注意事项 佩雷夫 :我们会提请您注意由Grafana的创建者提供的有关云服务最近中断的原因的技术细节。 这是一个经典的例子,说明了一个新的,看似极其有用的机会,该机会旨在改善基础设施的质量……如果人们没有预见到其在生产现实中的应用的细微差别,就会造成很大的伤害。 出现这些材料不仅可以使您从错误中学到的东西,这真是太好了。 详细信息摘自Grafana Labs产品副总裁的本文翻译。
7月19日,星期五,Grafana Cloud的Hosted Prometheus服务停止工作约30分钟。 我向所有遭受失败的客户表示歉意。 我们的任务是提供必要的监视工具,并且我们知道它们的不可访问性使您的生活变得复杂。 我们非常重视这一事件。 本说明解释了发生的情况,我们对此的反应以及我们正在做的事情,以使这种情况不再发生。
背景知识
Grafana Cloud Hosted Prometheus服务基于
Cortex (CNCF项目),可创建水平可扩展,高度可访问的多租户Prometheus服务。 Cortex体系结构由一组单独的微服务组成,每个微服务都执行其功能:复制,存储,请求等。 Cortex正在积极开发中,不断有新的机会并提高生产力。 我们会定期将新的Cortex版本部署到集群,以便客户可以利用这些机会-幸运的是,Cortex可以在不停机的情况下进行更新。
为了顺利进行更新,Ingester Cortex服务在更新过程中需要一个附加的Ingester副本。
( 注 : Ingester是Cortex的核心组件。它的任务是收集恒定的样本流,将其分组为Prometheus块,并将其存储在DynamoDB,BigTable或Cassandra等数据库中。)这允许使用较旧的Ingesters。将当前数据转发到新的Ingesters。 值得注意的是,摄取器对资源的要求很高。 对于他们的工作,每个Pod必须具有4个内核和15 GB的内存,即 在我们的Kubernetes集群中,占主机处理器和内存的25%。 通常,与4个核心和15 GB的内存相比,群集中通常有更多的未使用资源,因此我们可以在更新期间轻松运行这些额外的Ingester。
但是,经常会发生这样的情况:在正常运行期间,这些机器都没有拥有这25%的无人认领资源。 是的,我们不努力:CPU和内存对于其他进程总是有用的。 为了解决这个问题,我们决定使用
Kubernetes Pod Priorities 。 这个想法是给Ingesters比其他(无状态)微服务更高的优先级。 当我们需要运行额外的(N + 1)个Ingester时,我们会暂时淘汰其他较小的吊舱。 这些吊舱被转移到其他机器上的空闲资源上,留下了足够大的“空洞”来启动其他Ingester。
7月18日,星期四,我们在集群中启动了四个新的优先级:
关键 ,
高 ,
中和
低 。 他们在没有客户端流量的内部群集上进行了大约一周的测试。 默认情况下,没有给定优先级的Pod会获得
中等优先级;为Ingesters设置了具有
高优先级的类。
关键保留用于监视(Prometheus,Alertmanager,node-exporter,kube-state-metrics等)。 我们的配置已打开,请
在此处查看PR。
意外事故
7月19日,星期五,一位工程师为大型客户启动了一个新的专用Cortex集群。 该集群的配置不包括新的Pod优先级,因此所有新的Pod都被分配了默认优先级
-medium 。
