在每个服务产生至少1 Mb / s的Internet流量之前,就会出现一个问题:“如何? 通过TCP还是通过UDP?” 在包括交付平台在内的应用领域中,制定此类决策的偏好和传统已经得到发展。
从理论上讲,例如,如果一个懒惰的开发人员不尝试在Python中部署他的ML(因为他只知道),那么世界极有可能永远不会被这种卑鄙的“超级Java编码器”语言所吸引。 如今,这种语言在过去的应用环境中的弱点无条件地使其在部署和启动大量挖掘A / B时处于首要地位。
您可以进行很多比较:ARM与Intel,iOS和Android,以及Mortal Kombat与Injustice。 并遇到了太空大亨,所以回到提供大量多格式内容的主题。
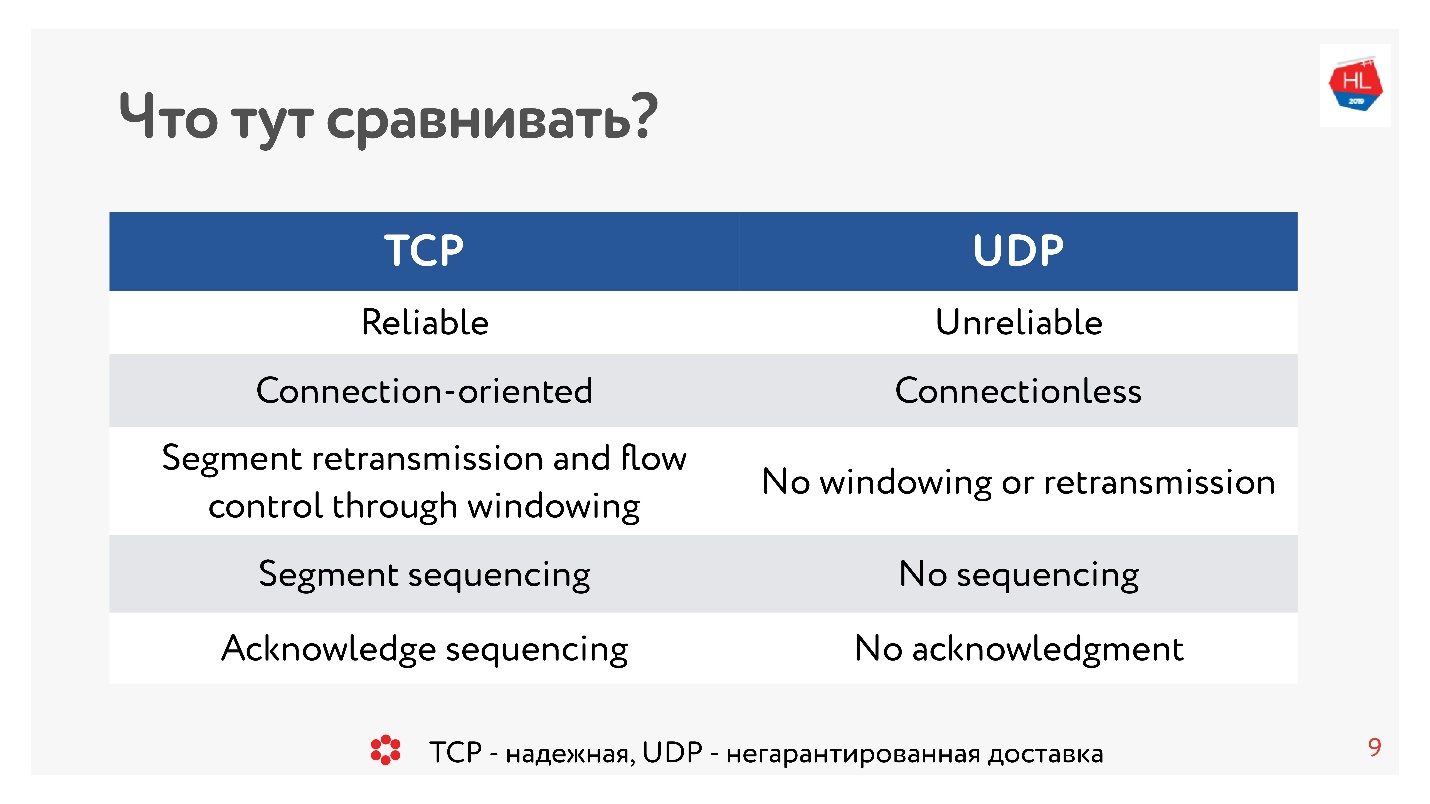
十年前,每个人都绝对确定UDP与无保证的传送有关。 如果您需要可靠的协议,则使用TCP。 与本文的传统相反,我们将比较看似不可比的事物,例如TCP和UDP。
 注意,切下的99个插图和图表均重要。
注意,切下的99个插图和图表均重要。比较由OK
Alexander Tobol (
alatobol )的视频和磁带平台的开发负责人进行。 社交网络上的服务视频和新闻源OK-仅涉及内容及其在任何不良或良好网络条件下向所有现有客户端平台的交付以及如何通过TCP或UDP交付的问题至关重要。
TCP与UDP。 最小理论
为了进行比较,我们需要一些基本理论。
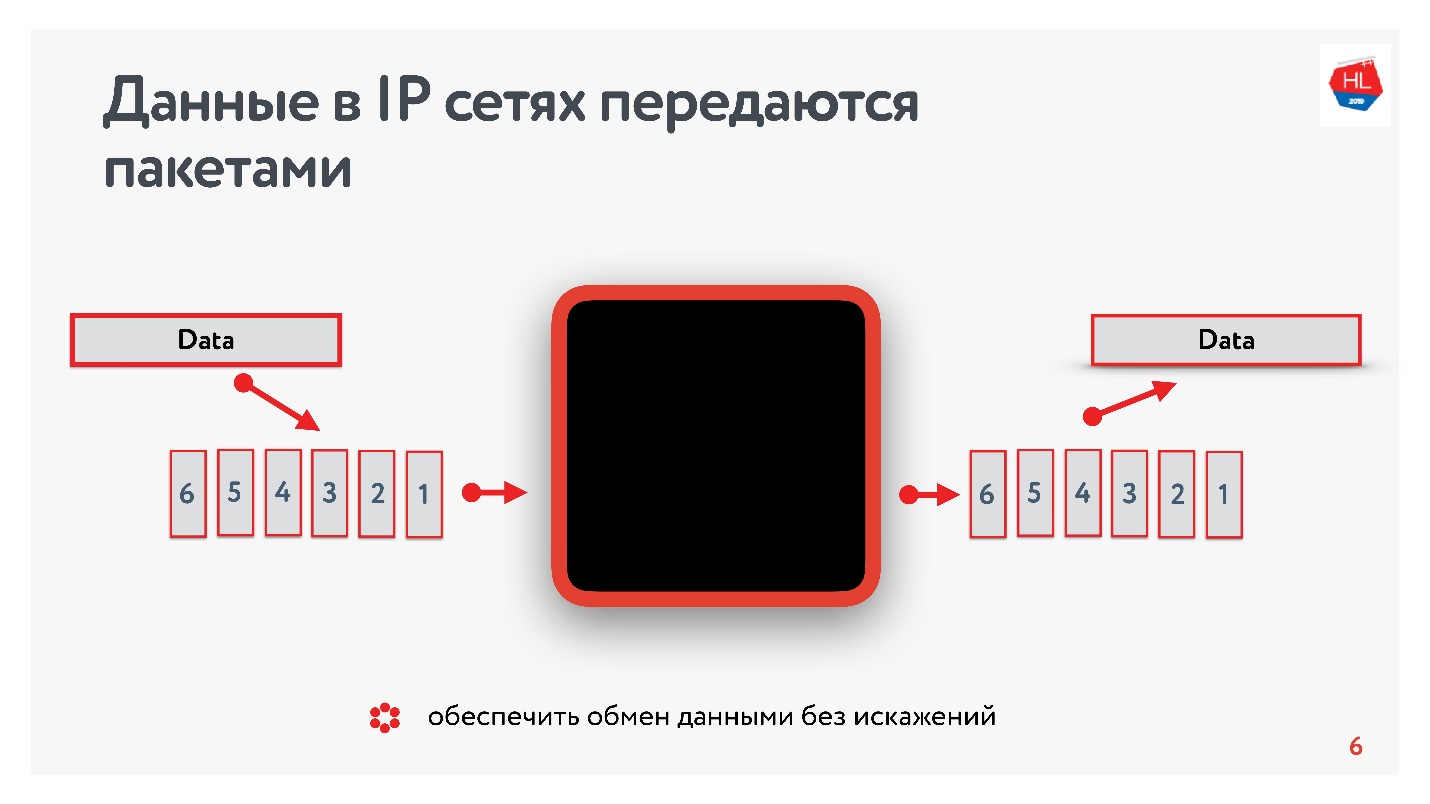
我们对IP网络了解多少? 您发送的数据流分为数据包,某种黑匣子将这些数据包传递给客户端。 客户端收集数据包并接收数据流。 通常,这都是透明的,无需考虑较低级别的内容。
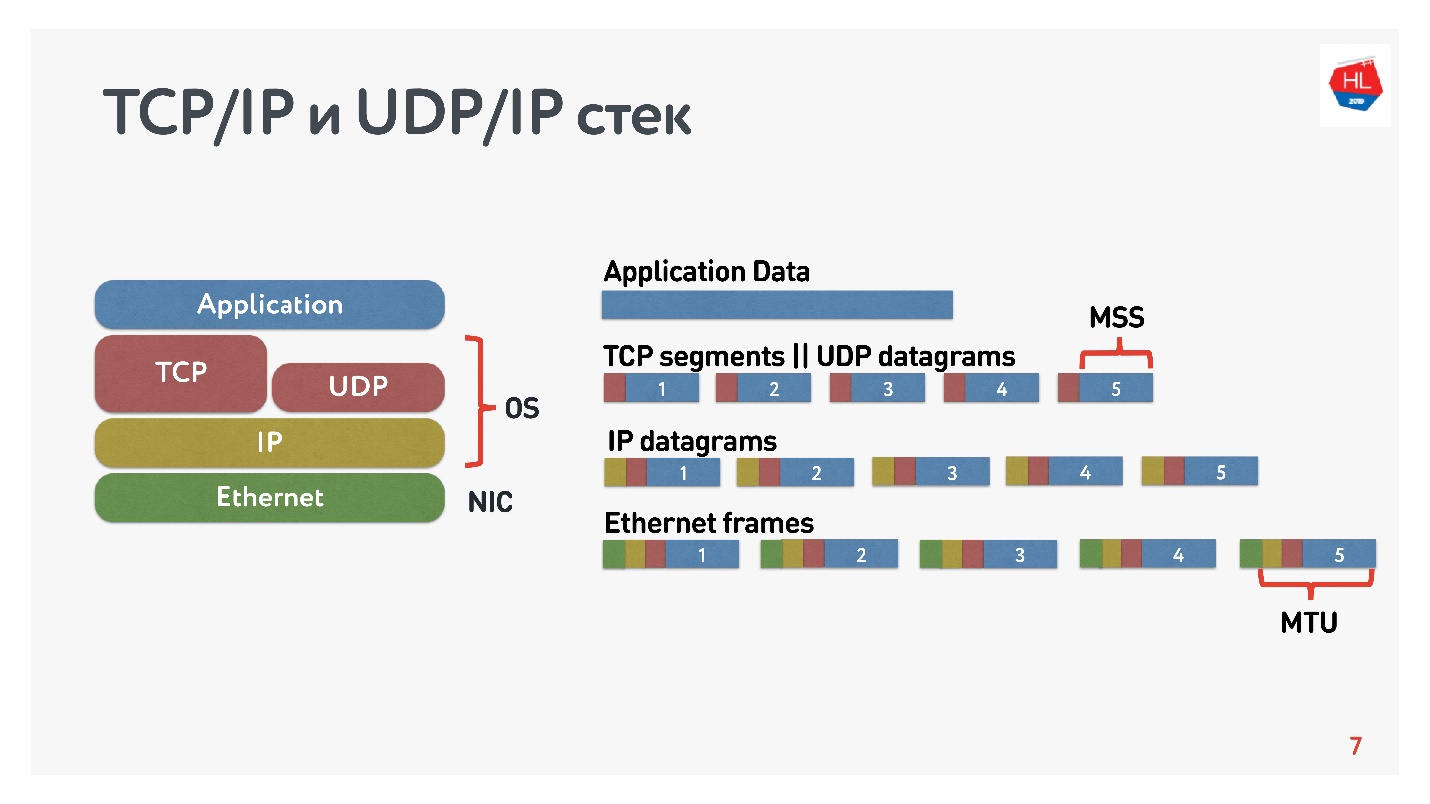
该图显示了TCP / IP和UDP / IP堆栈。 在底部有以太网数据包,IP数据包,在操作系统级别还有TCP和UDP。 此堆栈中的TCP和UDP彼此之间并没有太大区别。 它们封装在IP数据包中,应用程序可以使用它们。 要查看差异,您需要查看TCP和UDP数据包的内部。
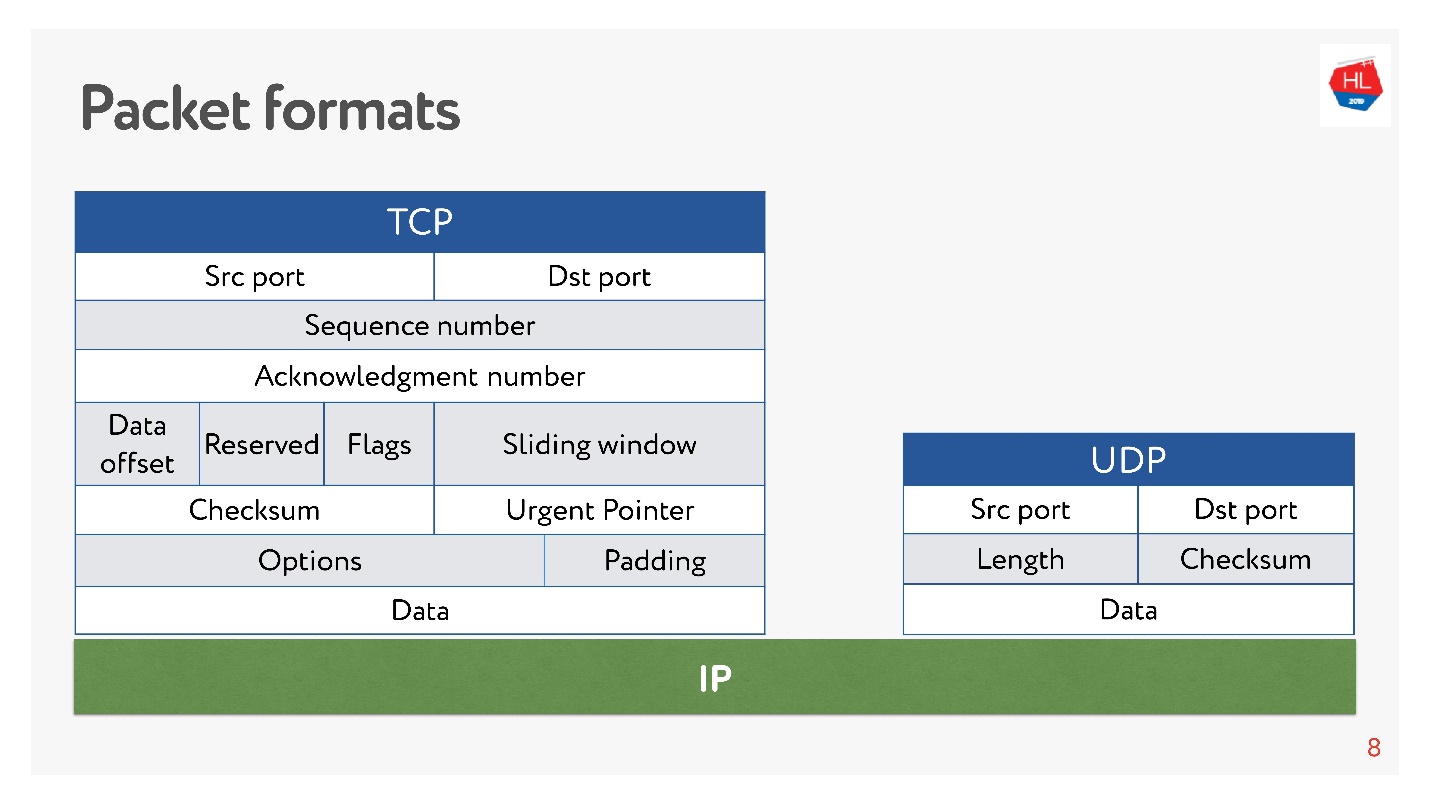
那里和那里都有港口。 但是
在UDP中只有一个校验和 -数据包长度,该协议尽可能简单。 在TCP中,有很多数据可以清楚地指示窗口,确认,序列,数据包等。 显然,
TCP更复杂 。
粗略地说,TCP是一种可靠的传输协议,而UDP是一种不可靠的协议。
然而,尽管据称UDP不可靠,我们仍将弄清楚是否有可能比使用TCP更快,更可靠地传送数据。 让我们尝试从内部看一下网络,并了解其工作原理。 在此过程中,我们将涉及以下问题:
- 为什么比较TCP或它有什么问题;
- 用什么和什么应该比较TCP;
- Google做了什么以及做出了什么决定;
- 网络协议的未来等待着我们。
本文不会有理论:OSI级别和模型,复杂的数学模型,尽管可以通过它们来计算所有内容。 我们将最大程度地分析如何不从理论上而是由我们自己动手接触网络。
为什么要比较TCP或它有什么问题
TCP是1974年发明的,20年后,当我上学时,我买了网卡,删除了代码,然后打电话到某个地方。 此外,如果您从2夜到早上7点打电话,那么互联网是免费的,但很难接通。
又过了20年,移动无线网络上的用户开始胜过“有线”用户,而TCP在概念上没有改变。
移动世界赢了,无线协议出现了,TCP仍然没有改变。
如今,80%的用户使用Wi-Fi或3G-4G无线网络。

在无线网络中,有:
- 数据包丢失-我们发送的大约0.6%的数据包在途中丢失;
- 重新排序-在现实生活中,在某些地方对包装进行重新安排是一种相当罕见的现象,但这种情况发生在0.2%的情况下;
- 抖动-数据包均匀发送并以大约50毫秒的延迟到达队列时。
TCP成功地向您隐藏了异构网络中数据传输的所有这些功能,您无需陷入内部。
地图下方是俄罗斯的平均TCP数据速率。 如果删除西部部分,很明显,速度的测量单位是千位而不是兆位。
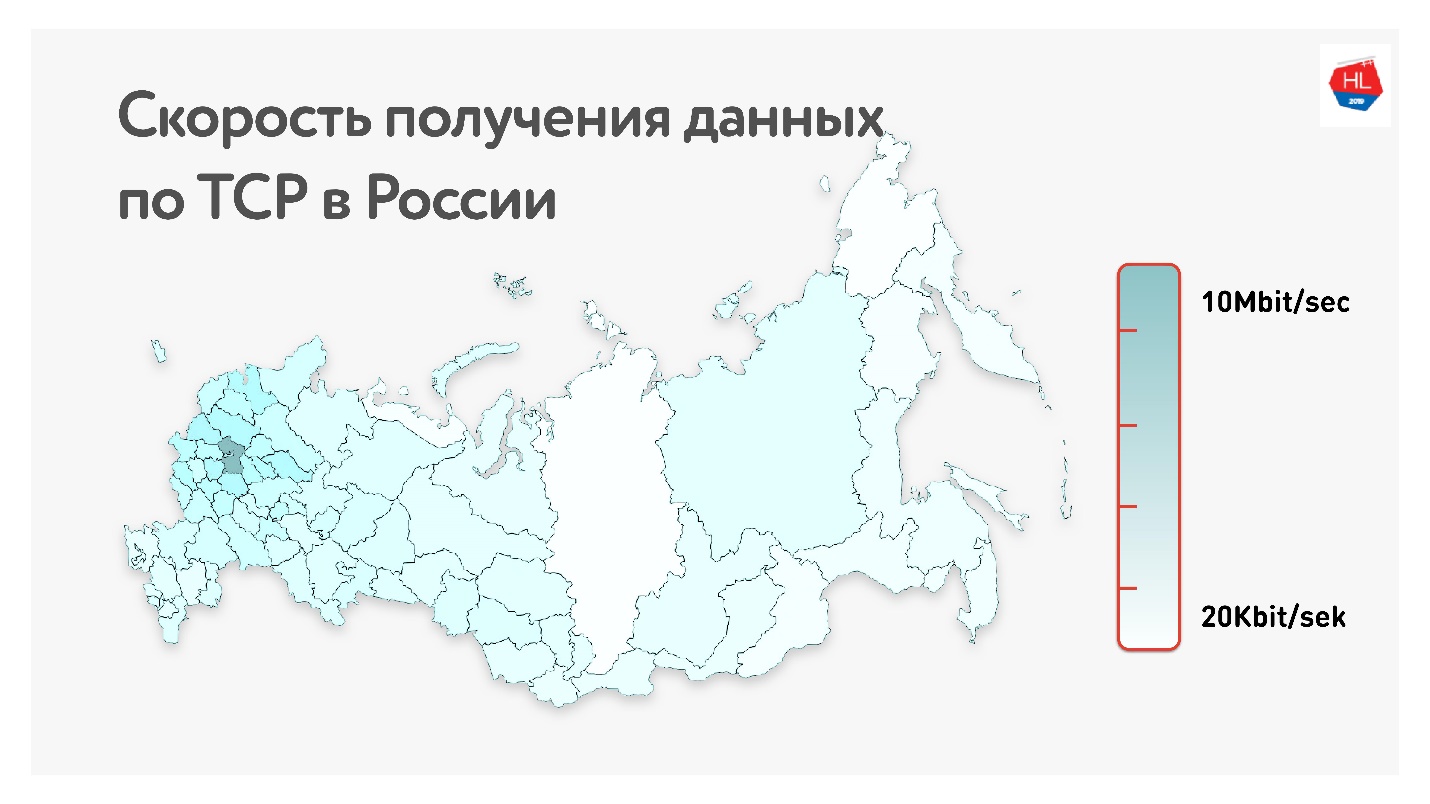
也就是说,对于我们的用户(不包括俄罗斯西部)而言,平均而言:吞吐量为1.1 Mbps,丢包率为0.6%,RTT(往返时间)约为200毫秒。
如何计算RTT
当我看到平均200毫秒时,我以为统计数据有误,因此决定使用RIPE Atlas以另一种方式测量MSC中我们服务器的RTT。 这是一个用于收集有关Internet状态的数据的系统。
