大家好! 6月在新西伯利亚举行了一次有关高负载应用程序HighLoad ++ Siberia 2019开发的会议。在早先的Habré文章中,我们提到我们在Plesk对会议和报告进行了回顾,以免丢失所学知识并随后应用它们。 我们将告诉您我们为自己记录的报告,并与您分享回顾性食谱。 组织者正在逐步将视频发布在这里:
youtube频道 。 我们正在描述的部分内容已经可见。
报告概述
维克托·埃雷姆琴科 (米罗)这是有关Redis成功迁移-> PostgreSQL-> Pgbouncer + PostgreSQL-> Patroni Consul + Pgbouncer + PostgreSQL的审查报告。 作者给出了方案,显而易见的解决方案的典型陷阱,讨论了替代解决方案以及为什么它们不合适。 来自有趣的:
- Miro工程师整理了他们的解决方案,以免为Amazon RDS买单,到目前为止,该解决方案很适合他们。
- Likbez关于PostgreSQL的连接管理器。
- 描述不停止应用程序而更新群集节点的过程。
- 显示了快速更新PostgreSQL的技巧。
看看那些正在使用或将要使用PostgreSQL的人以及拥有越来越多的数据的人很有用。
瓦西里·波哥纳托夫 (Yandex)作为介绍性演讲者,他简要介绍了Kafka和RabbitMQ的某些功能。 简而言之:Kafka-一个简单的队列,一个复杂的接收者; RabbitMQ是一个复杂的队列,一个简单的接收器。 作者还谈到了从队列传递消息的保证类型。 重要说明:在没有发件人和收件人支持的情况下,没有队列可以确保将邮件准确发送1次。
该报告专用于YandexMQ。 YandexMQ(YMQ)是与Amazon SQS队列兼容的API。 YandexMQ的基础是Yandex数据库(YDB)。 Vasily展示了YandexMQ的优势,如何实现严格的一致性和可靠性,并回顾了YMQ的体系结构。 YMQ实施竞争消费者模式-向一位消费者发出一条消息。 YMQ芯片:当消费者请求一条消息时,它被隐藏在队列中,因此没有其他人将其用于处理。 如果在处理过程中出现问题,则在VisibilityTimeout之后,该消息将再次在队列中可见。 发言者声称,Apache Kafka在进程突然终止时会出现数据丢失问题,Yandex MessageQueue对此具有抵抗力。

该报告推荐给所有想了解队列基本功能的人。
伊万·穆拉托夫 (第一监测公司)报告如何在PostgreSQL时间序列中存储和处理数据。
TimescaleDB允许您通过棘手的分区存储大量数据,而PipelineDB则直接在PostgreSQL中提供对流的工作(以及与队列的集成)。
TimescaleDB:
- 它具有非常稳定的记录速度,在重负载下数据库的容量增加了,分区的数量也增加了(以千计)。
- 允许您使用标准的PostgreSQL功能,例如SQL,复制,备份,还原等。
- 例如,与Prometheus,Telegraf,Grafana,Zabbix和Kubernetes宣布了一系列很好的集成。
- 有一个免费的开源版本。
主要思想:TimescaleDB主要用于存储数据。
PipelineDB:
- 允许您使用SQL连续处理传入数据并将结果添加到表中。
- 有一个SQL接口。
- 在这种情况下有存储过程的执行。
- 可以与Apache Kafka和Amazon Kinesis集成。
- 有一个免费的开源版本。
- PipelineDB的开发被冻结在1.0版中,现在仅发布错误修复。
主要思想:PipelineDB主要用于数据处理。
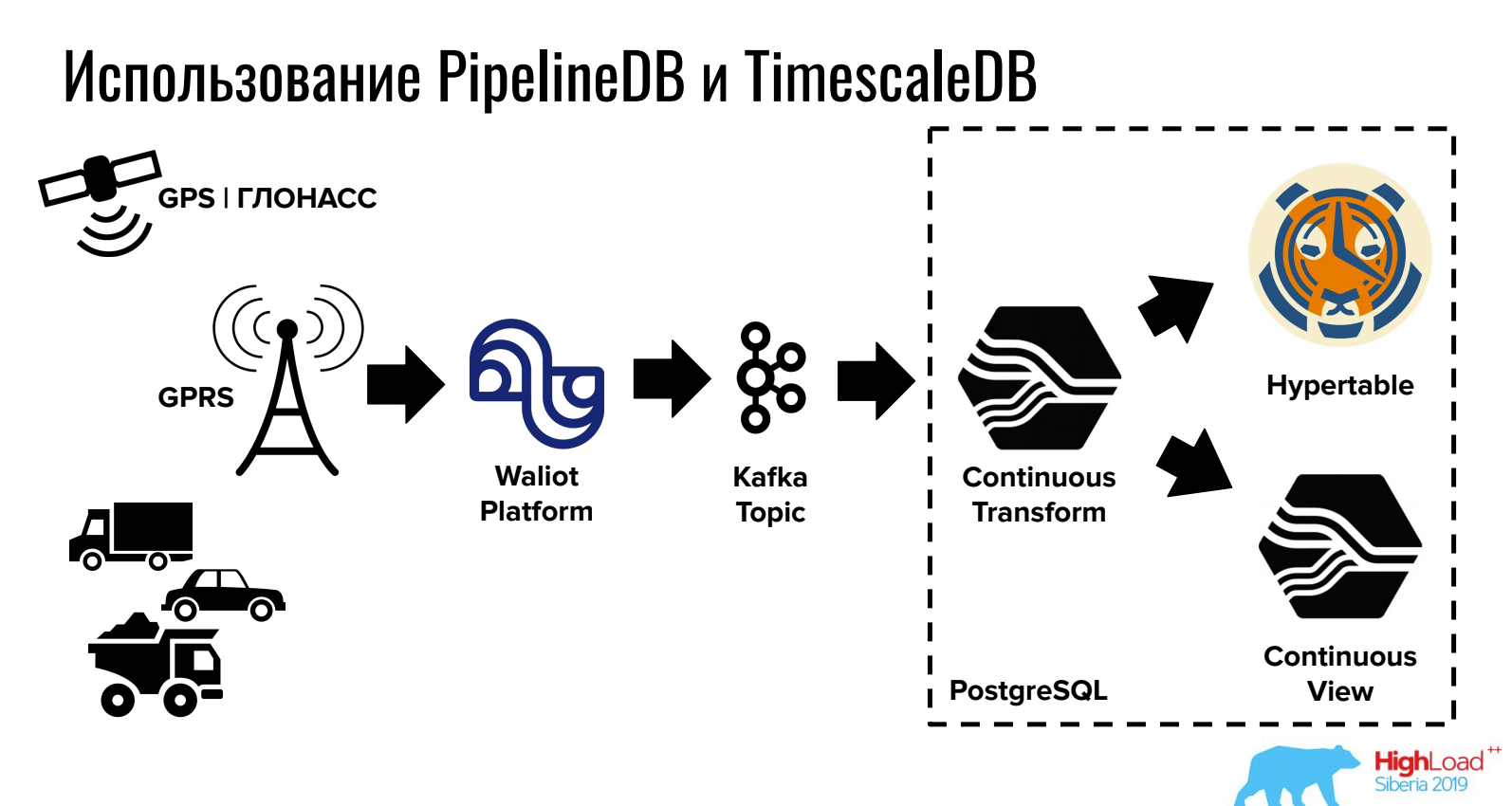
对于同时需要关系DBMS,NoSQL和时间序列的任务,此选项非常方便。
Pavel Luzanov (Postgres Professional)关于PostgreSQL,表继承以及PostgreSQL 10、11、12+的技巧与窍门的良好概述报告。 通过继承,分片进行分区。 看到每个使用PostgreSQL并想使其更快一点的人都是很有用的。
谢尔盖·波洛夫科 (Yandex)关于尚处于“预览”阶段的Yandex Monitoring云产品是免费的。 关于架构的一些知识。 显示了一种有趣的技术-将元数据与数据分离,从而实现独立的缩放和优化。 Grafana用作GUI,而其警报不在Grafana中。
 安德烈·萨尔尼科夫 (数据白鹭)
安德烈·萨尔尼科夫 (数据白鹭)具有许多PostgreSQL服务器的商业系统管理经验。 它告知自动监视哪些服务器参数,如何确定任务的优先级。
数据白鹭在Wiki中使用带有配方,清单的通用经验-这是以后的文章和报告的基础。 他们使用带有问题和解决方案描述的事件数据库-这样可以大大节省资源。 发布了许多用于PostgreSQL的实用程序,并提供了指向它们的链接。
 叶夫根尼·索科洛夫 (Yandex.Market)
叶夫根尼·索科洛夫 (Yandex.Market)报告复杂,高度可访问的分布式Yandex.Market应用程序的体系结构,以及有关其开发,测试,更新,监视的过程和工具的报告。 来自有趣的:
- “ Stop-crane”是其用于快速应用和回滚配置的解决方案;它有助于测试新功能。
- 如果出现问题,流量将由平衡器从当前数据中心重定向到另一个数据中心。
- 石墨和格拉法纳用于监测。
- 在另一个技术堆栈上有重复的基本监视。
- Shadow群集用于开发人员,它会复制部分用户流量。 用户看不到Shadow群集的响应。
- 在A / B测试期间执行自动质量计算。
 安东·阿列克谢夫(2GIS)
安东·阿列克谢夫(2GIS)报告ClickHouse擅长的方面以及如何与Grafana一起烹饪。 主要有趣的是:
- 如果速度不够,则应使用采样(据认为采样后数据的准确性已足够)。 ClickHouse中的采样-使用聚合对数据进行部分采样,同时保持表键中各种值的比率,从而使您有时可以加快聚合速度,同时获得非常接近真实的结果。
- ClickHouse可用于快速调查事件(报告中的一个有趣示例)。
- ClickHouse还具有MaterializedView来加快获取速度。
- 描述了用于查询和数据加载的ClickHouse HTTP接口。
在审查报告的总结中,我想指出的是,我们也非常喜欢报告
“视频通话:从每天数百万人到一个会议的100名参与者” (
Alexander Tobol / Odnoklassniki),该报告根据投票结果被列入会议最佳报告列表。 这是视频会议对一组参与者的工作原理的很好概述。 该报告的特点是易于理解的系统介绍。 如果您突然需要进行视频通话,则可以查看报告,以快速了解主题区域。
Plesk会议闪回结构
现在,关于甜点,关于我们如何在公司内部撰写回顾展。 首先,我们尝试在参加会议后的第一周内写复古,而我们的记忆仍然鲜活。 顺便说一句,您可以猜想,回顾性材料可以作为文章的基础;)
编写回顾展的目的不仅在于巩固知识,而且还与那些没有参加会议但想了解最新趋势,有趣的解决方案的人分享知识。 一个现成的列表有助于减少搜索有趣报告的时间。 我们会写出我们自己为自己吸取的教训,用注释标记特定的人,为什么您需要查看报告并考虑其他人的想法和决定。 书面课程有助于集中精力,而不会失去我们想要做的事情。 查看3到6个月内的录音,我们将了解是否忘记了重要的事情。
我们将文档存储在Confluence的公司中,对于会议,我们有单独的页面树,一块木头:
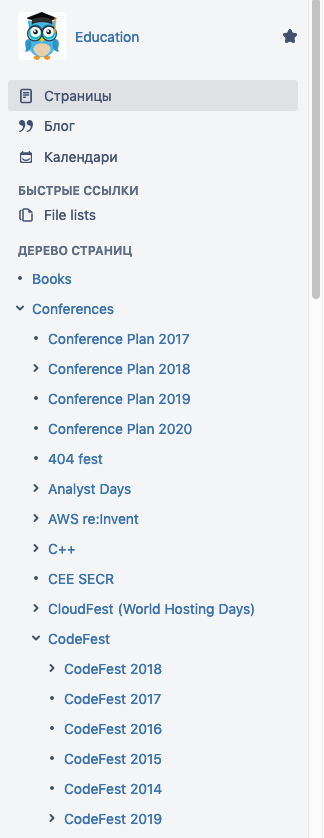
从屏幕截图可以看出,为了便于导航,我们按年度对材料进行了布局。
在专门用于特定会议的页面内,我们存储以下部分:概述,包括指向活动网站,日程,视频和演示的链接,与会人员列表(亲自和广播),总体印象(总体印象)和详细概述(详细概述) ) 顺便说一下,我们从已经存在整个结构的模板中生成一个页面来进行追溯。 我们还对标题的内容进行了编排,以便您可以非常快速地查看报告列表并转到所需的报告列表。
总体印象部分对会议进行了简要评估,并给出了与会人员的印象。 如果参加者在过去的几年中参加过会议,他们可以比较自己的水平并大致了解参加该活动的有用性。
详细概述部分包含一个表:

填写表格的示例:

我们很想知道您在Highload Siberia 2019上喜欢的报告以及您进行回顾的经验。