 注意事项 佩雷夫 :Dailymotion是全球最大的视频托管服务之一,因此是著名的Kubernetes用户。 在本文中,系统架构师David Donchez分享了为公司创建基于K8s的生产平台的结果,该平台首先在GKE中安装了云,然后以混合解决方案结束,从而可以缩短响应时间并节省基础架构成本。
注意事项 佩雷夫 :Dailymotion是全球最大的视频托管服务之一,因此是著名的Kubernetes用户。 在本文中,系统架构师David Donchez分享了为公司创建基于K8s的生产平台的结果,该平台首先在GKE中安装了云,然后以混合解决方案结束,从而可以缩短响应时间并节省基础架构成本。三年前决定重建核心的
Dailymotion API时,我们希望开发一种更有效的方式来托管应用程序并简化
开发和生产过程 。 为此,我们决定使用容器编排平台,并自然选择了Kubernetes。
为什么值得创建自己的基于Kubernetes的平台?
尽快使用Google Cloud进行生产级API
2016年夏季
三年前,在
维旺迪(Vivendi)收购Dailymotion之后,我们的工程团队专注于一个全球目标:创造一款全新的Dailymotion产品。
基于对容器,业务流程解决方案的分析以及我们过去的经验,我们确保Kubernetes是正确的选择。 一些开发人员已经对基本概念有所了解,并且知道如何使用它,这对于基础结构转换具有巨大的优势。
从基础架构的角度来看,需要一种功能强大且灵活的系统来托管新型的云原生应用程序。 我们选择在旅途的开始阶段留在云中,以便从容构建最可靠的本地平台。 他们决定使用Google Kubernetes Engine部署应用程序,尽管他们知道我们迟早会切换到自己的数据中心并采用混合策略。
为什么选择GKE?
我们之所以做出此选择,主要是出于技术原因。 此外,有必要快速提供满足公司业务需求的基础架构。 我们有一些应用程序需求,例如地理分布,可伸缩性和容错能力。
 Dailymotion中的GKE集群
Dailymotion中的GKE集群由于Dailymotion是全球可用的视频平台,因此我们确实希望通过减少
延迟来提高服务质量。 以前,
我们的API仅在巴黎可用,这不是最佳选择。 我希望不仅可以在欧洲,而且可以在亚洲和美国托管应用程序。
这种对延迟的敏感性意味着我们将不得不认真研究平台的网络架构。 大多数云服务迫使他们在每个区域中创建自己的网络,然后通过VPN或某个托管服务将它们连接起来,而Google Cloud使创建覆盖Google所有区域的完全可路由的统一网络成为可能。 就操作和系统效率而言,这是一大优势。
此外,Google Cloud的网络服务和负载平衡器也表现出色。 它们仅允许您使用每个区域中的任意公共IP地址,出色的BGP协议负责其余部分(即,将用户重定向到最近的群集)。 显然,如果发生故障,流量将自动流向另一个区域,而无需任何人工干预。
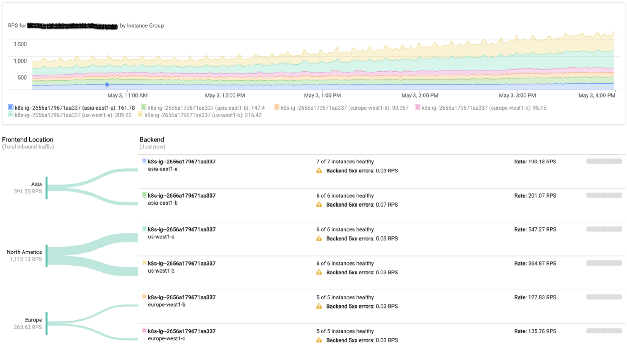 Google负载平衡监控
Google负载平衡监控我们的平台还积极使用图形处理器。 Google Cloud使在Kubernetes集群中直接使用它们非常高效。
那时,基础架构团队主要集中在物理服务器上部署的旧堆栈上。 这就是使用托管服务(包括Kubernetes主组件)满足我们的要求并允许我们培训团队使用本地集群的原因。
结果,我们在工作开始后仅6个月便开始接受Google Cloud基础架构上的生产流量。
但是,尽管有许多优势,但与云提供商合作会带来一定的成本,成本可能会根据负载而增加。 因此,我们仔细分析了每个使用的托管服务,希望将来在本地实现它们。 实际上,本地集群的引入始于2016年底,同时启动了混合策略。
启动Dailymotion本地容器编排平台
2016年秋季
在整个堆栈准备好生产并且API
仍在继续工作的情况下,有时间集中精力于区域集群。
当时,用户每月观看超过30亿个视频。 当然,多年来,我们一直在运营自己的分支内容交付网络。 我们想利用这种情况,在现有数据中心中部署Kubernetes集群。
Dailymotion基础架构在六个数据中心内总计有超过2.5千台服务器。 所有都使用Saltstack进行配置。 我们开始准备用于创建主节点和工作节点以及etcd集群的所有必要配方。

网络部分
我们的网络是完全可路由的。 每个服务器使用Exabgp在网络上宣布其IP。 我们比较了几种网络插件,而
Calico是满足所有需求的唯一插件(由于L3级别使用的方法)。 它完全适合现有的网络基础架构模型。
因为我想使用所有可用的基础架构元素,所以首先,我不得不处理我们自己开发的网络实用程序(用于所有服务器):使用它来宣布具有Kubernetes节点的网络上的IP地址范围。 我们允许Calico为Pod分配IP地址,但未使用它,也仍未将其用于网络设备上的BGP会话。 实际上,路由是由Exabgp处理的,Exabgp宣布了Calico使用的子网。 这使我们可以从内部网络(尤其是从负载平衡器)连接到任何Pod。
我们如何管理入口流量
要将传入的请求重定向到所需的服务,由于它与Kubernetes入口资源集成在一起,因此决定使用入口控制器。
三年前,nginx-ingress-controller是最成熟的控制器:Nginx已经使用了很长时间,并且以其稳定性和性能而闻名。
在我们的系统中,我们决定将控制器放置在专用的10 Gb刀片服务器上。 每个控制器都连接到相应集群的kube-apiserver的端点。 这些服务器还使用Exabgp来宣布公共或私有IP地址。 我们网络的拓扑结构使我们可以使用这些控制器中的BGP将所有流量直接路由到Pod,而无需使用NodePort之类的服务。 这种方法有助于避免节点之间的水平通信并提高效率。
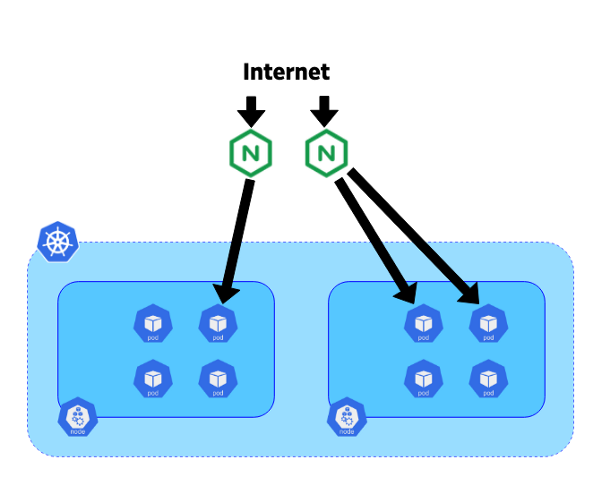 流量从Internet到Pod的移动
流量从Internet到Pod的移动既然您已经了解了我们的混合平台,就可以深入研究流量迁移的过程。
将流量从Google Cloud迁移到Dailymotion基础架构
2018年秋季
经过近两年的创建,测试和配置,我们终于获得了完整的Kubernetes堆栈,准备接收一些流量。

当前的路由策略非常简单,但是可以满足需求。 除了公共IP(在Google Cloud和Dailymotion中)之外,AWS Route 53还用于设置策略并将用户重定向到我们选择的集群。
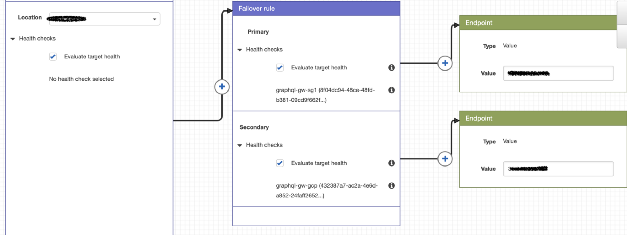 使用路由53的示例路由策略
使用路由53的示例路由策略使用Google Cloud,这很容易,因为我们对所有群集使用一个IP,并将用户重定向到最近的GKE群集。 对于我们的集群来说,技术是不同的,因为它们的IP是不同的。
在迁移期间,我们试图将区域请求重定向到各个集群,并评估了这种方法的优势。
由于我们的GKE群集配置为使用自定义指标自动扩展,因此它们会根据传入流量增加/减少容量。
在正常模式下,所有区域流量都会路由到本地集群,GKE会在出现问题时用作备用(运行状况检查由Route 53进行)。
...
将来,我们希望使路由策略完全自动化,以获得一种能够不断提高用户可访问性的自主混合策略。 至于优点:云的成本大大降低,甚至可以减少API的响应时间。 我们相信最终的云平台,并准备在必要时将更多流量重定向到该平台。
译者的PS
您可能也对最近有关Daily Kubernetes的Dailymotion出版物感兴趣。 它专门用于将Helm应用程序部署到许多Kubernetes集群上,大约一个月前发布。
另请参阅我们的博客: