的Excel,它具有选项卡(工作表)和仪表板(仪表板)-在工作表上获得的可视化效果的组合。 拖放选项非常易于使用,图形上的过滤器易于配置和更改(图3,图4)。 Tableau有两个版本的服务:桌面版和桌面+联机版。 桌面是老式的-实际上,它是高级Excel。 测试期间的在线版本通常考虑周全,有时会在不保存您的工作的情况下更新页面。
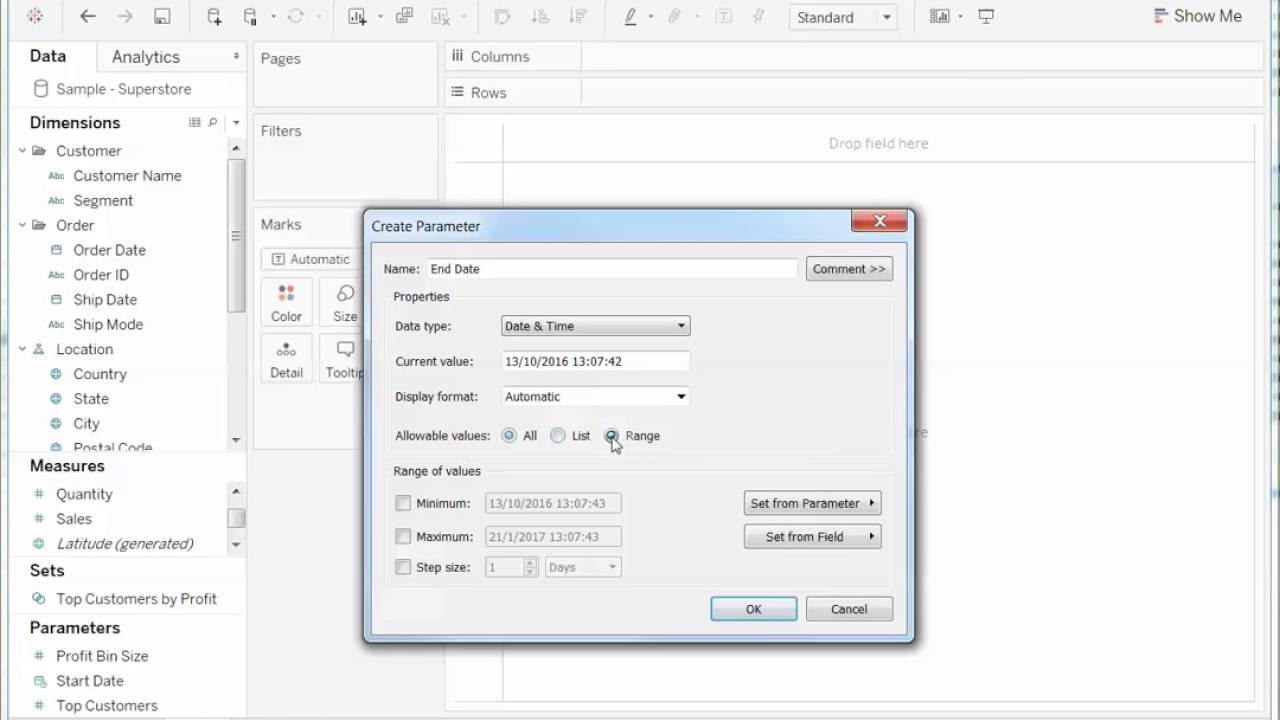
图 1个
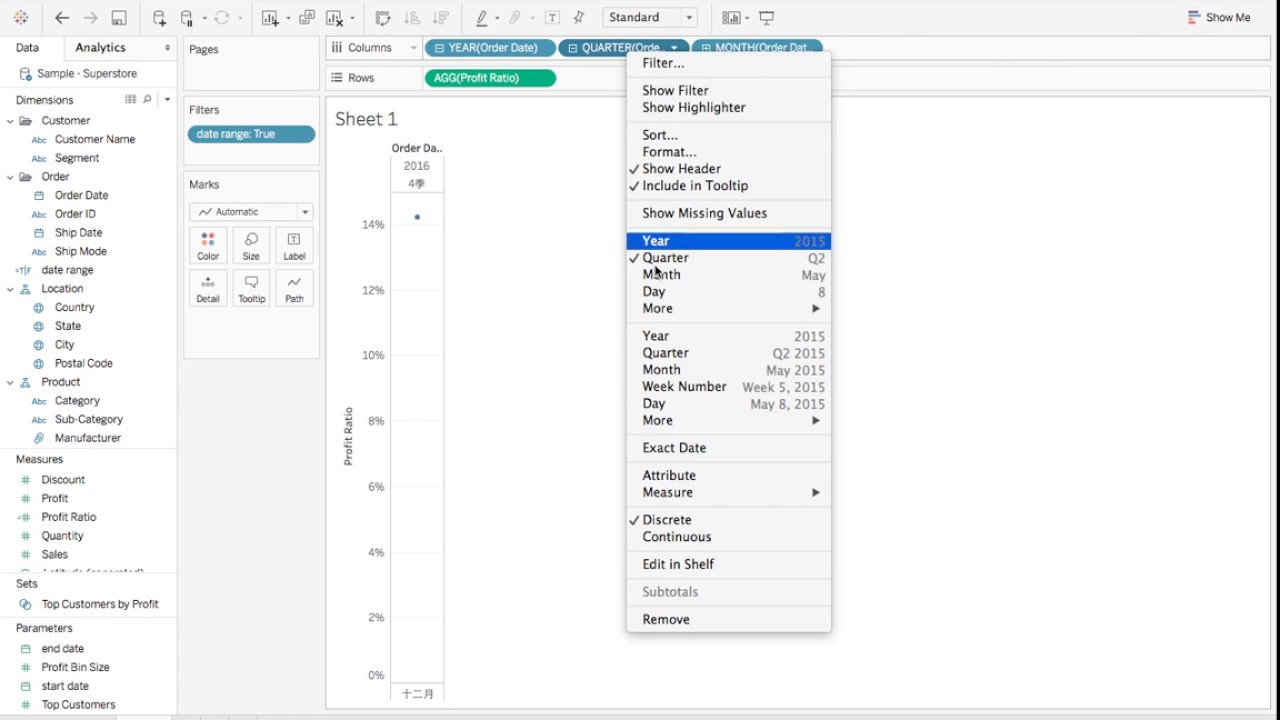
图 2
图 3
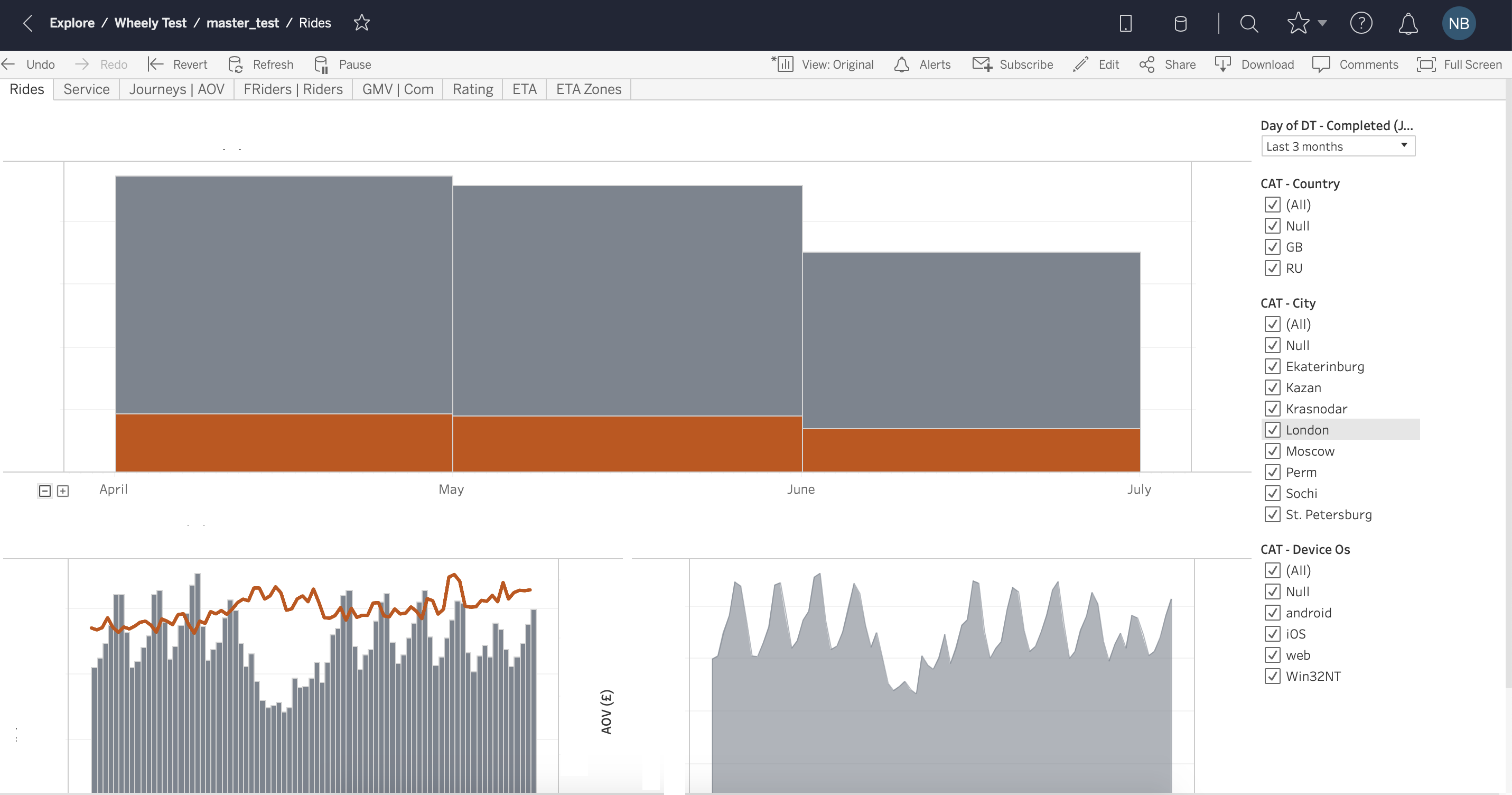
图 4
- 数据处理。
Tableau可以非常快速地处理数据,即使对于大量数据(超过2000万条记录),更改时间过滤器或聚合也只需几秒钟。 正如我们已经说过的,为此,Tableau同时使用了OLAP数据多维数据集和内存数据引擎。 Tableau声称,由于其内部内存解决方案Hyper,查询执行速度提高了5倍 。
可以在本地版本的Tableau Desktop上配置数据多维数据集,并在网络服务器上下载或更新数据多维数据集,在这种情况下,将自动更新基于多维数据集程序集的先前版本构建的所有仪表板。 可以自动配置更新多维数据集,例如在晚上。 组装立方体时,所有度量和度量(尺寸和度量)都是预先设置的,在下一个版本的装配中才可以更改。 连同在Tableau中使用数据多维数据集一起,可以直接访问数据库,这称为实时连接,在这种情况下,速度将大大降低,但数据将更加相关。 组装数据多维数据集的过程非常简单,主要是选择正确的字段来组装多个表(联接)(图5)。
图 5
- 工作流程
由于这一点,我们将来不再选择Tableau。 根据此参数,Tableau远远落后于行业,无法提供任何工具来简化仪表板的开发和发布。 Tableau不提供版本控制,代码审查,团队协作,也没有经过深思熟虑的开发和测试环境。 正是由于这个原因,公司经常放弃Tableau,转而使用更高级的工具。 已经有一些员工参与创建数据多维数据集和仪表板,可能会引起混乱-在哪里可以找到最新版本的数据,哪些度量可以使用,哪些不能使用。 缺乏数据完整性,这导致业务对它在系统中看到的指标的不信任。
- 可视化
在数据可视化方面,Tableau是一个非常强大的工具。 您可以找到每种口味和颜色的图表和图形(图6)。 数据可视化-页面,如在Excel中一样,您可以在选项卡之间切换。
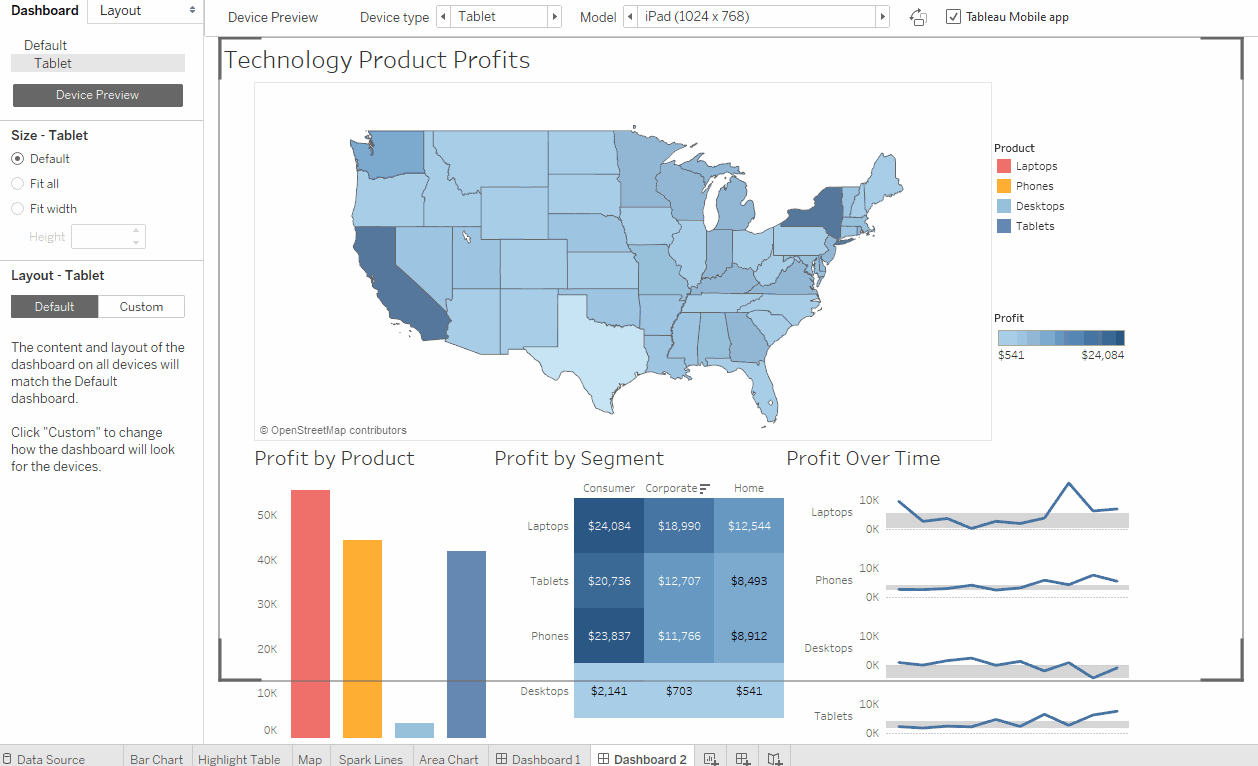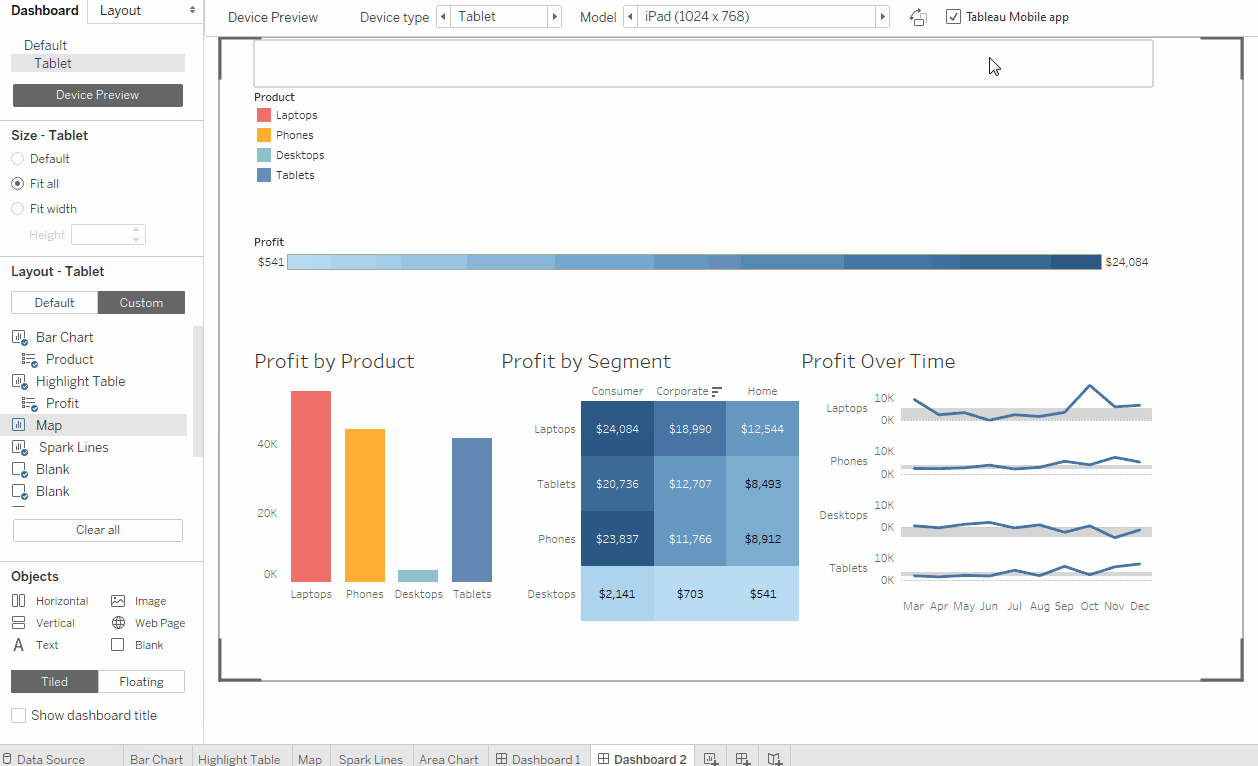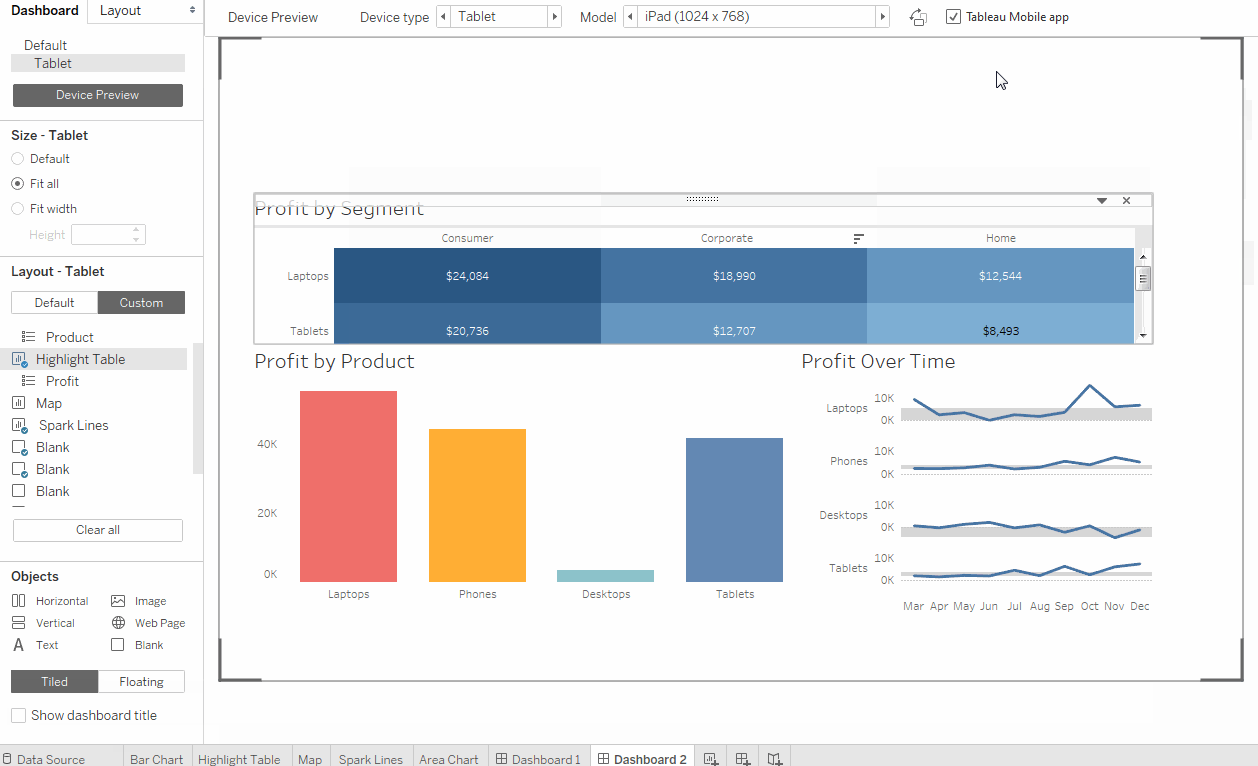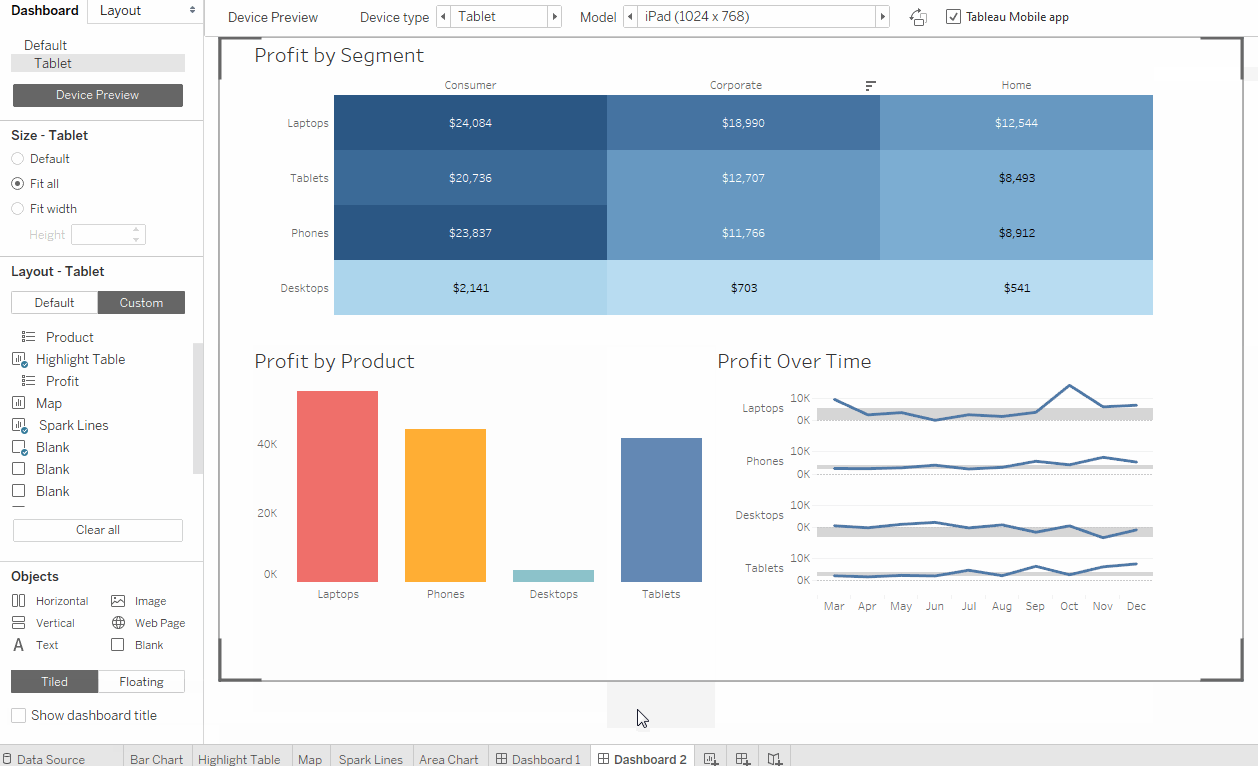
图 6
- 支持。
从Tableau支持的角度来看,在我看来不是很以客户为中心 ,对于大多数问题,我必须自己寻找答案。 幸运的是,Tableau有一个相当大的社区 ,您可以在其中找到大多数问题的答案。
- 统计资料
Tableau具有与Python 集成的功能,可以找到更多详细信息。
- 价钱
价格是市场的标准价格 ,可以在官方网站上找到。 价格取决于用户级别(开发人员,资源管理器,查看器),可以在此处找到说明。 在计算10个开发人员,25个浏览器和100个查看器时,每年的收入为39,000美元。
外观
- UX +拖放。
Looker是一家相对年轻的公司,成立于2012年。 UX对用户而言本来就很清晰,简单,拖放操作很方便(图7)。
图 7
- 数据处理。
在Looker中处理数据的速度明显比在Tableau中慢 。 主要原因是Looker无需创建OLAP多维数据集即可直接查询数据库。 正如我们所讨论的,这种方法有其优势-数据始终是新鲜的,并且可以进行任何数据聚合。 Looker还提供了用于加速复杂查询的工具- 缓存查询 ,即缓存查询的功能。
- 工作流程
与我们测试的所有BI工具相比,Looker的主要优势在于其经过深思熟虑的仪表板开发和发布过程 。 Looker使用github集成了版本控制 。 开发环境(生产模式 )和生产环境(图8)也很好地分开了。 Looker的另一个优点是,数据建模的访问权掌握在同一手-数据模型只有一个主版本,可以确保完整性。
在这里还要提及一下,Looker有其自己的SQL语言类似物,并具有用于数据建模的其他功能-LookML,这很有意义。 这是一个相当简单而灵活的工具,使您可以自定义拖放功能并添加许多新选项(图9)。
图 8
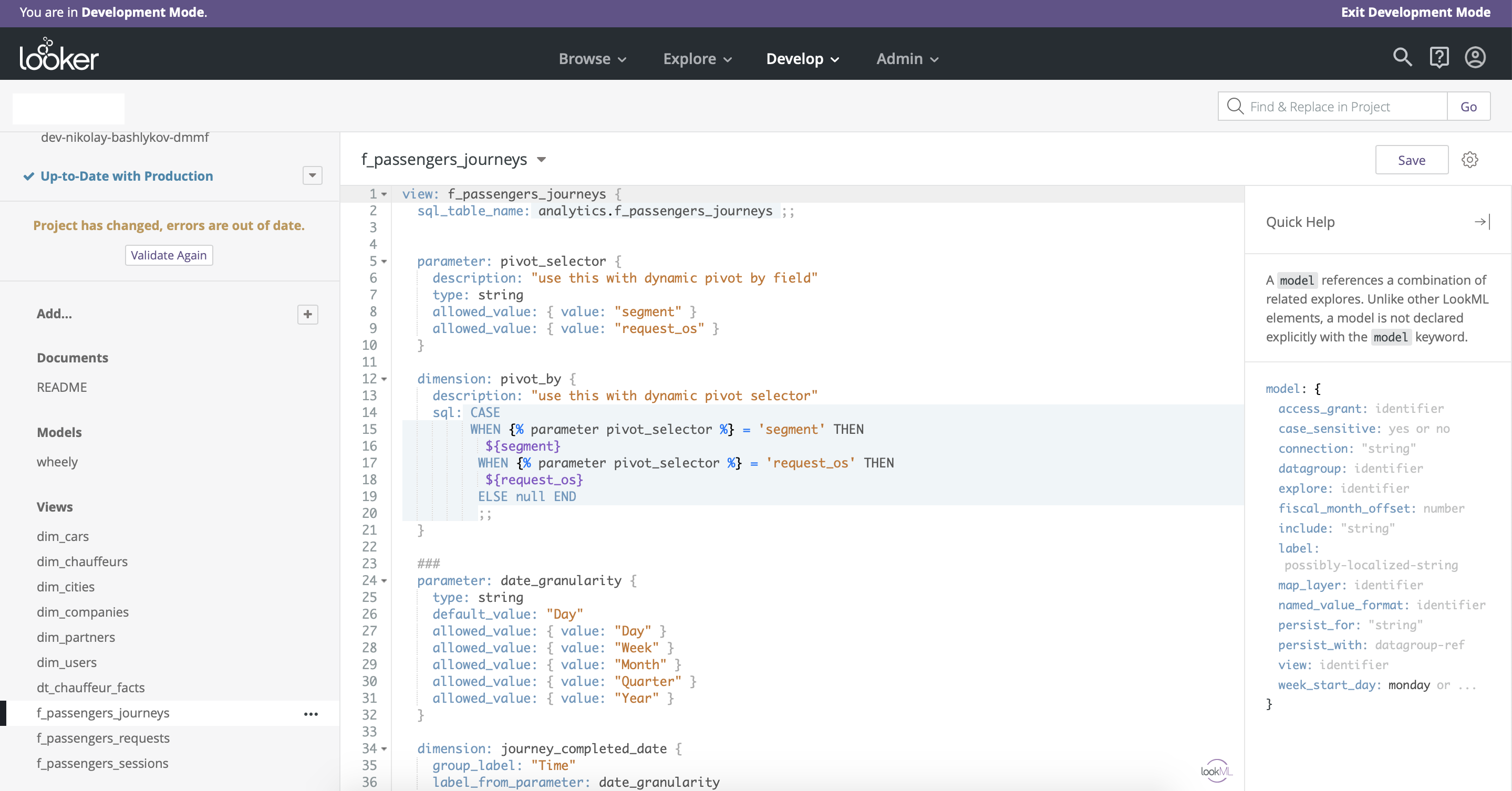
图 9
- 可视化
从可视化的角度来看,Looker并不逊于Tableau,在其中您可以找到任何您喜欢的图表。 与Tableau不同,图表的组织是垂直的(在其中组织是分页的(图10,图11))。 对业务用户而言,一项有用的功能是向下钻取功能-可以按预定义的维度细分所选数据。
图 10
图 11
- 支持。
我必须说,Looker的业务顾问和技术专家的支持令人惊讶-我们可以安排在半小时内就任何问题进行视频通话并获得完整答复。 看起来Looker确实很重视客户,并试图简化他们的生活。
- 统计资料
Looker拥有一个API-用于Python的Look API和SDK,在它们的帮助下,您可以从Python连接到Looker并下载必要的信息,然后在Python中执行必要的转换和统计分析,然后将结果加载回数据库中,随后输出到仪表板中的looker。
- 价钱
Looker的成本比Tableau高得多 ,对于一组类似的用户,Looker的价格几乎是Tableau的2倍-约60,000美元/年。
潜望镜
- UX +拖放。
Periscope是一个相当易于使用的工具,功能有限 。 还有一个拖放功能,但是必须分别创建用于不同图表的过滤器,这很不方便(图12)。 没有SQL,就无法创建稍微复杂的查询。
图 12
- 数据处理。
Periscope在OLAP多维数据集和查询缓存之间有一个交叉。 在其中,您可以创建视图并对其进行缓存。 View是任何SQL查询,为了对其进行缓存,必须在此View的设置中单击“ materialize”按钮(图13)。 您还可以发布“发布”视图,以便将其用于拖放。
图 13
- 工作流程
Periscope Pro使用git集成了版本控制 。 还可以查看任何仪表板的更改历史记录并回滚到以前的版本。
- 可视化
图表和图表的集合非常有限;在这里找不到Tableau或Looker中的变化。
- 支持。
如果您修改支持中心在太平洋标准时间运行,则支持是相当可操作的。 您一定会在24小时内收到答复。
- 统计资料
Periscope已与Python集成。 可以在这里找到更多详细信息。
- 价钱
Periscope Pro的价格大致类似于Tableau:35,000美元。
模式分析
- UX +拖放。
模式是这些工具中最简单的。 它的主要区别在于与Python的集成以及基于Jupyter Notebook创建分析报告的能力(图14)。 如果尚未建立使用Jupyter Notebook创建分析报告的过程,则此工具可能对您有用。 Mode是完全成熟的BI系统的补充,其功能非常有限,出于创建仪表板的目的,您可以使用不超过27,000行的表,这极大地限制了该工具的功能(图15)。 否则,您需要为每个图编写单独的SQL查询,以便聚合数据并获得较小的维表以进行可视化(图16)。
图 14
图 15
图 16
- 数据处理。
在这种模式下,缺少数据处理。 所有查询都是直接对数据库进行的,无法缓存主表。
- 工作流程
Mode已与Github集成,请在此处找到更多详细信息。
- 可视化
数据可视化集非常有限;有6-7种图形类型。
- 支持。
在测试期间,支持非常有效。
- 统计资料
如前所述,Mode与Python很好地集成在一起,它使您可以使用Jupyter Notebook创建用户友好的分析报告。
- 价钱
奇怪的是,模式的功能非常昂贵-大约每年50,000美元。
结论
BI , (, ). , , .
资料来源
- Gartner, Business Intelligence — BI — Gartner IT Glossary
- Kaggle
- Tableau — Hyper
- ZDNet — Salesforce-Tableau, other BI deals flow
- Tableau website
- Looker website
- Periscope website
- Mode analytics website