数据的收集,存储,转换和表示是数据工程师面临的主要挑战。 Badoo商业智能部门每天接收和处理从用户设备发送的超过200亿个事件,即2 TB的传入数据。
对所有这些数据的研究和解释并不总是一件容易的事,有时需要超越现成数据库的能力。 并且,如果您有勇气并决定做一些新的事情,那么您首先应该熟悉现有解决方案的工作原理。
简而言之,本文介绍了好奇心强的开发人员。 在其中,您将以演示语言PigletQL为例,对关系数据库中传统查询执行模型进行描述。
目录内容
背景知识
我们的工程师团队致力于后端和接口,为公司内部数据的分析和研究提供了机会(顺便说一下,我们正在扩展 )。 我们的标准工具是一个包含数十个服务器的分布式数据库(Exasol)和一个用于数百台机器(Hive和Presto)的Hadoop集群。
这些数据库的大多数查询都是分析性的,也就是说,影响了数十万至数十亿条记录。 根据所使用的解决方案和请求的复杂性,它们的执行需要几分钟,几十分钟甚至几小时。 使用用户分析器的手动工作,这样的时间被认为是可以接受的,但不适合通过用户界面进行交互式研究。
随着时间的流逝,我们重点介绍了流行的分析查询和难以用 SQL 列出的查询,并为它们开发了小型专用数据库。 它们以适合轻量级压缩算法的格式(例如streamvbyte)存储数据的子集,这使您可以将数据在一台计算机中存储几天,并在几秒钟内执行查询。
对这些数据及其解释器的第一种查询语言是凭直觉实现的,我们不得不不断地对其进行改进,并且每次花费的时间都是无法接受的。
尽管没有明显的理由限制查询语言的功能,但查询语言还不够灵活。 结果,我们求助于SQL解释器开发人员的经验,从而使我们能够部分解决出现的问题。
下面,我将讨论关系数据库中最常见的查询执行模型-Volcano。 本文附带了原始SQL方言解释器的源代码PigletQL ,因此,所有感兴趣的人都可以轻松了解存储库中的详细信息。
SQL解释器结构
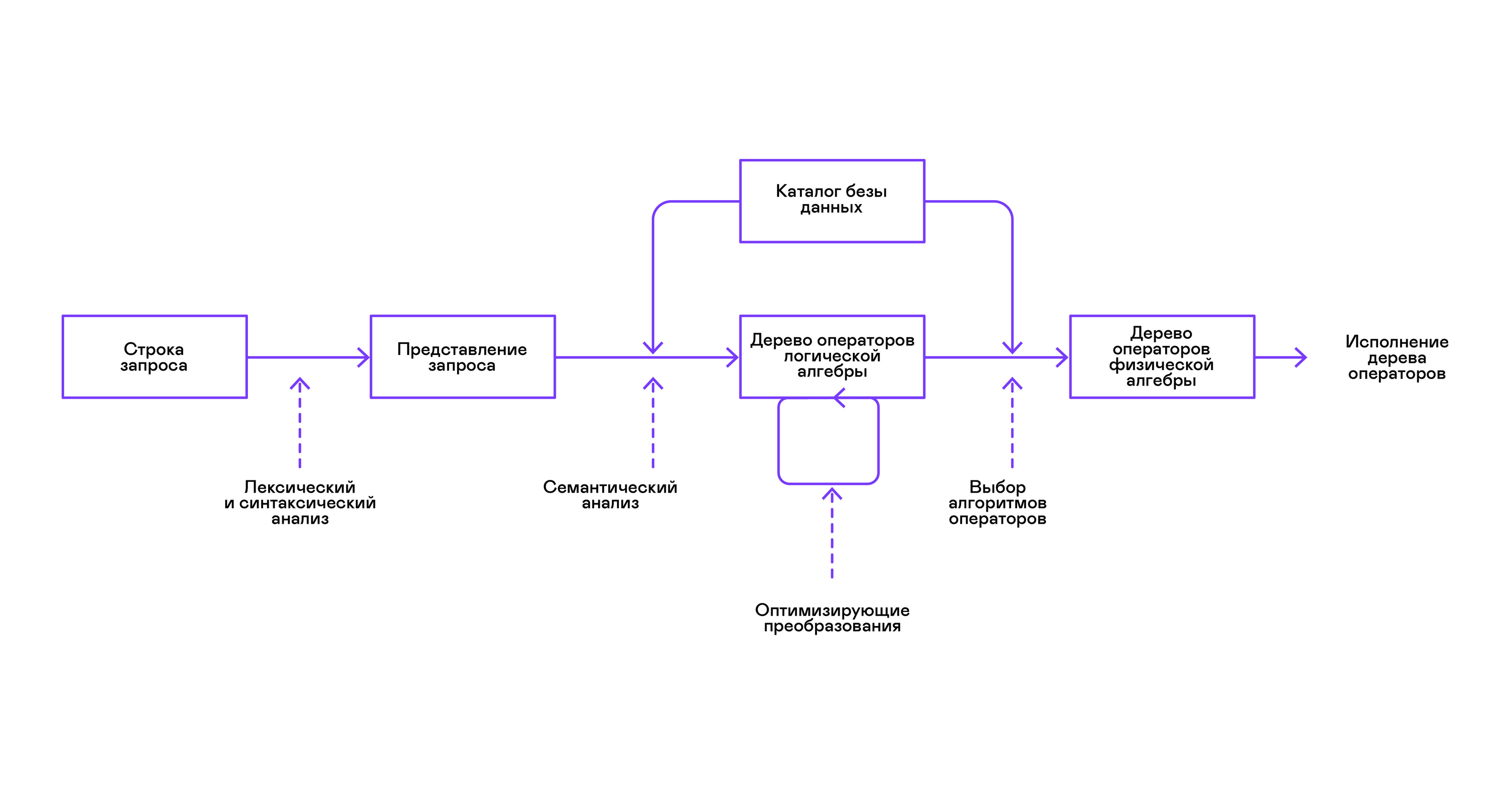
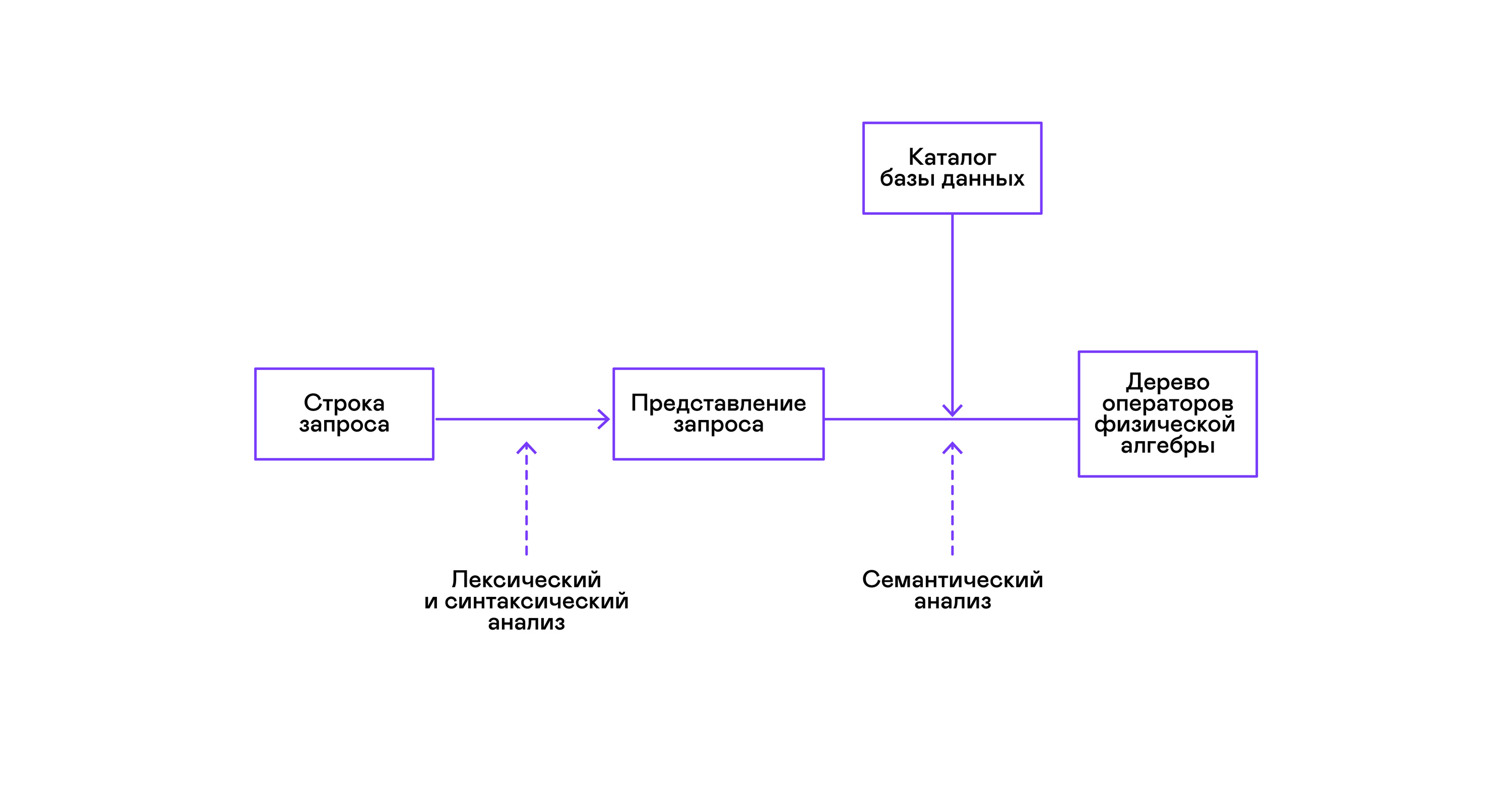
大多数流行的数据库以声明性SQL查询语言的形式提供数据接口。 解析器将字符串形式的查询转换为查询的描述,类似于抽象语法树。 在此阶段可能已经执行了简单的查询,但是,为了优化转换和后续执行,此表示很不方便。 在我所知道的数据库中,出于这些目的引入了中间表示。
关系代数成为中间表示的模型。 这是一种语言,其中明确描述了对数据执行的转换( 运算符 ):根据谓词选择数据的子集,组合来自不同来源的数据等。此外,关系代数是数学意义上的代数,即,大量等价的代数转变。 因此,方便的是以关系代数运算符树的形式对查询执行优化转换。
数据库中的内部表示形式与原始关系代数之间存在重要的区别,因此将其称为逻辑代数更为正确。
查询的验证通常在将查询的初始表示编译为逻辑代数运算符时执行,并且对应于常规编译器中的语义分析阶段。 符号表在数据库中的角色由数据库目录扮演, 该目录存储有关数据库模式和元数据的信息:表,表列,索引,用户权限等。
与通用解释器相比,数据库解释器具有更多的特点:数据量的差异和有关应该进行查询的数据的元信息。 在表中,或在关系代数方面的关系中,可以有不同数量的数据,可以在某些列(关系属性 )上建立索引,等等。也就是说,根据数据库模式和表中的数据量,查询必须由不同的算法执行,并以不同的顺序使用它们。
为了解决这个问题,引入了另一种中间表示形式- 物理代数 。 根据列上索引的可用性,表中的数据量以及逻辑代数树的结构,提供物理代数树的不同形式,从中选择最佳选择。 这棵树作为查询计划显示在数据库中。 在常规编译器中,此阶段有条件地对应于寄存器分配,计划和指令选择的阶段。
解释器工作的最后一步是直接执行物理代数运算符树。
火山模型和查询执行
物理代数树解释器一直在封闭的商业数据库中使用,但是学术文献通常引用90年代初期开发的实验性优化器Volcano。
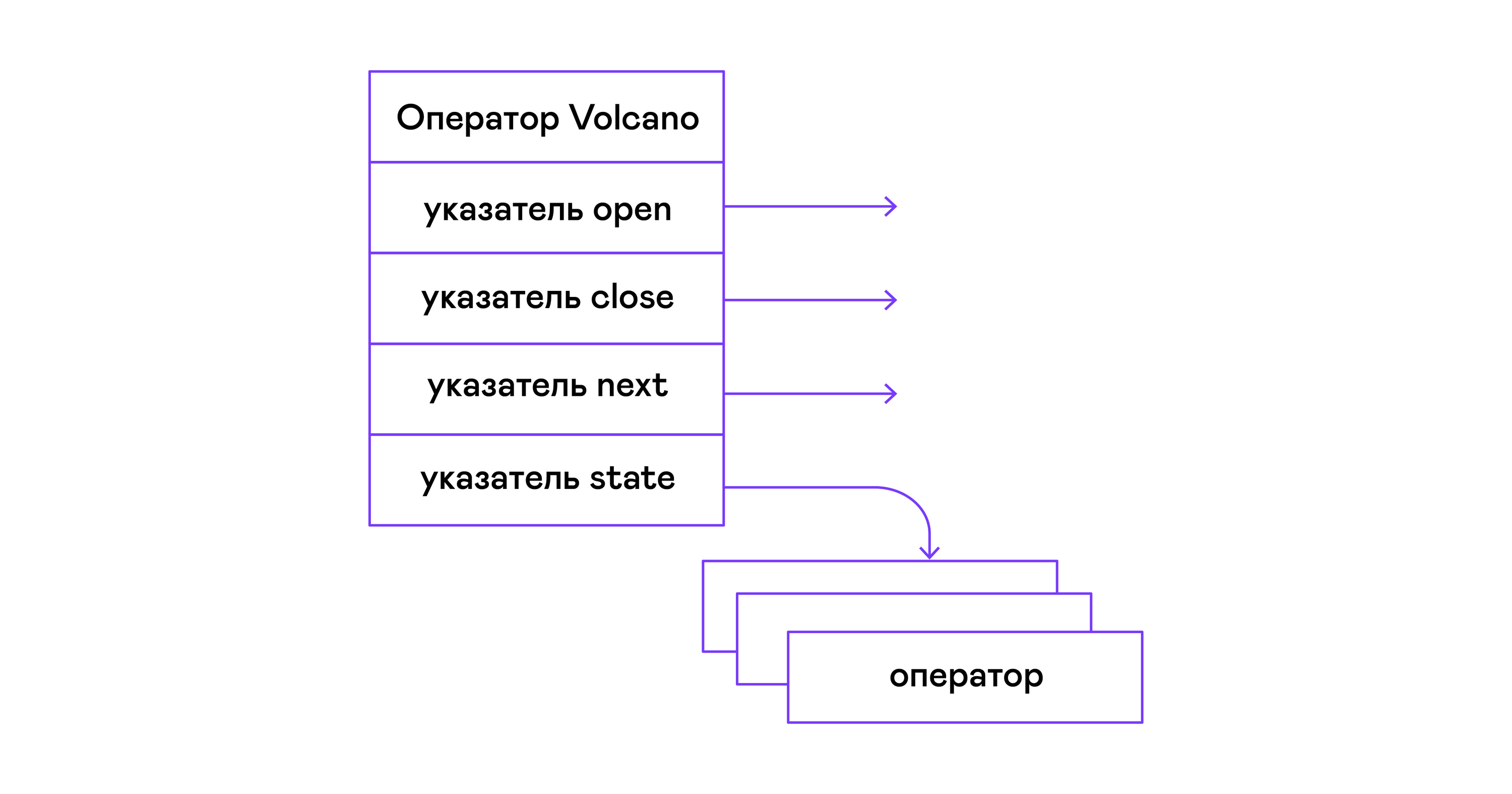
在Volcano模型中,物理代数树的每个算子都变成具有三个功能的结构:打开,下一个,关闭。 除功能外,操作员还包含一个操作状态-状态。 open函数启动语句的状态,next函数返回下一个元组 (英语元组)或NULL,如果没有元组,则close函数终止该语句:
运算符可以嵌套以形成物理代数运算符的树。 因此,每个运算符都遍历存在于实际介质上的关系的元组或通过枚举嵌套运算符的元组而形成的虚拟关系的元组:
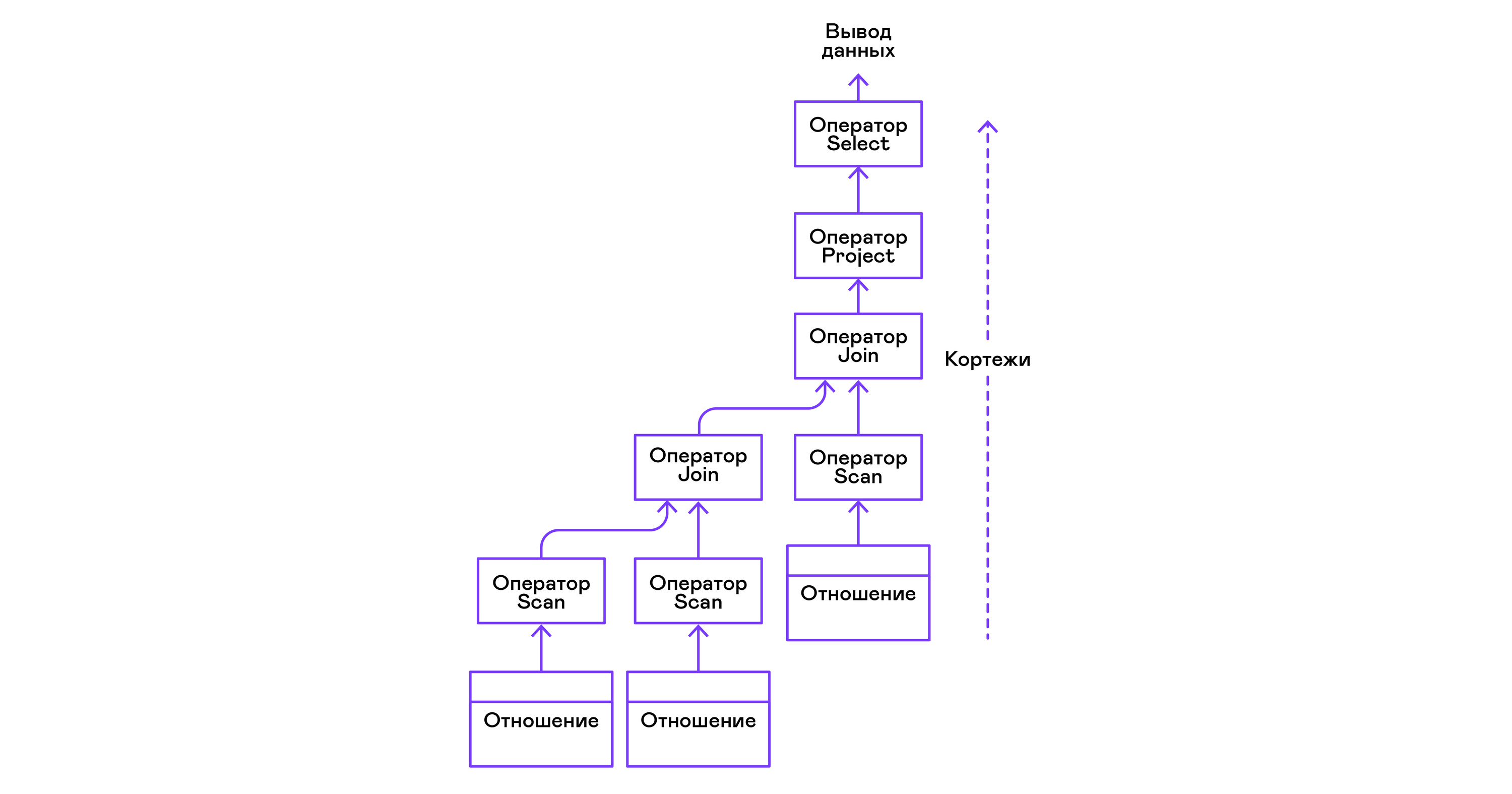
在现代高级语言方面,此类运算符的树是迭代器的级联。
关系数据库管理系统中的甚至工业查询解释器都被Volcano模型拒斥,这就是为什么我将其作为PigletQL解释器的基础。
仔猪QL
为了演示该模型,我开发了受限查询语言PigletQL的解释器。 它用C语言编写,支持以SQL样式创建表,但仅限于单一类型-32位正整数。 所有表都在内存中。 该系统在单线程中运行,并且没有事务处理机制。
PigletQL中没有优化器,并且SELECT查询直接编译为物理代数的运算符树。 其余查询(CREATE TABLE和INSERT)直接在主内部视图中工作。
PigletQL中的示例用户会话:
> ./pigletql > CREATE TABLE tab1 (col1,col2,col3); > INSERT INTO tab1 VALUES (1,2,3); > INSERT INTO tab1 VALUES (4,5,6); > SELECT col1,col2,col3 FROM tab1; col1 col2 col3 1 2 3 4 5 6 rows: 2 > SELECT col1 FROM tab1 ORDER BY col1 DESC; col1 4 1 rows: 2
词法分析器
PigletQL是一种非常简单的语言,在词法分析和语法分析阶段不需要其实现。
词法分析器是用手写的。 根据查询字符串创建一个分析器对象( Scanner_t ),它逐个给出令牌:
scanner_t *scanner_create(const char *string); void scanner_destroy(scanner_t *scanner); token_t scanner_next(scanner_t *scanner);
使用递归下降方法进行解析。 首先, 创建parser_t对象,该对象接收到词法分析器(scanner_t)后,将有关请求的信息填充到query_t对象中:
query_t *query_create(void); void query_destroy(query_t *query); parser_t *parser_create(void); void parser_destroy(parser_t *parser); bool parser_parse(parser_t *parser, scanner_t *scanner, query_t *query);
query_t中的解析结果是PigletQL支持的三种查询类型之一:
typedef enum query_tag { QUERY_SELECT, QUERY_CREATE_TABLE, QUERY_INSERT, } query_tag; typedef struct query_t { query_tag tag; union { query_select_t select; query_create_table_t create_table; query_insert_t insert; } as; } query_t;
PigletQL中最复杂的查询类型是SELECT。 它对应于query_select_t数据结构 :
typedef struct query_select_t { attr_name_t attr_names[MAX_ATTR_NUM]; uint16_t attr_num; rel_name_t rel_names[MAX_REL_NUM]; uint16_t rel_num; query_predicate_t predicates[MAX_PRED_NUM]; uint16_t pred_num; bool has_order; attr_name_t order_by_attr; sort_order_t order_type; } query_select_t;
该结构包含查询的描述(用户请求的属性数组),数据源列表(关系),谓词过滤元组数组以及有关用于对结果进行排序的属性的信息。
语义分析器
常规SQL的语义分析阶段涉及检查列出的表,表中的列是否存在以及查询表达式中的类型检查。 对于与表和列相关的检查,使用数据库目录,其中存储了有关数据结构的所有信息。
PigletQL中没有复杂的表达式,因此查询检查简化为检查表和列的目录元数据。 例如,SELECT查询通过validate_select函数进行验证 。 我将以缩写形式提出:
static bool validate_select(catalogue_t *cat, const query_select_t *query) { for (size_t rel_i = 0; rel_i < query->rel_num; rel_i++) { if (catalogue_get_relation(cat, query->rel_names[rel_i])) continue; fprintf(stderr, "Error: relation '%s' does not exist\n", query->rel_names[rel_i]); return false; } if (!rel_names_unique(query->rel_names, query->rel_num)) return false; if (!attr_names_unique(query->attr_names, query->attr_num)) return false; return true; }
如果请求有效,则下一步是将解析树编译为运算符树。
将查询编译为中间视图
在成熟的SQL解释器中,通常有两种中间表示形式:逻辑代数和物理代数。
一个简单的PigletQL解释器直接从其解析树(即query_create_table_t和query_insert_t结构)执行CREATE TABLE和INSERT查询。 更为复杂的SELECT查询被编译为单个中间表示形式,该中间表示形式将由解释器执行。
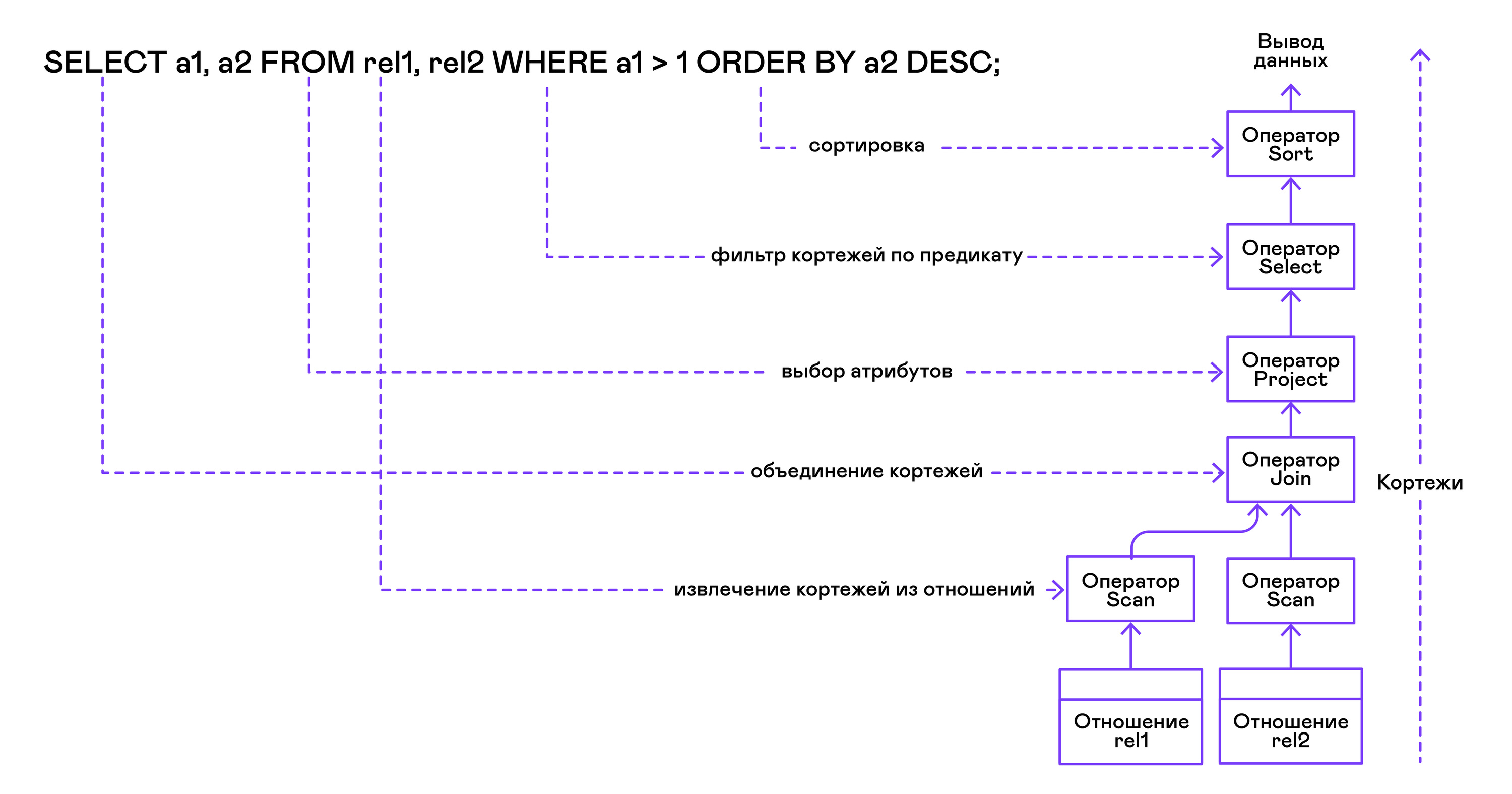
运算符树从叶到根按以下顺序构建:
从查询的右侧(“ ... FROM Relation1,Relation2,...”),获得所需关系的名称,并为每个关系创建一个扫描语句。
从关系中提取元组,扫描运算符通过join运算符组合成左侧的二叉树。
用户要求的属性(“ SELECT attr1,attr2,...”)由project语句选择。
如果指定了任何谓词(“ ... WHERE a = 1 AND b> 10 ...”),则将select语句添加到上面的树中。
如果指定了对结果进行排序的方法(“ ... ORDER BY attr1 DESC”),则将排序运算符添加到树的顶部。
PigletQL 代码中的编译:
operator_t *compile_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = NULL; { size_t rel_i = 0; relation_t *rel = catalogue_get_relation(cat, query->rel_names[rel_i]); root_op = scan_op_create(rel); rel_i += 1; for (; rel_i < query->rel_num; rel_i++) { rel = catalogue_get_relation(cat, query->rel_names[rel_i]); operator_t *scan_op = scan_op_create(rel); root_op = join_op_create(root_op, scan_op); } } root_op = proj_op_create(root_op, query->attr_names, query->attr_num); if (query->pred_num > 0) { operator_t *select_op = select_op_create(root_op); for (size_t pred_i = 0; pred_i < query->pred_num; pred_i++) { query_predicate_t predicate = query->predicates[pred_i]; } root_op = select_op; } if (query->has_order) root_op = sort_op_create(root_op, query->order_by_attr, query->order_type); return root_op; }
树形成后,通常会执行优化转换,但是PigletQL立即进入中间表示的执行阶段。
执行临时陈述
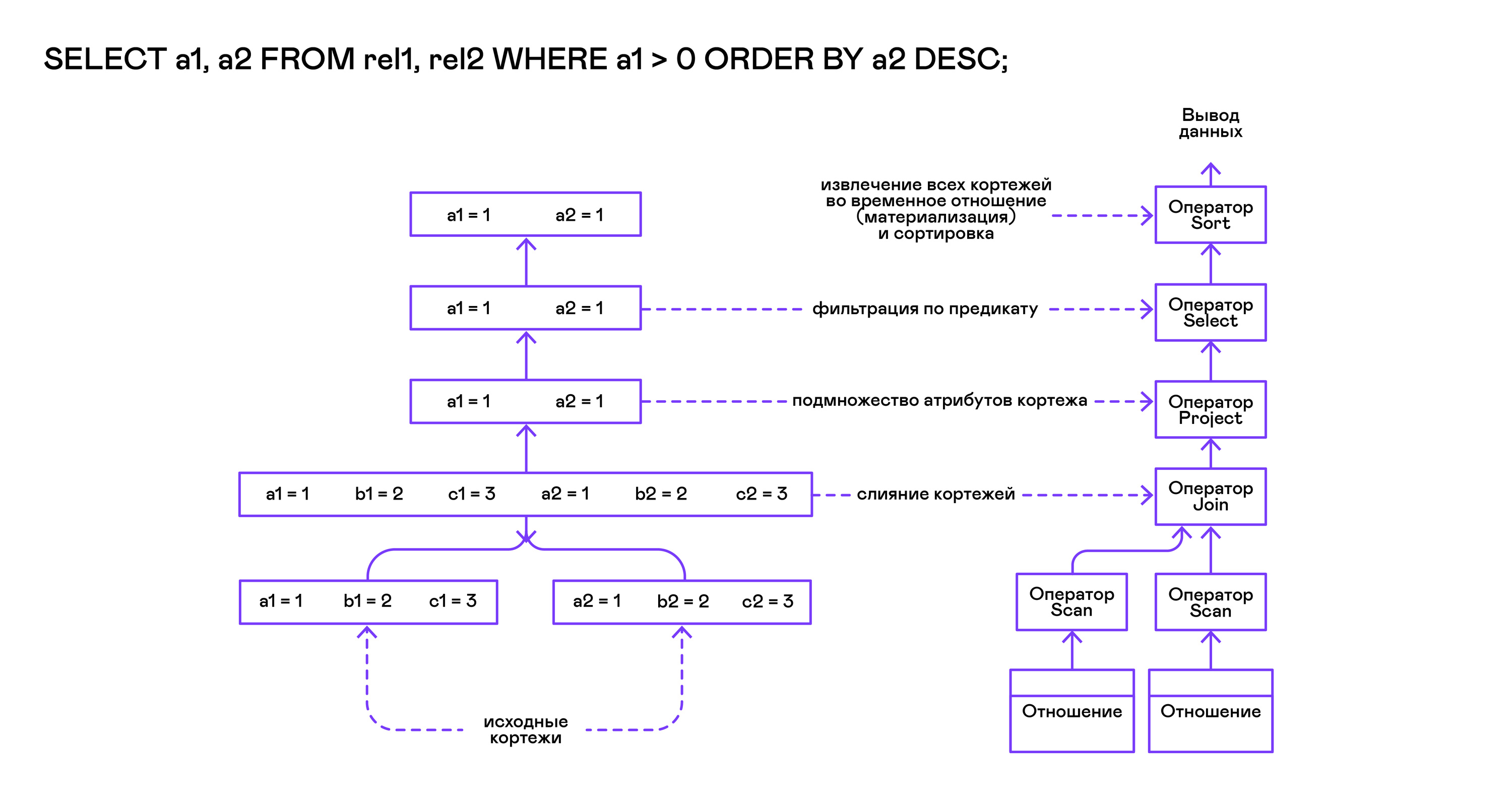
火山模型暗示了通过三个常见的打开/下一个/关闭操作与操作员进行交互的界面。 从本质上讲,每个Volcano语句都是一个迭代器,从该迭代器中元组被一个一个地“拖拉”,因此这种执行方法也称为拉模型。
这些迭代器中的每一个自身都可以调用嵌套迭代器的相同函数,创建具有中间结果的临时表,并转换传入的元组。
在PigletQL中执行SELECT查询 :
bool eval_select(catalogue_t *cat, const query_select_t *query) { operator_t *root_op = compile_select(cat, query); { root_op->open(root_op->state); size_t tuples_received = 0; tuple_t *tuple = NULL; while((tuple = root_op->next(root_op->state))) { if (tuples_received == 0) dump_tuple_header(tuple); dump_tuple(tuple); tuples_received++; } printf("rows: %zu\n", tuples_received); root_op->close(root_op->state); } root_op->destroy(root_op); return true; }
该请求首先由compile_select函数编译,该函数返回运算符树的根,然后在根运算符上调用相同的open / next / close函数。 每次对next的调用都会返回下一个元组或NULL。 在后一种情况下,这意味着已提取所有元组,并且应调用close迭代器函数。
表将重新计算所得的元组,并将其输出到标准输出流。
经营者
PigletQL最有趣的是运算符树。 我将展示其中一些设备。
运算符具有一个公共接口 ,由指向open / next / close函数的指针和一个附加的destroy destroy函数组成,该函数立即释放整个运算符树的资源:
typedef void (*op_open)(void *state); typedef tuple_t *(*op_next)(void *state); typedef void (*op_close)(void *state); typedef void (*op_destroy)(operator_t *op); struct operator_t { op_open open; op_next next; op_close close; op_destroy destroy; void *state; } ;
除功能外,运算符还可以包含任意内部状态(状态指针)。
下面,我将分析两个有趣的运算符的设备:最简单的扫描和创建中间关系排序。
扫描语句
启动任何查询的语句是scan。 他只是经历了关系的所有元组。 scan的内部状态是指向从中检索元组的关系的指针,该关系中下一个元组的索引以及指向传递给用户的当前元组的链接结构:
typedef struct scan_op_state_t { const relation_t *relation; uint32_t next_tuple_i; tuple_t current_tuple; } scan_op_state_t;
要创建扫描语句的状态,您需要一个源关系。 其他所有内容(指向相应功能的指针)都是已知的:
operator_t *scan_op_create(const relation_t *relation) { operator_t *op = calloc(1, sizeof(*op)); assert(op); *op = (operator_t) { .open = scan_op_open, .next = scan_op_next, .close = scan_op_close, .destroy = scan_op_destroy, }; scan_op_state_t *state = calloc(1, sizeof(*state)); assert(state); *state = (scan_op_state_t) { .relation = relation, .next_tuple_i = 0, .current_tuple.tag = TUPLE_SOURCE, .current_tuple.as.source.tuple_i = 0, .current_tuple.as.source.relation = relation, }; op->state = state; return op; }
在扫描重置的情况下,打开/关闭操作链接回关系的第一个元素:
void scan_op_open(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; } void scan_op_close(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; op_state->next_tuple_i = 0; tuple_t *current_tuple = &op_state->current_tuple; current_tuple->as.source.tuple_i = 0; }
下一个调用返回下一个元组,或者如果关系中没有其他元组,则返回NULL:
tuple_t *scan_op_next(void *state) { scan_op_state_t *op_state = (typeof(op_state)) state; if (op_state->next_tuple_i >= op_state->relation->tuple_num) return NULL; tuple_source_t *source_tuple = &op_state->current_tuple.as.source; source_tuple->tuple_i = op_state->next_tuple_i; op_state->next_tuple_i++; return &op_state->current_tuple; }
排序陈述
sort语句按用户指定的顺序生成元组。 为此,请使用从嵌套运算符获得的元组创建一个临时关系并将其排序。
操作员的内部状态 :
typedef struct sort_op_state_t { operator_t *source; attr_name_t sort_attr_name; sort_order_t sort_order; relation_t *tmp_relation; operator_t *tmp_relation_scan_op; } sort_op_state_t;
根据请求在时间比率(tmp_relation)中指定的属性(sort_attr_name和sort_order)执行排序。 所有这些都在调用open函数时发生:
void sort_op_open(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; operator_t *source = op_state->source; source->open(source->state); tuple_t *tuple = NULL; while((tuple = source->next(source->state))) { if (!op_state->tmp_relation) { op_state->tmp_relation = relation_create_for_tuple(tuple); assert(op_state->tmp_relation); op_state->tmp_relation_scan_op = scan_op_create(op_state->tmp_relation); } relation_append_tuple(op_state->tmp_relation, tuple); } source->close(source->state); relation_order_by(op_state->tmp_relation, op_state->sort_attr_name, op_state->sort_order); op_state->tmp_relation_scan_op->open(op_state->tmp_relation_scan_op->state); }
临时关系元素的枚举由临时操作员tmp_relation_scan_op进行:
tuple_t *sort_op_next(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; return op_state->tmp_relation_scan_op->next(op_state->tmp_relation_scan_op->state);; }
临时关系在close函数中被释放:
void sort_op_close(void *state) { sort_op_state_t *op_state = (typeof(op_state)) state; if (op_state->tmp_relation) { op_state->tmp_relation_scan_op->close(op_state->tmp_relation_scan_op->state); scan_op_destroy(op_state->tmp_relation_scan_op); relation_destroy(op_state->tmp_relation); op_state->tmp_relation = NULL; } }
在这里您可以清楚地看到为什么对没有索引的列进行排序操作会花费大量时间。
工作实例
这是PigletQL查询的一些示例以及相应的物理代数树。
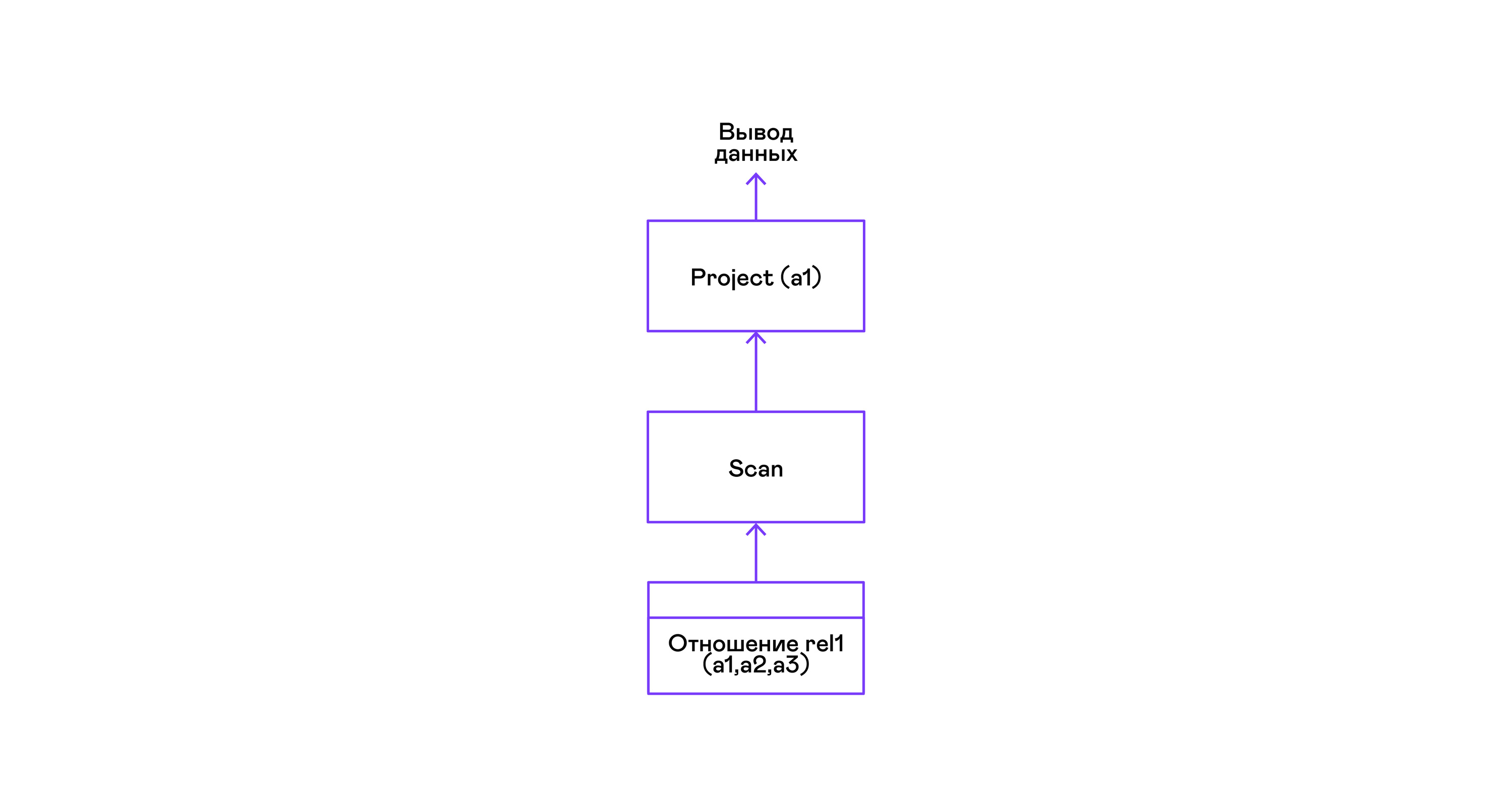
从关系中选择所有元组的最简单示例:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1; a1 1 4 rows: 2 >
对于最简单的查询,仅使用从扫描关系中检索元组,并从元组中选择唯一的项目属性:
用谓词选择元组:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 where a1 > 3; a1 4 rows: 1 >
谓词由select语句表示:
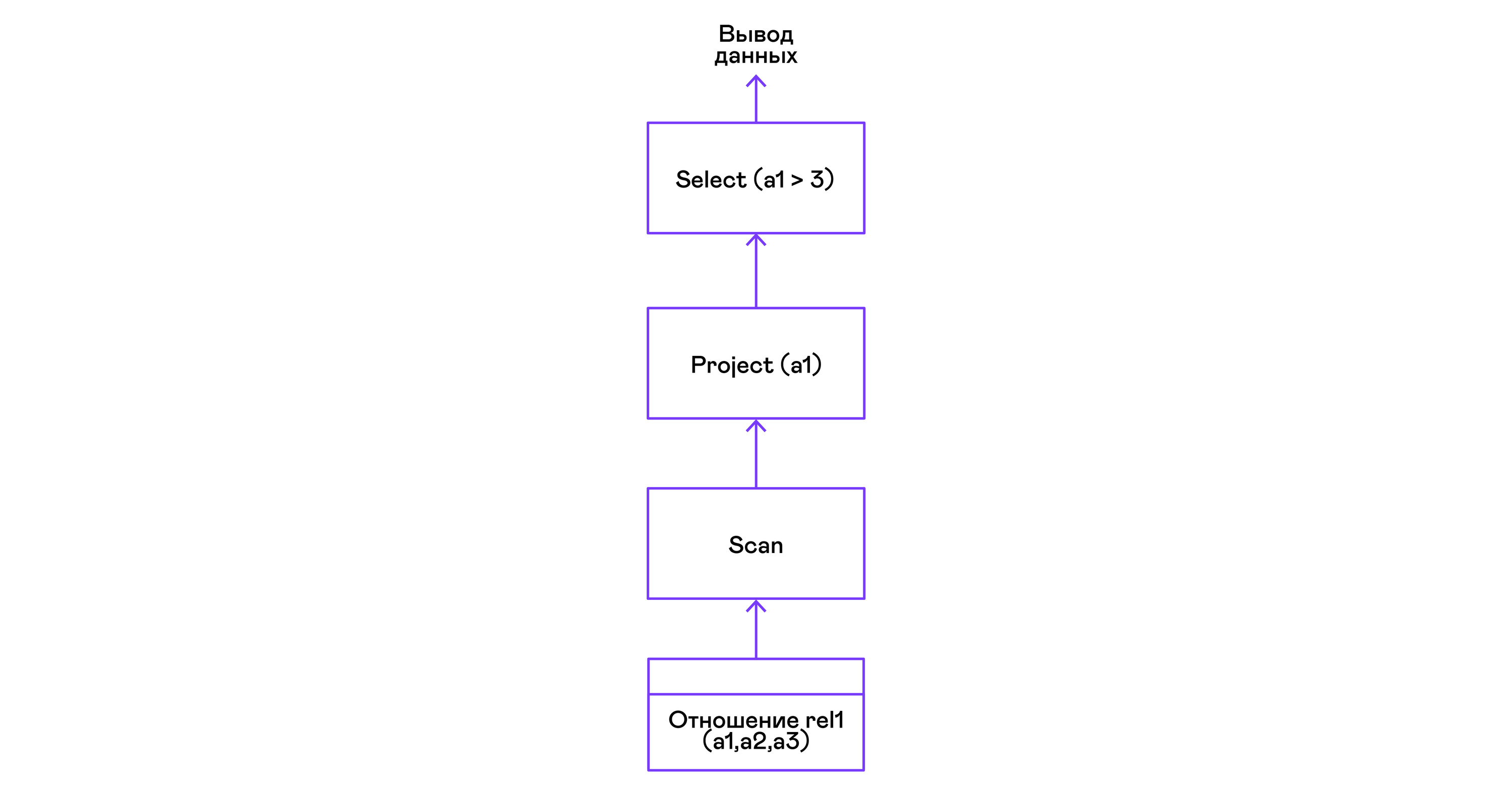
选择元组并进行排序:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > select a1 from rel1 order by a1 desc; a1 4 1 rows: 2
open调用中的scan sort运算符创建( 实现 )一个临时关系,将所有传入的元组放置在此处,然后对整体进行排序。 之后,在下一次调用中,它将根据用户指定的顺序从临时关系中推断出元组:

将两个关系的元组与谓词组合:
> ./pigletql > create table rel1 (a1,a2,a3); > insert into rel1 values (1,2,3); > insert into rel1 values (4,5,6); > create table rel2 (a4,a5,a6); > insert into rel2 values (7,8,6); > insert into rel2 values (9,10,6); > select a1,a2,a3,a4,a5,a6 from rel1, rel2 where a3=a6; a1 a2 a3 a4 a5 a6 4 5 6 7 8 6 4 5 6 9 10 6 rows: 2
PigletQL中的join运算符不使用任何复杂的算法,而只是从左右子树的元组集中形成笛卡尔乘积。 这是非常低效的,但是对于演示解释器,它将执行以下操作:
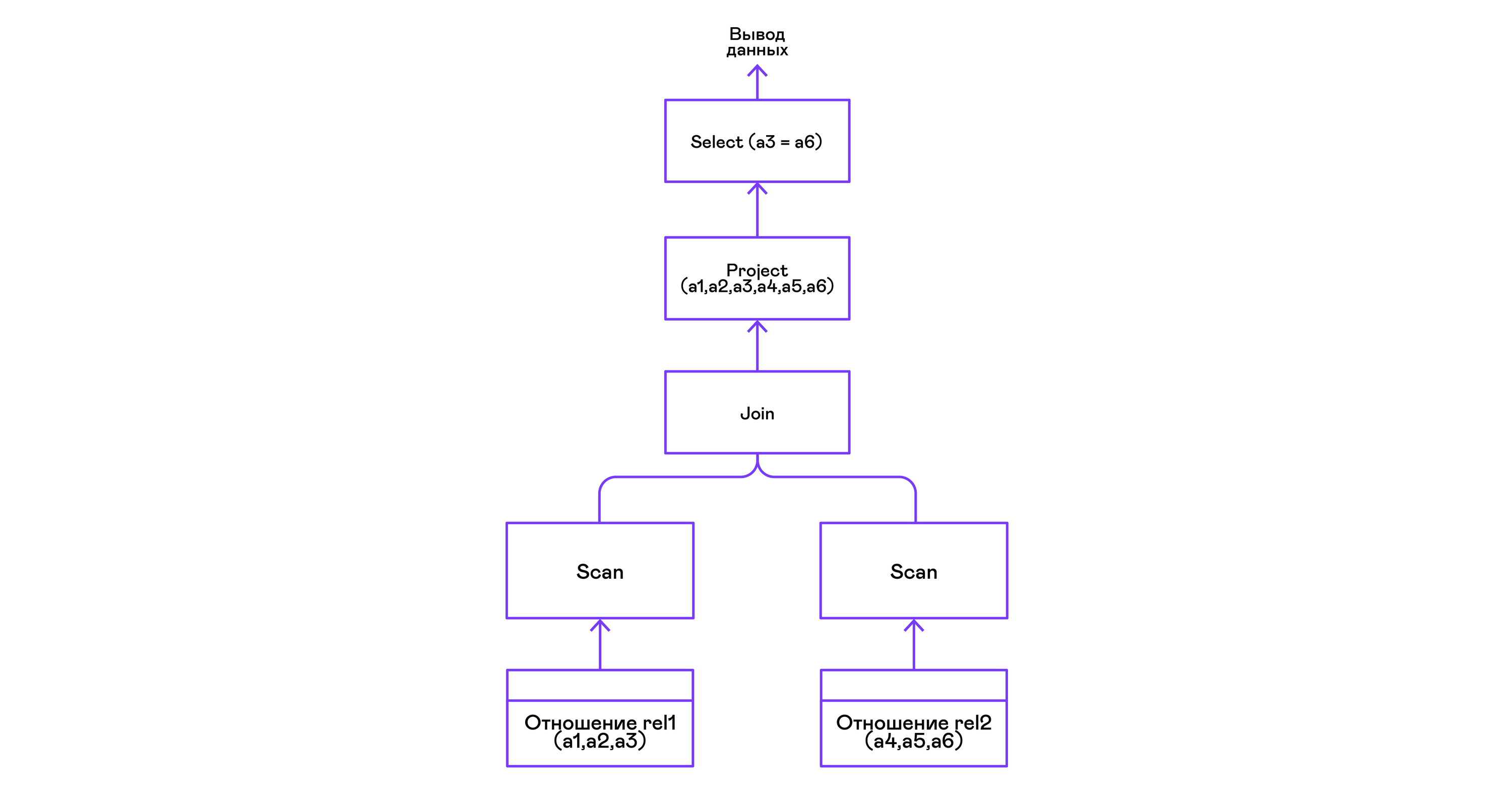
结论
总之,我注意到,如果您要对类似于SQL的语言进行解释,那么您可能应该只选择许多可用的关系数据库中的任何一个。 数千人年的时间已经投入到流行数据库的现代优化器和查询解释器上,即使是最简单的通用数据库也要花费数年的时间。
演示语言PigletQL模仿了SQL解释器的工作,但实际上,我们仅使用Volcano体系结构的各个元素,并且仅用于那些在关系模型的框架中难以表达的查询类型(罕见!)。
不过,我重复一遍:在需要灵活处理数据流的情况下,即使对这些解释器的体系结构有一点点了解也很有用。
文学作品
如果您对数据库开发的基本问题感兴趣,那么书籍会比“数据库系统实现”更好(Garcia-Molina H.,Ullman JD,Widom J.,2000)。
它唯一的缺点是理论取向。 就个人而言,我喜欢将具体的代码示例甚至演示项目附加到材料上。 为此,您可以参考“数据库设计和实现”一书(Sciore E.,2008年),该书提供了Java关系数据库的完整代码。
最受欢迎的关系数据库仍使用有关Volcano主题的变体。 原始出版物以一种易于访问的语言编写,可以在Google学术搜索中轻松找到:“火山-一种可扩展的并行查询评估系统”(Graefe G.,1994)。
尽管在过去的几十年中,SQL解释器已经进行了很多详细的更改,但是这些系统的非常常规的结构在很长一段时间内都没有发生变化。 您可以从同一作者的评论文章“大型数据库的查询评估技术”中了解到这一点(Graefe G. 1993)。