Kubernetes集群没有足够的资源用于新的Cortex集群,并且现有的Cortex生产集群未更新(Ingesters的优先级
较高 )。 由于新集群的Ingesters默认设置为
中等优先级,并且生产中的现有吊舱完全没有优先级,因此新集群的Ingesters将Ingesters赶出了现有的Cortex生产集群。
生产集群中抢占式Ingester的ReplicaSet检测到抢占式Pod,并创建了一个新的Pod以维护指定的副本数。 默认情况下,新的Pod设置为
中等优先级,生产中的下一个“旧” Ingester丢失了资源。 结果是
类似雪崩的过程 ,导致将Ingester的所有豆荚挤出来用于Cortex的生产集群。
摄取器保持状态并存储前12个小时的数据。 这使我们可以在写入长期存储之前更有效地压缩它们。 为此,Cortex使用分布式哈希表(DHT)对系列数据进行分片,并使用Dynamo风格的仲裁一致性将每个系列复制到三个Ingester。 Cortex不会将数据写入已禁用的Ingesters。 因此,当大量的摄取器离开DHT时,Cortex无法提供足够的记录复制,它们会“掉落”。
检测与消除
在关闭开始4分钟后,
基于 “
基于错误预算 ”的新Prometheus通知(基于
错误预算的详细信息将在以后的文章中显示)开始发出警报。 在接下来的五分钟左右,我们进行了诊断,并扩展了基础的Kubernetes集群,以适应新的和现有的生产集群。
五分钟后,旧的Ingesters成功地记录了他们的数据,新的Ingesters启动了,Cortex集群再次可用。
诊断和修复来自位于Cortex前面的反向身份验证代理的内存不足(OOM)错误又花了10分钟。 OOM错误是由QPS增长了十倍引起的(我们认为,这是由于Prometheus客户端服务器的要求过高)。
后果
总停机时间为26分钟。 没有数据丢失。 摄取器已成功将所有内存数据上传到长期存储中。 在关闭期间,Prometheus客户端服务器使用
新的基于WAL的
remote_write API (由Grafana Labs的
Callum Styan创作)将
远程条目保存到缓冲区,并在失败后重复失败的条目。
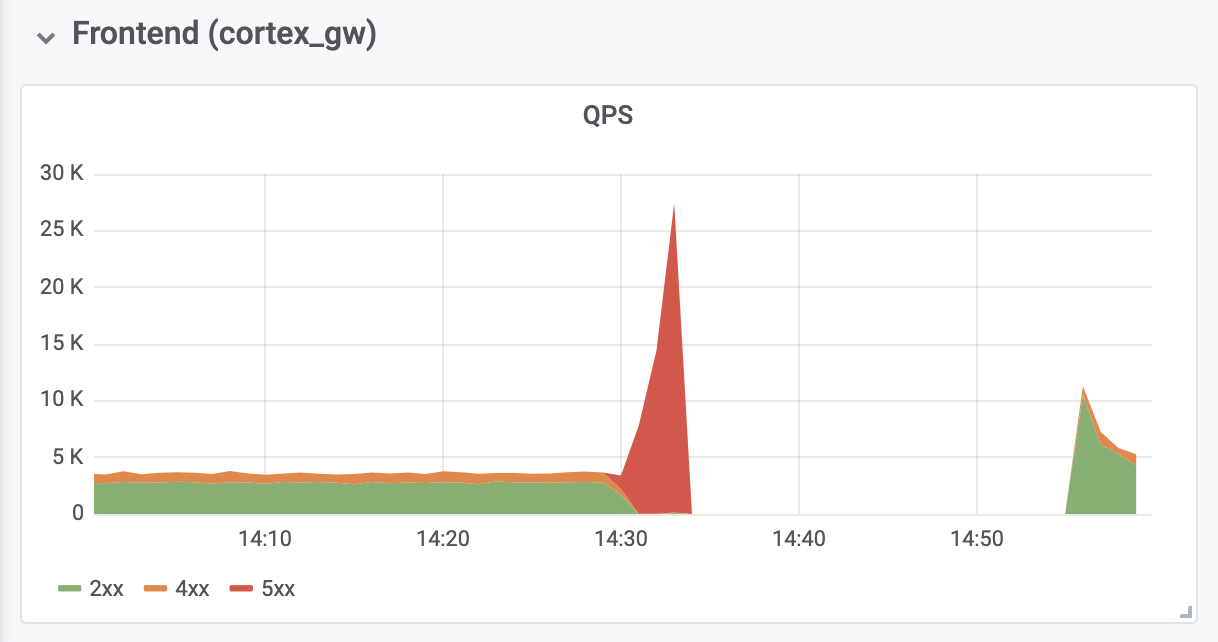 生产集群写操作
生产集群写操作结论
从此事件中学习并采取必要的步骤以避免再次发生是很重要的。
回顾过去,我们必须承认,在生产
中的所有Ingester都具有
高优先级之前,我们不应该将默认优先级设置为
中 。 此外,他们应该事先照顾好他们的
高度优先权。 现在一切都已修复。 我们希望我们的经验可以帮助其他组织考虑在Kubernetes中使用pod优先级。
我们将对任何其他对象的部署添加额外的控制级别,这些对象的配置对于集群是全局的。 从今以后,这种变化将被更多的人评价。 此外,导致失败的修改对于单独的项目文档而言也算是微不足道的-仅在GitHub问题中进行了讨论。 从现在开始,所有此类配置更改将随附适当的项目文档。
最后,我们自动调整了反向身份验证代理的大小,以防止拥塞期间的OOM(我们已目睹),并分析了与回滚和缩放相关的默认Prometheus设置,以防止将来出现类似问题。
经历过的故障还带来了一些积极的后果:在收到必要的资源后,Cortex会自动恢复,而无需任何其他干预。 我们还使用了我们新的日志聚合系统
Grafana Loki积累了宝贵的经验,该系统有助于确保所有Ingester在崩溃期间和之后均能正常运行。
译者的PS
另请参阅我们的博客: