在大型云系统中,自动平衡或平衡计算资源负载的问题尤为严重。 Tionics还解决了这个问题(云服务的开发者和运营商,我们是Rostelecom集团公司的一部分)。
而且,由于我们的主要开发平台是Openstack,而且我们和所有人一样都很懒惰,因此决定选择某种已经成为平台一部分的现成模块。 我们的选择取决于Watcher,我们决定将其用于我们的需求。

首先,让我们处理术语和定义。
术语和定义
目标是必须实现的人类可读,可观察和可测量的最终结果。 为了实现每个目标,有一个或多个策略。 策略是算法的一种实现,能够为此找到解决方案。
动作是一项基本任务,它会更改OpenStack集群的目标托管资源的当前状态,例如:迁移虚拟机(迁移),更改节点电源的状态(change_node_power_state),更改nova服务的状态(change_nova_service_state),更改样式(调整大小)。 ,注册NOP消息(nop),在一定时间长度内不执行任何操作-暂停(睡眠),磁盘传输(volume_migrate)。
行动计划(Action Plan) -以特定顺序执行以实现特定目标的特定行动流。 该行动计划还包含估计的全球绩效以及一系列绩效指标。 行动计划是由Watcher在成功审核期间生成的,因此,所使用的策略可以找到实现目标的解决方案。 行动计划由一系列连续行动组成。
审计是对集群优化的要求。 为了实现给定群集中的一个目标,执行了优化。 对于每次成功的审核,Watcher都会生成一个行动计划。
审核范围是在其中执行审核的一组资源(可用区,节点聚合器,单个计算节点或存储节点等)。 在每个模板中定义了审核范围。 如果未指定审核范围,则将审核整个群集。
审核模板 -保存的一组设置,用于开始审核。 需要模板才能多次使用相同的设置运行审核。 模板必须包含审核的目的,如果未指定策略,则选择最合适的现有策略。
群集是一组物理计算机,它们提供计算,存储和网络资源,并由同一OpenStack控制节点进行管理。
群集数据模型(CDM)是群集管理资源的当前状态和拓扑的逻辑表示。
效率指标(效率指标) -指示如何实施使用此策略创建的解决方案的指标。 绩效指标是特定于特定目标的,通常用于计算最终行动计划的整体有效性。
功效规范是与每个目标相关的一组特定功能,它定义了确保实现相应目标的策略应在其决策中提供的各种绩效指标。 实际上,将在计算策略整体有效性之前检查该策略提出的每个解决方案是否符合规范。
“评分引擎”是具有明确定义的输入数据,明确定义的输出数据并执行纯数学任务的可执行文件。 因此,该计算不依赖于执行该计算的环境-它将在任何地方给出相同的结果。
Watcher Planner是Watcher决策引擎的一部分。 该模块接受该策略生成的一组动作,并创建一个工作流计划,该计划定义如何及时计划这些各种动作,对于每个动作,先决条件是什么。
观察者目标和策略
虚拟目标 -用于测试目的的备用目标。
相关策略:虚拟策略,使用示例评分引擎的虚拟策略和具有调整大小的虚拟策略。 虚拟策略是通过Tempest进行集成测试的虚拟策略。 该策略没有提供任何有用的优化;其唯一目的是使用Tempest测试。
使用样本评分引擎的虚拟策略-该策略与先前的策略相似,仅在“评估引擎”样本的使用方面有所不同,后者使用机器学习方法进行计数。
具有调整大小的虚拟策略-该策略与上一个策略类似,仅在更改风味(迁移和调整大小)的用法上有所不同。
未在生产中使用。
