本文提供了用于使用替代方法和创建历史记录生成有关EMC VNX存储驱动器状态的常规报告的代码。
我试图用最详细的注释和一个文件编写代码。 仅替换您的密码。 还指出了源数据的格式,因此如果有人尝试在家中应用它,我将感到高兴。
背景知识
如果您不感兴趣“腿长”的来源,则可以跳过。
我们有一个数据中心。 没有非常新鲜的存储系统。 存储系统很多,磁盘也会发生故障。 一周几次,人们去数据中心并更换存储系统中的驱动器。 在“ 推荐的磁盘更换 ”系统发出警报后,决定更换磁盘。
没有什么不寻常的。

但是最近,收集在这些存储系统上并提供给虚拟环境的单个LUN开始严重退化。 与供应商的技术支持人员联系后,很明显,不仅在出现上述警报消息时,而且在出现大量其他消息时,系统都未考虑严重错误,也应该已经更换了磁盘。
不支持通过这些存储系统进行SNMP监视。 您需要使用昂贵的专有软件(我们没有),或者使用NaviSECCli控制台实用程序,该实用程序需要连接到每个存储系统的每个控制器(其中有两个),但这并不是很理想。
决定自动收集日志并搜索其中的错误。 根据报告的分析结果,应由负责的工程师决定更换磁盘。
第一步
最初,我的一位同事编写了执行以下操作的PowerShell代码:
- 拿了一个包含存储控制器IP地址的输入表;
- 周期到达控制器A的IP地址,然后到达控制器B的IP地址;
- 在此过程中,还额外采访了他们以获取磁盘的序列号;
- 处理了日志的所有行,并过滤了所查找消息的内容;
- 创建一个PowerShell对象,并在其属性中从上面获得的行中解析必要的数据;
- 将所有结果对象合并到以csv形式发布的表中。
代码如下。 立即保留他正在工作的保留,但是我们引入了替代解决方案。
PowerShell源cd 'd:\Navisphere CLI\' $csv = "D:\VNX-IP.csv" $Filter1 = "name1" $Filter2 = "name2" $Filter3 = "name3" $Data = import-csv $csv -Delimiter ';' | Where {$_.cl -EQ $Filter1 -Or $_.cl -EQ $Filter2 -Or $_.cl -EQ $Filter3} | Sort-Object -Property @{Expression={$_.cl}; Ascending=$true}, @{Expression={$_.Name} ;Ascending=$true} #$Filter1 = "nameOfcl" #$Data = import-csv $csv -Delimiter ';' | Where {$_.Name -EQ $Filter1} $Data | select Name,IP,cl $yStart = (Get-Date).AddDays(-30).ToString('yyyy') $yEnd = (Get-Date).ToString('yyyy') $mStart = (Get-Date).AddDays(-30).ToString('MM') $mEnd = (Get-Date).ToString('MM') $dStart = (Get-Date).AddDays(-30).ToString('dd') $dEnd = (Get-Date).ToString('dd') #$start = (Get-Date).AddDays(-3).ToString('MM\/dd\/yy') #$end = (Get-Date).ToString('MM\/dd\/yy') $i = 1 $table = ForEach ($row in $Data) { Write-Host $row.Name -ForegroundColor "Yellow" Write-Host "SP A" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "A" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host "SP B" Write-Host (Get-Date).ToString('HH:mm:ss') $txt = .\NaviSECCli.exe -scope 0 -h $row.newB -user myusername -password mypassword getlog -date $mStart/$dStart/$yStart $mEnd/$dEnd/$yEnd | Select-String -Pattern "\(820\)","\(803\)","\(801\)","\(920\)","\(901\)" ForEach ($n in $txt) { $x = $n -Split(' ') $disk = $x[3] + "_" + $x[5] + "_" + $x[7].Split("(")[0] $sn = (.\NaviSECCli.exe -scope 0 -h $row.newA -user myusername -password mypassword getdisk $disk -serial)[1] | %{$_ -replace "Serial Number: ",""} | %{$_ -replace "State: ",""} | %{$_ -replace " ",""} New-Object PSObject -Property @{ i = $i cl = $row.cl Storage = $row.Name SP = "B" Date = $x[0] Time = $x[1] Disk = $disk Error = (($n -Split('\['))[0] -Split('\)'))[1].Trim() eCode = (($n -Split('\('))[1] -Split('\)'))[0] SN = $sn } $i = $i + 1 } Write-Host " " } $table | select i,cl,Storage,SP,Date,Time,Disk,Error,eCode,SN | Export-Csv -Path 'd:\VNX-Errors.csv' -NoTypeInformation -UseCulture -Encoding UTF8
一切都很好,剩下的就是以自动发送给感兴趣的同事的信的形式添加“光泽”,并以最小的格式生成csv。 但是(!)所有这些麻烦解决了很长时间。 例如,收集一个月的数据大约需要45分钟 ,这不是很合适,因为除了定期报告之外,我还想对当年进行分析,这将是很长的时间。 但是“拒绝-提供”。 他们开始思考。

显然,您需要优化代码并启用并行计算。 在PowerShell中 ,使用工作流在5个以上并发线程中没有成功,并且还没有“抽烟”替代方法。 因此,决定尝试将脚本逻辑转换为R。 NaviSECCli实用程序可以在R下运行,可以在源代码中进行存储调查,因此该解决方案非常合适。
据说- 几天 -完成!
我们决定在输出中我想收到一份每日新闻通讯,其中包含信件文本中的错误总数 ,一些事故数量时间表 (以便向管理人员显示内容)以及一个xlsx表形式的附件 。 我们确定在表中我想要三个选项卡:
- 3天按磁盘和事故类型分类的事故数据
- 类似的标签,但使用了30天
- 原始数据(如果有人想自己在Excel中运行它们)
脚本算法
1.从csv下载控制器上的可用数据;
2.通过并行计算所有控制器的周期,搜索所需警报消息的记录;
3.将结果合并到一个数据框中;
4.做数据处理和转换;
5.生成xlsx文件;
6.形成我们保存在png中的时间表;
7.形成一封包含所收集数据的信件;
8.寄一封信。
让我们看一下算法的要点
1.从csv下载控制器上的可用数据
要收集紧急信息,您需要使用专用的EMC软件-NaviCLI(带有某些键)串联到两个控制器( newA和newB列 )。
为方便起见,我们在加载后重新格式化结果表,以便两个控制器的IP地址在同一列中,这样您就可以在整个列表中进行一个循环,而不是两个连续的循环。 我们使用collect函数来做到这一点。 tidyverse库的官方文档中很好地描述了使用“垂直”或“水平”数据格式的问题 。 您可以在这里阅读。
我们使用read_csv2函数读取数据,我们还通过其他参数col_types手动确定列的类型。 这是一个好习惯,因为 大大加快了加载速度。 就我们而言,这并不重要,因为 原始的csv包含不到100行,但我们习惯了正确编写。
在输出中,我们得到了这样一个数据帧(新列是cntName和cntIP ):
2-3。 我们通过并行计算为所有控制器运行一个周期,并搜索所需警报消息的记录。 将结果合并到数据框中
接下来是最有趣的。 并行计算 。
在R中,有几个(甚至很多)并行计算选项。 我更喜欢来自foreach和doParallel库的链接。 您可以在此处阅读有关它们以及R中其他并行计算选项的信息 。
简而言之,我们仅采取3个步骤 :
第一步 注册内核 纯翡翠 通过registerDoParallel在并行计算中工作的CPU(在我们的案例中,我们首先检测案例中的内核数)
注册CPU内核 numCores <- detectCores() registerDoParallel(numCores)
第二步 我们通过foreach开始循环(不要忘记指定%dopar%运算符,以便循环并行运行,并通过.combine参数指示我们收集结果的方式)。 在我们的例子中, .combine = rbind ,因为在每个循环的输出处,我们将有一个数据帧 。
第三步 我们通过stopImplicitCluster()清除创建的并行度集群
有关从原始错误文本获取可读表的更多详细信息
以文本形式,错误如下:
head(errors_raw) [1] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841d1080 10006 " [2] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841e1a00 10006 " [3] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 8420b600 10006 " [4] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 84206900 10006 " [5] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc900 10006 " [6] "07/13/2019 00:01:46 Bus 0 Enclosure 3 Disk 9(801) Soft SCSI Bus Error [0x00] 841fc000 10006
在这里,我们用空格分隔值,乍一看,即使在csv中也可以正常插入。 但这不是那么简单。 解析的复杂性在于:
- 日期和时间也用空格隔开(最小的邪恶);
- 错误文本由“单词”组成,即 也用空格隔开;
- 由于某种原因,磁盘号和错误代码(在方括号中)之间没有空格。
通常,是正则表达式爱好者的天堂:)

我将不讨论解析,因为这是一个问题,但是我要澄清一下错误文本必须撕开,因为值位于错误号的右括号和其他值的方括号之间。 在循环中,这是errors变量。
有趣的一点是,为了形成最终数据帧,我们希望循环访问控制器的ip地址,而不是通过带有控制器ip地址的列(即i = VNX_ip $ cntIP )来设置序列,而是通过行号(即e。i = 1:nrow(VNX_ip) )。 当创建具有已解析错误的数据帧时,这使我们可以分别通过调用VNX_ip $ cl [i]和VNX_ip $ Name [i]添加群集号和存储名称。 如果没有这个,就必须进行联接,这将使代码中的读取变得更慢,更糟。
最后,我们获得了一个数据框架(说实话,然后是tibble ,但区别不在本文的讨论范围之内),其中包含我们需要的所有数据。 即 在哪个存储系统上,在哪个磁盘上,何时发生什么错误。
最聪明的是,所有存储系统的并行轮询的整个周期不是30分钟,而是30秒 。
感谢上帝,这不是30秒过快的情况。

值得澄清的是, PowerShell代码还周期性地收集了所有存储系统的磁盘序列号,并且在R上重写代码时,此数据是多余的。 因此,运行时比较并不完全是诚实的,但仍然令人印象深刻。
xlsx文档的数据转换减少为在最近3天以及最后一个月过滤源表,并将带有错误名称的列转换为“水平”格式,以便每种错误类型都在单独的列中。 为此编写了一个单独的函数(以免重复相同的步骤2次)
源过滤功能 myErrorStats <- function(data, period, orderColname = quo(Soft_Media_Error)) { data %>% filter(Date > period) %>% group_by(cl, Storage, Disk, Error) %>% summarise(count = n()) %>% spread(Error, count, fill = 0) %>% arrange(desc(!!orderColname)) }
为了在单独的列中显示错误的类型,使用附加键fill = 0来应用散布函数,将缺失值填充为0 。 如果没有此键,则如果某天没有某种错误,则相应的列将具有NA值。
另外,在该函数中,我想保留传递列名作为变量进行排序的功能,但同时具有该变量的默认值。 为此,使用了特殊的语法dplyr ,有关更多信息,请参见 此处 。
在我们的例子中,当定义一个函数的参数时,我们将其中一个设置为默认值并引用它( orderColname = quo(Soft_Media_Error) ),然后在被调用时将字符放在其前面! 获得安排(desc(!! orderColname)) 。
我在有关VM状态报告的文章中分析了xlsx文档的形成,因此我将不作详细介绍。 所有代码均在文章末尾给出。

以下是可增强报告可读性的重要功能:
- 签名标签(默认情况下最有趣的是打开);
- 突出显示的列名
- 自动格式化所有列,以便无需扩展列即可读取所有文本。
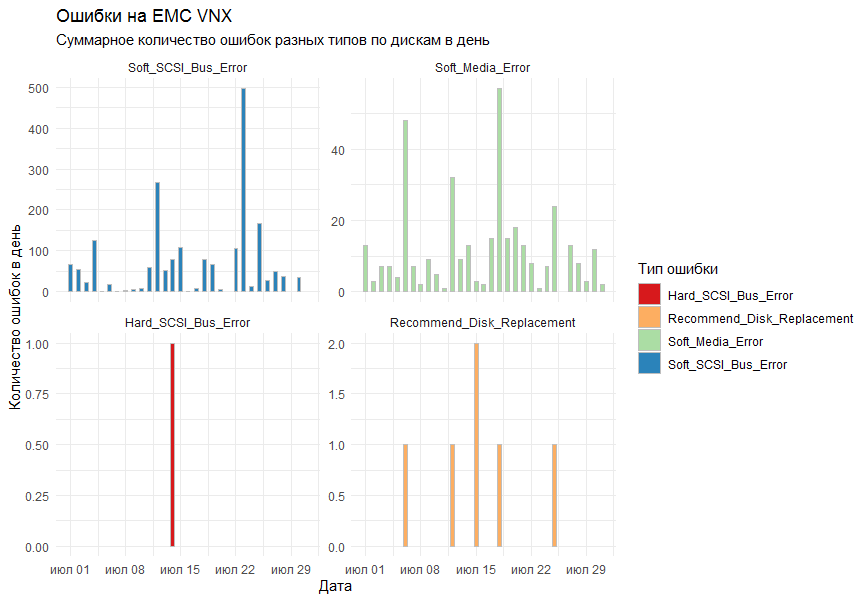
在图上,我想按类型获取所有存储系统每天的错误总数。 作为绘图工具,决定使用标准的ggplot2库。
该图的第一个版本在一个图上显示了所有错误,看起来像这样:

同事们说,结果令人难以理解。
他们会明白什么?
考虑了这些注释,并将facet_grid函数添加到标准列( geom_bar ),以根据错误类型将结果划分为单独的图形。
最终结果适合所有人。

从有趣的时间表中形成。
我希望图表按一定顺序排列。 为此,必须将在facet_grid中形成行的参数作为一个因素甚至是一个有序因素来传递。 因子就是R中一种如此狡猾的数据格式,它是一组值(在我们的示例中是字符串,即字符 ),并且严格定义了这些值的集(称为因子级别),甚至这些级别也已排序。 听起来很复杂,但是如果您说月份的名称是有序因素的一个很好的例子,那么一切都就位了。 即 我们知道几个月可以有什么名字,我们也知道(好吧,我希望)首先是一月,然后是二月,然后是三月,等等。 我们以同样的原则创造一个因素。
关于VM状态报告的文章中也考虑了字母的形成和发送以及Windows scheduller中任务的形成。 我们只需将一些变量放入文本中,或多或少地将其格式化。 不要忘记附件。
结论
R再次被证明是执行日常任务并可视化其结果的通用工具。 启用并行计算后,此工具也将变得快速。
实践还表明, PowerShell在解析日志并将其转换为可读格式方面极其缓慢。
非常感谢大家读了这么多结尾的信。
完整的应用程序代码
- : EMC VNX 5300
- : NaviCLI-Win-32-x86-en_US-7.31.25.1.29-1
- , : 4*2 CPU, 8 Gb RAM
R > sessionInfo() R version 3.5.3 (2019-03-11) Platform: x86_64-w64-mingw32/x64 (64-bit) Running under: Windows Server 2012 R2 x64 (build 9600) Matrix products: default locale: [1] LC_COLLATE=Russian_Russia.1251 LC_CTYPE=Russian_Russia.1251 LC_MONETARY=Russian_Russia.1251 [4] LC_NUMERIC=C LC_TIME=Russian_Russia.1251 attached base packages: [1] parallel stats graphics grDevices utils datasets methods base other attached packages: [1] taskscheduleR_1.4 pander_0.6.3 doParallel_1.0.14 iterators_1.0.10 foreach_1.4.4 mailR_0.4.1 [7] xlsx_0.6.1 stringi_1.4.3 zoo_1.8-6 lubridate_1.7.4 wesanderson_0.3.6 forcats_0.4.0 [13] stringr_1.4.0 dplyr_0.8.3 purrr_0.3.2 readr_1.3.1 tidyr_0.8.3 tibble_2.1.3 [19] ggplot2_3.2.0 tidyverse_1.2.1 loaded via a namespace (and not attached): [1] tidyselect_0.2.5 reshape2_1.4.3 rJava_0.9-11 haven_2.1.1 lattice_0.20-38 colorspace_1.4-1 [7] vctrs_0.2.0 generics_0.0.2 utf8_1.1.4 rlang_0.4.0 R.oo_1.22.0 pillar_1.4.2 [13] glue_1.3.1 withr_2.1.2 R.utils_2.9.0 RColorBrewer_1.1-2 modelr_0.1.4 readxl_1.3.1 [19] plyr_1.8.4 munsell_0.5.0 gtable_0.3.0 cellranger_1.1.0 rvest_0.3.4 R.methodsS3_1.7.1 [25] codetools_0.2-16 labeling_0.3 fansi_0.4.0 xlsxjars_0.6.1 broom_0.5.2 Rcpp_1.0.1 [31] scales_1.0.0 backports_1.1.4 jsonlite_1.6 digest_0.6.20 hms_0.5.0 grid_3.5.3 [37] cli_1.1.0 tools_3.5.3 magrittr_1.5 lazyeval_0.2.2 crayon_1.3.4 pkgconfig_2.0.2 [43] zeallot_0.1.0 data.table_1.12.2 xml2_1.2.0 assertthat_0.2.1 httr_1.4.0 rstudioapi_0.10 [49] R6_2.4.0 nlme_3.1-137 compiler_3.5.3