哈Ha
在
第一部分中 ,考虑了NVIDIA Jetson Nano-Raspberry Pi尺寸的主板,专注于使用GPU进行性能计算。 现在该测试板的创建目的了-面向AI的计算。

考虑一下板上的不同任务,例如对图像进行分类或识别行人或印章(没有图像的地方)。 对于所有测试,源代码都可以在台式机,Jetson Nano或Raspberry Pi上运行。 对于那些感兴趣的人,继续减产。
有两种使用该板的方法。 首先是运行Keras和Tensorflow等标准框架。 它在原理上可以正常工作,但是从第一部分已经可以看出,Jetson Nano当然不如成熟的台式机或笔记本视频卡。 用户将不得不承担优化模型的任务。 第二种方法是参加电路板附带的现成的课程。 它更简单并且可以“即开即用”地工作,其缺点是所有实现细节都被更大程度地隐藏了,此外,您还必须学习和使用custom-sdk,除了这些板之外,custom-sdk在其他任何地方都将无用。 但是,我们将从第一种开始着眼于两种方式。
图片分类
考虑图像识别问题。 为此,我们将使用Keras随附的ResNet50模型(该模型是2015年ImageNet挑战赛的获胜者)。 要使用它,只需几行代码就足够了。
import tensorflow as tf import numpy as np import time IMAGE_SIZE = 224 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) resnet = tf.keras.applications.ResNet50(input_shape=IMG_SHAPE) img = tf.contrib.keras.preprocessing.image.load_img('cat.png', target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_data = tf.contrib.keras.preprocessing.image.img_to_array(img) x = tf.contrib.keras.applications.resnet50.preprocess_input(np.expand_dims(img_data, axis=0)) probabilities = resnet.predict(x) print(tf.contrib.keras.applications.resnet50.decode_predictions(probabilities, top=5)) print("dT", time.time() - t_start)
我什至没有开始删除破坏者下的代码,因为 他很小。 如您所见,首先将图像调整为224x224(这是输入网络格式),最后,预测功能完成所有工作。
我们给猫拍照,然后运行程序。

结果:
[[('n02123045', 'tabby', 0.765179), ('n02123159', 'tiger_cat', 0.19059166), ('n02124075', 'Egyptian_cat', 0.013605555), ('n04493381', 'tub', 0.0025916891), ('n04553703', 'washbasin', 0.0021566998)]]
再一次,由于他对英语的了解而感到不安(我想知道有多少非本地人知道什么是“平头”?),我用字典检查了输出,是的,一切正常。
在CPU上计算的PC代码执行时间为
0.5 s ,在GPU上计算的PC代码执行时间为2 s(!)。 根据日志判断,问题出在模型中还是在Tensorflow中,但是在启动时,代码尝试分配大量内存,并以“分配器(GPU_0_bfc)内存不足,尝试分配freed_by_count = 0的2.13GiB”的形式发出警告。 。 这是一个警告,而不是一个错误,该代码可以正常工作,但是比它应该慢得多。
在Jetson Nano上,速度仍然较慢:CPU上为
2.8c ,GPU上为
18.8c ,输出如下所示:
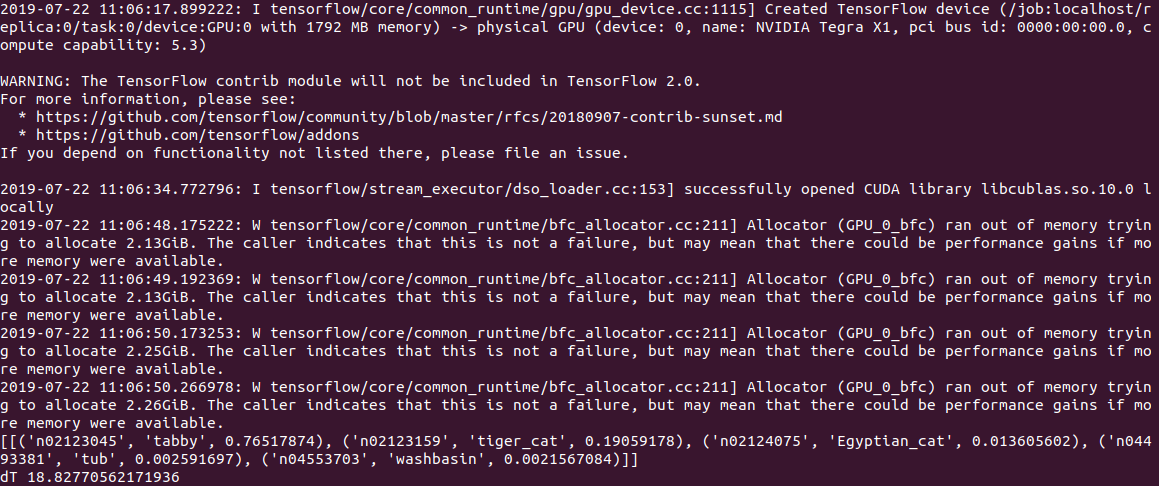
通常,即使每个图像3s,这也不是实时的。 设置建议在堆栈溢出时使用的gpu_options.allow_growth选项无济于事,如果有人知道另一种方法,请在注释中编写。
编辑 :按照评论中的提示,tensorflow的首次启动通常会花费很长时间,并且使用它来衡量时间是不正确的。 确实,当处理第二个及后续文件时,结果要好得多-不带GPU时为0.6秒,带GPU时为0.2秒。 但是,在台式机上,速度分别为2.0秒和0.05秒。
ResNet50的一个方便功能是,在第一次启动时,它将整个模型泵出到磁盘(大约100 MB)中,然后代码完全自主运行,无需注册和SMS。 考虑到大多数现代AI服务只能在服务器上运行,而没有Internet,设备会变成“南瓜”,这特别好。
猫与狗
考虑以下问题。 使用Keras,我们将创建一个可以区分猫和狗的神经网络。 这将是一个卷积神经网络(CNN-卷积神经网络),我们将从
本出版物中借鉴网络设计。 tensorflow_datasets包中已包含一组训练的猫和狗的图像,因此您不必自己拍摄它们。
我们加载一组图像并将其分为三个块-训练,验证和测试。 我们对每张图片进行“归一化”,使颜色达到0.1.1的范围。
import tensorflow as tf from tensorflow.keras import layers import tensorflow_datasets as tfds from keras.preprocessing import image import numpy as np import time IMAGE_SIZE = 64 IMG_SHAPE = (IMAGE_SIZE, IMAGE_SIZE, 3) splits = tfds.Split.TRAIN.subsplit(weighted=(80, 10, 10)) (cat_train, cat_valid, cat_test), info = tfds.load('cats_vs_dogs', split=list(splits), with_info=True, as_supervised=True) label_names = info.features['label'].int2str def pre_process_image(image, label): image = tf.cast(image, tf.float32) image = image / 255.0
我们编写了生成卷积神经网络的功能。
def custom_model():
现在,我们可以在“猫狗”工具包上进行网络培训。 培训需要很长时间(在GPU上需要20分钟,在CPU上需要1-2小时),因此最后我们将模型保存到文件中。
tl_model = custom_model() t_start = time.time() tl_model.fit(train_batch, steps_per_epoch=8000, epochs=2, validation_data=validation_batch, validation_steps=10, callbacks=None) print("Training done, dT:", time.time() - t_start) print(tl_model.summary()) validation_steps = 20 loss0, accuracy0 = tl_model.evaluate(validation_batch, steps=validation_steps) print("Loss: {:.2f}".format(loss0)) print("Accuracy: {:.2f}".format(accuracy0)) tl_model.save("dog_cat_model.h5")
顺便说一句,直接在Jetson Nano上进行培训的尝试失败了-5分钟后,主板过热并挂了。 对于资源密集型计算,电路板需要一个冷却器,尽管总的来说,直接在Jetson Nano上执行此类任务没有任何意义-您可以在PC上训练模型并在Nano上使用完成的保存文件。
然后又出现了一个陷阱-在PC上安装了tensowflow版本14库,到目前为止,Jetson Nano的最新版本是13。而且在第13版中没有读取保存在第14版中的模型,我不得不使用pip安装相同的版本。
最后,我们可以从文件中加载模型并使用它来识别图像。
def predict_model(model, image_file): img = image.load_img(image_file, target_size=(IMAGE_SIZE, IMAGE_SIZE)) t_start = time.time() img_arr = np.expand_dims(img, axis=0) result = model.predict_classes(img_arr) print("Result: {}, dT: {}".format(label_names(result[0][0]), time.time() - t_start)) model = tf.keras.models.load_model('dog_cat_model.h5') predict_model(model, "cat.png") predict_model(model, "dog1.png") predict_model(model, "dog2.png")
猫的照片使用了相同的照片,但“狗”测试使用了2张照片:

第一个猜对了,第二个开始有错误,神经网络认为那是一只猫,我不得不增加训练的迭代次数。 但是,我可能第一次会犯一个错误;
事实证明,在Jetson Nano上的执行时间非常短-第一张照片的处理时间为0.3秒,但随后的所有照片都快得多,显然数据已缓存在内存中。
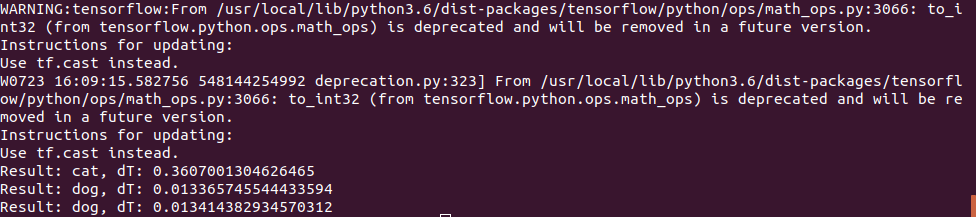
通常,我们可以假设在这样简单的神经网络上,即使不进行任何优化,电路板速度也足够了,即使对于实时视频,100fps也足够了。
结论
如您所见,即使成功的程度不尽相同,即使Keras和Tensorflow的标准模型也可以用于Nano。 但是,结果可以得到改善,有关优化模型和减小内存大小的说明可以在
此处阅读。
但是幸运的是,制造商已经为我们做到了。 如果读者仍然有兴趣,那么最后一部分将专门介绍针对Jetson Nano进行了优化的
现成库 。