节约能源 -减少能耗。 节能策略与VM工作负载合并策略(服务器合并)一起能够执行动态电源管理(DPM)功能,即使在资源负荷较低的情况下,该功能也可以通过动态整合工作负载来节省能源:虚拟机转移到更少的节点上,不必要的节点将断开连接。 合并后,该策略将决定根据给定的参数打开/关闭节点:“ min_free_hosts_num”-等待负载的空闲包含的节点数,“ free_used_percent”-空闲包含的节点占计算机所占节点数的百分比。 为了使该策略
起作用,必须
打开Ironic并将其配置为在节点上打开/关闭电源的情况下工作。策略选择
云中必须至少有两个节点。 所使用的方法是更改节点的电源状态(change_node_power_state)。
策略不需要收集指标。服务器整合-最小化计算节点的数量(整合)。 它有两个策略:基本脱机服务器合并和VM工作负载合并策略。
基本脱机服务器合并策略可最大程度地减少使用的服务器总数,并最大程度减少迁移次数。
基本策略需要以下指标:
策略参数:migration_attempts-搜索潜在关闭候选对象的组合数(默认值,0,无限制),period-从度量标准数据源获取静态聚合的时间间隔(以秒为单位)(默认值为700)。
使用的方法:迁移,新星服务状态更改(change_nova_service_state)。
VM Workload Consolidation策略基于“最适合的启发式”算法,该算法专注于测得的CPU负载,并考虑到资源容量限制,尝试最小化负载过多或过少的节点。 此策略提供了一种解决方案,可通过以下四个步骤来更有效地利用群集资源:
- 卸载阶段-处理过度使用的资源;
- 合并阶段-处理未充分利用的资源;
- 解决方案优化-减少迁移数量;
- 禁用未使用的计算节点。
该策略需要以下指标:
以下指标是可选的,但可以提高策略的准确性(如果有):
策略参数:period-从度量标准数据源获得静态聚合的时间间隔(以秒为单位)(默认为3600)。
使用与先前策略相同的方法。 更多细节
在这里 。
工作负载平衡 -平衡计算节点之间的工作负载。 该目标具有三个策略:工作负载平衡迁移策略,工作负载稳定,存储容量平衡策略。
工作负载平衡迁移策略根据主机虚拟机的工作负载启动虚拟机迁移。 每当节点的CPU或RAM利用率百分比超过指定的阈值时,就做出传输决定。 在这种情况下,移动的虚拟机应使节点更接近所有节点的平均工作负载。
要求条件
- 使用物理处理器;
- 至少两个物理计算节点;
- 安装并配置的Ceilometer组件是在每个计算节点上运行的ceilometer-agent-compute和Ceilometer API,并收集以下指标:
策略选项:
使用的方法是迁移。
工作负载稳定-一种旨在通过实时迁移来稳定工作负载的策略。 该策略基于标准偏差算法,确定集群中是否存在拥塞,并通过触发机器迁移来稳定集群来对此做出响应。
要求条件
- 使用物理处理器;
- 至少两个物理计算节点;
- 安装并配置的Ceilometer组件是在每个计算节点上运行的ceilometer-agent-compute和Ceilometer API,并收集以下指标:
存储容量平衡策略(自皇后区开始实施的策略)-该策略根据Cinder池的负载来传输磁盘。 只要池利用率超过指定的阈值,就做出转移决定。 漫游磁盘应使池接近所有Cinder池的平均负载。
要求与限制
- 至少两个煤渣池;
- 能够迁移磁盘。
- 集群数据模型收集器。
策略选项:
使用的方法是磁盘迁移(volume_migrate)。
嘈杂邻居-识别并迁移“嘈杂邻居”-一种低优先级虚拟机,从IPC角度来看,这会严重影响高优先级虚拟机的性能,并过度使用最后一级缓存。 自己的策略:嘈杂的邻居(使用的策略参数为cache_threshold(默认值为35),当性能下降到指定值时开始迁移。为使该策略起作用,包括了
LLC(上级缓存)指标, 最新的具有CMT支持的Intel服务器 ,以及收集以下指标:
群集数据模型(默认):Nova群集数据模型收集器。 应用的方法是迁移。
通过仪表板实现此目的的工作在Queens中尚未完全实现。
热优化 -优化温度条件。 出口温度(排气)是测量服务器热/工作量状态的重要热遥测系统之一。 为此,有一种策略-基于出口温度的策略,当原始主机的输出温度达到自定义阈值时,该决策将工作负载转移到具有良好温度条件(出口处的最低温度)的节点。
为使该策略生效,您需要一台服务器并安装并安装了Intel Power Node Manager
3.0或更高版本 ,并且需要收集以下指标:
策略选项:
使用的方法是迁移。
气流优化 -优化通风模式。 自己的策略-使用实时迁移实现统一气流。 每当来自服务器风扇的气流超过指定的阈值时,该策略便开始迁移虚拟机。
要运作,该策略需要:
- 硬件:<具有NodeManager 3.0支持的计算节点;
- 至少两个计算节点;
- 在每个计算节点上安装和配置的ceilometer-agent-compute和Ceilometer API组件可以成功报告指标,例如空气流量,系统功率和入口温度:
为使该策略生效,您需要安装和配置了Intel Power Node Manager 3.0或更高版本的服务器。
局限性:该概念不适用于生产。
由于每次迭代计划仅迁移一个虚拟机,因此建议将此算法与连续审核一起使用。
可以进行实时迁移。
策略选项:
使用的方法是迁移。
硬件维护 -硬件维护。 与该目标相关的策略是区域迁移。 该策略是在硬件维护的情况下有效地自动最小化虚拟机和磁盘迁移的工具。 该策略根据权重建立一个行动计划:将在其他行动之前计划一组具有更大权重的行动。 有两个配置选项:操作权重(action_weights)和并行化。
局限性:有必要调整动作和并行化的权重。
策略选项:
计算节点数组的元素:
存储节点数组的元素:
优先对象的元素:
使用的方法-虚拟机迁移,磁盘迁移。
未分类是用于促进策略制定的辅助目标。 它不包含规范,并且只要该策略尚未与现有目标关联就可以使用。 这个目标也可以用作过渡阶段。 相关策略是执行器。
创建一个新目标
Watcher Decision Engine具有“外部目标”插件界面,可让您集成可以使用策略实现的外部目标。
在创建新目标之前,您应确保现有目标均不满足您的需求。
创建一个新的插件
要创建新目标,您必须:扩展目标类,实现
get_name()类方法以为要创建的新目标返回唯一标识符。 此唯一标识符必须与您稍后声明的入口点的名称匹配。
接下来,您需要实现类方法
get_display_name()以返回要创建的目标的翻译后的显示名称(不要使用该变量返回翻译后的字符串,以便翻译工具可以自动收集该字符串)。
实现
get_translatable_display_name()类方法以返回新目标的翻译键(实际上是英文显示名称)。 返回值必须与转换为get_display_name()的字符串匹配。
实现其
get_efficacy_specification()方法以返回性能规格供您使用。 get_efficacy_specification()方法返回Watcher提供的Unclassified()实例。 此性能规格在制定目标的过程中很有用,因为它符合空的规格。
→
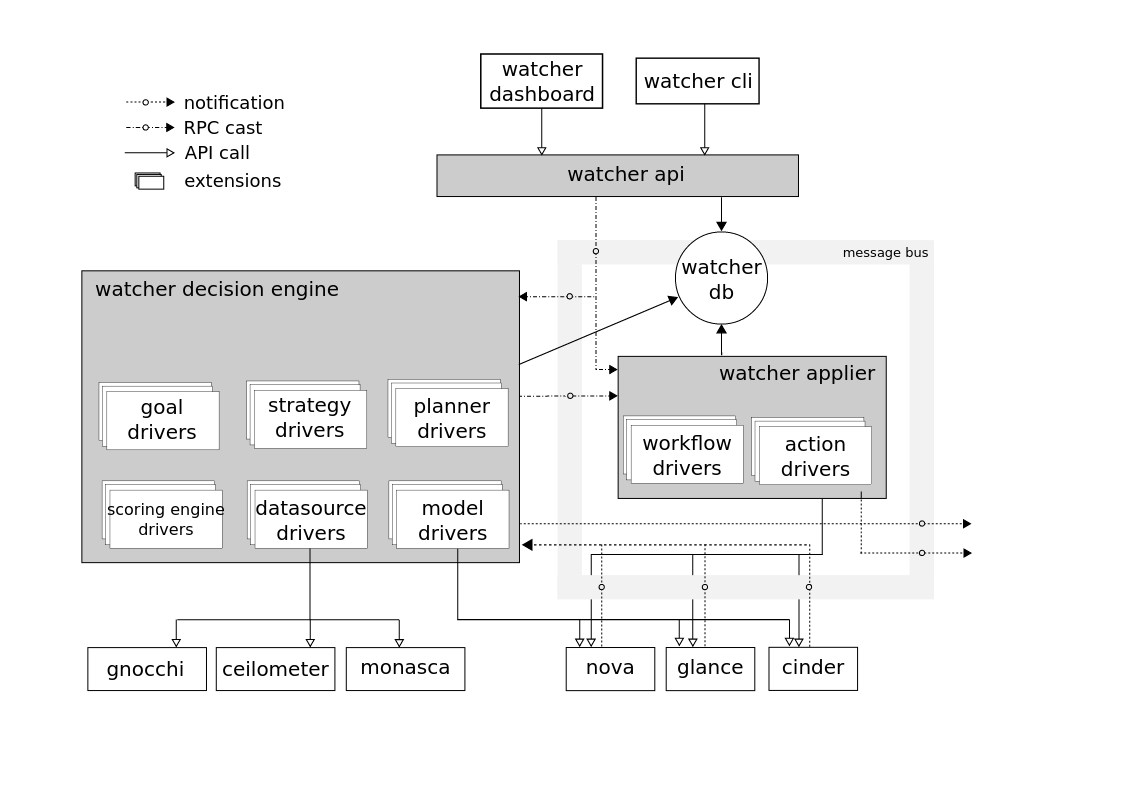
此处有更多详细信息体系结构观察器(更多信息
