本文是一种主类“用于自动执行ML实验和数据版本控制的DVC”,它于6月18日在ML REPA(机器学习REPA:
重现性,实验和管道自动化)。
在这里,我将讨论DVC内部工作的功能以及如何在项目中使用它。
本文中使用了代码示例。 该代码已在MacOS和Linux(Ubuntu)上进行了测试。
目录内容
第一部分
第二部分
DVC设定
数据版本控制是一种工具,用于管理ML项目中的模型和数据版本。 它在实验阶段和将模型部署到操作中都非常有用。
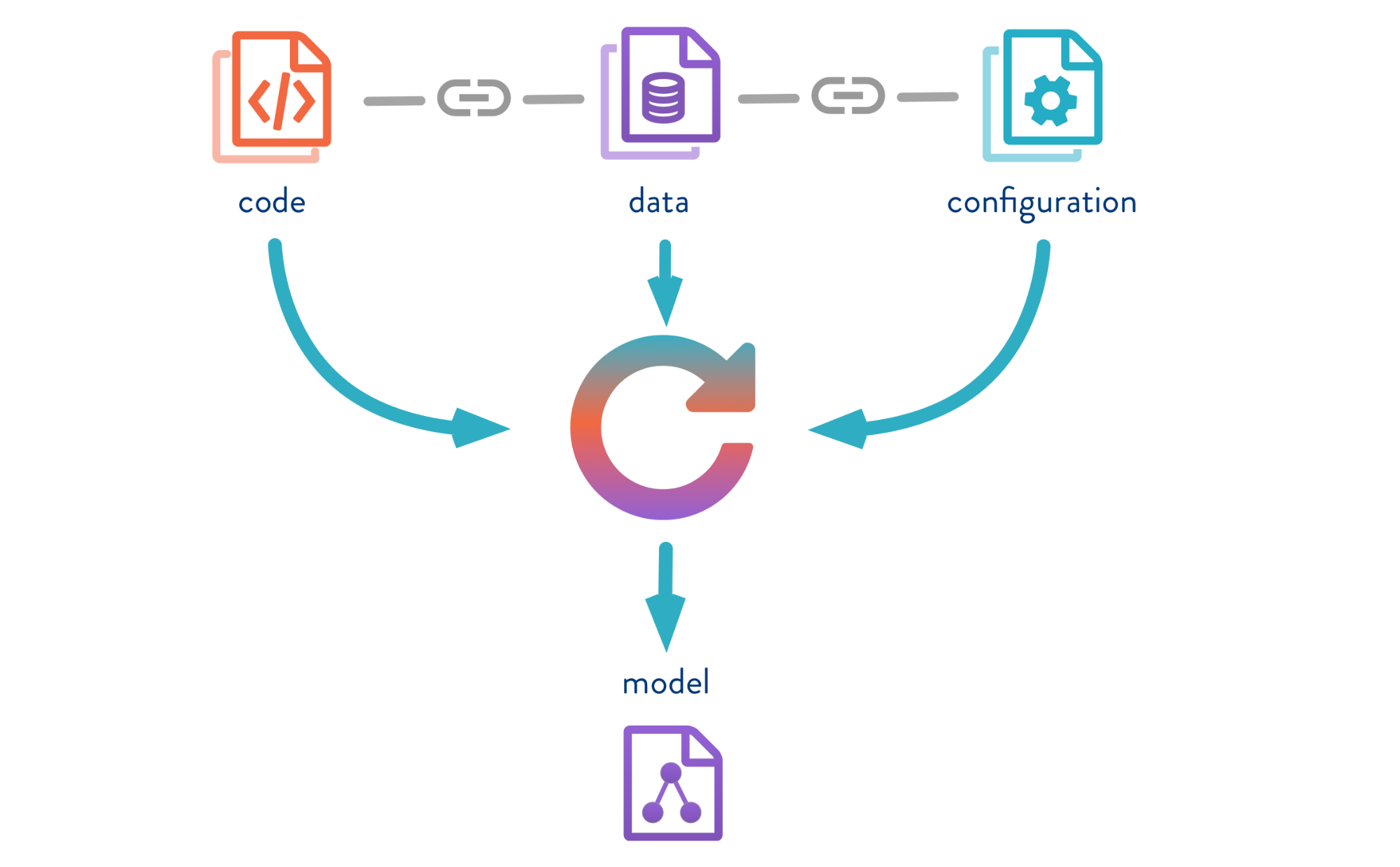
DVC允许您在DS项目中对模型,数据和管道进行版本控制。
来源在
这里 。
让我们使用虹膜颜色分类问题的示例来看一下DVC操作。 为此,将使用
虹膜数据集 。 Jupyter Notebook显示了使用DVC的其他
示例 。
您需要做什么:- 克隆存储库;
- 创建虚拟环境;
- 安装必要的python软件包;
- 初始化DVC。
因此,我们克隆存储库,创建虚拟环境并安装必要的软件包。 安装和启动说明位于README存储库中。
1.克隆此存储库
git clone https://gitlab.com/7labs.ru/tutorials-dvc/dvc-1-get-started.git cd dvc-1-get-started
2.创建并激活虚拟环境
pip install virtualenv virtualenv venv source venv/bin/activate
3.安装python库(包括dvc)
pip install -r requirements.txt
要安装DVC,请使用
pip install dvc命令。 安装后,必须在
dvc init项目文件夹中初始化DVC,该文件夹将生成一组文件夹,用于DVC的进一步工作。
4.在演示存储库中签出新分支(不擦除主分支的内容)
git checkout -b dvc-tutorial
5.初始化DVC
dvc init commit dvc init git commit -m "Initialize DVC"
DVC在Git之上运行,使用其基础结构,并且具有类似的语法。
在此过程中,DVC创建元文件来描述管道和版本化文件,您需要将其保存在Git中以保存项目的历史记录。 因此,在执行
dvc init必须运行
git commit来提交所做的所有设置。
.dvc文件夹将出现在您的存储库中,其中包含
cache和
config 。
.dvc的内容将如下所示:
./ ../ .gitignore cache/ config
Config是DVC配置,而cache是DVC将存储要版本化的所有数据和模型的系统文件夹。
DVC还将创建一个
.gitignore文件,在其中它将写入不需要提交到存储库的那些文件和文件夹。 当您将文件传输到DVC以在Git中进行版本控制时,将保存版本和元数据,并且文件本身将存储在缓存中。
现在,您需要安装所有依赖项,然后在新的
dvc-tutorial分支中进行
checkout出,我们将在其中进行工作。 并下载虹膜数据集。
获取数据
wget -P data/ https://raw.githubusercontent.com/uiuc-cse/data-fa14/gh-pages/data/iris.csv
DVC功能
版本控制模型和数据
来源在
这里 。
让我提醒您,如果您在DVC的控制下传输某些数据,则它将开始跟踪所有更改。 我们可以像使用Git一样使用这些数据:保存版本,将其发送到远程存储库,获取正确的数据版本,进行更改并在版本之间进行切换。 DVC的界面非常简单。
输入
dvc add命令并指定我们需要版本控制的文件的路径。 DVC将创建带有扩展名.dvc的iris.csv图元文件,并将有关它的信息写入缓存文件夹。 让我们提交这些更改,以便有关版本开始的信息出现在Git历史记录中。
dvc add data/iris.csv
在生成的dvc文件中,其散列与标准参数一起存储。
Output -dvc文件夹中文件的路径,我们在DVC的控制下添加了该路径。 系统获取数据,将其放入缓存中,并在工作目录中创建指向缓存的链接。 可以将该文件添加到Git历史记录中并进行版本控制。 DVC接管数据本身的管理。 哈希的前两个字符用作缓存内的文件夹,其余字符用作创建文件的名称。
 ML管道的自动化
ML管道的自动化除了数据版本控制外,我们还可以创建管道(pipelines)-定义依赖关系的计算链。 这是用于分类器训练和评估的标准管道:
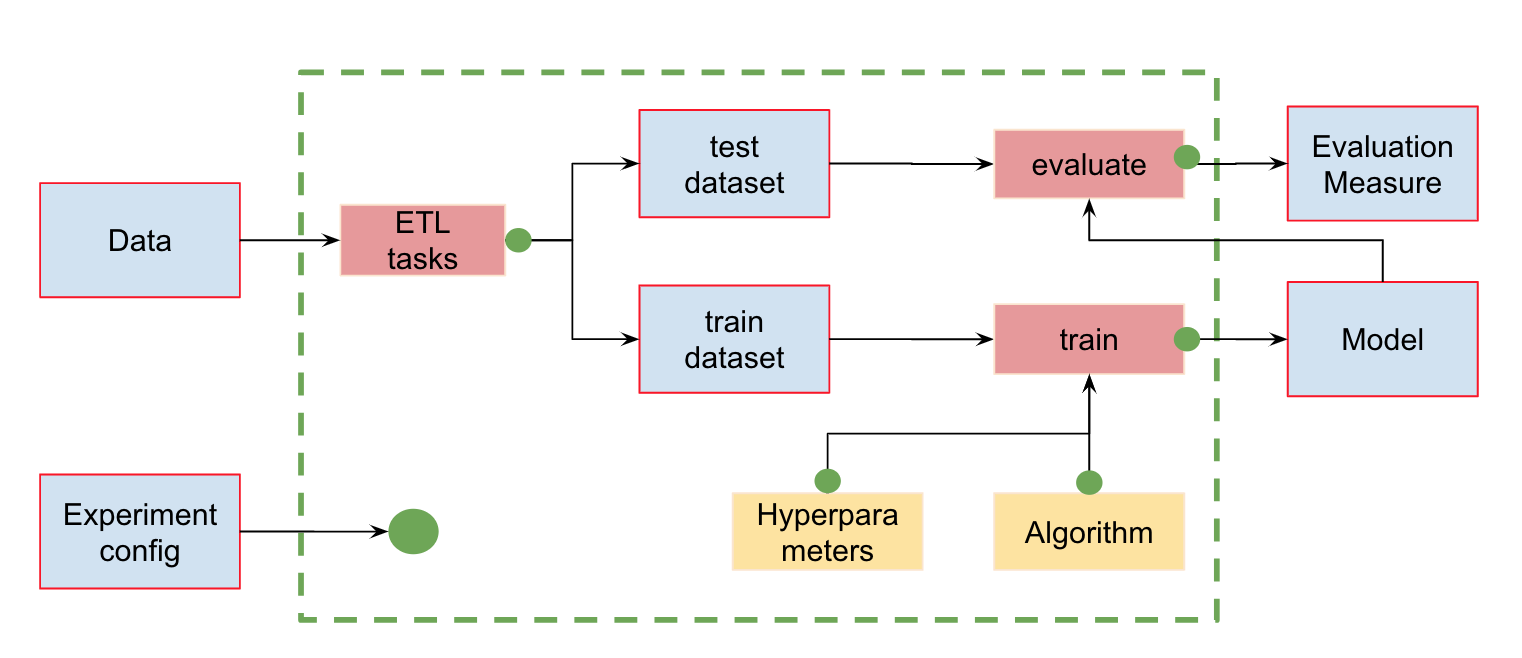
在输入中,我们必须对数据进行预处理,将其分为训练和测试,计算特征,然后训练模型并对其进行评估。 该管道可以分为几个部分。 例如,要区分加载和预处理数据,拆分数据,评估等以及将这些链连接在一起的阶段。
为此,DVC有一个很棒的
dvc run命令,在其中我们传递某些参数并指定我们需要运行的Python模块。
现在-例如,计算符号的发射阶段。 首先,让我们看一下featureization.py模块的内容:
import pandas as pd def get_features(dataset): features = dataset.copy()
此代码获取数据集,计算特征并将其保存在iris_featurized.csv中。 我们将其他符号的计算留给下一阶段。
要创建管道,需要在计算的每个阶段运行命令
dvc run 。

首先,在
dvc run命令中,指定stage_feature_extraction.dvc图元文件的名称,DVC将在该图元文件中写入有关计算阶段的必要元数据。 通过
-d参数,我们指定必要的依赖关系:featureization.py模块和iris.csv数据文件。 我们还指定了用于保存符号的iris_featurized.csv文件,以及python src / featurization.py启动命令本身。
dvc run -f stage_feature_extraction.dvc \ -d src/featurization.py \ -d data/iris.csv \ -o data/iris_featurized.csv \ python src/featurization.py
DVC将创建一个图元文件并跟踪Python模块和iris.csv文件中的更改。
如果其中发生更改,则DVC将在管道中重新开始此计算步骤。
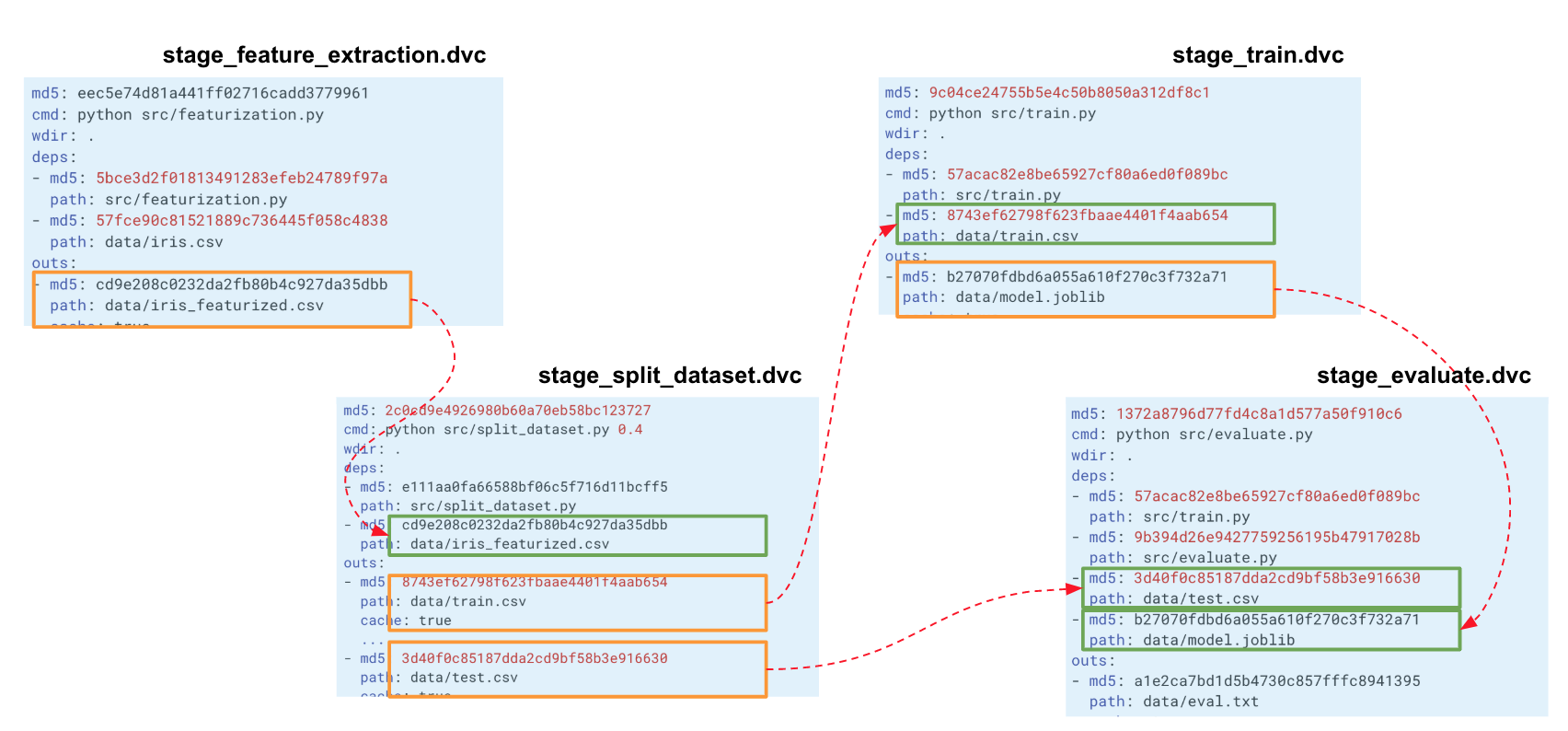
生成的stage_feature_extraction.dvc文件将包含其哈希,启动命令,依赖项和输出(可以在元数据中找到它们的其他参数)。
现在,您需要将此文件保存在Git提交的历史记录中。 因此,我们可以创建一个新分支并将其推送到Git存储库中。 您可以通过单独创建每个阶段或一次创建所有阶段来提交Git故事。
当我们为整个实验构建这样的链时,DVC会构建一个计算图(DAG),通过它可以开始对整个管道或某些部分进行重新计算。 一个阶段的输出的哈希值进入另一个阶段的输入。 根据他们的说法,DVC跟踪依赖关系并建立计算图。 如果您在split_dataset.py中的某处更改了代码,DVC将不会加载数据并可能重新计算符号,但是将重新开始此阶段以及随后的训练和评估阶段。
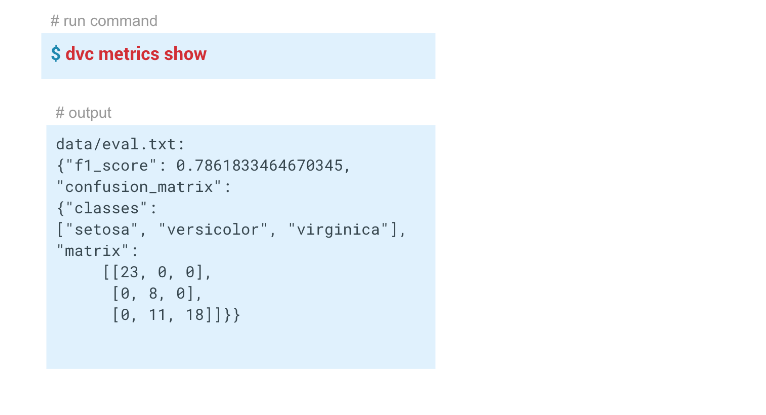
 指标跟踪
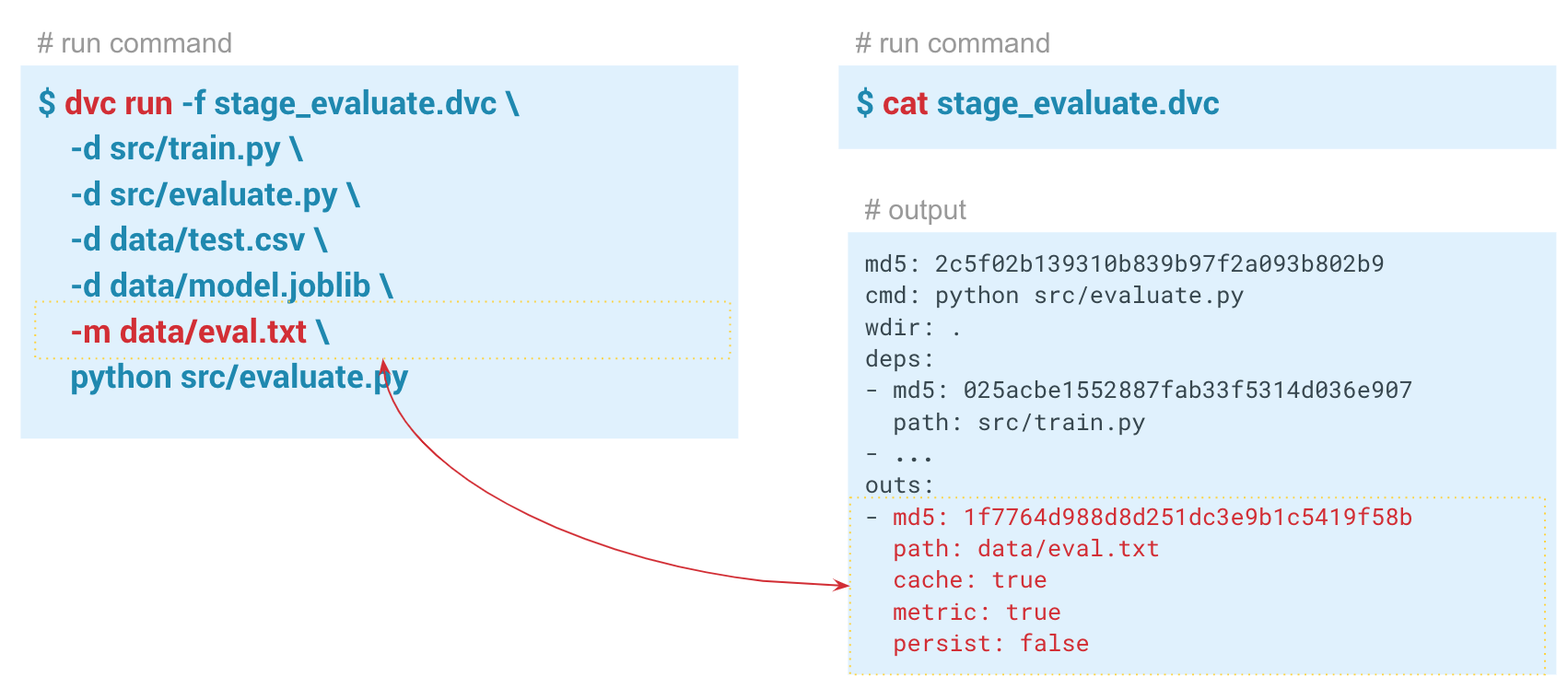
指标跟踪使用
dvc metrics show命令,您可以显示当前启动的度量,即我们所在的分支。 如果我们通过
-a选项,DVC将显示Git历史记录中的所有指标。 为了使DVC开始跟踪指标,在创建评估步骤时,我们通过data / eval.txt传递
-m参数。 valuate.py模块将度量标准(在本例中为
f1和
confusion metrics写入该文件。 在此步骤dvc文件中的输出文件夹中,将
cache和
metrics设置为true。 也就是说,dvcmetric show命令将把eval.txt文件的内容输出到控制台。 另外,使用此命令的参数,您只能显示
f1_score或
confusion_matrix 。
在此示例中,我们得到了以下结果:
 管道重现性
管道重现性那些使用此数据集的人都知道,很难在其上建立良好的模型。
现在,我们有了使用DVC创建的管道。 系统跟踪数据和模型的历史记录,可以全部或部分重新启动自身,并可以显示指标。 我们已经完成了所有必要的自动化。
我们有一个f1 = 0.78的模型。 我们想通过更改一些参数来改进它。 为此,最好使用单个命令重新启动整个管道。 另外,如果您在团队中工作,则可能需要将模型和代码传递给同事,以便他们可以继续为他们工作。
dvc repro允许
dvc repro重新启动管道或各个阶段(在这种情况下,您需要在命令后指定重现阶段)。
dvc repro stage_evaluate ,该阶段将尝试重新启动整个管道。 但是,如果我们在当前状态下执行此操作,则DVC将看不到任何更改,也不会重新启动。 如果我们进行了更改,他将找到更改并从那一刻开始重新启动管道。
$ dvc repro stage_evaluate.dvc Stage 'data/iris.csv.dvc' didn't change. Stage 'stage_feature_extraction.dvc' didn't change. Stage 'stage_split_dataset.dvc' didn't change. Stage 'stage_train.dvc' didn't change. Stage 'stage_evaluate.dvc' didn't change. Pipeline is up to date. Nothing to reproduce.
在这种情况下,DVC在stage_evaluate阶段依赖项中看不到任何更改,因此拒绝重新启动。 而且,如果我们指定
-f选项,则它将重新启动所有准备步骤,并显示一条警告,指出它删除了从其跟踪的数据的先前版本。 每次DVC重新启动阶段时,它都会删除先前的缓存,并实际上将其覆盖以免重复数据。 在启动DVC文件的那一刻,将检查其哈希,如果已更改,则管道将重新启动并覆盖该管道具有的所有输出。 如果要避免这种情况,那么必须首先在某个远程存储库中运行特定版本的数据。
重新启动管道并跟踪每个阶段的依赖性的能力使您可以更快地试验模型。
例如,您可以更改特征(在
featurization.py “取消注释”用于计算特征的
featurization.py )。 DVC将看到这些更改并重新启动整个管道。
将数据保存到远程存储库
DVC不仅可以与本地版本存储一起使用。 如果执行
dvc push命令,则DVC会将模型和数据的当前版本发送到预先配置的远程存储库。 如果这样,您的同事将对您的存储库进行
git clone并进行
dvc pull ,那么他将获得该分支的数据和模型版本。 最主要的是,每个人都可以访问此存储库。
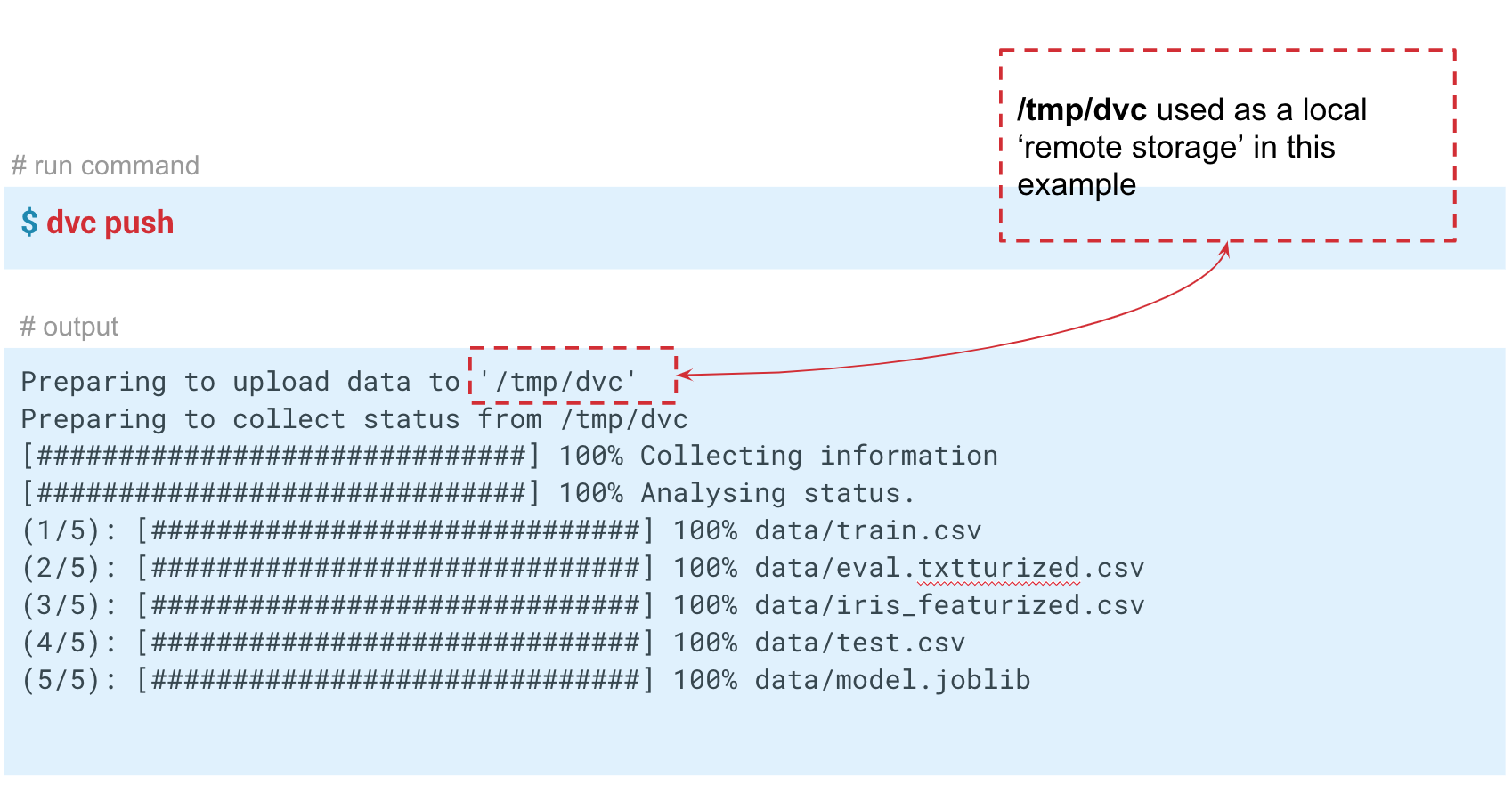
在这种情况下,我们在temp / dvc文件夹中模拟“远程”存储。 大致以相同的方式,在云中创建了远程存储。 提交此更改,使其保留在Git故事中。 现在,我们可以执行
dvc push来将数据发送到此存储,而您的同事只是执行
dvc pull来获取它。
因此 ,我们研究了DVC和基本功能有用的三种情况:
- 版本化数据和模型 。 如果不需要管道和远程存储库,则可以在本地计算机上对特定项目的数据进行版本控制。 DVC使您可以快速处理数十GB的数据。
- 团队之间的数据和模型交换 。 您可以使用云解决方案来存储数据。 如果您有一个分散的团队或对通过邮件发送的文件大小有限制,这是一个方便的选择。 此外,在彼此发送笔记本但无法启动笔记本时,可以使用此技术。
- 在大型服务器中组织团队工作 。 该团队可以使用本地版本的大数据,例如数十或数百GB,以便您不来回复制它们,而使用一个远程存储,该远程存储将仅发送和保存模型或数据的关键版本。
第二部分
如何在您的项目中实施DVC?为了确保项目的可重复性,必须遵守某些要求。
这里是主要的:
- 所有管道都是自动化的;
- 控制每个计算阶段的发射参数;
- 代码,数据和模型的版本控制;
- 环境控制;
- 文档。
如果所有这些都完成了,那么该项目更有可能是可复制的。 DVC使您可以满足此列表中的前3个要求。
尝试在您的公司中实施DVC时,您可能会遇到不愿意的情况:“为什么我们需要这样做? 我们有一个Jupyter笔记本。” 也许您的某些同事仅使用Jupyter Notebook,对于他们而言,在IDE中编写此类管道和代码要困难得多。 在这种情况下,您可以逐步进行实施。
- 最简单的开始方法是对代码和模型进行版本控制。
然后继续自动化管道。 - 首先,将经常重新启动和更改的步骤自动化,
然后是整个管道。
如果您有一个新项目,并且团队中有几个爱好者,那么最好立即使用DVC。 因此,例如,事实证明是我们的团队! 当开始一个新项目时,我的同事们支持我,我们开始自己使用DVC。 然后他们开始与其他同事和团队分享。 有人承担了我们的任务。 如今,DVC尚未成为我们银行中公认的工具,但已在多个项目中使用。