如您所知,索引在DBMS中起着重要的作用,可以快速搜索必要的记录。 因此,及时为他们提供服务非常重要。 已经写了很多有关分析和优化的资料,包括在Internet上。 例如,在
该出版物中对该主题进行了最新回顾。
为此,有许多付费和免费解决方案。 例如,存在基于自适应索引优化方法的交钥匙
解决方案 。
接下来,考虑由
AlanDenton编写的免费
SQLIndexManager实用程序。
作者自己
在这里和
这里,在SQLIndexManager和许多其他类似物之间的主要技术区别。
在同一篇文章中,我们介绍了该项目以及使用该软件解决方案的可能性。
在此讨论此实用程序。
随着时间的流逝,大多数注释和错误已得到修复。
因此,现在让我们进入SQLIndexManager实用程序本身。
该应用程序使用Visual Studio 2017中的C#.NET Framework 4.5编写,并将DevExpress用于以下形式:
看起来像这样:
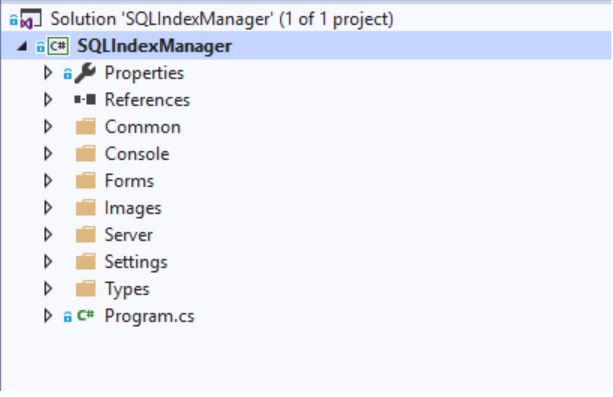
所有请求均在以下文件中生成:
- 索引
- 询问
- 查询引擎
- 服务器信息
当连接到数据库并将请求发送到DBMS时,该应用程序的签名如下:
ApplicationName=”SQLIndexManager”
应用程序启动时,将打开一个模式窗口以添加连接:
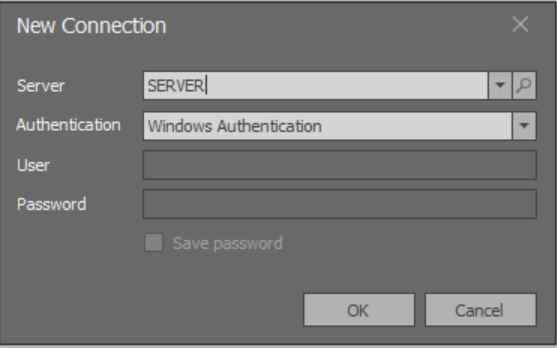
在这里,无法加载通过本地网络可用的MS SQL Server所有实例的完整列表。
您还可以使用主菜单上最左侧的按钮添加连接:
接下来,将启动以下DBMS查询:
获取DBMS信息 SELECT ProductLevel = SERVERPROPERTY('ProductLevel') , Edition = SERVERPROPERTY('Edition') , ServerVersion = SERVERPROPERTY('ProductVersion') , IsSysAdmin = CAST(IS_SRVROLEMEMBER('sysadmin') AS BIT)
获取可用数据库及其简要属性的列表 SELECT DatabaseName = t.[name] , d.DataSize , DataUsedSize = CAST(NULL AS BIGINT) , d.LogSize , LogUsedSize = CAST(NULL AS BIGINT) , RecoveryModel = t.recovery_model_desc , LogReuseWait = t.log_reuse_wait_desc FROM sys.databases t WITH(NOLOCK) LEFT JOIN ( SELECT [database_id] , DataSize = SUM(CASE WHEN [type] = 0 THEN CAST(size AS BIGINT) END) , LogSize = SUM(CASE WHEN [type] = 1 THEN CAST(size AS BIGINT) END) FROM sys.master_files WITH(NOLOCK) GROUP BY [database_id] ) d ON d.[database_id] = t.[database_id] WHERE t.[state] = 0 AND t.[database_id] != 2 AND ISNULL(HAS_DBACCESS(t.[name]), 1) = 1
执行上述脚本后,将出现一个窗口,其中包含有关MS SQL Server所选实例的数据库的简要信息:
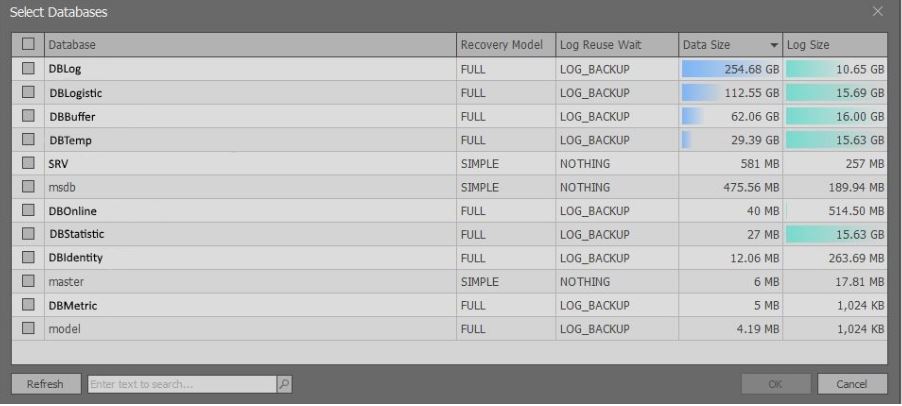
值得注意的是,基于权限显示扩展信息。 如果有
sysadmin ,则可以从
sys.master_files视图中选择数据。 如果没有这样的权限,那么将返回较少的数据,以免减慢请求的速度。
在这里,您需要选择感兴趣的数据库,然后单击“确定”按钮。
接下来,将对每个选定的数据库执行以下脚本以分析索引的状态:
索引状态分析 declare @Fragmentation float=15; declare @MinIndexSize bigint=768; declare @MaxIndexSize bigint=1048576; declare @PreDescribeSize bigint=32768; SET NOCOUNT ON SET ARITHABORT ON SET NUMERIC_ROUNDABORT OFF IF OBJECT_ID('tempdb.dbo.#AllocationUnits') IS NOT NULL DROP TABLE
从查询本身可以看到,经常使用临时表。 这样做是为了避免重新编译,并且在大型方案的情况下,由于只能在一个流中插入表变量,因此在插入数据时可以并行生成计划。
执行上述脚本后,将出现一个带有索引表的窗口:

在这里您还可以显示其他详细信息,例如:
- 一个数据库
- 段数
- 上次通话的日期和时间
- 压缩
- 文件组
等
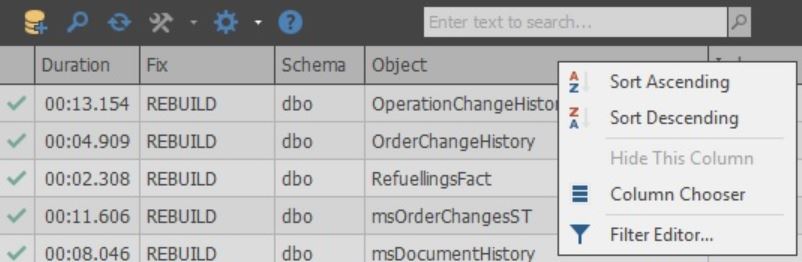
列本身可以自定义:
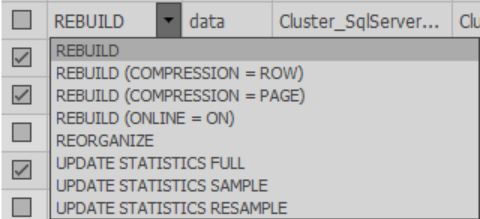
在“修复”列的单元格中,您可以选择在优化过程中将执行的操作。 另外,扫描完成后,将根据所选设置选择默认操作:
您必须选择所需的索引进行处理。
使用主菜单,您可以保存脚本(相同的按钮本身启动索引优化过程):
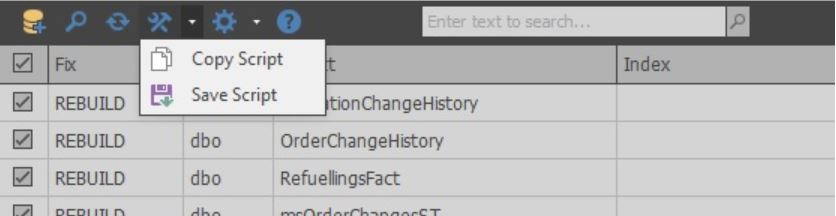
以不同的格式保存表格(使用同一按钮可以打开详细的设置以分析和优化索引):

同样,可以通过单击放大镜旁边主菜单左侧的第三个按钮来更新信息。
带有放大镜的按钮可让您选择所需的数据库进行考虑。
当前没有完整的帮助系统。 因此,按“?” 它只会导致出现一个模态窗口,其中包含有关软件产品的基本信息:
除上述所有功能外,主菜单还有一个搜索栏:

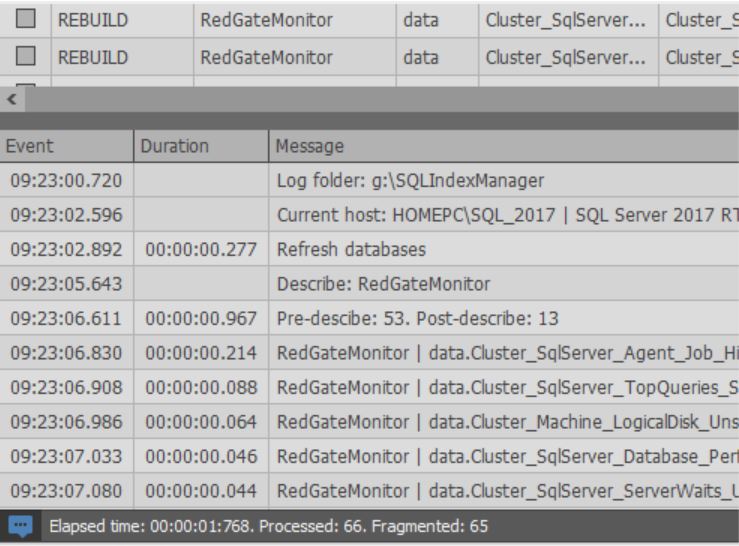
启动索引优化过程时:

同样在窗口底部,您可以看到执行的操作的日志:
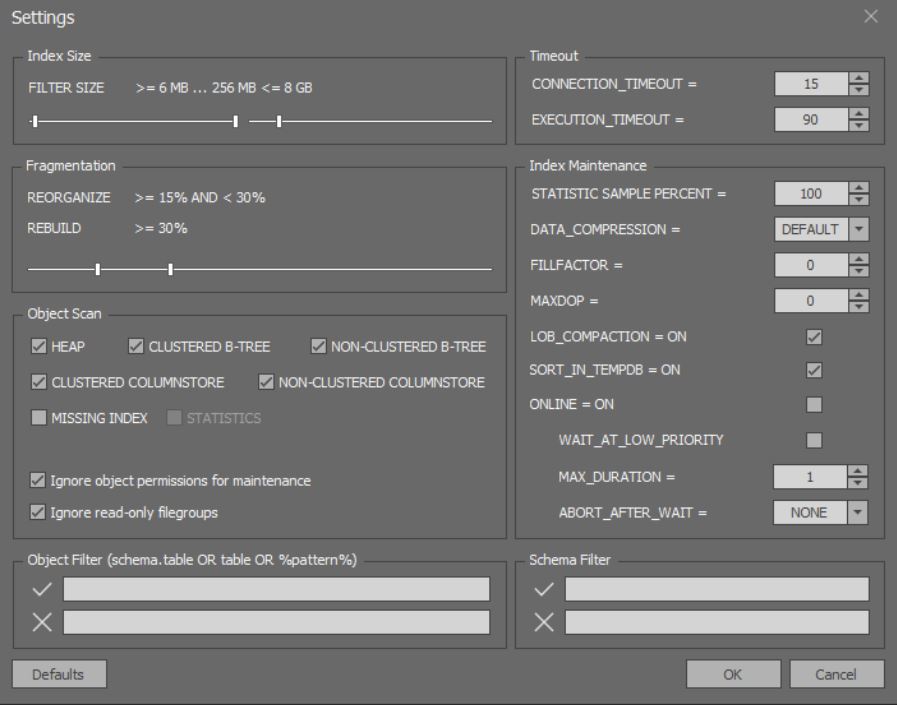
在用于详细分析和优化索引的窗口中,可以配置更多细微的选项:
 申请建议:
申请建议:- 使不仅可以有选择地更新索引的统计信息,还可以以不同方式(完全更新或部分更新)
- 不仅可以选择数据库,还可以选择其他服务器(当有许多MS SQL Server实例时,这非常方便)
- 为了获得更大的使用灵活性,建议将命令包装在库中,然后将其输出到PowerShell命令,例如,在此处: dbatools.io/commands
- 可以保存和更改整个应用程序以及(如有必要)MS SQL Server的每个实例和每个数据库的个人设置
- 从第2章和第4章开始,人们希望在数据库上创建组,并在MS SQL Server实例上创建组,其设置是相同的
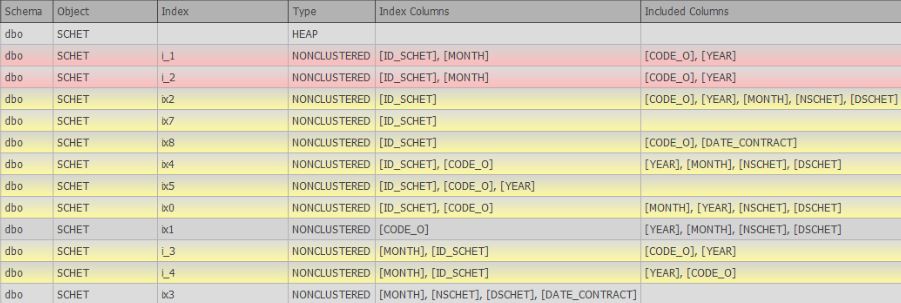
- 搜索重复的索引(完整索引和不完整索引,它们可能略有不同,或者仅在包括的列中有所不同)
- 由于SQLIndexManager仅用于MS SQL Server DBMS,因此您需要在名称中反映出来,例如,如下所示:用于MS SQL Server的SQLIndexManager
- 将应用程序的所有部分从GUI删除到单独的模块中,然后将它们重写为.NET Core 2.1
在撰写本文时,愿望的第6条正在积极制定中,并且已经以搜索完整和相似的副本的形式得到了支持:
资料来源