哈Ha! 我叫Nikolai,我在Sberbank从事机器学习模型的构建和实施。 今天,我将讨论为您的智能手机上的应用程序开发一种用于付款和转帐的推荐系统。
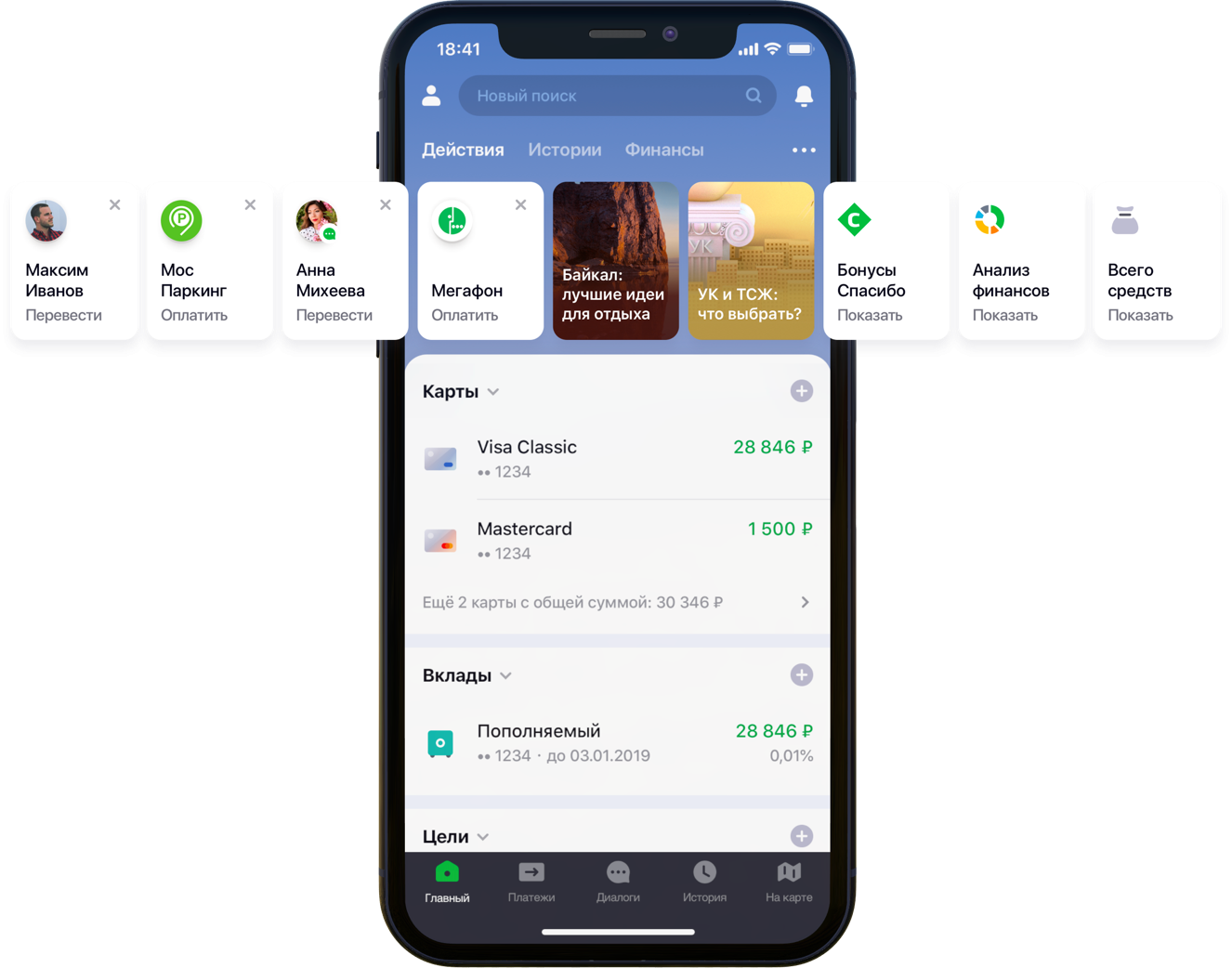 带有建议的移动应用程序主屏幕设计
带有建议的移动应用程序主屏幕设计我们有20万种可能的付款方式,5500万客户,5个不同的银行来源,一半的开发人员专栏和大量的银行活动,算法以及所有这些,所有颜色,一升随机种子,一盒超参数,半升校正因子和两个数十个图书馆。 并不是说所有这些工作都是必要的,而是因为他开始改善客户的生活,所以请尽心尽力。 切入点是关于UX斗争的故事,问题的正确表述,与数据维数的斗争,对开源的贡献以及我们的成果。
问题陈述
随着开发和扩展,Sberbank Online应用程序正在获得有用的功能和附加功能。 特别是,在应用程序中,您可以转移资金或为各种组织的服务付费。
“我们仔细查看了应用程序内部的所有用户路径,并意识到可以大大减少其中的许多路径。 为此,我们决定分几个阶段对主屏幕进行个性化设置。 首先,我们尝试从屏幕上删除客户端不使用的内容(从银行卡开始)。 然后,他们将客户早先已经执行的那些动作突显出来,并且他现在可以针对这些动作进入应用程序。 我的同事谢尔盖·科马罗夫(Sergey Komarov)说,现在行动清单包括向组织付款和转移到联系人,然后将扩大这些行动清单,他正在从Sberbank Online团队的客户角度开发功能。 有必要构建一个模型,该模型将用个人建议的付款和转帐方式(而不是简单的规则)填充“操作”小部件中的指定位置(上图)。
解决方案
我们团队中的任务分解为两个部分:
- 重复操作以支付服务或转移资金的建议(“建议操作”框)
- 建议此客户以前未使用过的服务的搜索搜索请求示例(“搜索示例”框)
我们决定先在搜索标签上测试功能:
推荐的搜索屏幕设计推荐操作
评分优化
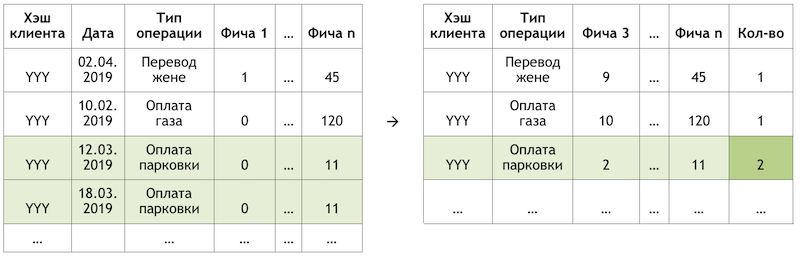
如果我们将子任务设置为重复操作的建议,则可以避免为所有客户计算和评估数以万亿计的所有可能操作的组合,而将精力集中在数量有限的操作上。 如果在我们的客户可用的全部操作中,带有YYY哈希的假设客户仅使用汽油和停车费,那么我们将评估对该客户仅重复执行这些操作的可能性:
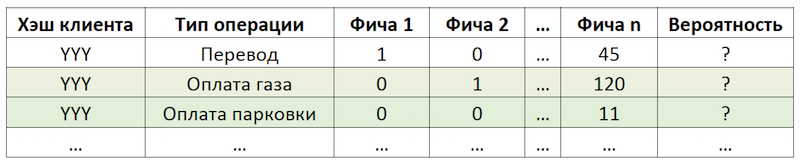 减少数据维度以进行评分的示例
减少数据维度以进行评分的示例准备数据集
该样本是一个事务性观察,其中包含客户人口统计,财务汇总和特定操作的各种频率特征等因素。
在这种情况下,目标变量是二进制的,反映了在计算因子的次日发生的事件的事实。 因此,迭代地移动计算因子的日期并设置目标变量的标志,我们乘以并标记相同的操作,并根据相对于这一天的位置将它们标记为不同。
观察方案计算客户“ YYY”在03/17/2019的切割,我们得到两个观察结果:
数据集观察值的示例“功能1”可以表示,例如,客户所有卡上的余额“功能2”-上周存在这种类型的操作。
我们进行相同的交易,但是在不同的日期形成对培训的观察结果:
观察方案我们将获得具有要素和目标变量的其他值的数据集的观测值:
 数据集观察值的示例
数据集观察值的示例在上面的示例中,为清楚起见,给出了因子的实际值,但实际上,这些值是由自动算法处理的:将
WOE转换的结果输入模型的输入。 它使您可以使变量与目标变量具有单调关系,同时摆脱异常值的影响。 例如,我们有因子“纸牌数”和目标变量的一些分布:
 WOE转换示例
WOE转换示例WOE转换使我们能够将非线性依赖性转换为至少单调的依赖性。 被分析因子的每个值都与其自己的WOE值相关联,因此形成了一个新因子,并从数据集中删除了原始因子:
 WOE变换对与目标变量的关系的影响
WOE变换对与目标变量的关系的影响将用于将变量值转换为WOE的字典已保存,以后用于评分。 也就是说,如果我们需要计算明天的概率,则可以使用上面的观察示例在表中创建一个数据集,并使用保存的代码将必要的变量转换为WOE,然后将模型应用于这些数据。
培训课程
方法的选择受到严格限制-可解释性。 因此,为了遵守最后期限,决定在问题的后半部分使用相同的
SHAP推迟解释,并测试相对简单的方法:回归和浅层神经元。 该工具是SAS Miner,它是一种用于以交互形式对各种数据进行预处理,分析和构建模型的软件,从而节省了编写代码的大量时间。
 SAS Miner接口
SAS Miner接口质量评估
在一个过时的样本上对GINI指标进行的比较表明,神经网络可以最好地应对任务:
质量模型和频率规则比较表该模型有两个出口点。 在主屏幕上以小部件卡的形式进行的建议包括其预测高于特定阈值的操作(请参阅帖子中的第一张图片)。 基于质量和覆盖范围的平衡来选择边界,在这种架构中,边界是所执行的所有操作的一半。 前4个操作将发送到搜索屏幕的“推荐操作”块(请参见第二张图片)。
搜寻范例
转到任务的第二部分,我们回到了一个问题,即需要对每个客户内部的提供商进行评估和分类的服务提供商的服务可能有多种选择-数万亿对。 除此之外,我们还有隐性数据,即没有有关付款评估的信息,也没有客户为什么不付款的信息。 因此,对于初学者来说,决定测试各种方法来扩展从客户到提供商的付款方式:ALS和FM。
ALS
ALS(交替最小二乘)或交替最小二乘-协作过滤中的一种方法,用于解决交互矩阵分解的问题。 我们将以矩阵的形式显示有关服务支付的交易数据,其中列是所有提供商服务的唯一标识符,行是唯一的客户。 在单元格中,我们放置特定时间段内特定客户端与特定提供者的操作数:
 矩阵分解原理
矩阵分解原理该方法的含义是,我们创建了两个这样的较低维矩阵,将它们相乘可以得出最接近填充单元中原始大矩阵的结果。 该模型学习为客户和提供者创建隐藏的析因描述。 使用了
隐式库中该方法的实现。 训练根据以下算法进行:
- 具有隐藏因素的客户和提供者矩阵被初始化。 它们的数量是模型的超参数。
- 提供者的隐藏因素矩阵是固定的,并考虑了损失函数的导数,用于校正客户矩阵。 作者使用了一种有趣的共轭梯度方法 ,使您可以大大加快这一步骤。
- 对于客户的隐藏因素矩阵,类似地重复前面的步骤。
- 步骤2-3交替进行,直到算法收敛为止。
准备工作
交易数据被转换成交互矩阵,其稀疏程度约为99%,提供商之间的差异很大。 为了将数据分为训练样本和验证样本,我们随机掩盖了填充单元的比例:
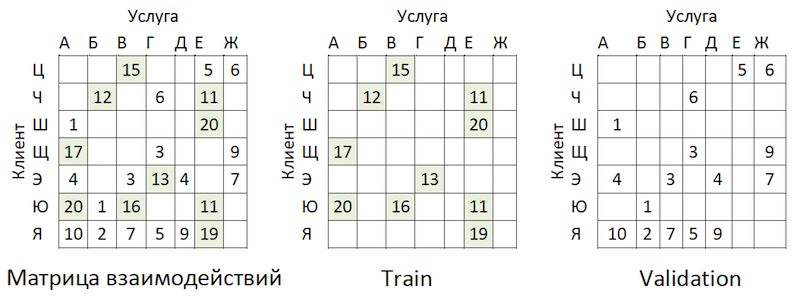 数据共享示例
数据共享示例在培训之后的一段时间内,将交易作为测试,并以相同格式的矩阵进行布局-结果过期了。
培训课程
该模型具有几个可以调整以提高质量的超参数:
- Alpha是对矩阵加权的系数,用于调整给定服务确实被客户“喜欢”的置信度( C_iu )。
- 客户端和提供者的隐藏矩阵中的因子数分别是列数和行数。
- 正则化系数L2λ。
- 方法的迭代次数。
我们使用了
hyperopt库,该库允许我们使用
TPE方法评估超参数对质量指标的影响并选择其最佳值。 该算法从冷启动开始,并根据所分析的超参数的值对质量度量进行几次评估。 然后,从本质上讲,他尝试选择一组更有可能为质量指标提供良好价值的超参数值。 结果保存在字典中,您可以从中构建图形并直观地评估优化器的结果(蓝色更好):
质量度量对超参数组合的依赖关系图该图表明,超参数的值强烈影响模型的质量。 由于必须将每个范围的范围应用于方法的输入,因此该图可以进一步确定扩展值空间是否有意义。 例如,在我们的任务中,很显然测试大量因素值是有意义的。 将来,这确实改善了模型。
质量评估指标和复杂性
如何评估模型的质量? 推荐
@重要的推荐系统中最常用的度量标准之一是
MAP @ k或
K处的平均平均精度。该度量标准估计了K个推荐模型的准确性,同时考虑了所有客户平均而言这些推荐列表中项目的顺序。
不幸的是,即使对样品进行质量评估也要花费几个小时。 袖手旁观之后,我们开始使用line_profiler库来分析mean_average_pecision_at_k()函数。 该函数使用cython代码并且必须正确
考虑这一事实,使任务进一步复杂化,否则根本就不会收集必要的统计信息。 结果,我们再次面临数据维度的问题。 要计算此指标,您需要从每个客户的所有可能情况中获得每个服务的一些估计,并通过对结果数组进行排序来选择排名前K的个人推荐。 即使考虑使用具有O(n)复杂度的numpy.argpartition()的部分排序,对等级进行排序也是延长质量分级的最长步骤。 由于numpy.argpartition()并未使用我们服务器的所有内核,因此决定通过cython在C ++和OpenMP中重写此部分来改进算法。 一种简短的新算法如下:
- 数据被客户分批切割。
- 空矩阵和指向内存的指针被初始化。
- 通过指针对字符串进行批处理的方式有两种:通过partial_sort函数,然后通过C ++算法库进行排序。
- 将结果并行写入空矩阵的单元格。
- 数据以python返回。
这使我们可以多次加快建议的计算速度。 该修订版已
添加到官方存储库中。
OOT结果分析
现在是时候评估模型的质量了。 为什么我们需要超时采样? 如果查看提供者的操作分布,我们将看到以下图片:
服务提供商的受欢迎程度分布不平衡。 这导致该模型试图推荐流行的服务。 回到上图:
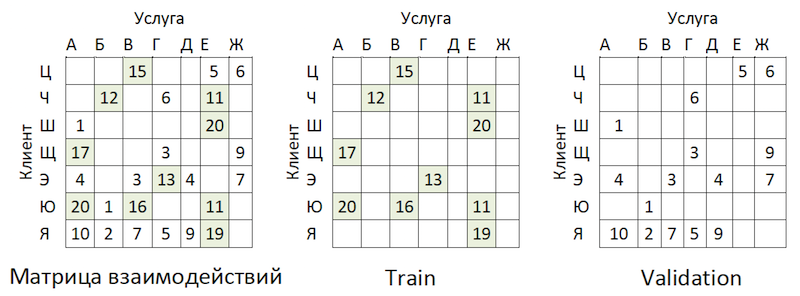
问题是,如果您通过屏蔽几乎所有地方都建议的相同矩阵来检查模型的准确性,那么对于大多数客户(边际示例:“ W”,“ E”和“ I”),验证预测的质量(我们会假装她没有参加超参数的选择)(如果它们是最受欢迎的提供者)将会很高。 结果,我们对模型的强度没有信心。 因此,我们的行为如下:
- 按模型形成提供者的估计。
- 现有的客户服务对被排除在等级(参见下图)和OOT矩阵之外。
- 由前K个推荐的剩余评分和剩余OOT上的MAP @ k组成。
 准备用于生成预测的矩阵的逻辑
准备用于生成预测的矩阵的逻辑作为基础,我们编制了一个提供程序列表,按受欢迎程度排序,然后将其乘以所有客户,再一次排除了现有的客户服务对。 事实证明这很可悲,根本不符合我们在火车\验证样本中所期望的:
基准和模型质量比较表别说了 我们有客户因素和提供者的参数。 我们得到分解机。
调频
因数分解机(factorization machine)-一种具有教师的学习算法,旨在查找描述交互实体的因素之间的关系,这些关系以稀疏矩阵的形式表示。 我们使用了
LightFM库中的FM实现。
资料格式
除了归一化的交互矩阵之外,该
方法还使用两个附加的数据集,这些数据集具有与客户端和提供者服务有关的因子,形式为与单个因子相连的一键编码矩阵:
 准备用于生成预测的矩阵的逻辑
准备用于生成预测的矩阵的逻辑质量评估
事实证明,FM数据在质量上低于ALS:
质量模型和基准的比较表变更模型架构-促进
决定从另一侧进来。 回顾服务受欢迎程度的分布情况,我们确定了其中的300种服务,涵盖了所有业务的80%的交易,并对其进行了分类训练。 此处,数据代表丰富了客户功能的客户交易汇总:
 交易汇总方案
交易汇总方案您问为什么只有客户端? 因为在这种情况下,要准备建议,我们每个客户只有一行就足够了。 将模型应用于该模型,我们可以获得所有类别的概率输出向量,从中可以轻松选择前K个建议。 如果我们将提供者服务的功能添加到训练集中,则在模型应用阶段,我们将被迫为每个客户准备300行-为每个提供服务的行提供描述它们的功能,或者建立另一种模型以对评分候选者进行预排序。
从ALS向客户添加功能不会增加我们的数据,因为我们已经考虑了交易活动-例如,在“我的客户中心”部分或“游戏”或“剧院”风格的类别中。 通过这种格式,我们取得了良好的效果:
质量模型和基准的比较表区域过滤器
尽管模型的质量很高,但是这种方法仍然存在另一个问题。 由于数据和模型的体系结构并不意味着使用提供商的服务功能,因此该模型未完全考虑地理位置,可能会建议人们为来自其他地区的本地提供商的服务付费。 为了最大程度地降低这种风险,我们开发了一个小型过滤器,可以在提出建议之前预先截断选项。 算法上有一个简单的递归:
- 我们从银行资料和其他内部来源收集有关客户所在地区的信息。
- 我们为每个提供商选择主要的服务区域。
- 我们按照客户使用的提供商的区域来阐明/填写有关客户区域的信息。
在进行了这些操作之后
,我们使用
赫芬达尔指数将区域提供者(在有限的一组区域中代表)与联邦提供者分开:
按区域分布区分提供者我们与可接受的区域供应商一起为客户提供掩膜,并在创建建议列表之前从模型预测中排除不必要的项目。
结论
我们已经开发了两个模型,这些模型共同构成了有关付款和转帐的完整建议。 可以将一半重复操作的客户端路径减少到一键。 在将来的计划中,将使用反馈数据(可以隐藏卡片等)来改进“推荐操作”的模型,这将减少选择建议的门槛并扩大覆盖范围。 还计划在“搜索示例”模型中扩展推荐付款的覆盖范围,并开发一种评分优化算法。
我们已经经历了建立付款和转帐推荐系统的艰难道路。 在此过程中,我们在分解和简化此类任务,正确评估此类系统,方法的适用性,使用大量数据进行优化工作方面积累了丰富的经验,并获得了丰富的经验,并极大地扩展了我们对此类任务具体内容的理解。 在此过程中,我设法为我们自己使用的开源做出了贡献。 我希望您有有趣的任务,切合实际的基准和单个F1。 感谢您的关注!