在此处 )。
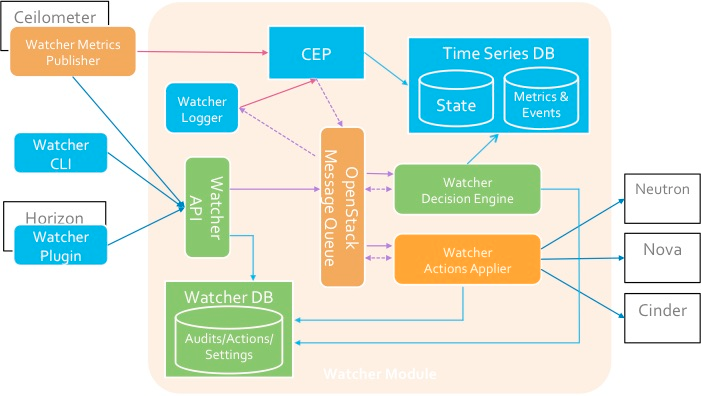
组成部分
 Watcher API-
Watcher API-实现Watcher提供的REST API的组件。 交互机制:CLI,Horizon插件,Python SDK。
Watcher DB -Watcher数据库。
Watcher Applier-观察者决策者创建的行动计划的实施组件。Watcher Decision Engine是负责计算一组可能的优化操作以实现审核目标的组件。如果未指定策略,则组件将独立选择最合适的策略。Watcher Metrics Publisher是一个收集和计算某些度量标准或事件并将其发布到CEP端点的组件。功能功能也可以由Ceilometer发行商提供。复杂事件处理(CEP)引擎-用于复杂事件处理的引擎。出于性能方面的考虑,CEP引擎可能同时运行多个实例,每个实例都处理一种特定类型的度量标准/事件。在Watcher系统中,CEP启动两种类型的操作:-将相应的事件/指标写入时间序列数据库;-由于Openstack集群不是静态系统,因此当此事件可能影响当前优化策略的结果时,将相关事件发送给Watcher Decision Engine组件。组件的交互是根据AMQP协议执行的。→ 配置观察器与Watcher的交互方案

观察者测试结果
- Optimization — Action plans 500 ( Queens, ), , , .
- Action details , ( Queens, ).
- Dummy () , .
- Unclassified , .
- Workload Balancing ( Storage Capacity balance) , . .
- Workload Balancing ( Workload Balance Migration Strategy) , .
- Workload Balancing ( Workload Stabilization Strategy) .
- Noisy Neighbor , .
- Hardware maintenance , ( , ).
- nova.conf ( default compute_monitors = cpu.virt_driver) .
- Server Consolidation ( Basic) .
- Server Consolidation ( VM workload consolidation) . . , , .
- Watcher ( — Optimization, - ):
[watcher_strategies.basic]
datasource = ceilometer, gnocchi - Saving Energy . , - Ironic, baremetal service.
- Thermal Optimization . , Server Consolidation ( VM workload consolidation) ( )
- 气流优化审核失败。
还遇到以下审核完成错误。Decision-engine.log日志中的回溯(未定义集群状态)。→在这里讨论错误结论
我们进行了为期两个月的研究,得出了明确的结论:为了获得功能完善的工作负载平衡系统,我们必须紧密合作才能最终确定Openstack平台的工具。Watcher已证明自己是一个严肃且迅速发展的产品,具有巨大的潜力,要充分利用它,将需要进行大量认真的工作。但是,在本周期的下一篇文章中会更多地介绍这一点。