RIPE Atlas探针是免费提供的。
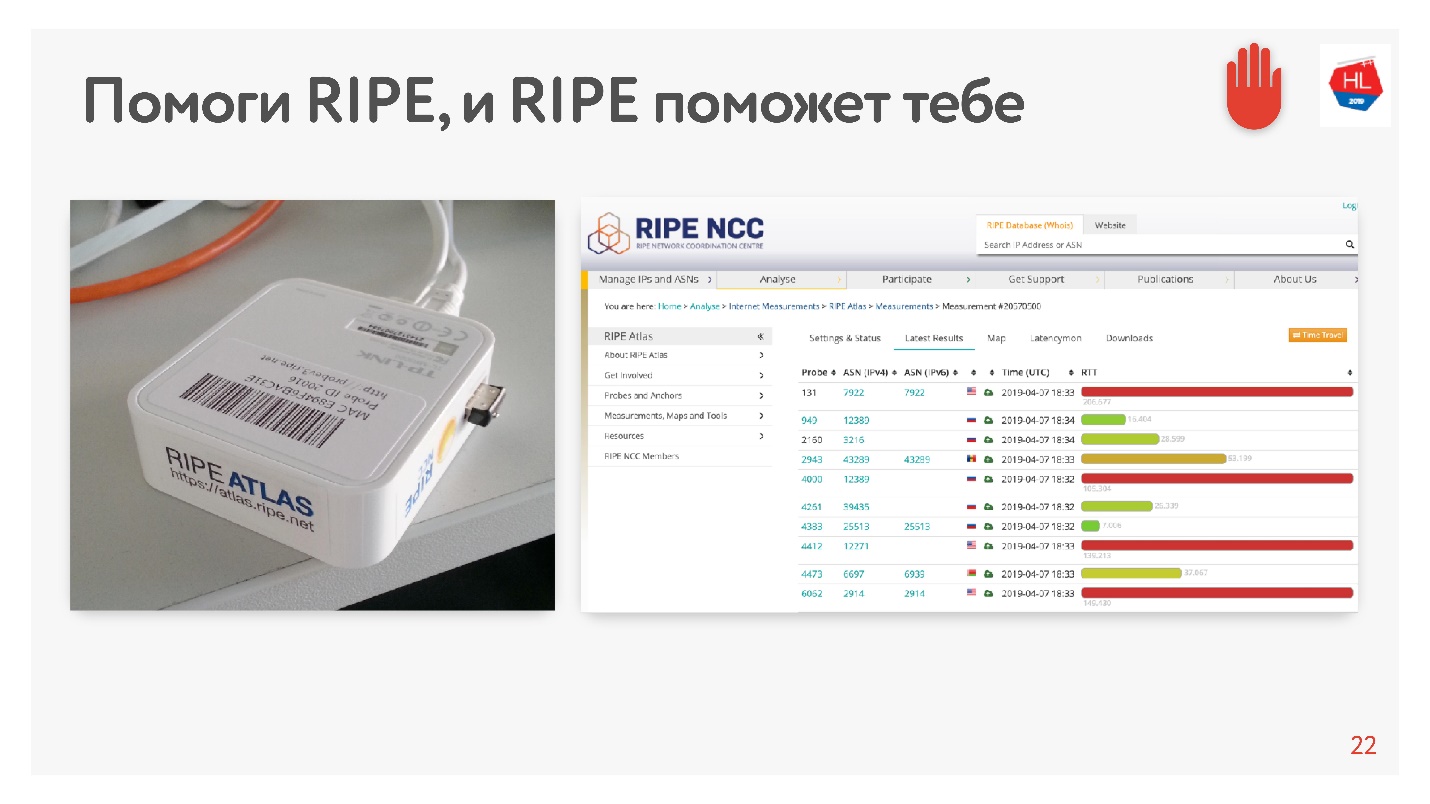
底线是您将其连接到家庭Internet并收集“业力”。 她工作了几天,有些人满足了她的一些要求。 然后,您可以自己设置各种任务。 此类任务的一个示例:意外地在Internet上获得30分,并要求测量RTT,即对Odnoklassniki网站执行ping命令。
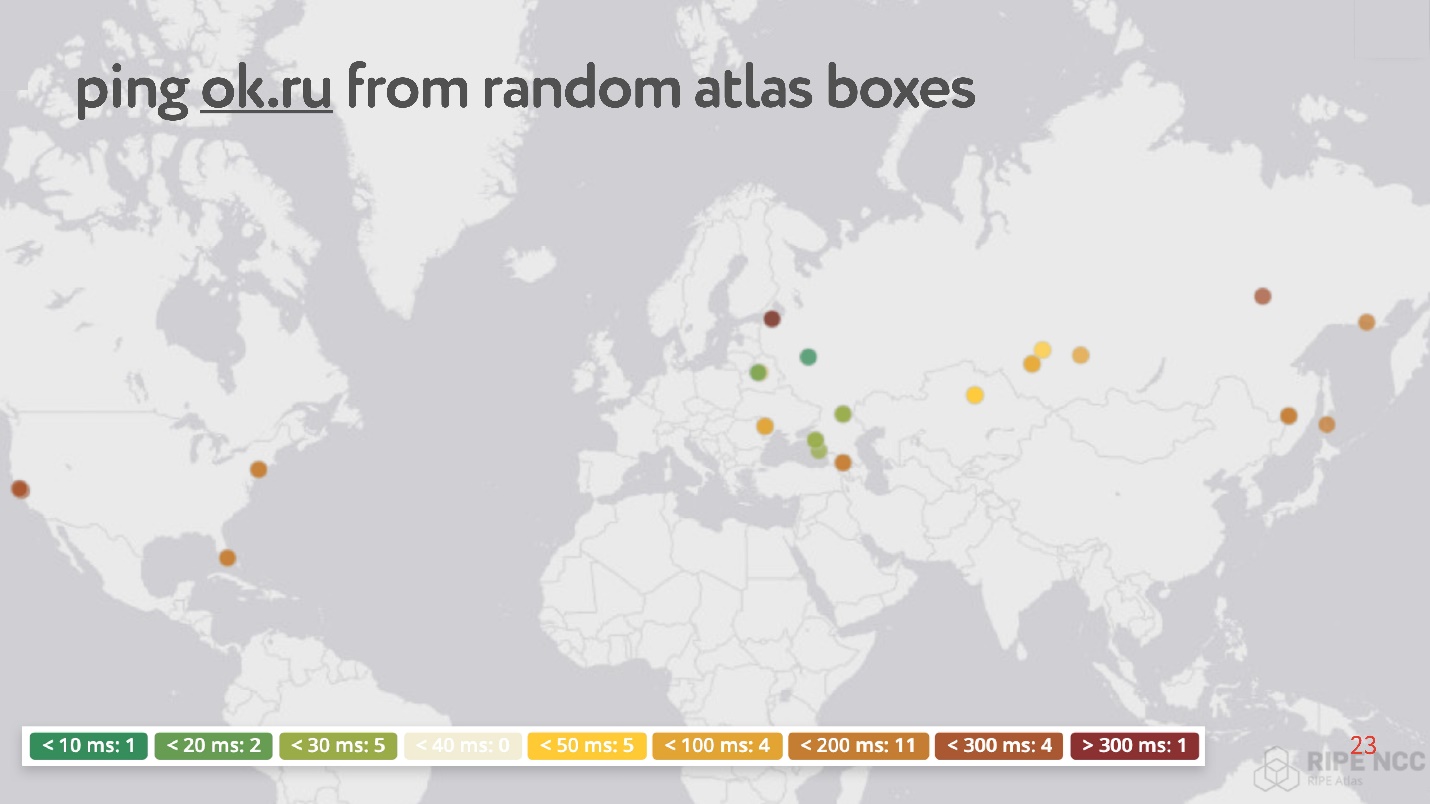
奇怪的是,在随机点中,有很多这样的点的ping从200到300 ms。
总的来说,
无线网络是流行且不稳定的 (尽管通常会忽略后者,因为据信TCP可以处理此问题):
- 超过80%的用户使用无线互联网;
- 无线网络的参数例如根据用户转弯的事实而动态地变化。
- 无线网络的丢包率,抖动和重排序率很高。
- 固定非对称通道,更改IP地址。
内容消耗取决于互联网速度
这很容易验证-统计数据很多。 我对视频进行了
统计 ,结果表明该国的互联网速度越高,观看视频的用户就越多。
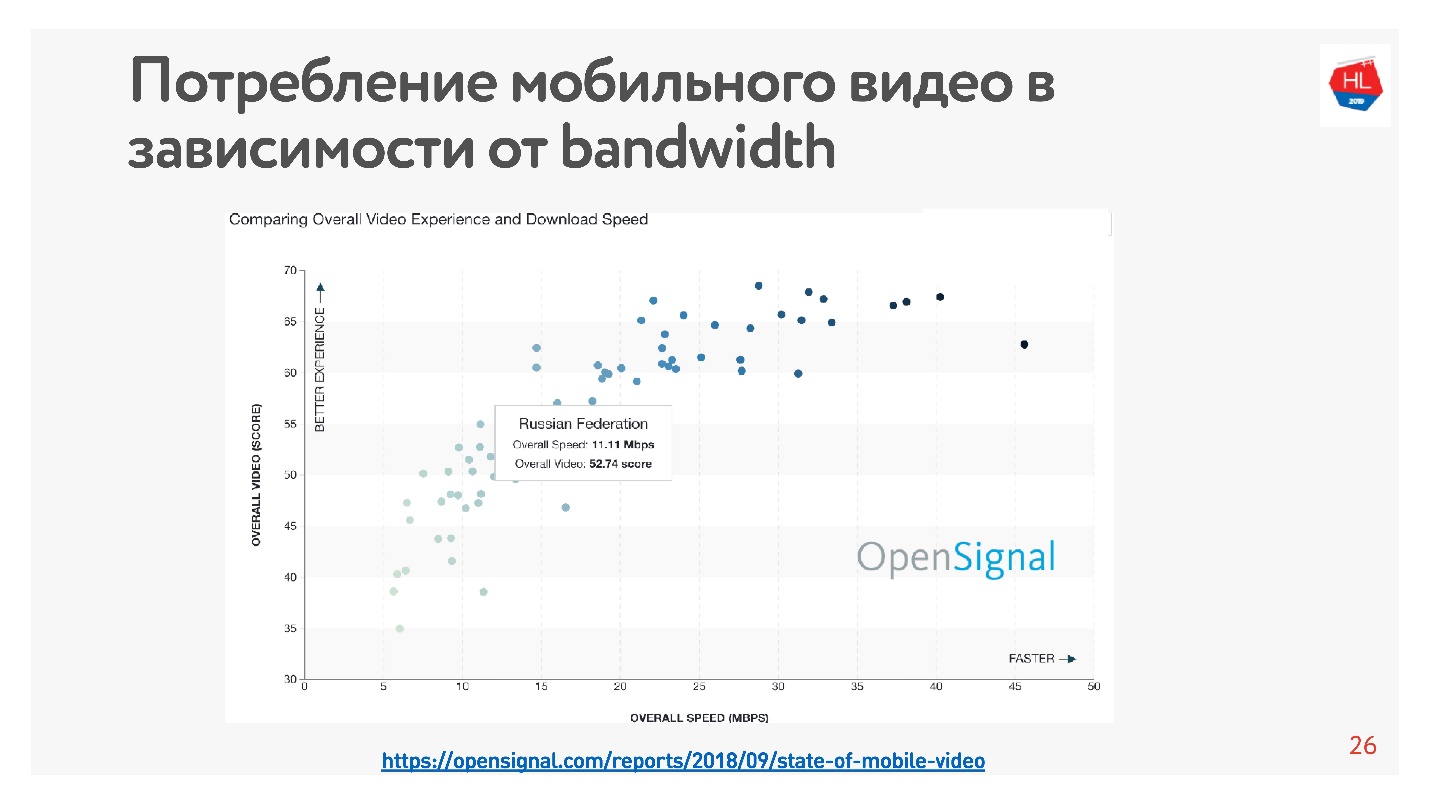
根据这些统计数据,俄罗斯的互联网速度相当快,但根据我们的内部数据,平均速度略低。
支持整个互联网速度不足的事实,它表示大型应用程序,社交网络,视频服务等的所有创建者都在优化其服务以在不良网络中工作。 接收到10 Kb的数据后,您可以在磁带中看到最少的信息,而以500 Kb的速度可以观看视频。
如何加快加载
在开发视频平台的过程中,我们意识到TCP在无线网络中不是很有效。 您是如何得出这个结论的?
我们决定加快下载速度,并做了下一个技巧。
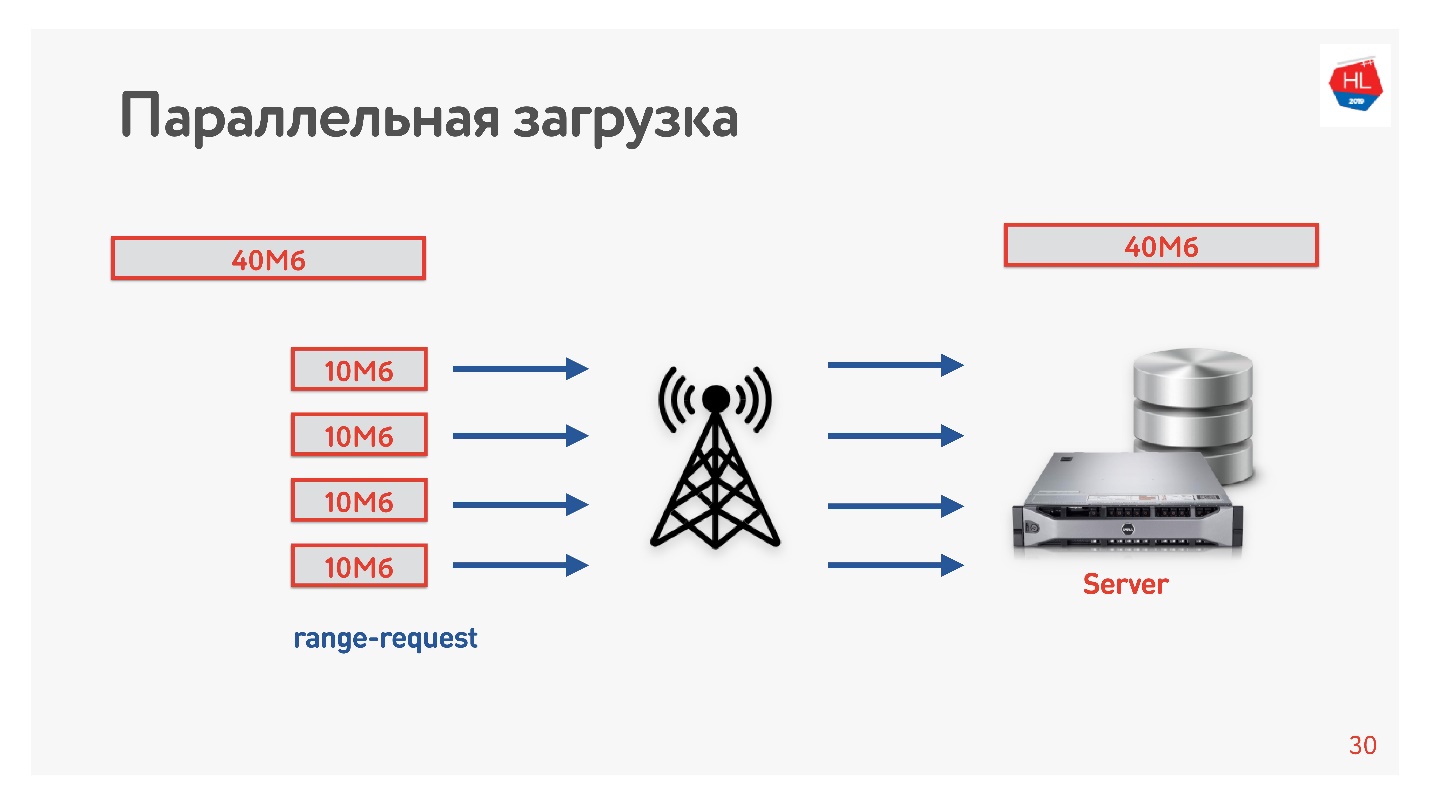
我们将视频从客户端以几种流的形式从客户端下载到服务器,即40 MB被分成10 MB的4部分并并行加载。 我们在Android上启动了它,并发现它并行加载的速度比一次连接快(报告中的
演示 )。 最有趣的是,当我们将并行下载产品投入生产时,我们发现在某些地区,下载速度提高了3倍!
四个TCP连接实际上可以将数据上传到服务器的速度提高了3倍。
因此,我们提高了视频下载速度,并得出结论认为需要并行下载。
不稳定网络中的TCP
可以触摸到令人难以置信的并行效果。 只需使用一个速度计来接收/发送数据(例如,速度测试)和流量整形器(例如,网络链接调节器,如果您使用的是Mac)就足够了。我们将网络的上传和下载限制为1 Mbps参数,并开始增加数据包丢失。

该表显示了RTT和损耗。 可以看出,在0%丢失的情况下,网络利用率为100%。
在下一次迭代中,我们将数据包丢失量增加了5%,而我们发现仅74%的网络被利用。 看起来还可以-丢包率为5%,网络丢失了26%。 但是,如果您还增加ping,则将保留
不到一半的通道 。
如果通道具有高RTT和大数据包丢失,则一个TCP连接不能完全利用网络。
另一个技巧表明,如果您开始使用并行TCP连接(可以同时运行多个速度测试),则可以看到通道利用率的反向增长。
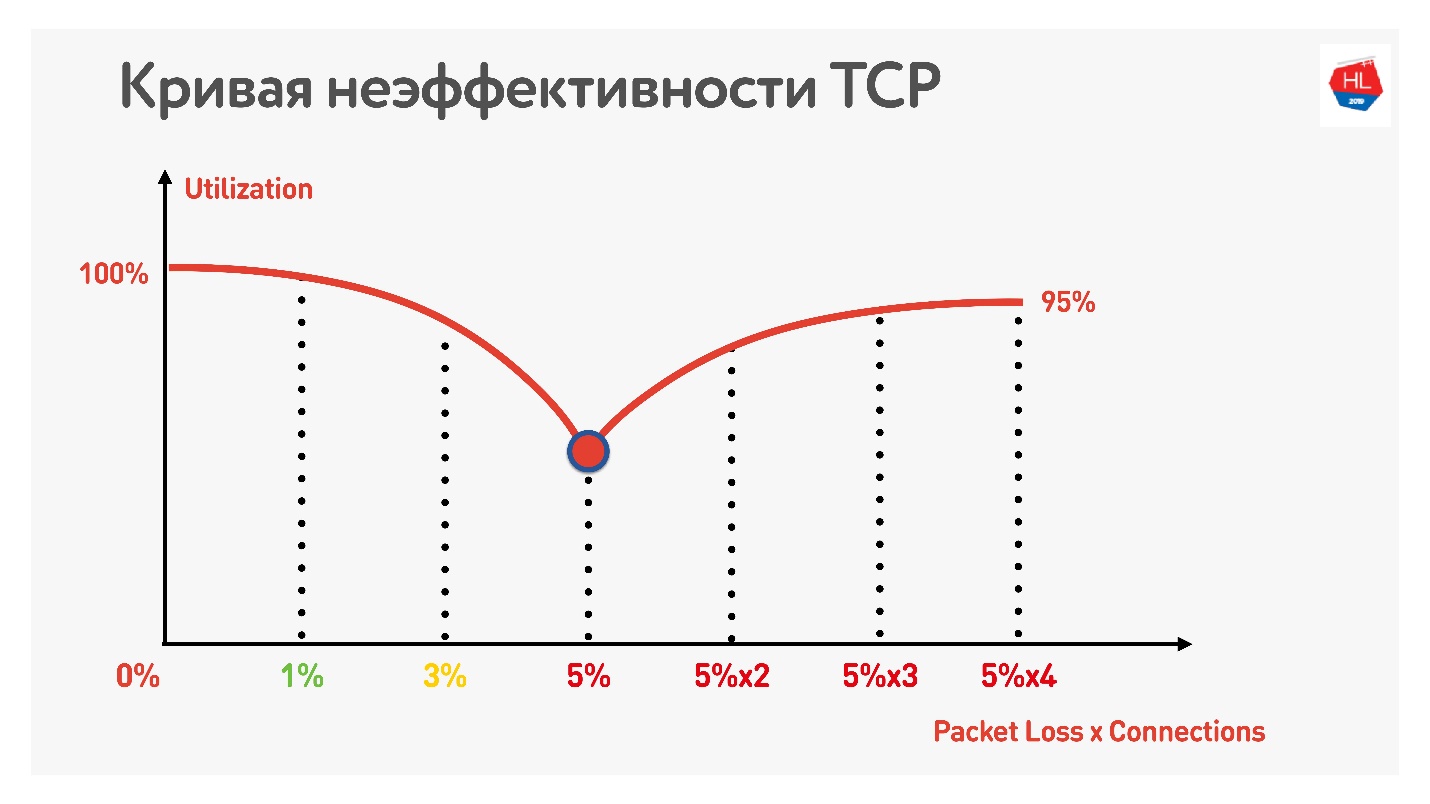
随着并行TCP连接数量的增加,网络利用率几乎等于吞吐量,减去损失百分比。
因此,结果是:
- 无线移动网络已经赢得并且不稳定。
- 在不稳定的网络中,TCP无法充分利用该通道。
- 内容消耗取决于互联网的速度:互联网的速度越高,观看的用户越多,我们真的很喜欢我们的用户并希望他们观看更多的内容。
显然,您需要移动到某个地方并考虑TCP的替代方法。
TCP与非TCP
如何比较温暖? 有两种选择。
第一种选择-在IP级别上有TCP和UDP,我们可以从上面提供其他协议。 显然,如果您同时启动自己的协议和TCP和UDP,则防火墙,Brandmauer,路由器以及其他与数据包传递有关的领域将不知道它。 结果,当所有设备更新并开始使用新协议时,您将不得不等待数年。
第二种选择是在不可靠的UDP之上建立自己的可靠数据传输协议。 显然,您可以等待很长时间,直到Linux,Android和iOS向内核添加新协议为止,因此您需要将该协议切入用户空间。
这种解决方案似乎很有趣,我们将其称为自制的UDP协议。 开始开发它,不需要任何特殊操作:只需打开UDP套接字并发送数据即可。
我们将在研究网络工作原理的同时开发它。
TCP与自制UDP
好了,在什么比较上呢?
网络不同:
- 在拥塞的情况下,当有很多数据包并且其中一些由于信道或设备的拥塞而丢弃时。
- 大往返的高速(例如,当服务器相对较远时)。
- 奇怪-网络上似乎什么也没发生,但是数据包仍然消失的原因仅仅是因为Wi-Fi接入点在墙后。
您随时可以自己触摸网络配置文件:在手机上选择一个或另一个配置文件,然后运行速度测试。

除了网络配置文件之外,您还需要确定流量消耗的配置文件。 这是我们使用的:
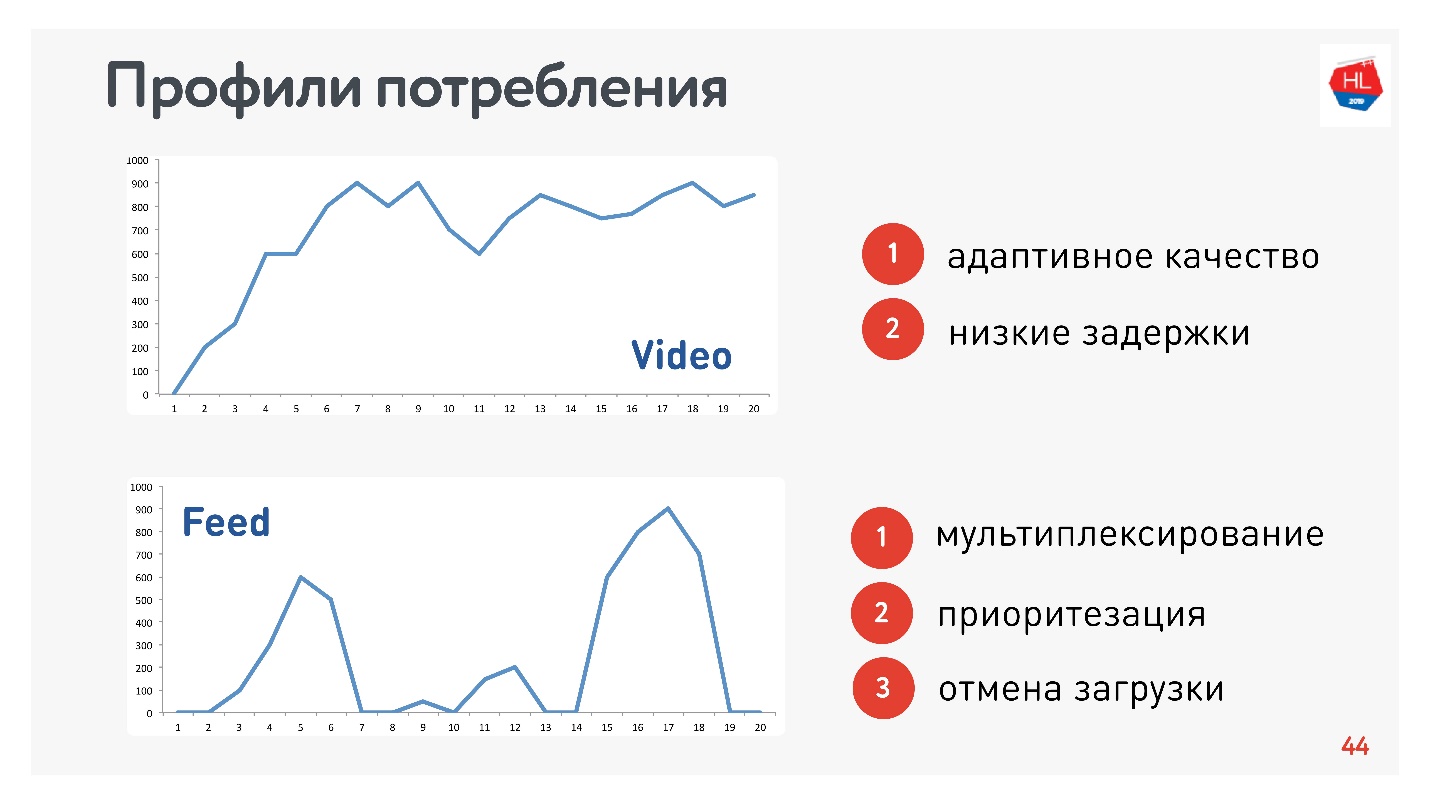
由于我负责视频和视频流,因此配置文件是合适的:
- 配置文件视频,当您连接并流式传输此内容时。 如上图所示,连接速度增加。 该协议的要求:低延迟和比特率自适应。
- 磁带视图选项:脉冲数据加载,后台查询,停机时间。 该协议的要求:接收到的数据被多路复用并确定优先级,用户内容的优先级高于后台进程,下载被取消。
当然,您需要比较最流行的HTTP上的协议。
HTTP 1.1和HTTP 2.0
2000年代的标准堆栈看起来像基于SSL的HTTP 1.1。 现代堆栈是HTTP 2.0,TLS 1.3和所有基于TCP的堆栈。
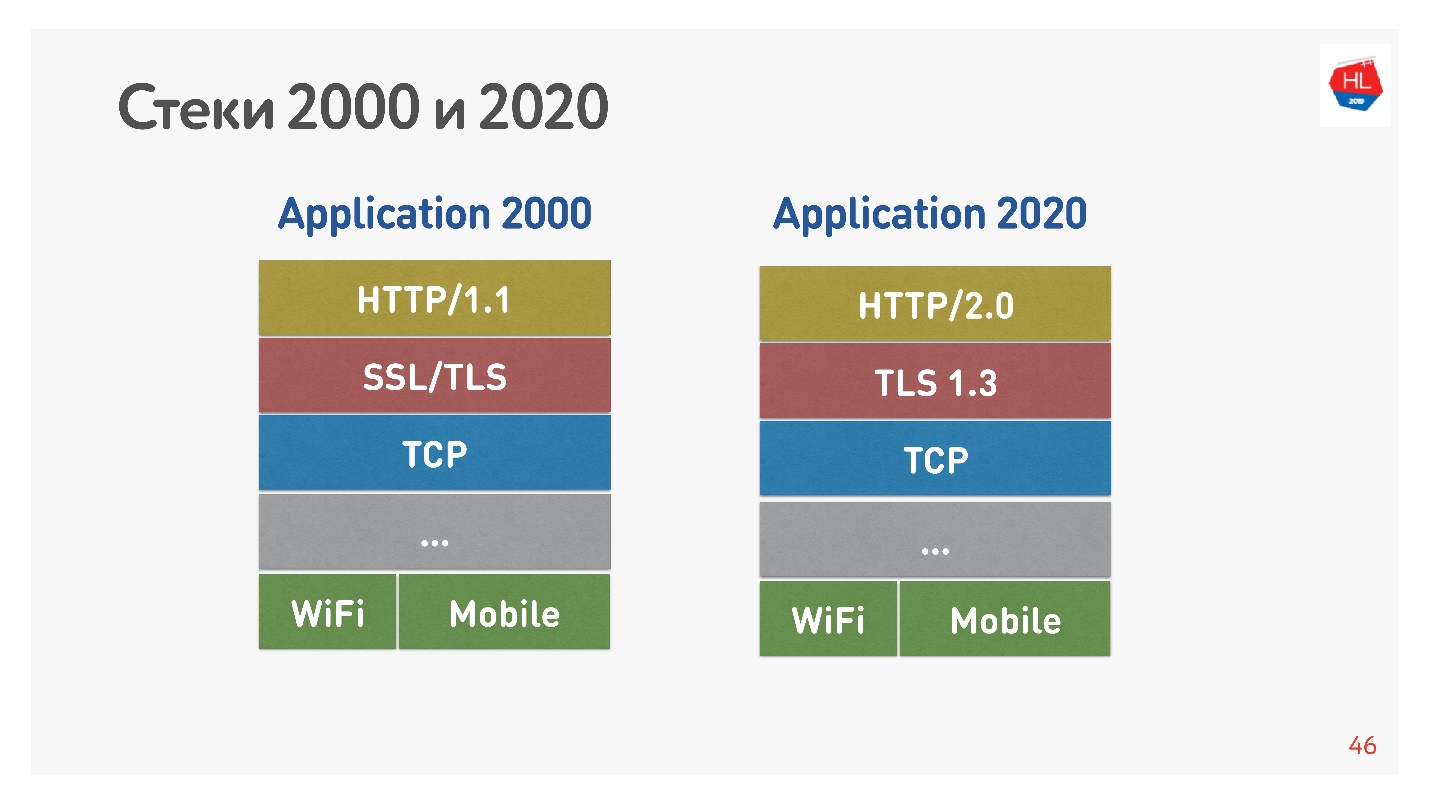
主要区别在于HTTP 1.1使用浏览器中到一个域的有限连接池,因此它们为图片,数据等创建了一个单独的域。 HTTP 2.0提供了一个多路复用连接,所有这些数据都在其中传输。
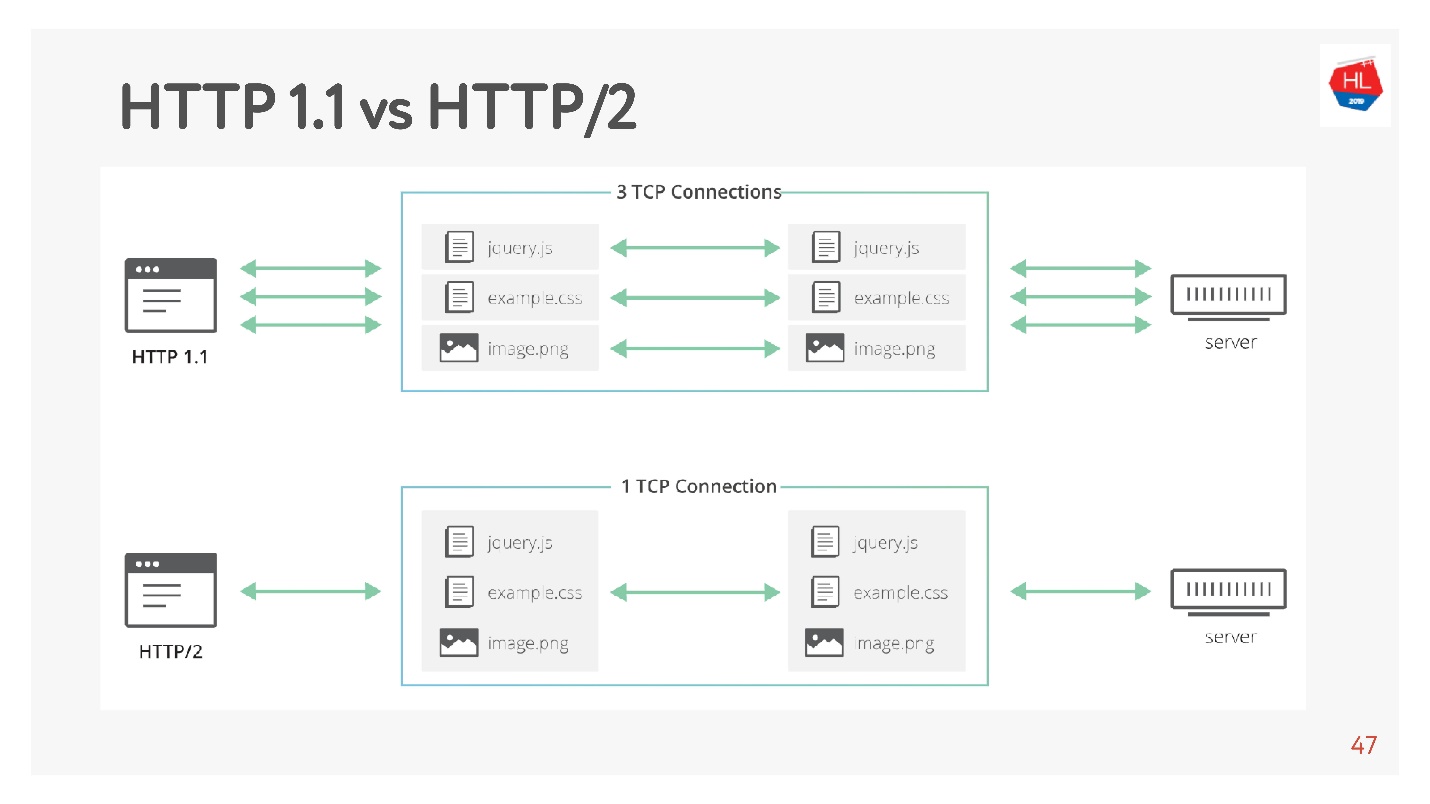
HTTP 1.1的工作方式如下:发出请求,获取数据,发出请求,获取数据。
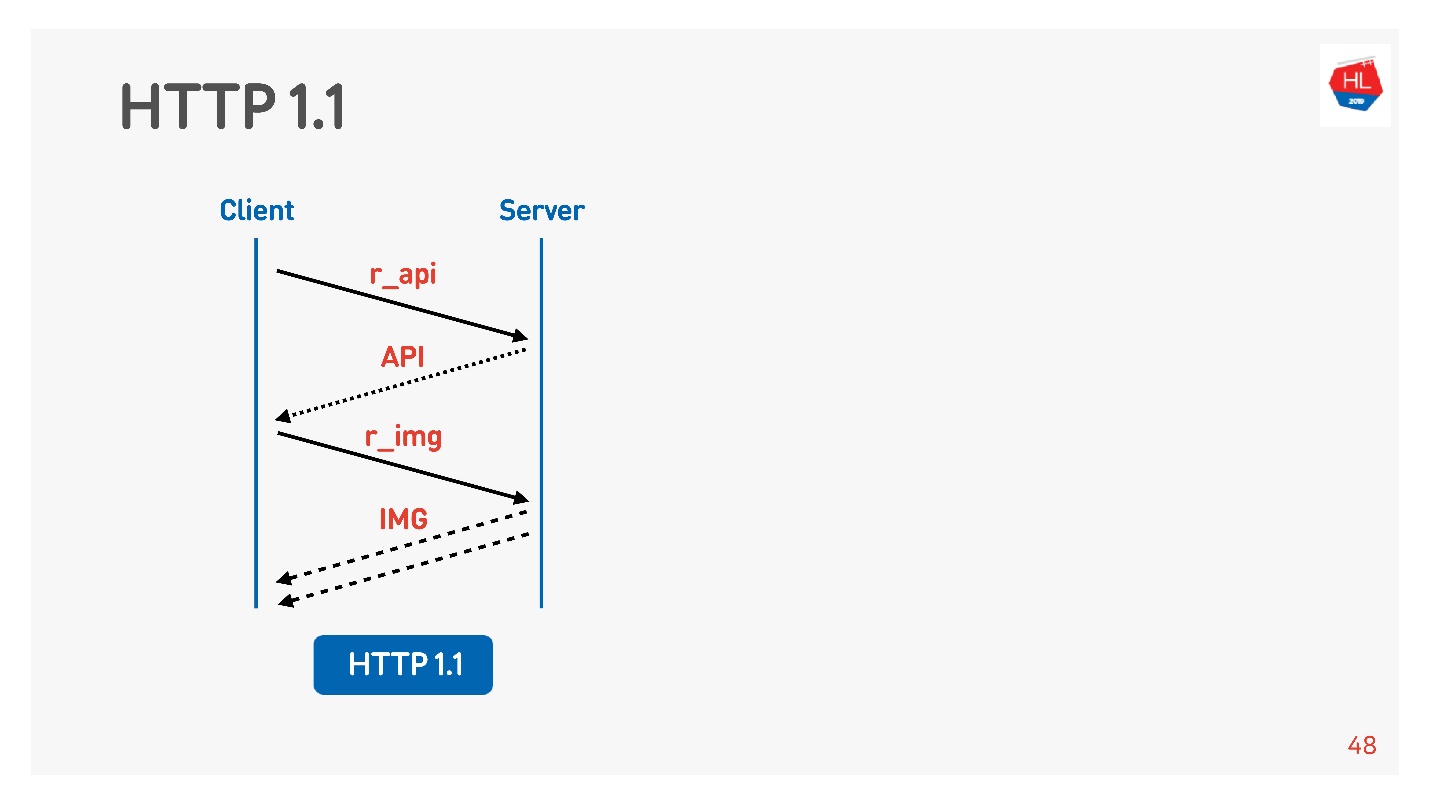
通常,浏览器或移动应用程序是项目符号,即通过API接收图片,数据的连接,并且您同时执行对图片,API,视频等的请求。
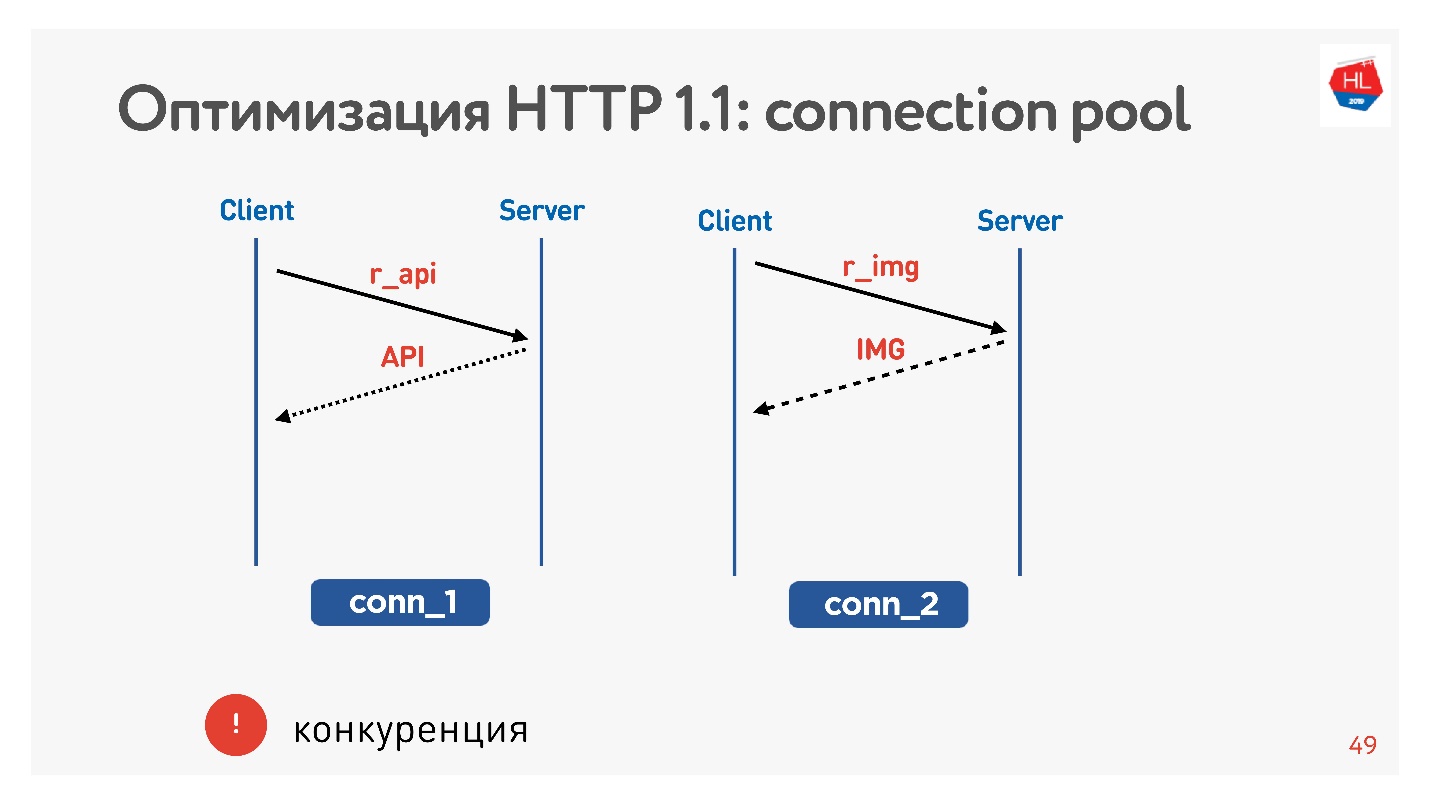
主要问题是竞争。 您无法控制已提交的请求。 您了解到,用户不再需要他翻过的图片,但无能为力。
使用HTTP 1.1,您仍然可以得到所需的内容,很难取消下载。
唯一可能的套接字套接字是关闭连接。 然后我们将了解为什么这很糟糕。
HTTP 2.0的差异
HTTP 2.0解决了以下问题:
- 二进制头压缩
- 数据多路复用;
- 优先次序;
- 取消下载;
- 服务器推送
让我们考虑对我们来说更重要的一点。
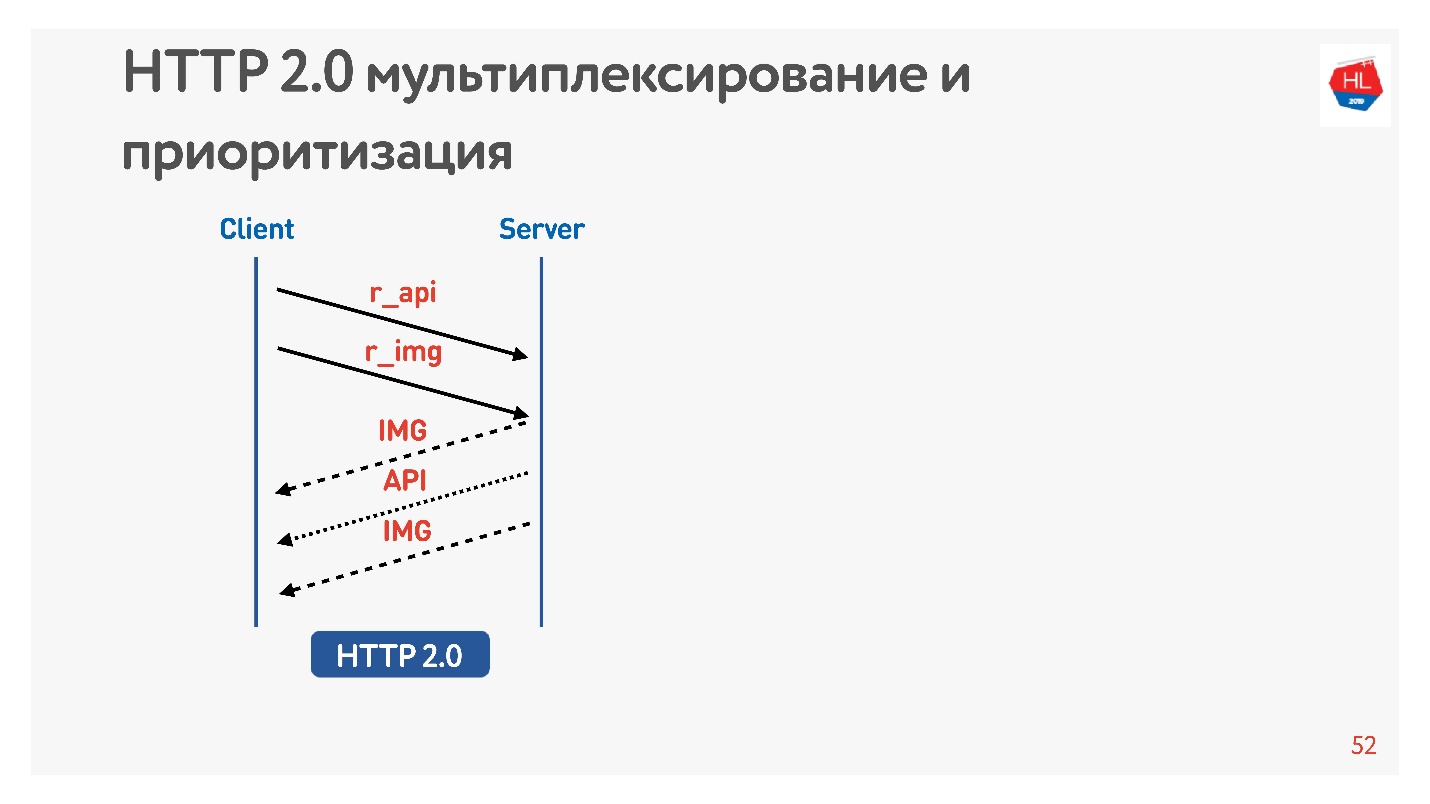
索取图片和API。 图片马上给出,过一会儿就准备好了API。 提供了API-图片已结束。 所有这些透明地发生。
高优先级内容会提前下载。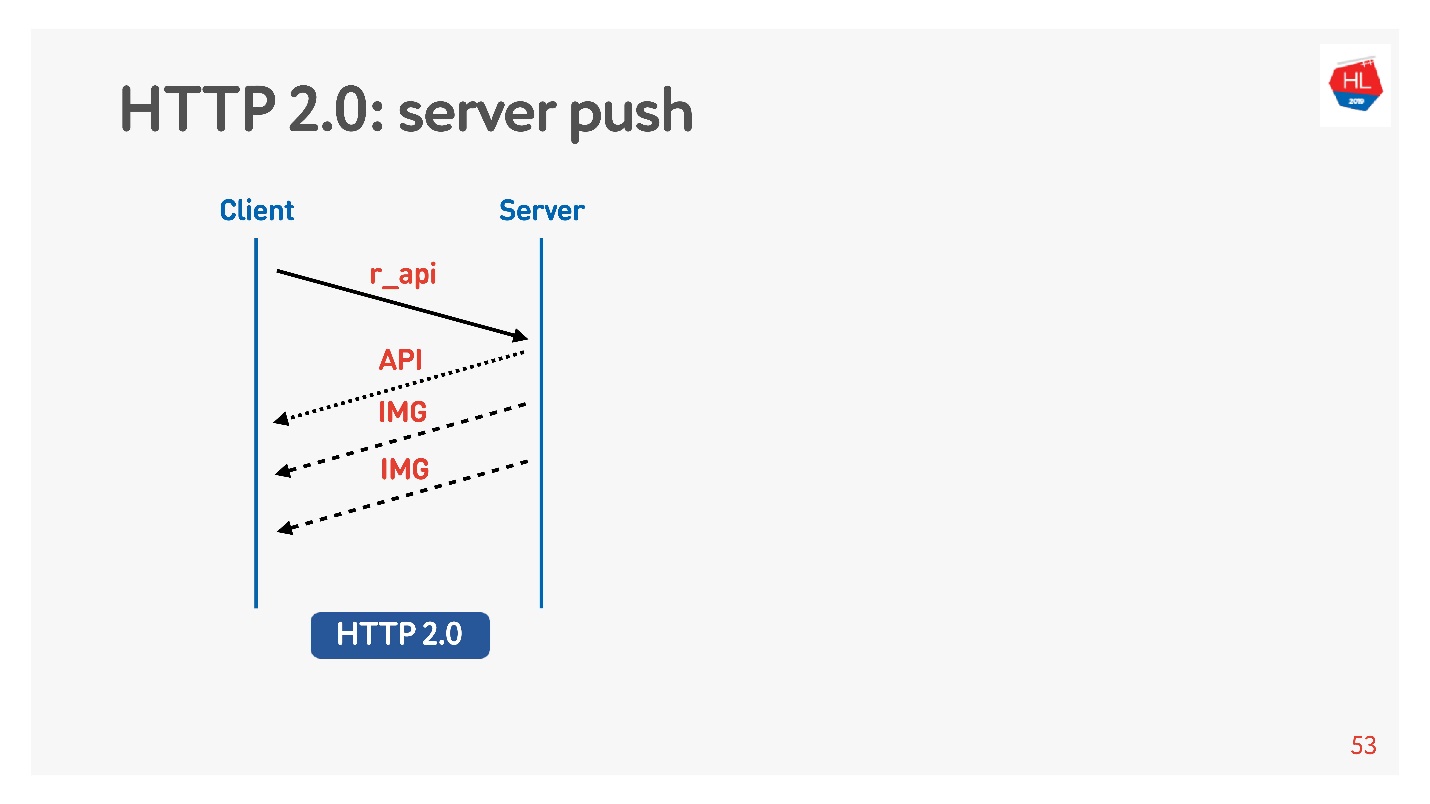
当您请求特定的东西(例如API)时,
服务器推送就是这样,但是即使在客户端的负载中,也确实需要查看图片(例如,查看磁带)。
还有一个
Reset stream命令,如果您在页面之间切换,浏览器将自行执行。 对于移动客户端,在其帮助下,您可以拒绝接收数据而不会丢失连接。
因此,我们将比较不同的TCP:
- 网络配置文件:Wi-Fi,3G,LTE。
- 消费配置文件:流(视频),多路复用和优先级,取消下载(HTTP / 2)以接收磁带的内容。
无损模型
让我们从一个只有两个参数的简单网络开始进行比较:往返时间和带宽。
RTT正在ping,数据包的周转时间,确认的接收或响应回波时间。
为了测量
带宽 -网络带宽-我们发送一个数据包包并计算在特定时间间隔内传输的数据包数量。
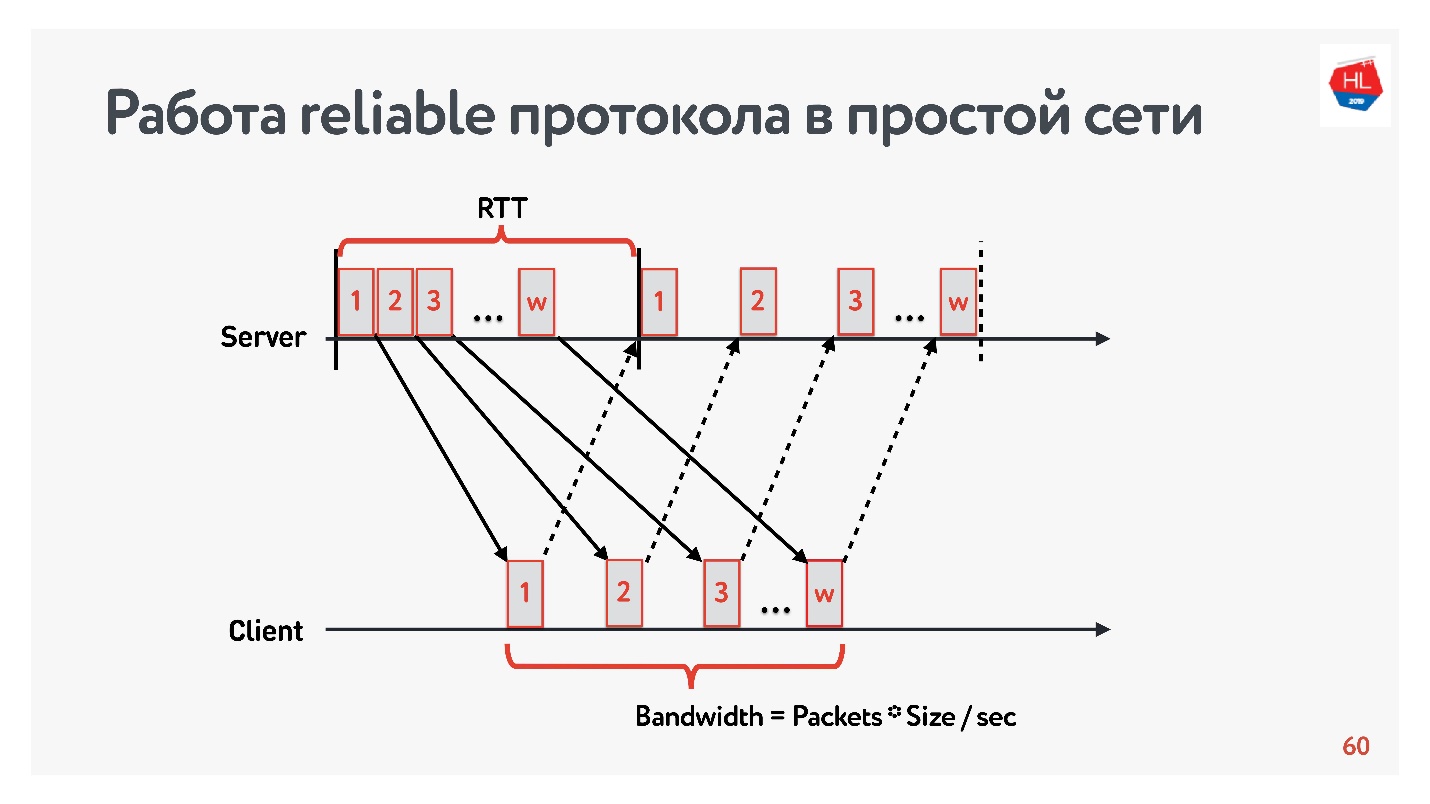
由于我们使用可靠的协议,因此肯定会有一个确认-我们发送数据包并收到收货确认。
互联网速度慢的问题
在2013年我们视频服务发展的曙光中,我的朋友去了加利福尼亚,决定在Odnoklassniki上观看他最喜欢的系列的新节目。 他在Google园区拥有250毫秒的RTT,完美的Wi-Fi 400 Mbps,他想观看FullHD的新系列。
您认为他能够观看视频吗? 答案取决于我们服务器上发送/接收缓冲区的配置。
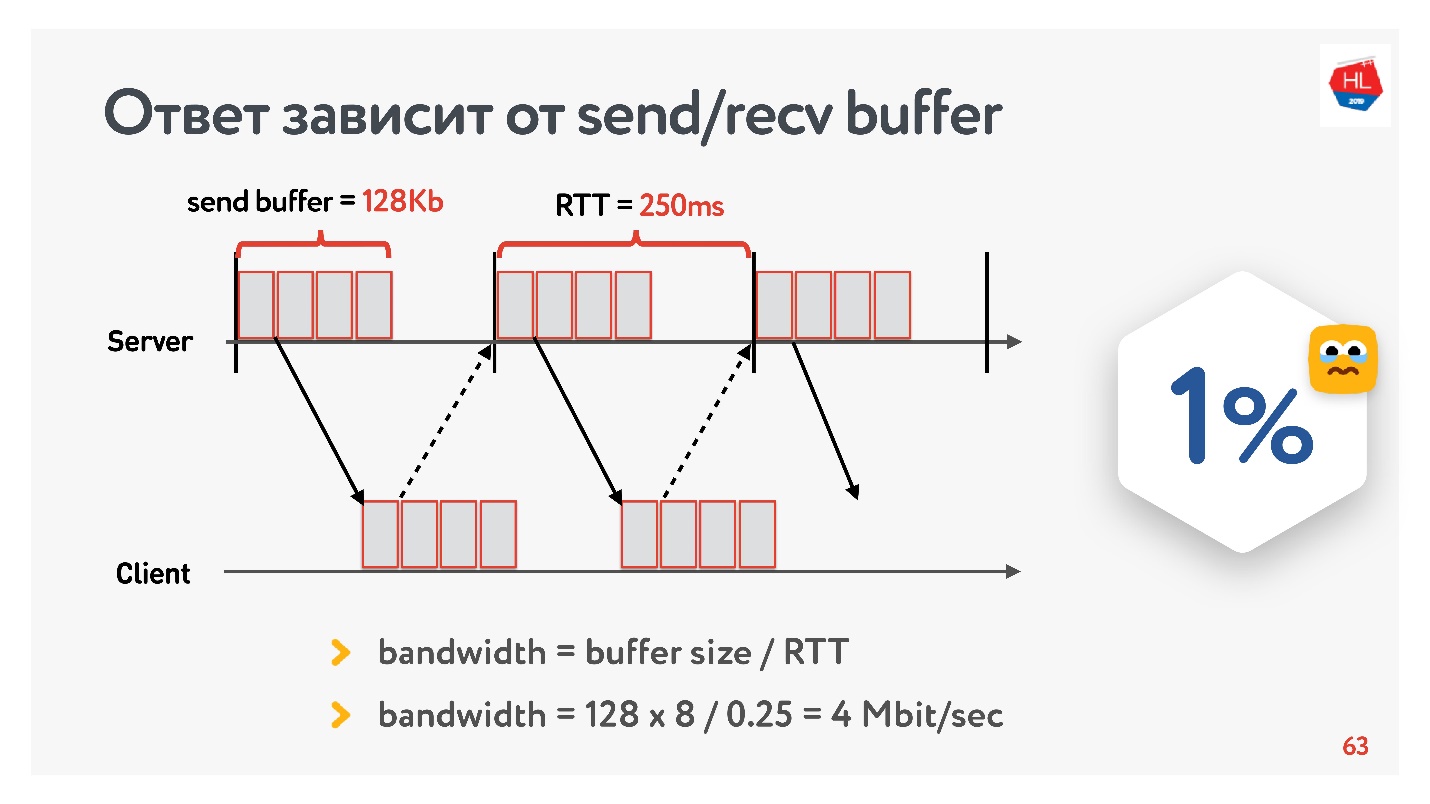
因为我们有一个带有确认的协议,所以所有未收到发送确认的数据都存储在缓冲区中。 如果发送缓冲区限制为128 Kb,则这128 Kb小于RTT的大小,我们将无法发送。 因此,从我们的400 Mbit / s的网络中,剩下4 Mbit / s。 这还不足以观看FullHD在线视频。
然后,我拉大了缓冲区的大小,并研究了一个视频片段的输出速度实际上如何根据缓冲区的大小变化而变化。 立即预约自动调整recv缓冲区,即 服务器发送的内容,客户端始终可以接受。

一个明显的TCP配方:如果您要长距离传输高速数据,则需要增加发送缓冲区。
一切似乎都很好。 您可以转到fast.com服务,该服务可衡量Internet到Netflix服务器的速度。 从办公室我获得了210 Mbps的速度。 然后通过net shaper设置任务的条件,然后再次访问该站点。 魔术-我的速度是4 Mbps。
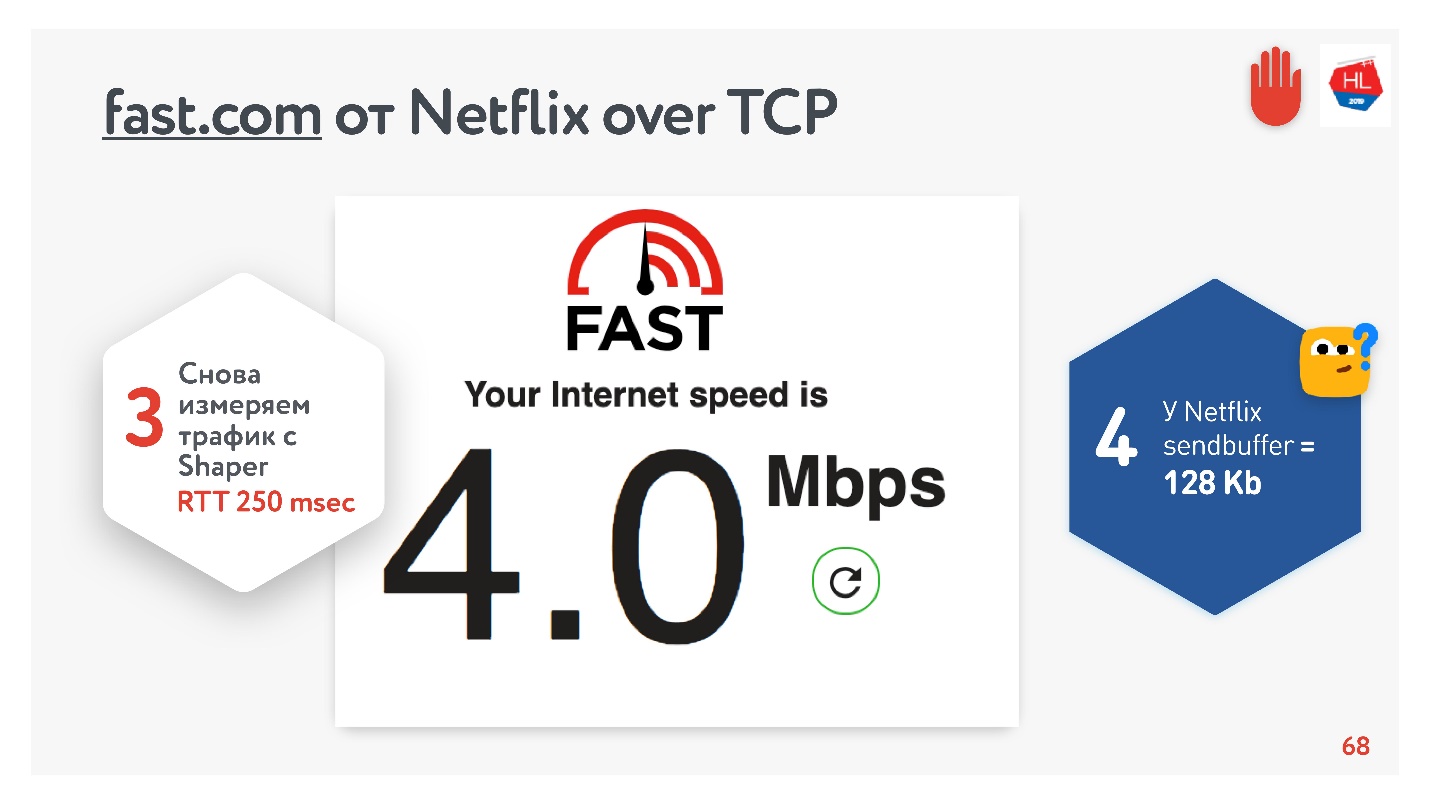
无论我如何扭曲,Netflix都无法获得大于128 KB的缓冲区。
缓冲区大小
为了找出最佳的缓冲区大小,您需要了解什么是实时数据包。
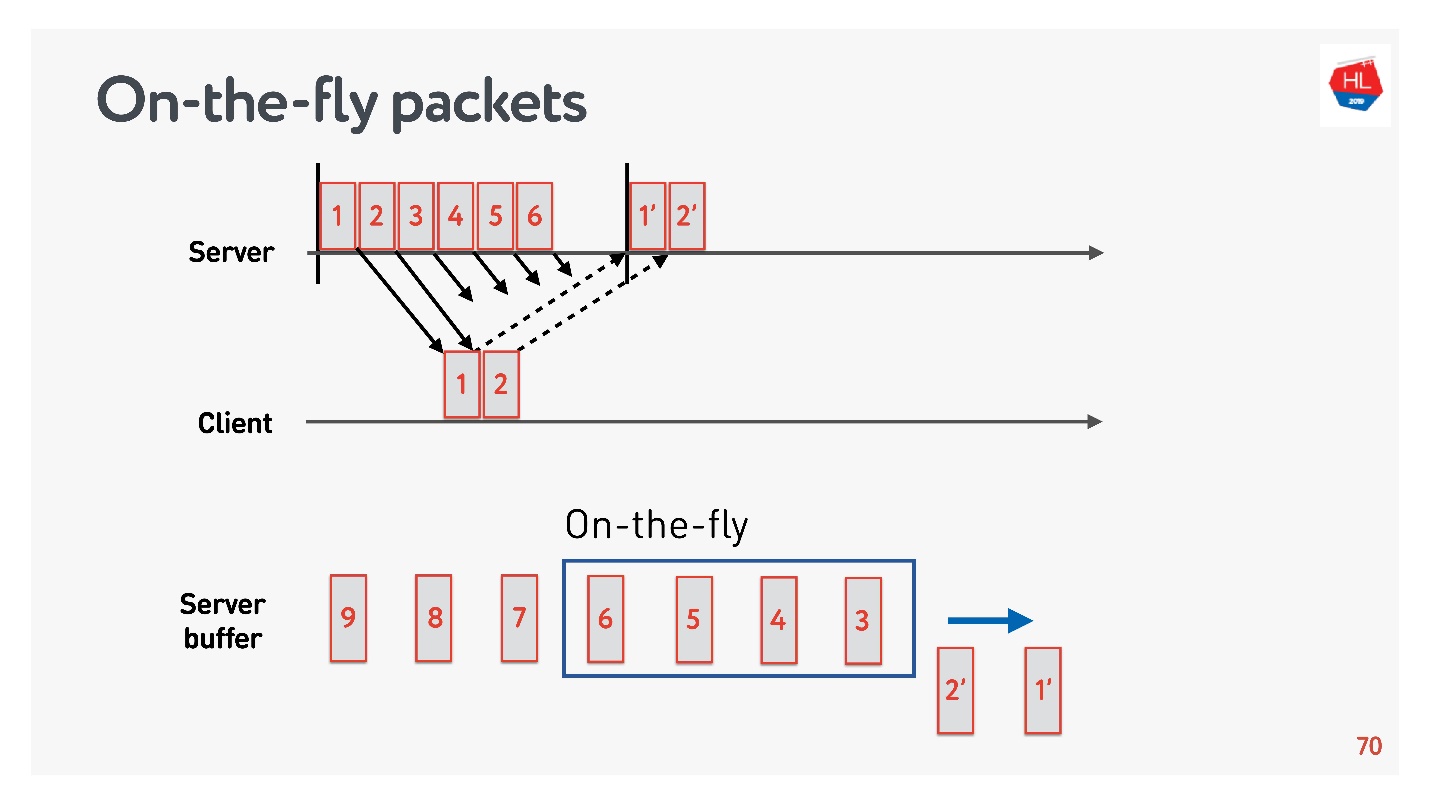
存在网络状态:
- 包1和2已经发送,已经收到确认。
- 发送了数据包3、4、5、6,但是传送结果未知(动态数据包);
- 其他数据包在队列中。
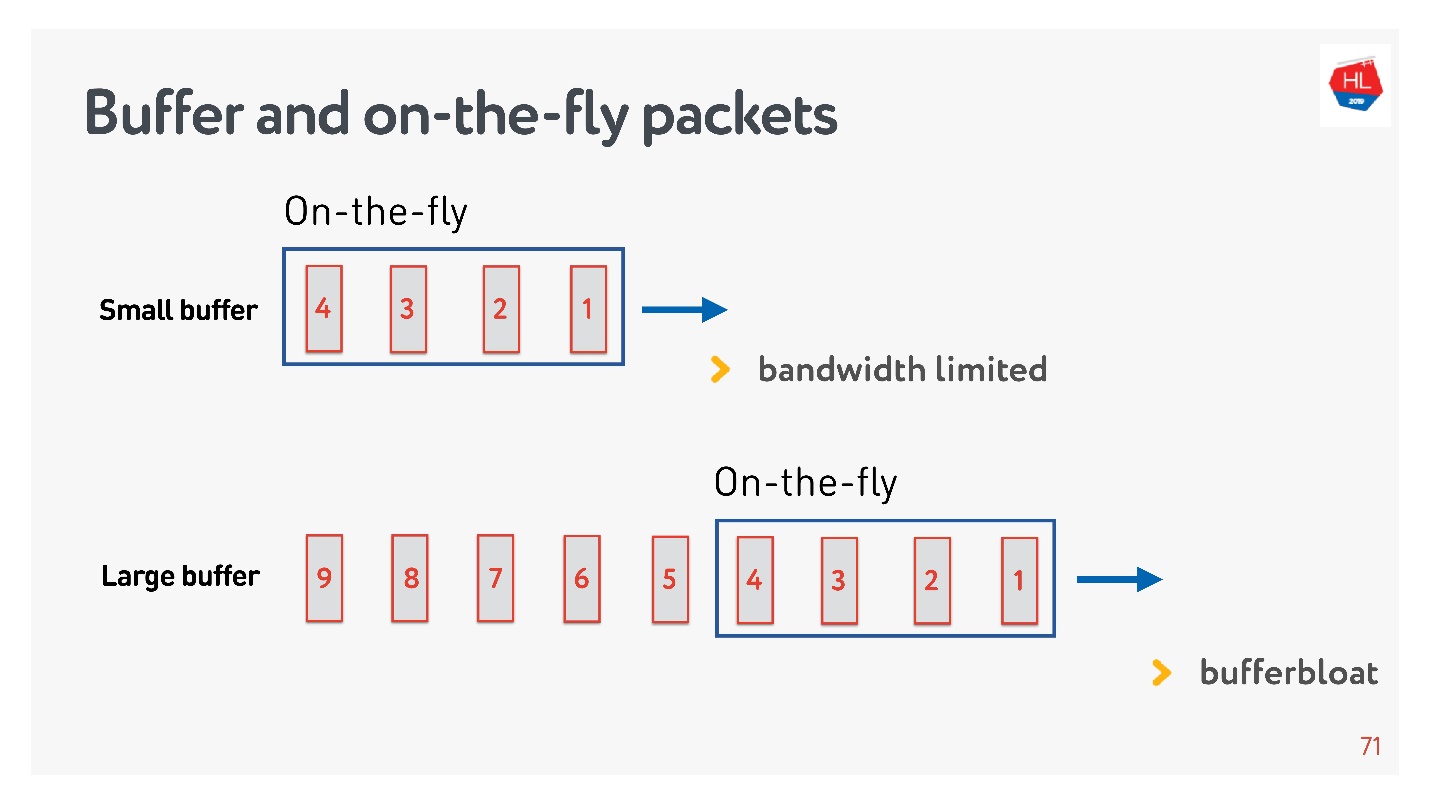
如果即时数据包的数量等于缓冲区的大小,则它不够大。 在这种情况下,网络很饿,没有得到充分利用。
相反的情况是可能的-缓冲区太大。 在这种情况下,缓冲区膨胀。 为什么这样不好?

如果我们谈论数据多路复用并同时发送多个请求,例如同一连接和API中的图片,那么当整个巨大的兆字节图片进入缓冲区时,我们也尝试填充高优先级的API,缓冲区就会膨胀。 图片消失时,您必须等待很长时间。
一个简单的解决方案是自动调整缓冲区大小。 现在,它在许多客户端上都可用,并且可以像这样工作。
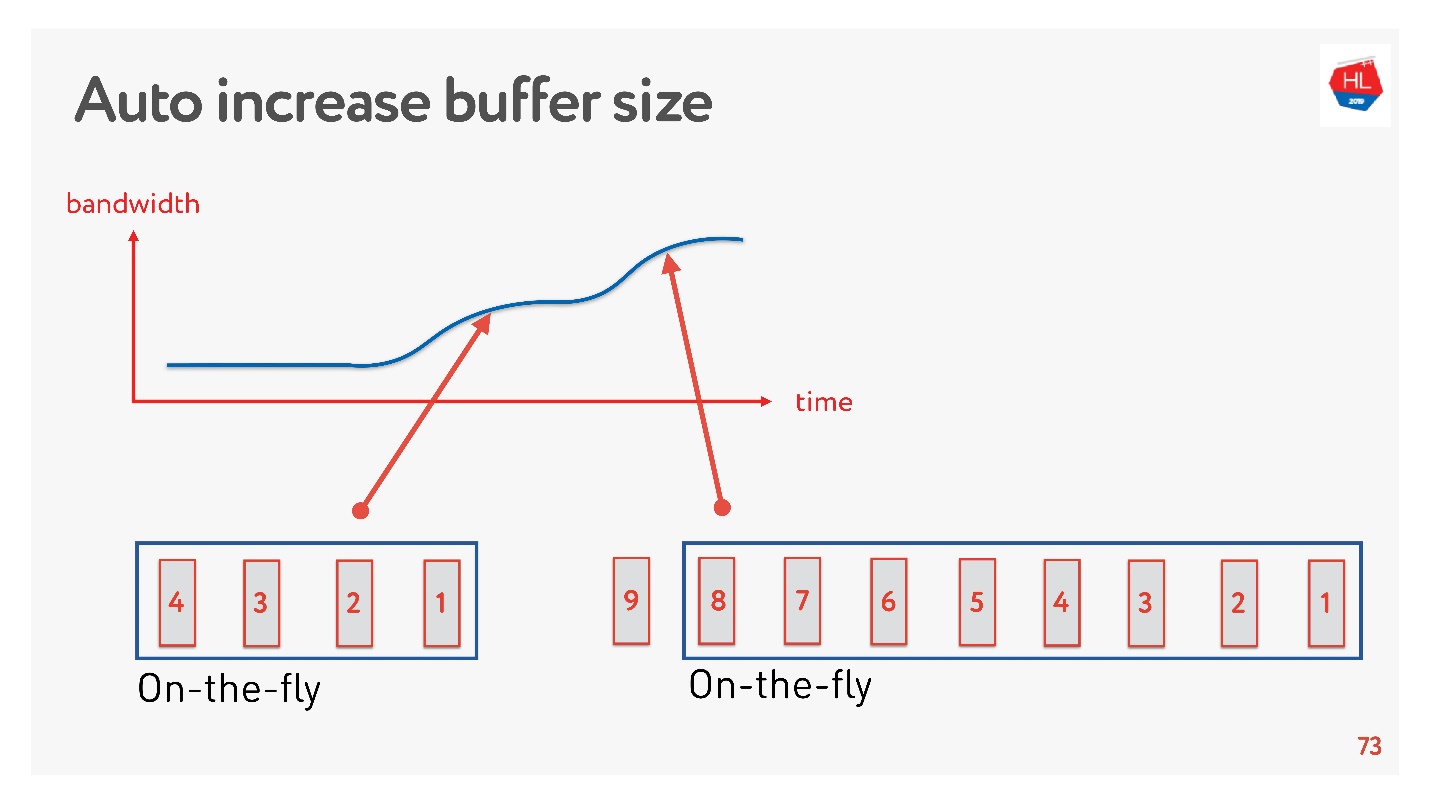
如果现在可以发送很多数据包,则缓冲区正在增加,数据传输正在加速,缓冲区的大小正在增加,一切似乎都很棒。
但是有一个问题。 如果缓冲区增加了,那么就不能轻易减少缓冲区。 这是一个更加困难的任务。 如果速度下降,则将发生相同的缓冲区膨胀。 缓冲区很大且已满,我们需要等到所有数据发送到客户端为止。
如果我们编写自己的UDP协议,那么一切都非常简单-我们可以访问缓冲区。
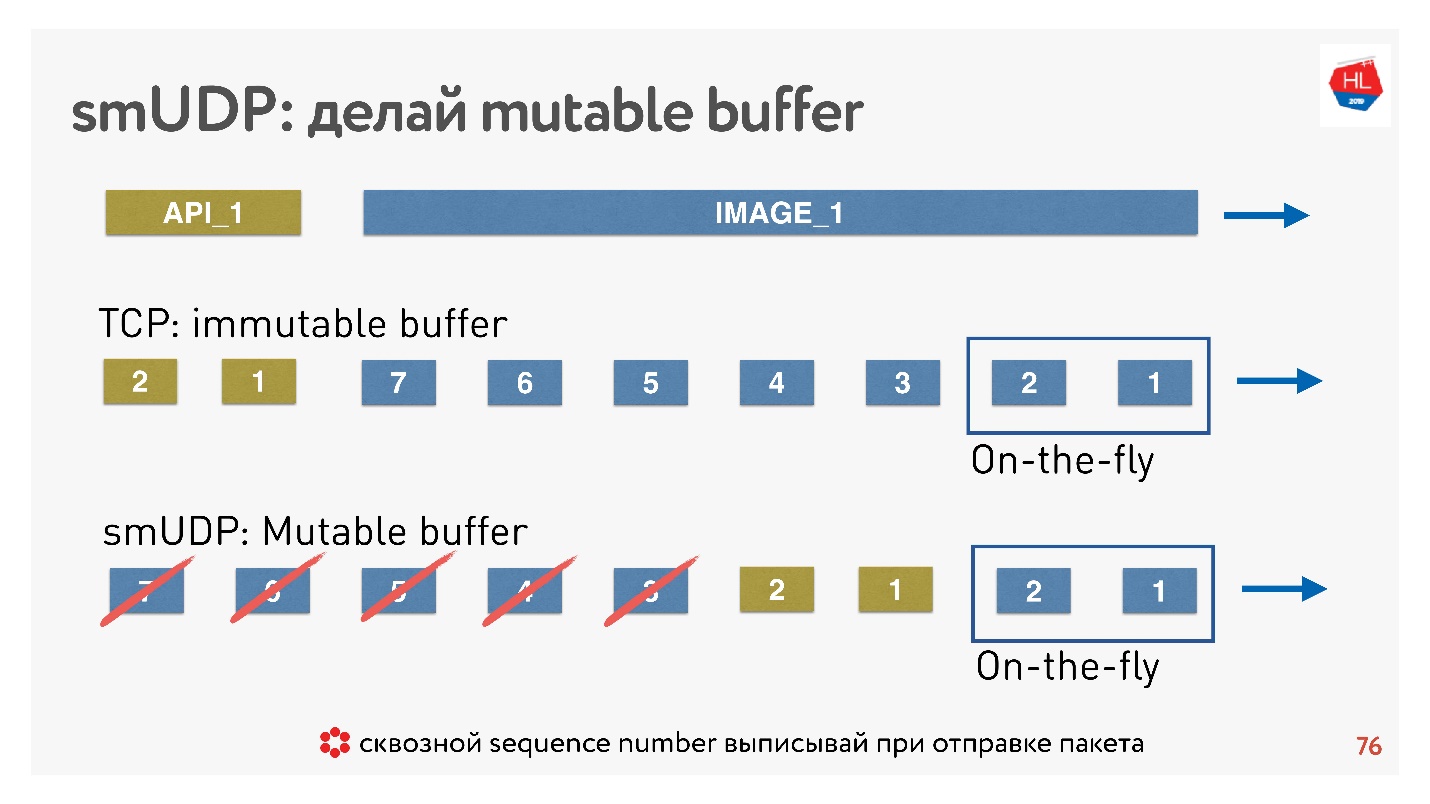
如果在这种情况下TCP仅将数据添加到末尾,而您却无能为力,那么在自制协议中,您可以将数据(例如,转发)紧接在即时数据包之后。
如果取消出现,并且客户说不再需要该图片,则他需要API数据,他进一步滚动了内容,可以将所有这些内容扔出缓冲区并发送所需的图片。
怎么做? 众所周知,为了还原数据包,管理传递,接收确认,您需要一些数据包的sequence_id。
针对即时数据仅包写出Sequence_id,也就是说,仅发送数据包在发布时才。缓冲区中的其他所有内容都可以根据需要移动,直到数据包消失为止。结论:必须正确配置了TCP缓冲区, 。保持平衡并,邻接以免网络且不会使缓冲区膨胀对于您自己的协议UDP的,一切都很简单-可以控制。有损网络模型
, - , packet loss. . . retransmit :
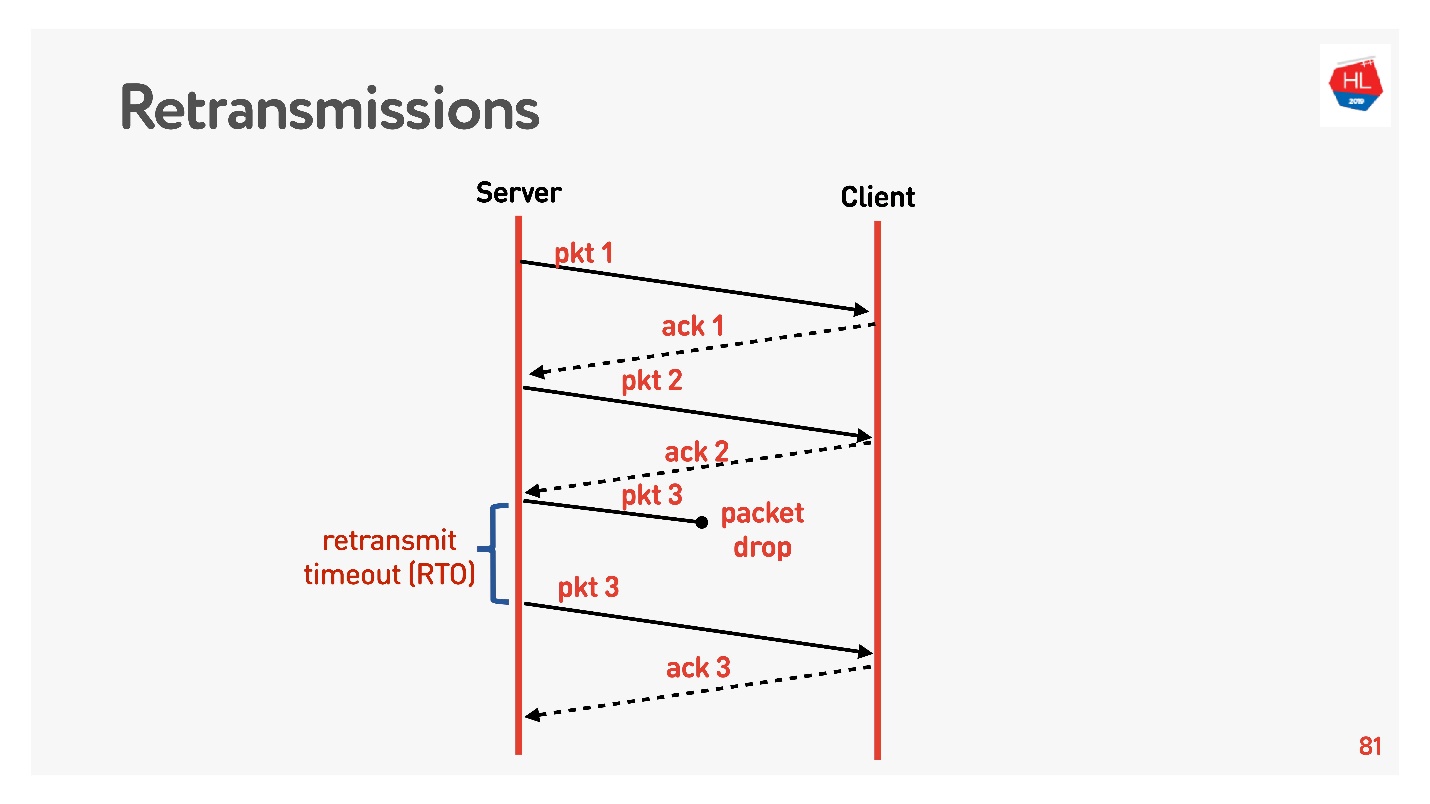
, acknowledgement. Retransmit timeout (RTO) RTT , .
TCP, 5% , 50%.
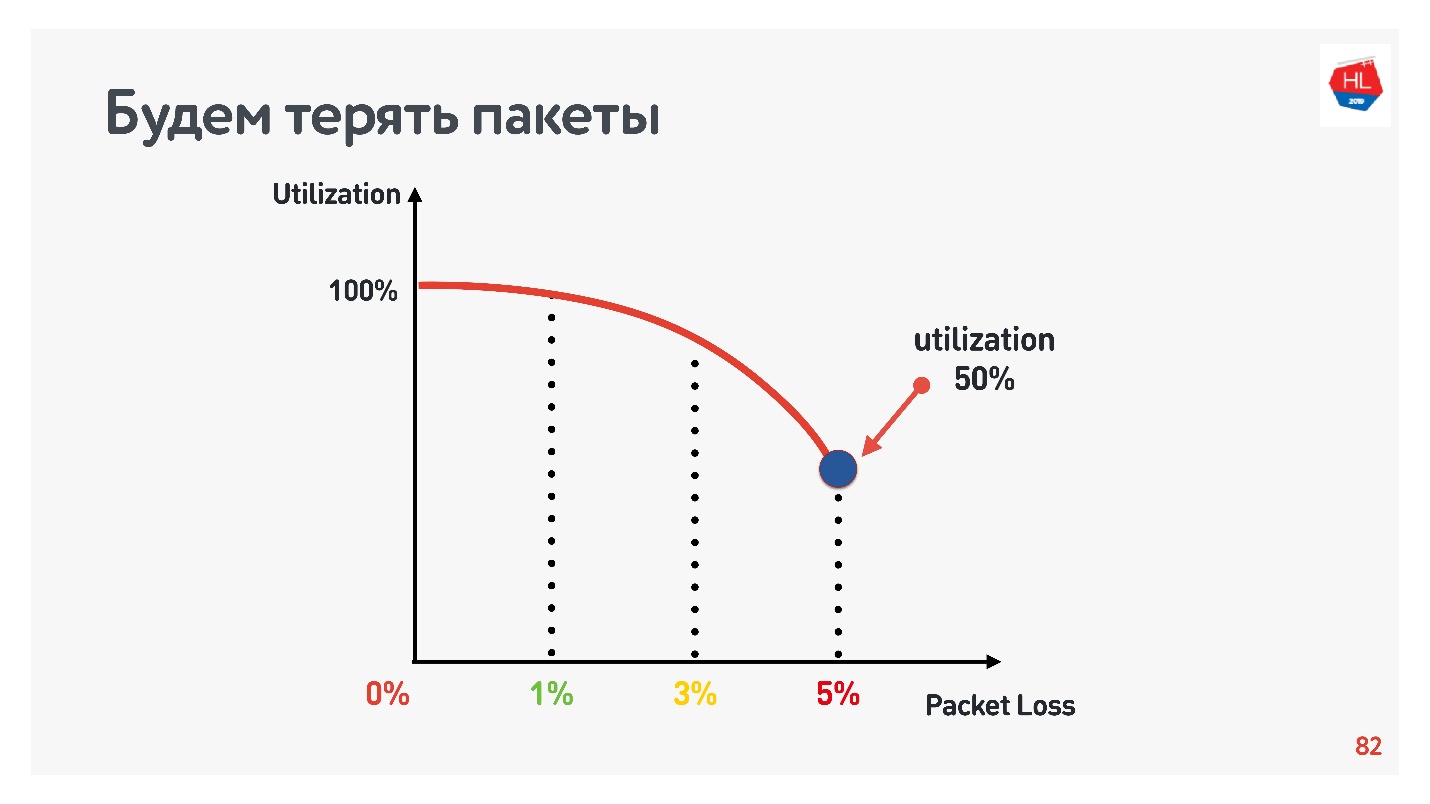
retransmit, , . , , Congestion control.
Congestion control
flow control, .
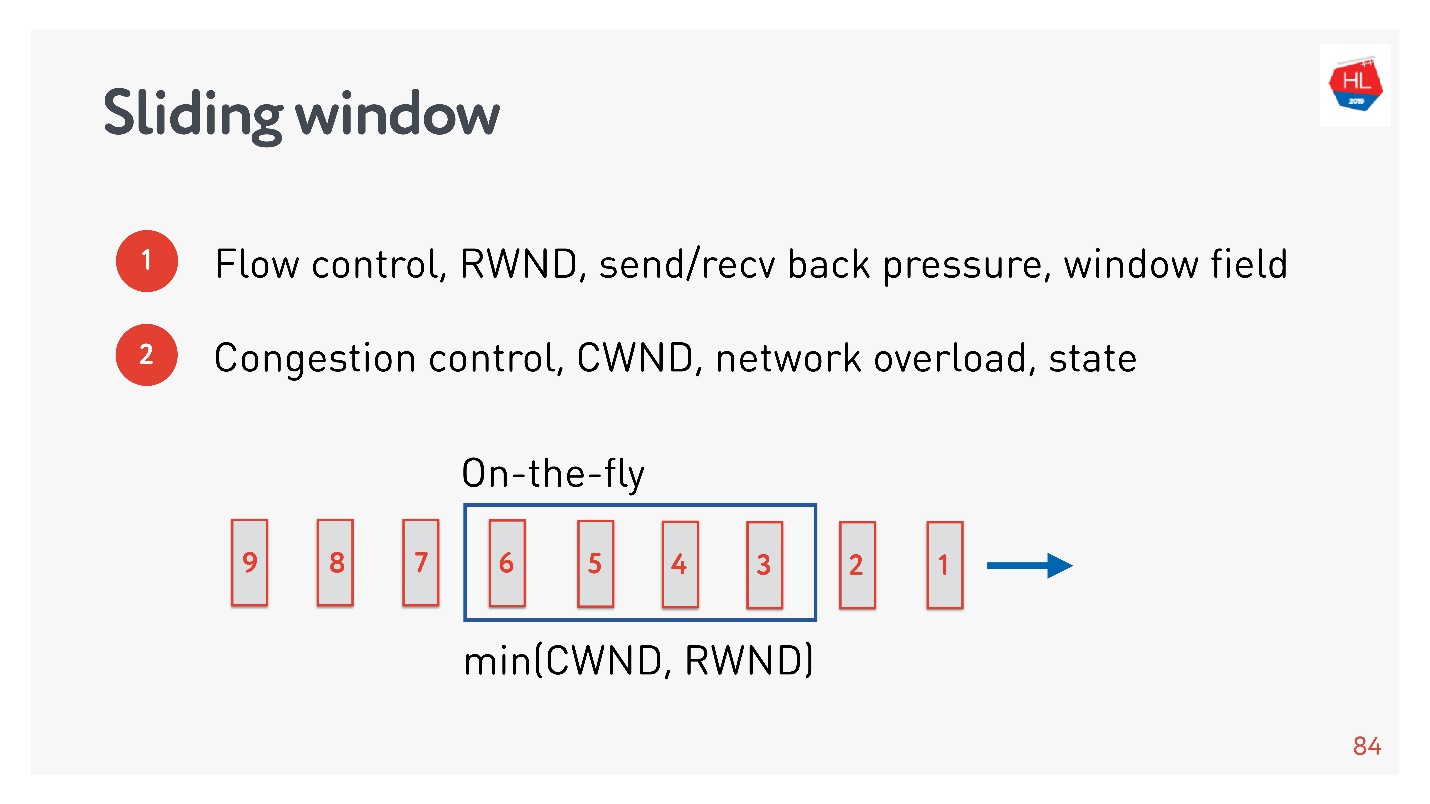
- Flow control — . , , . flow control recv window, . flow control — back pressure , - .
- congestion control . , — .
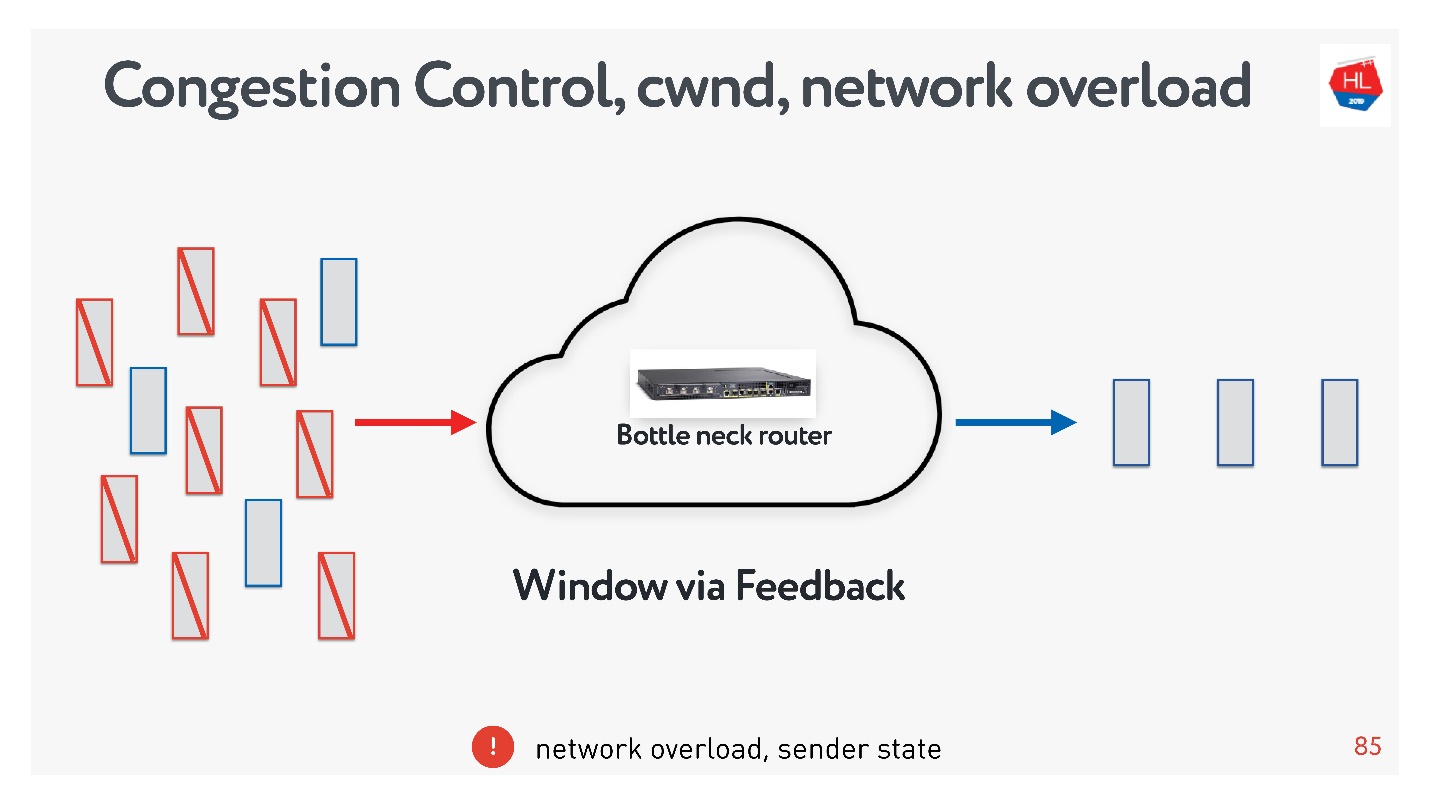
, : , , , . , congestion control.
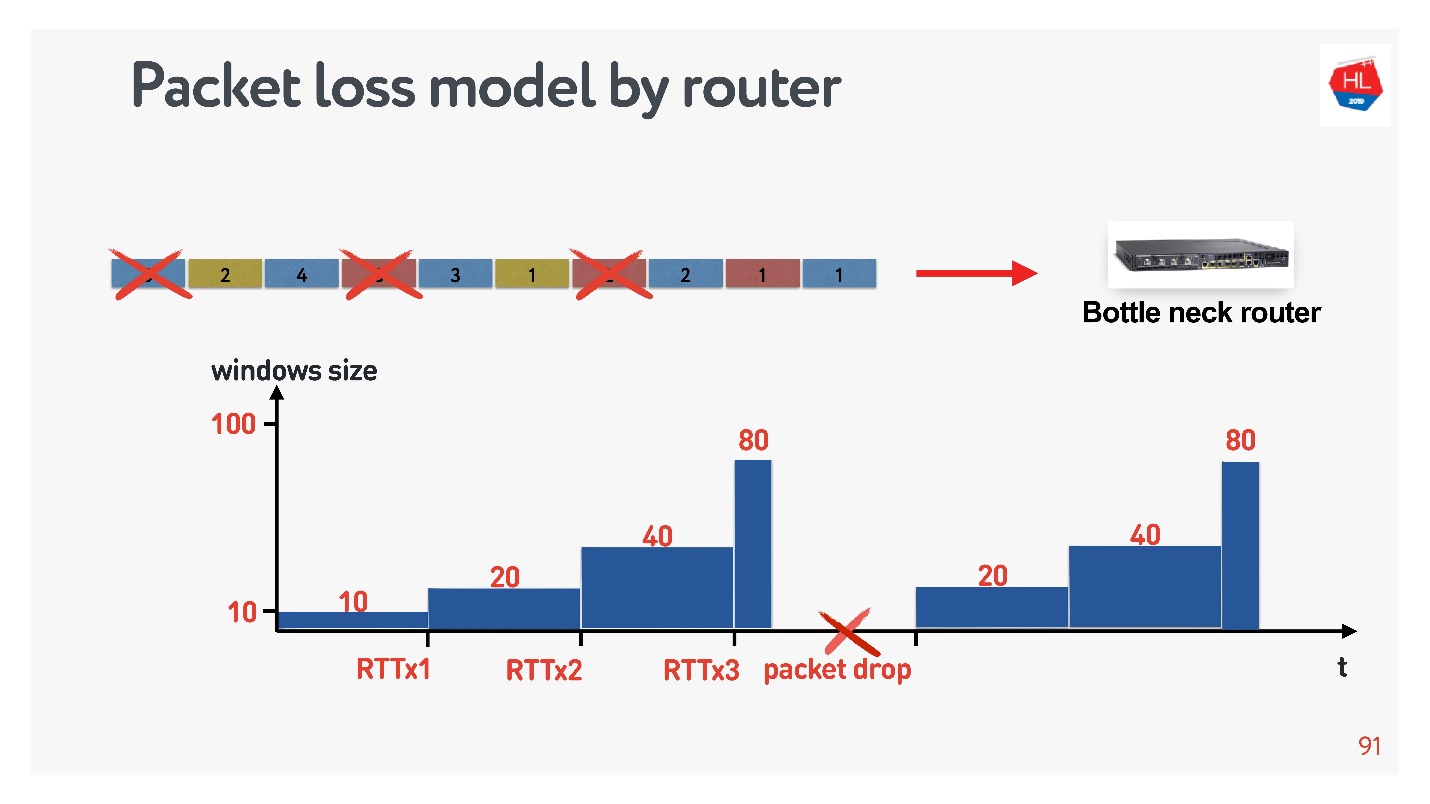
TCP window.
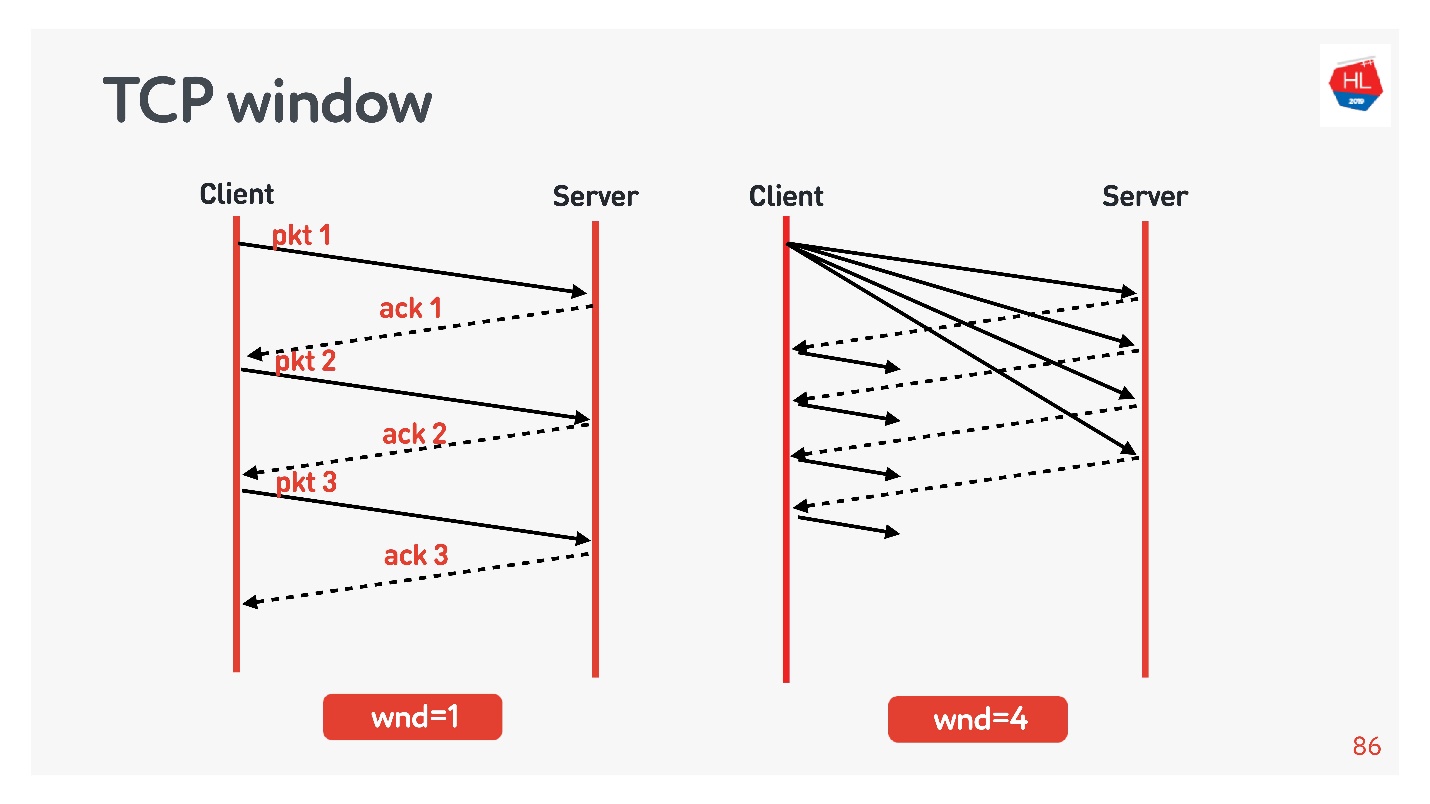
flow control congestion control, .
:
- TCP window = 1, : acknowledgement, ..
- TCP window = 4, , acknowledgement .
, . initial window TCP = 10.
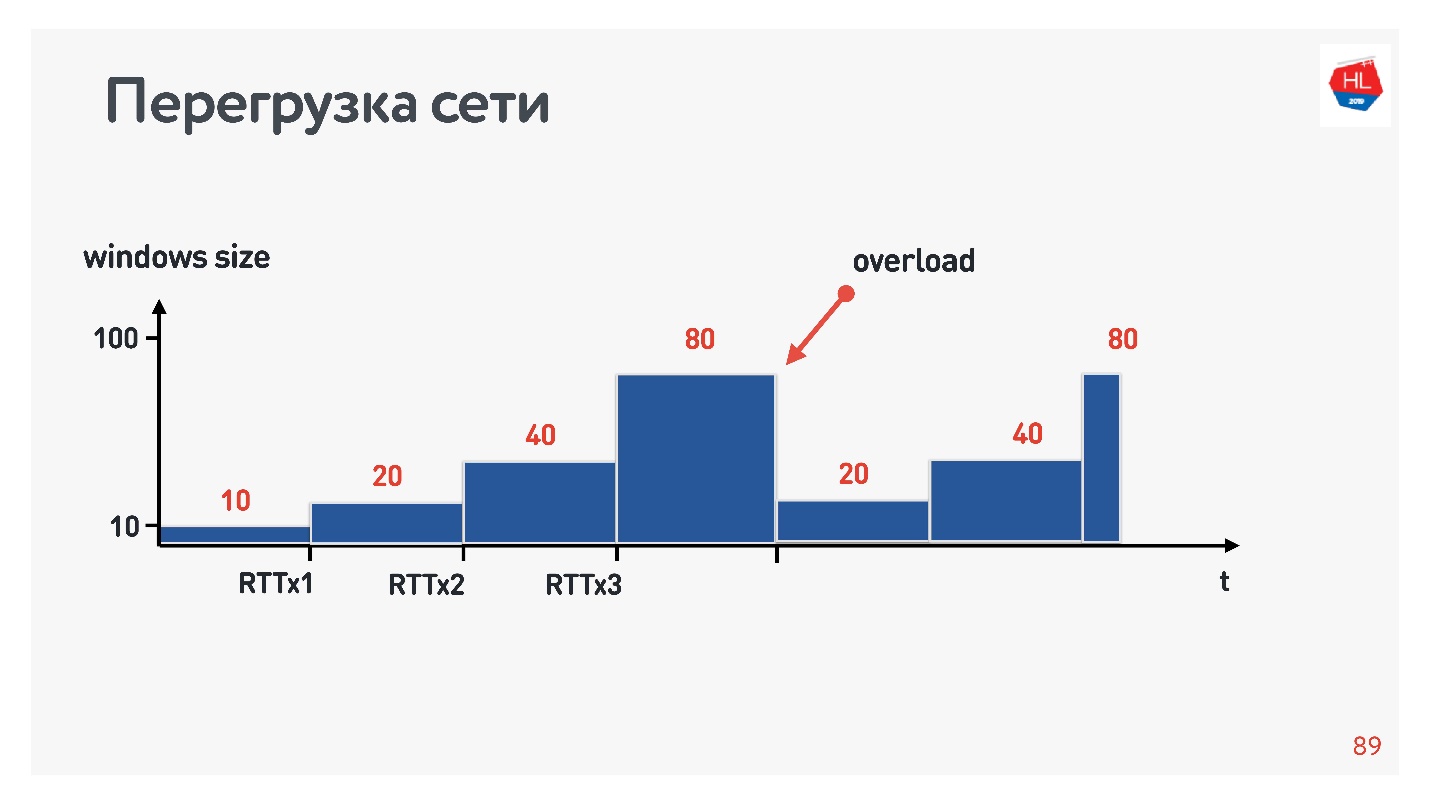
, , .
?
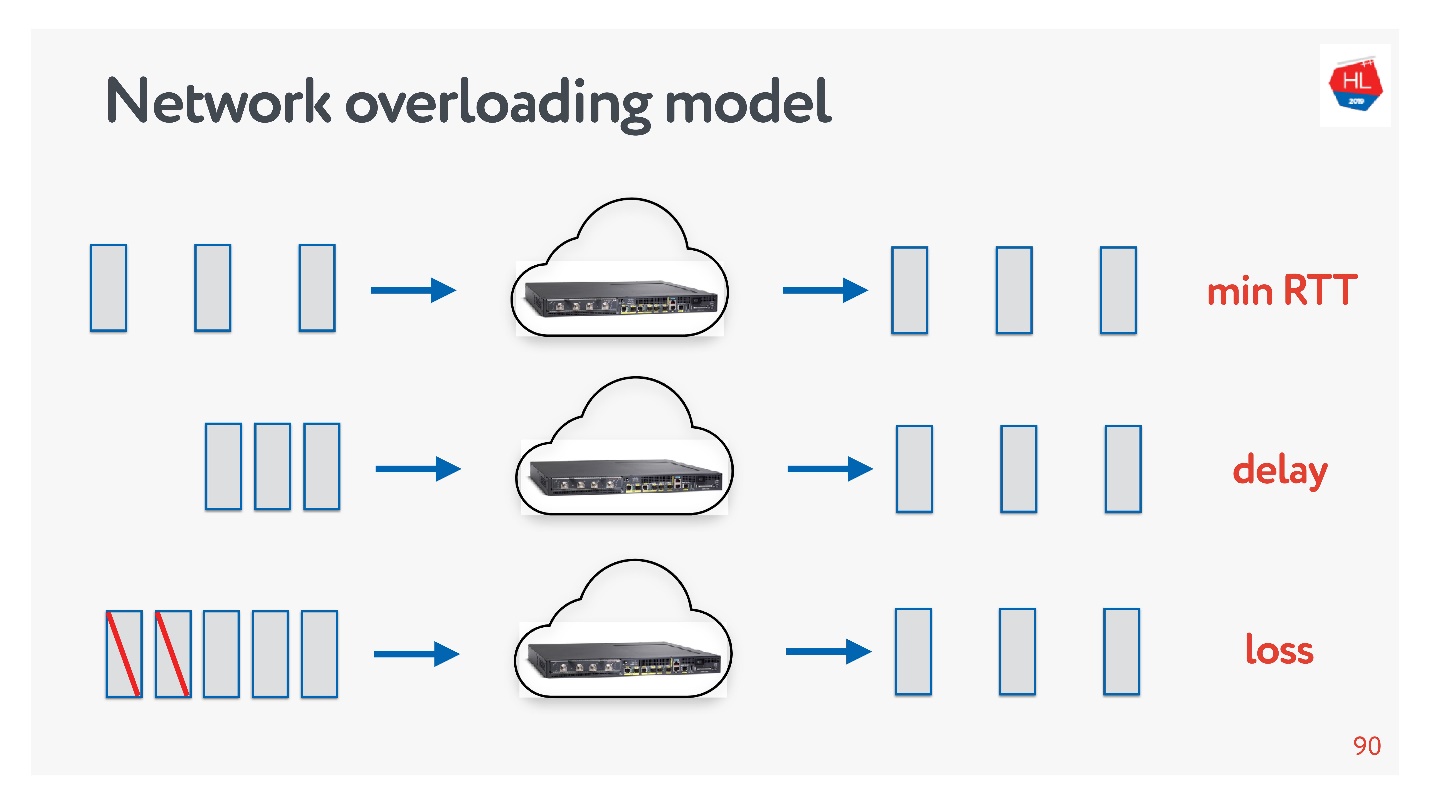
- , . , .
- : , acknowledgements .
- - , acknowledgements ( ).
.
, , . : , .. , . congestion control, TCP window, , .
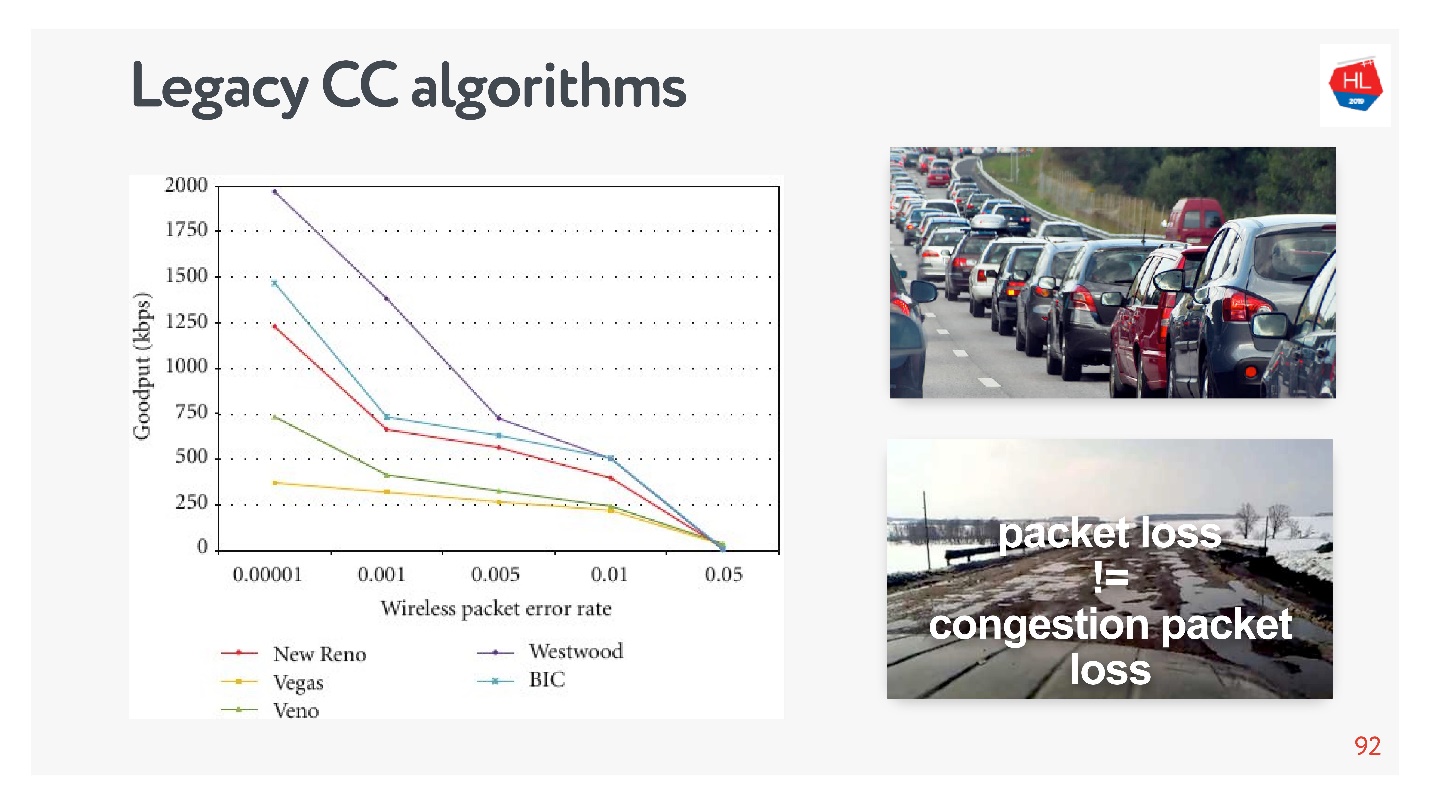
congestion control, , — . packet loss — , . , , — , .
, TCP , , congestion control loss-. congestion control loss delay, , .
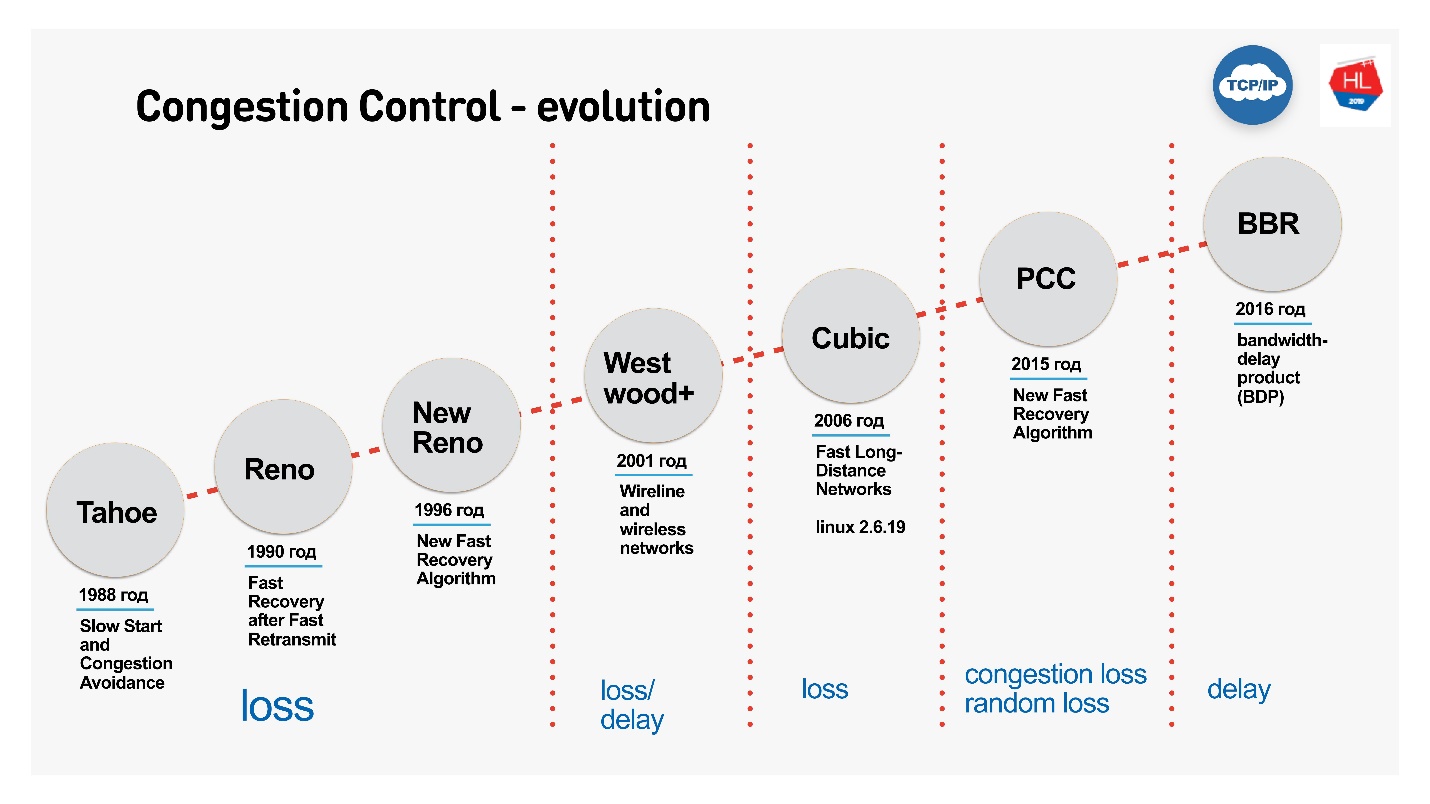
:
- Cubic — Congestion Control Linux 2.6. : — .
- BBR — Congestion Control, Google 2016 . .
BBR Congestion Control
Cubic BBR feedback.
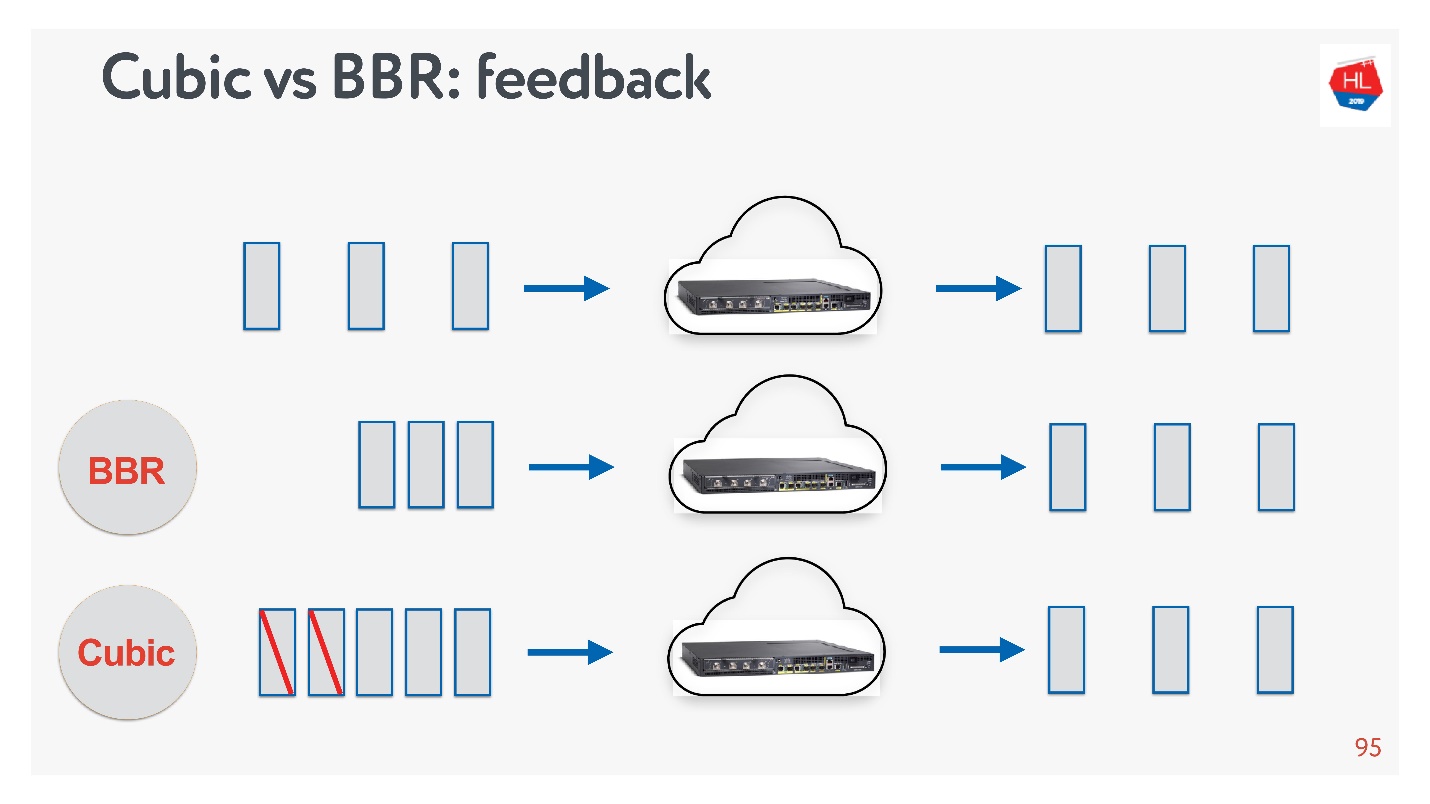
, — acknowledgement . :
- BBR , , , .
- 立方等待数据包丢失,然后关闭窗口。
下面是延迟与连接时间的关系图,它显示了在不同的拥塞控件上发生的情况。
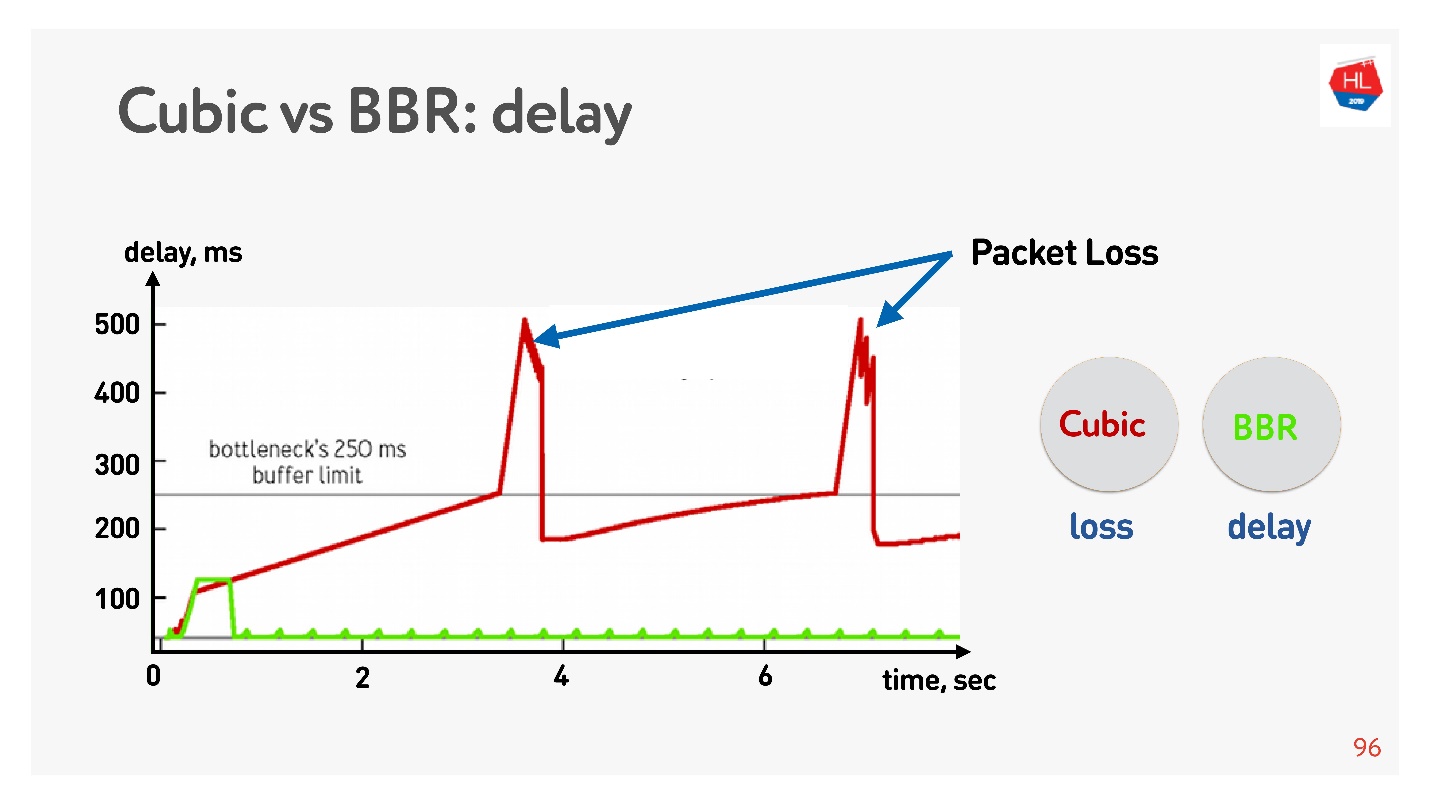
BBR首先检测往返时间,发送越来越多的数据包,然后意识到缓冲区被阻塞,并以最小的延迟进入操作模式。
Cubic积极地工作-它使整个缓冲区溢出,并且当缓冲区溢出且发生数据包丢失时,cubic会减小窗口。
在BBR的帮助下,似乎可以解决所有问题,但是网络中存在
抖动 -数据包有时会延迟,有时会成捆分组。 您以一定的频率发送它们,它们成组出现。 更糟糕的是,当您收到这些软件包的确认时,它们也会以某种方式“抖动”。
由于我承诺可以用手触摸所有东西,因此我们可以对例如
HighLoad ++站点进行ping操作,然后对ping进行
检查并考虑包之间的抖动。
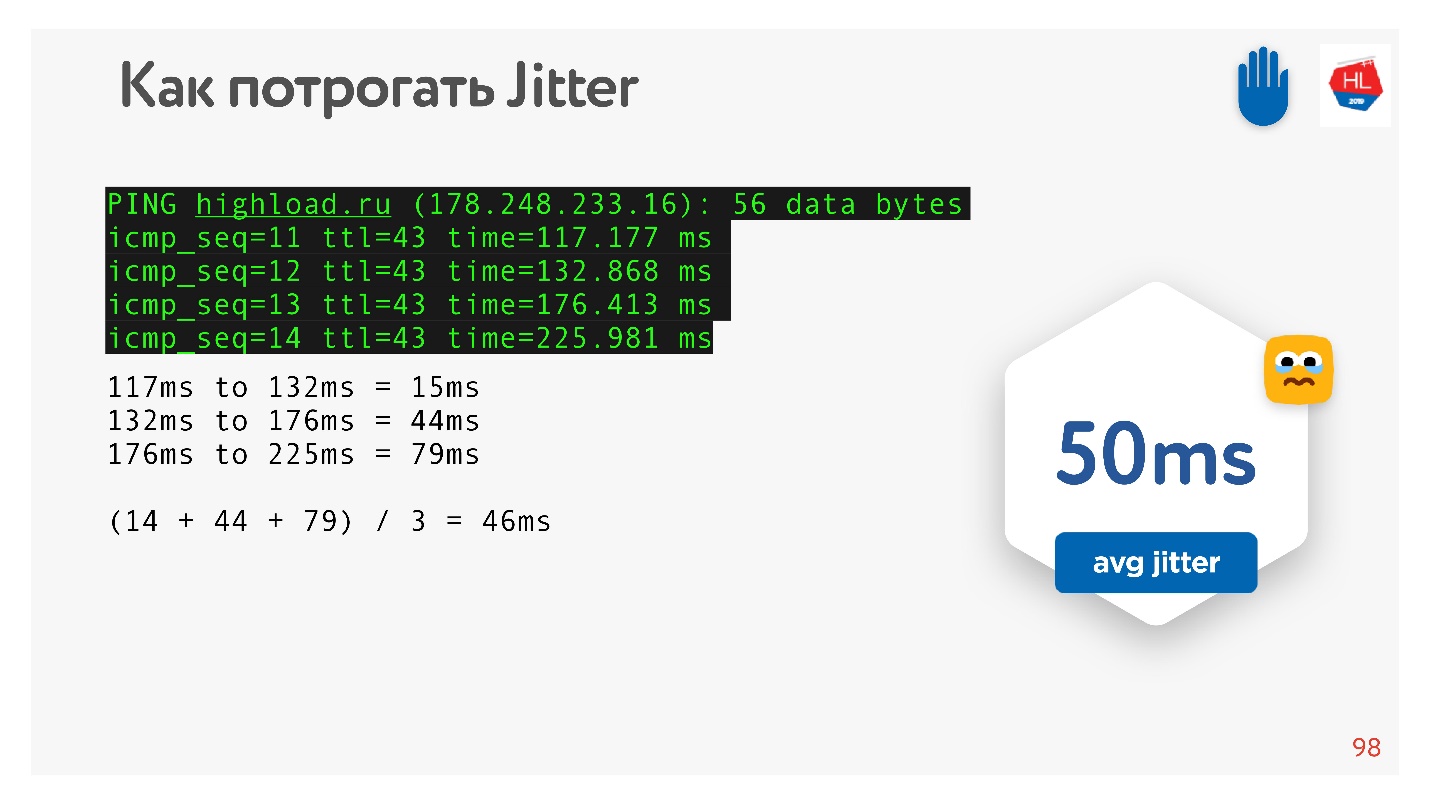
可以看出,数据包来的不均匀,平均抖动约为50 ms。 自然,BBR可能是错误的。
BBR之所以出色,是因为它可以区分:实际的拥塞丢失,由于设备缓冲区溢出导致的数据包丢失以及由于无线网络不佳造成的随机丢失。 但是,在高抖动情况下,它不能很好地工作。 我该如何帮助他?
如何更好地控制拥塞
实际上,TCP在确认中没有足够的信息,它只包含它看到的数据包。 也有选择性的确认,它说确认哪些数据包,哪些尚未到达。 但是,这些信息还不够。
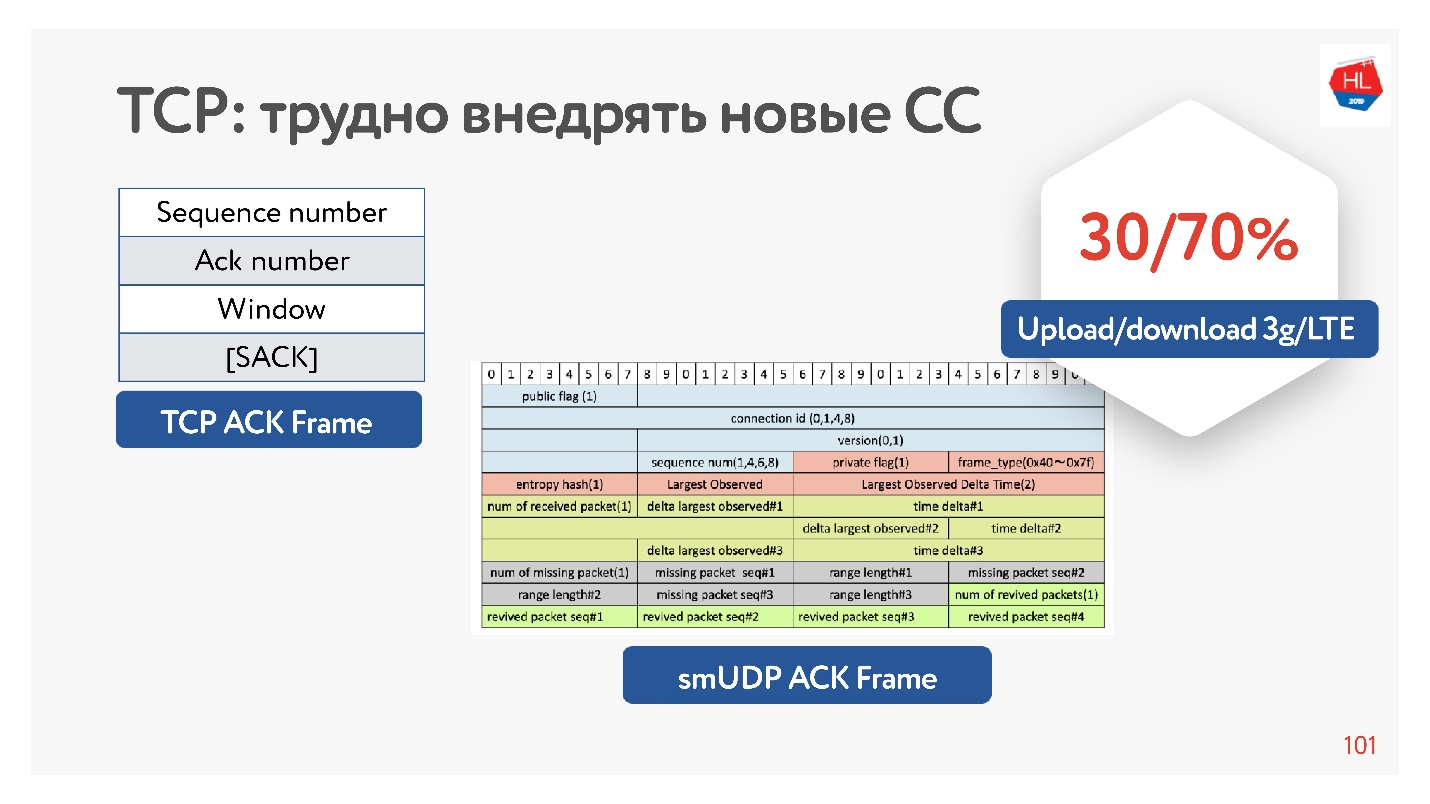
如果您有机会增加确认,您仍然可以节省所有时间-不仅发送这些数据包,而且还可以到达客户端。 也就是说,实际上是在服务器上收集抖动客户端。
为什么通常增加确认有效? 因为移动网络是不对称的。 例如,通常在3G或LTE中,70%的带宽分配给下载数据,30%的带宽分配给上传。 变送器切换:上载-下载,上载-下载,您不会以任何方式影响它。 如果您不卸载任何东西,则它只是空闲。 因此,如果您有任何有趣的想法,请增加认可度,不要害羞-这不是问题。
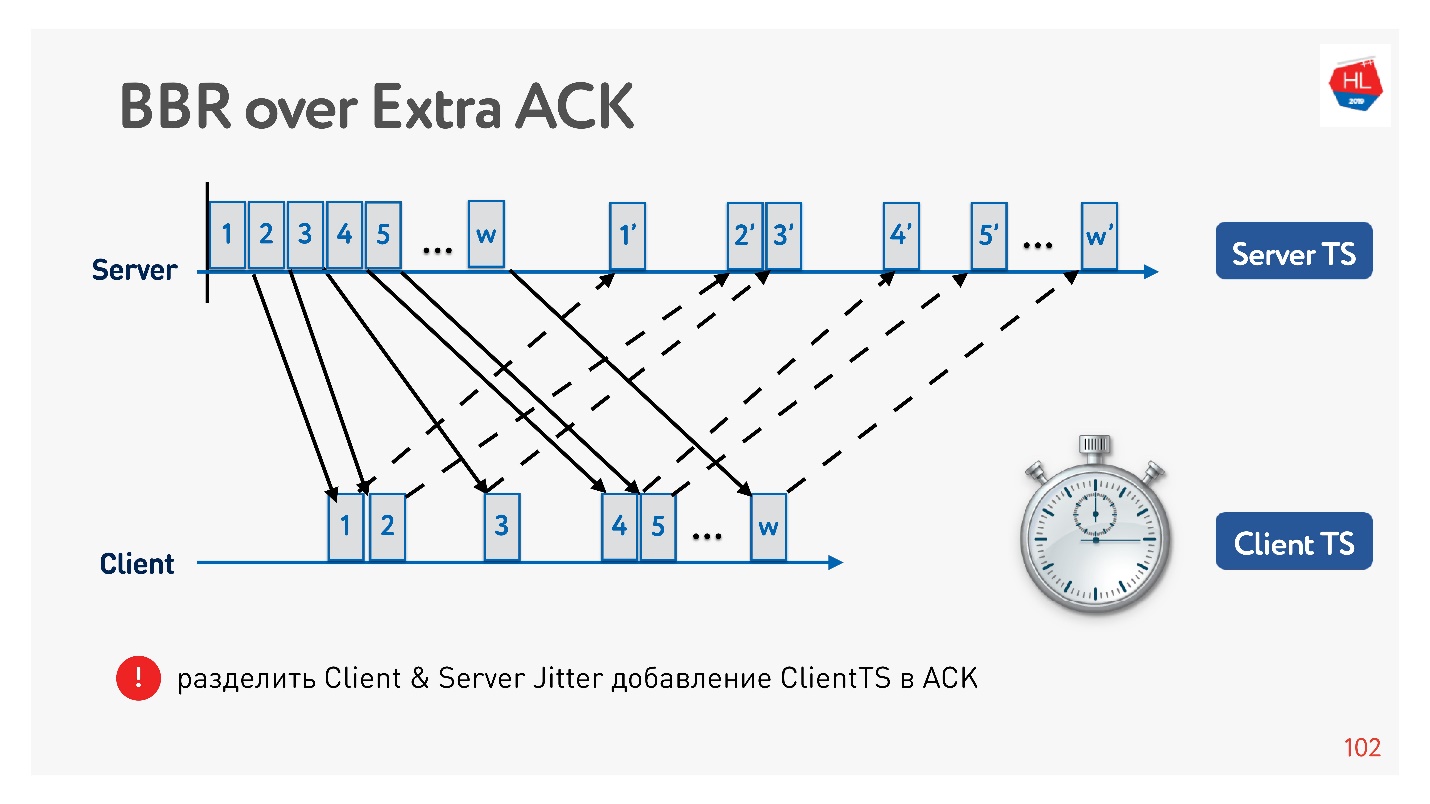
一个示例,说明如何使用确认将抖动分为发送抖动和接收抖动,并分别进行跟踪。 然后我们变得更加灵活,我们了解何时发生拥塞丢失以及何时发生随机丢失。 例如,您可以了解每个方向的抖动量,并更准确地配置窗口。

选择哪种拥塞控制
同学们是一个拥有大量不同流量的大型网络:视频,API,图片。 还有一些统计信息,哪个拥塞控制比较好选择。
BBR对于视频始终有效,因为它可以减少延迟。 在其他情况下,通常使用立方-对照片很有用。 但是还有其他选择。

有数十种不同的拥塞控制选项。 为了选择最佳的负载均衡器,您可以在客户端上收集统计信息,并针对不同类型的负载配置文件尝试一个或另一个拥塞控制。
例如,这是在视频上启动BBR的效果。
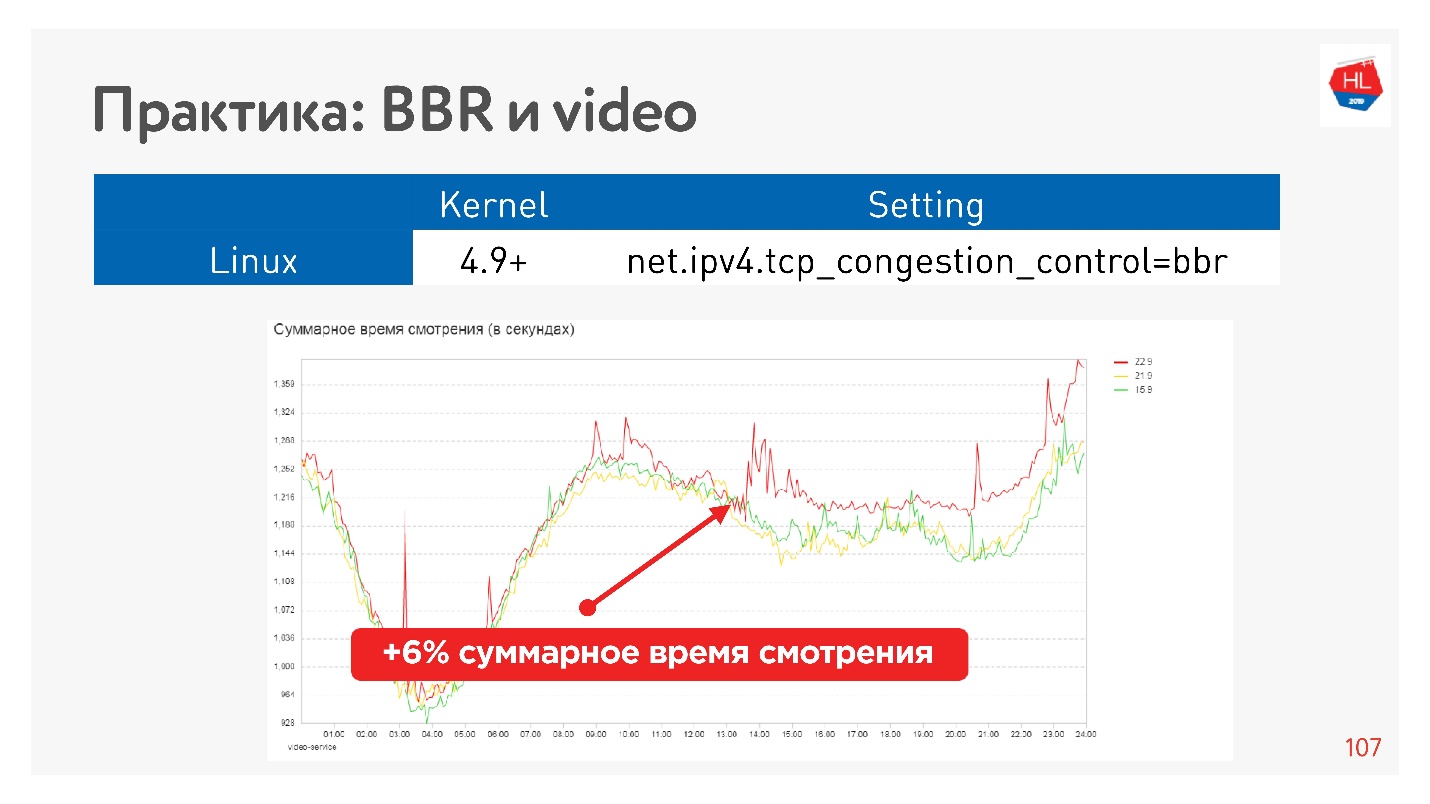
我们设法严重增加了观看深度。 谷歌表示,使用BBR时,播放器的缓冲空间减少了约10%。
很好,但是我们的客户呢?

客户有点慢,他们都有立方,您无法影响它。 没关系,有时您可以并行化数据,这会很好。
关于拥塞控制的结论:- BBR始终适合视频。
- 在其他情况下,如果我们使用自己的UDP协议,则可以控制拥塞。
- 从TCP的角度来看,您只能使用内核中的拥塞控制。 如果要在内核中实现拥塞控制,则必须遵守TCP规范。 夸大确认并进行更改是不可能的,因为它们根本不在客户端上。
如果您使用UDP协议,则拥塞控制方面的自由度更高。
复用和优先级
这是一个新趋势,每个人现在都在这样做。 有什么问题吗? 如果我们使用TCP,那么肯定每个人(或几乎每个人)都知道行头阻塞情况。
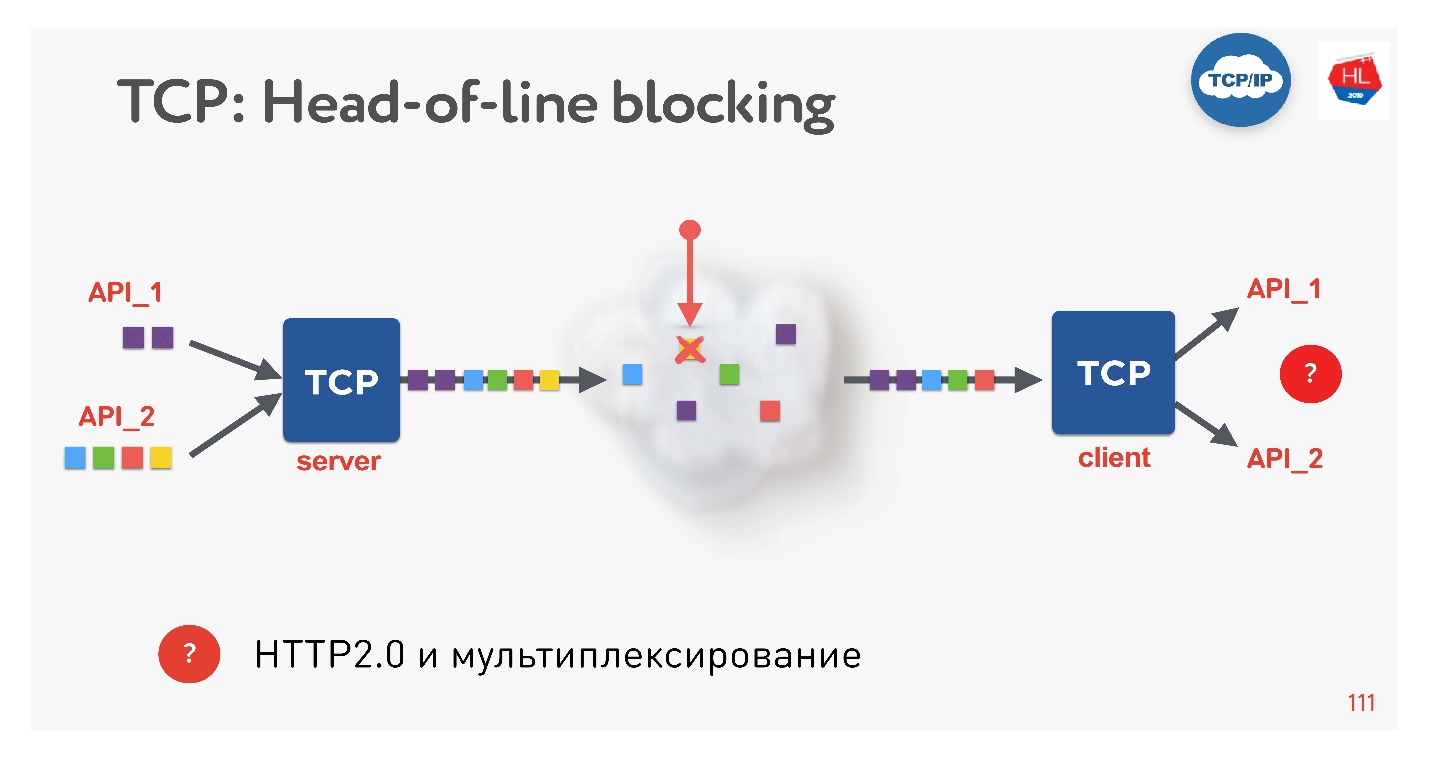
在单个TCP连接上多路复用了多个请求。 我们将它们发送到网络,但是缺少一些软件包。 TCP连接将重传此数据包;它将在接近RTT或更长时间的时间内重传。 目前,我们无法获得任何信息,尽管TCP缓冲区包含来自完全准备好可以接收的另一个请求的数据。
事实证明,如果使用HTTP 2.0,则通过TCP进行的多路复用在不良网络上并不总是有效。
下一个问题是缓冲区膨胀。

当图片发送到客户端时,缓冲区增加。 我们发送了很长时间,然后出现了一个API请求,并且绝不对它进行优先级排序。 在这种情况下,TCP优先级不起作用。
因此,如果发生数据包丢失,则会出现行头阻塞,并且当客户端的比特率可变时(移动客户端经常发生这种情况),就会出现缓冲膨胀效应。 结果,无论是多路复用,优先级划分,服务器推送还是其他所有操作都不起作用,因为我们要么有缓冲区,要么客户端期望某些东西。
如果我们自己进行多路复用,则可以在其中放置各种数据。
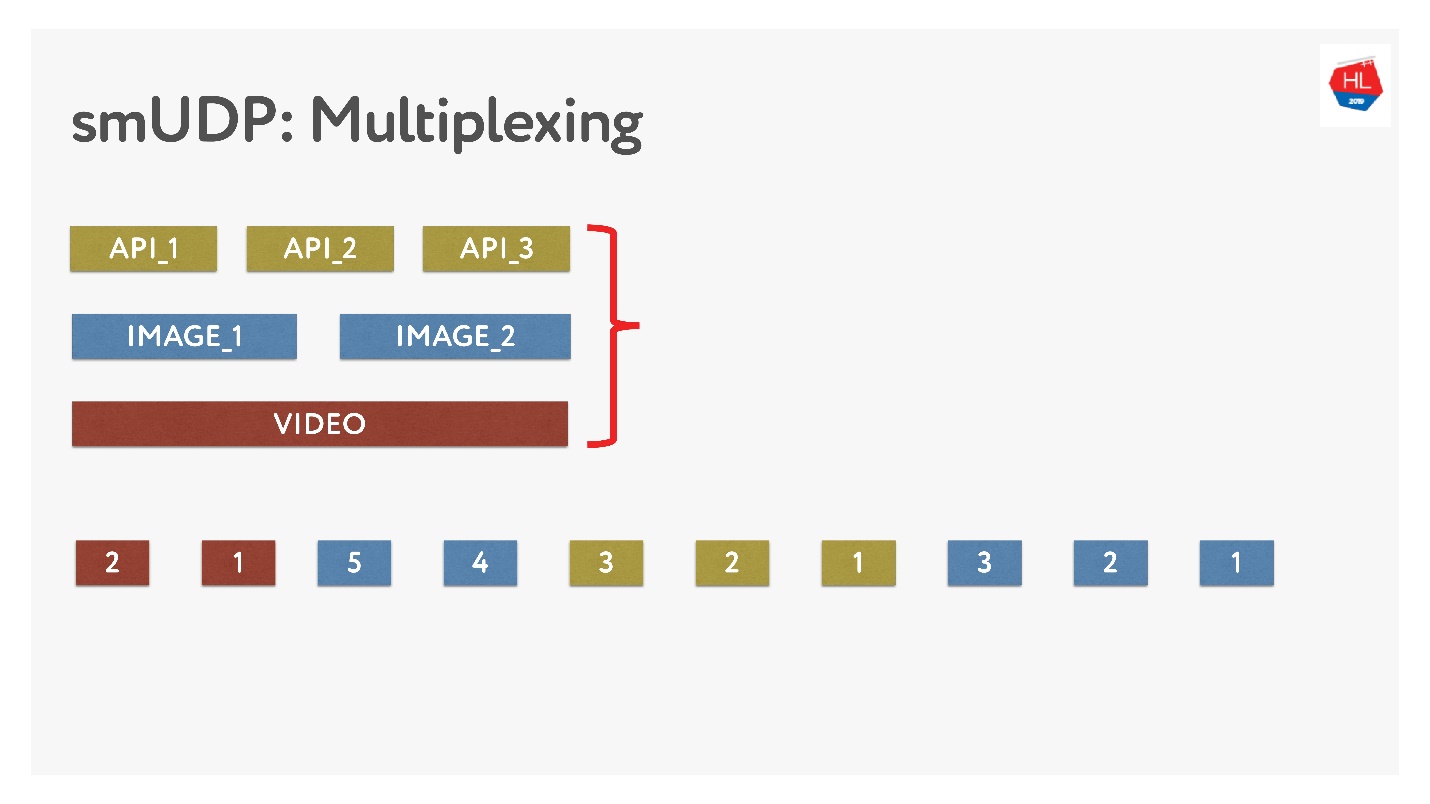
这并不困难,只需将带有数字的数据包添加到缓冲区即可。 即时-请勿触摸已发送的内容,但可以重新安排尚未发送的内容。 看起来像这样。
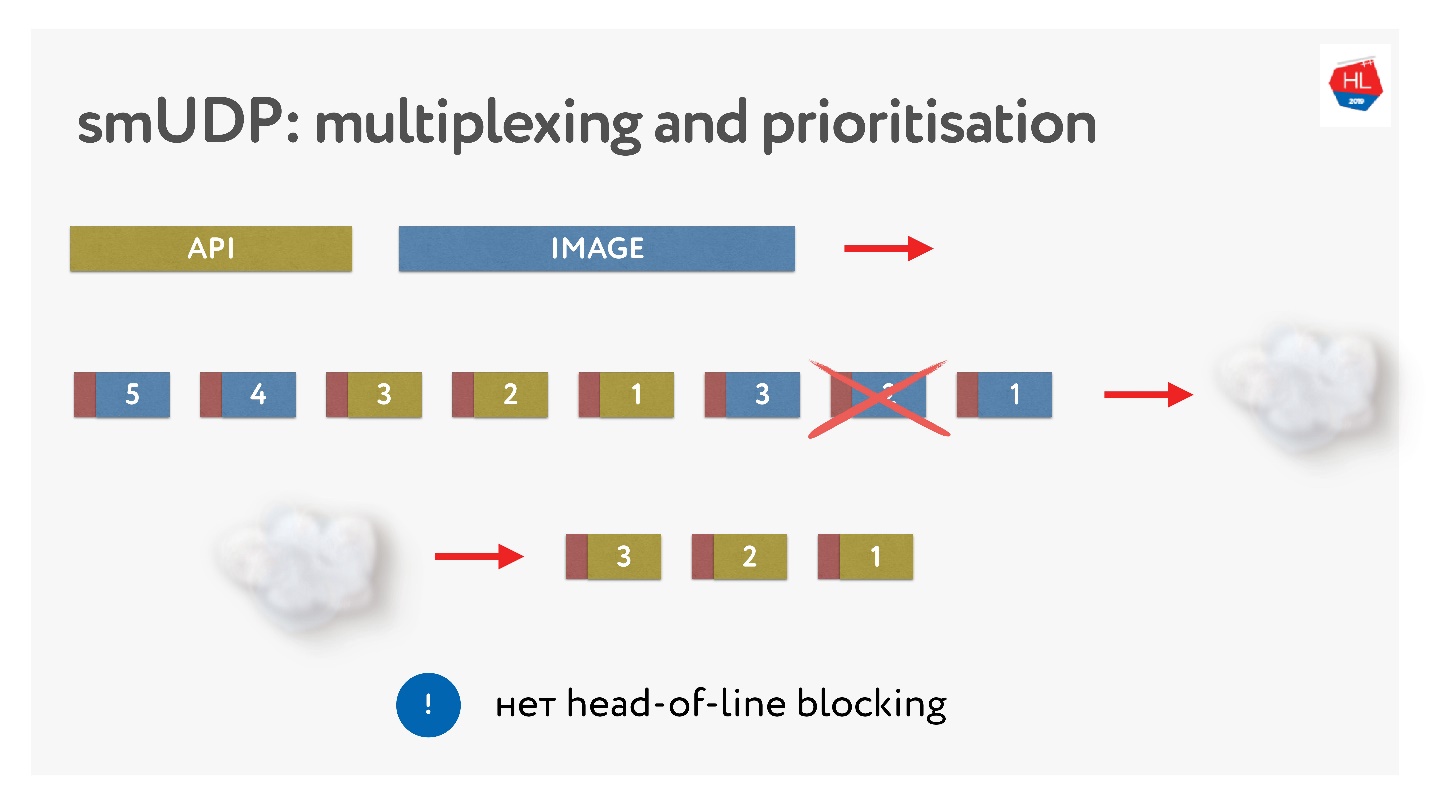
他们发送了图片,将它们打包,发出优先API请求:他们将其插入并发送了图片。 即使数据包丢失,我们也可以从缓冲区中获得现成的API请求,它具有很高的优先级,并且可以很快到达客户端。 根据定义,在TCP中,无法进行流数据传输。
建立连接
如果我们对应用程序进行概要分析,则将在大多数情况下看到应用程序启动时网络处于空闲状态,因为首先在API之前建立了连接,然后获得了数据,然后在图片,此数据被下载之前建立了连接等。 这总是会发生-网络被高峰利用。

为了解决这个问题,让我们看看如何建立连接。
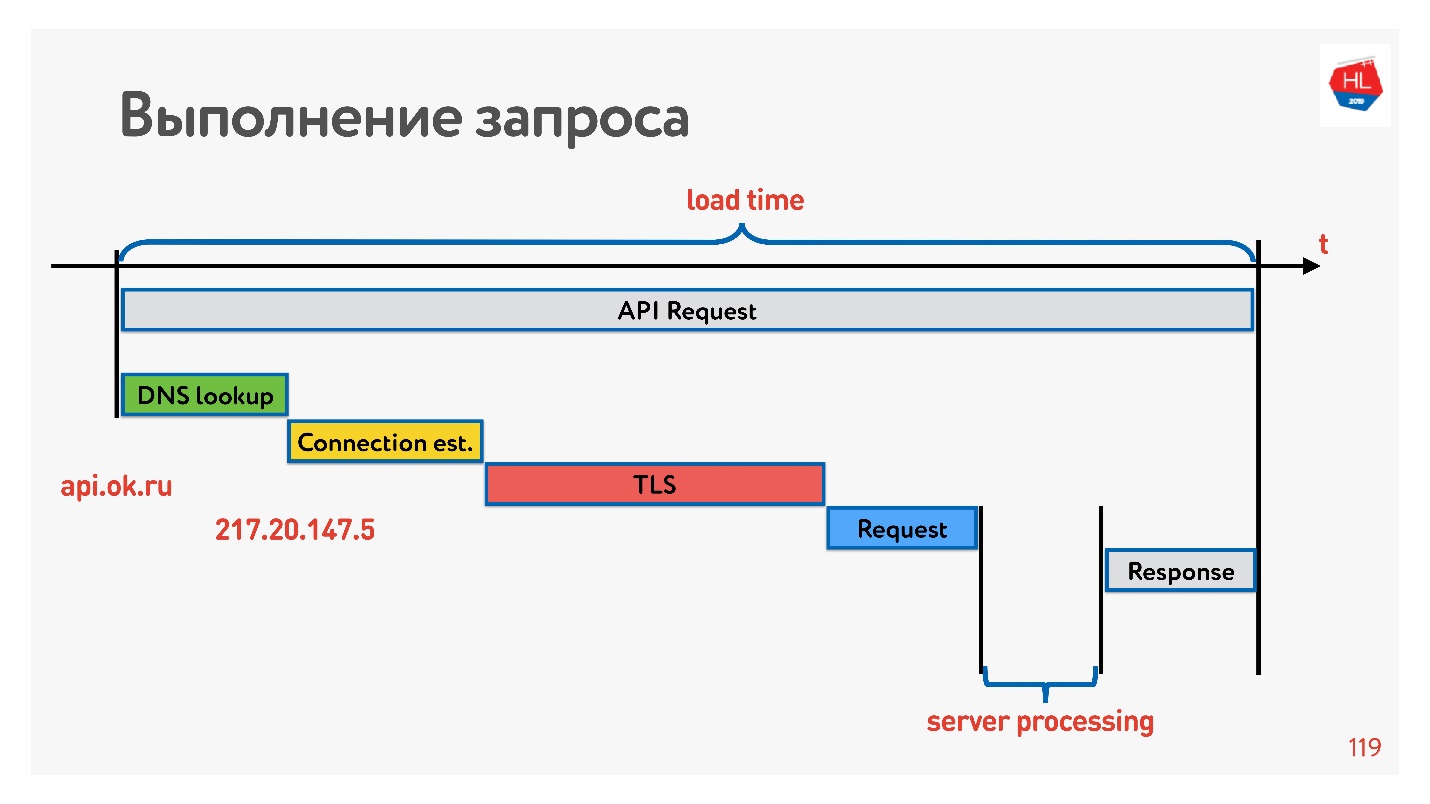
首先是解析DNS-我们不能对此做任何事情。 接下来,建立TCP连接,建立安全连接,然后执行请求并接收响应。 最有趣的是,服务器在响应请求时所做的工作通常比建立连接花费的时间更少。
现在,测量内存,磁盘或其他东西的延迟数非常时尚。 您可以为3G,4G网络测量它们,并查看在最坏情况下使用TLS建立TCP连接需要多长时间。
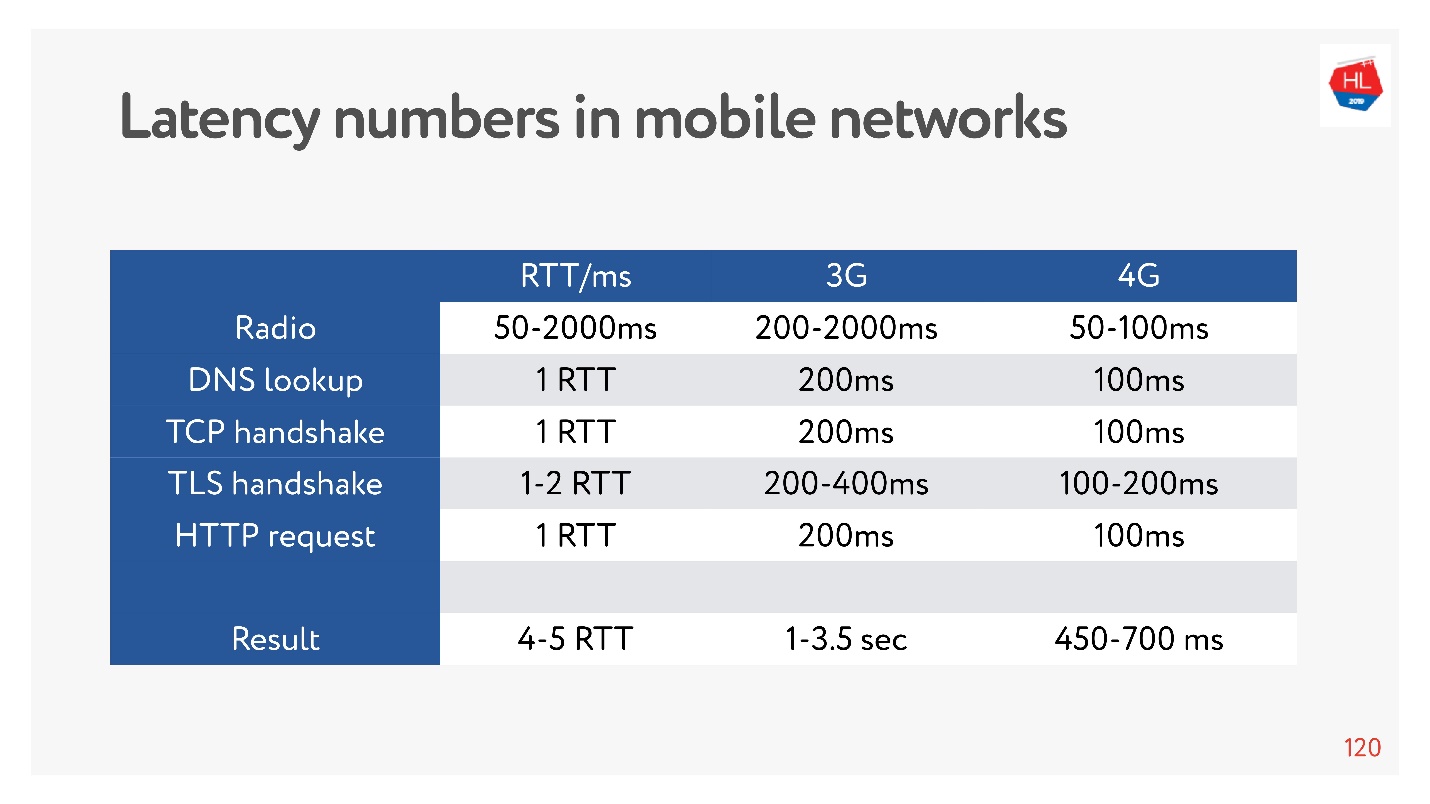
可能要几秒钟! 即使在4G上,长达700毫秒也很重要。 但是,TCP一直无法如此轻松地生活。
该连接基于基本的
TCP三向握手算法。 执行syn,syn + ack,然后稍后更正请求(在图的左侧)。
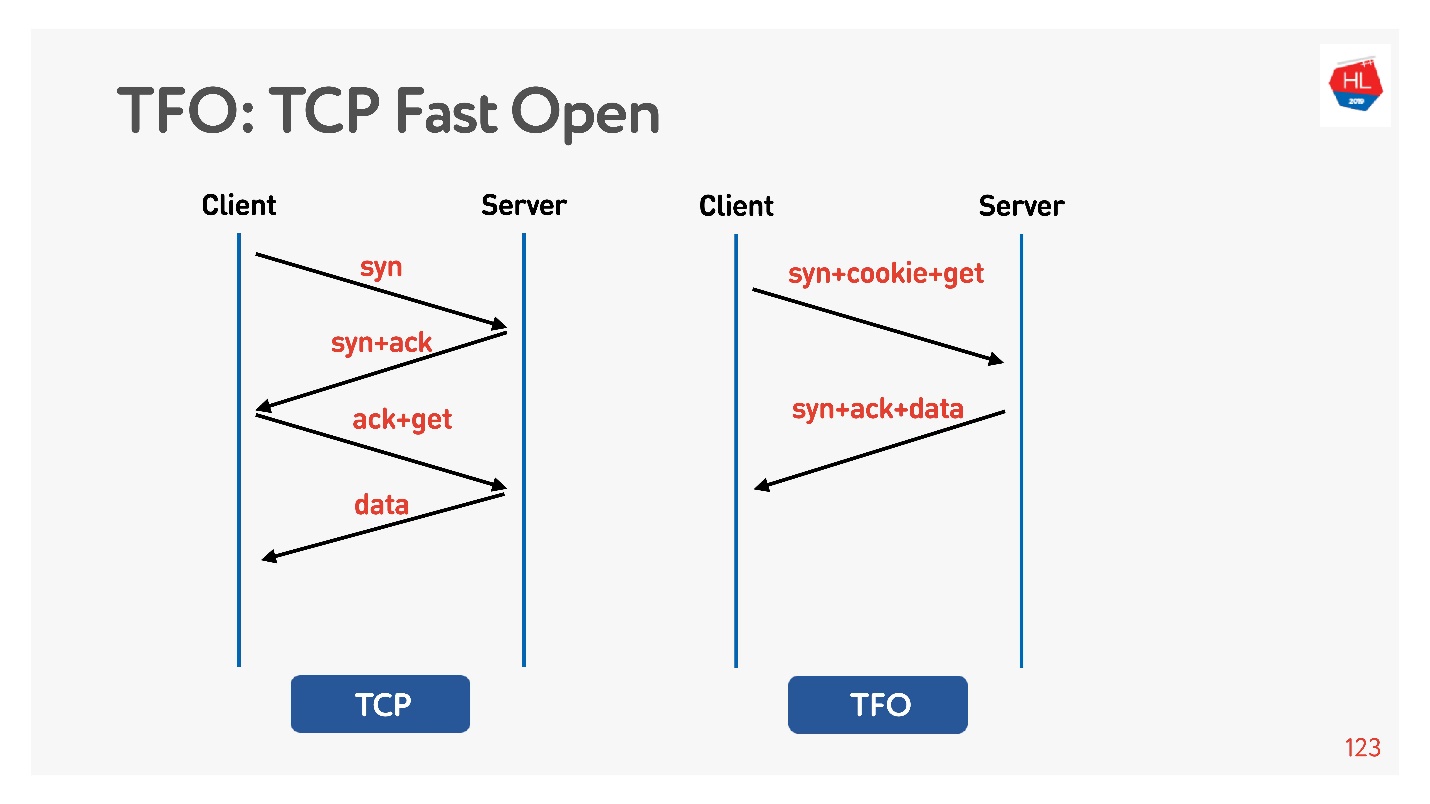
有
TCP快速打开 (右)。 如果您已经使用此服务器动手了,则有一个cookie,您可以立即发送零RTT的请求。 要使用此功能,您需要创建一个套接字,使sendto()为第一个数据,并说您要FASTOPEN。

Nginx可以做到所有这些-只需将其打开,一切都将起作用(或在内核中将其打开)。
TLS
让我们检查一下TLS是否无效。
我再次将net shaper设置为200 ms,对google.com进行了ping操作,发现RTT = 220是我的RTT + RTT shaper。 然后,我通过HTTP和HTTPS发出了请求。 我发现通过HTTP可以在RTT期间获得响应,即TFO在我的计算机上适用于Google。 对于HTTPS,这花费了更长的时间。

这是常见的TLS开销,需要进行消息传递才能建立安全连接。
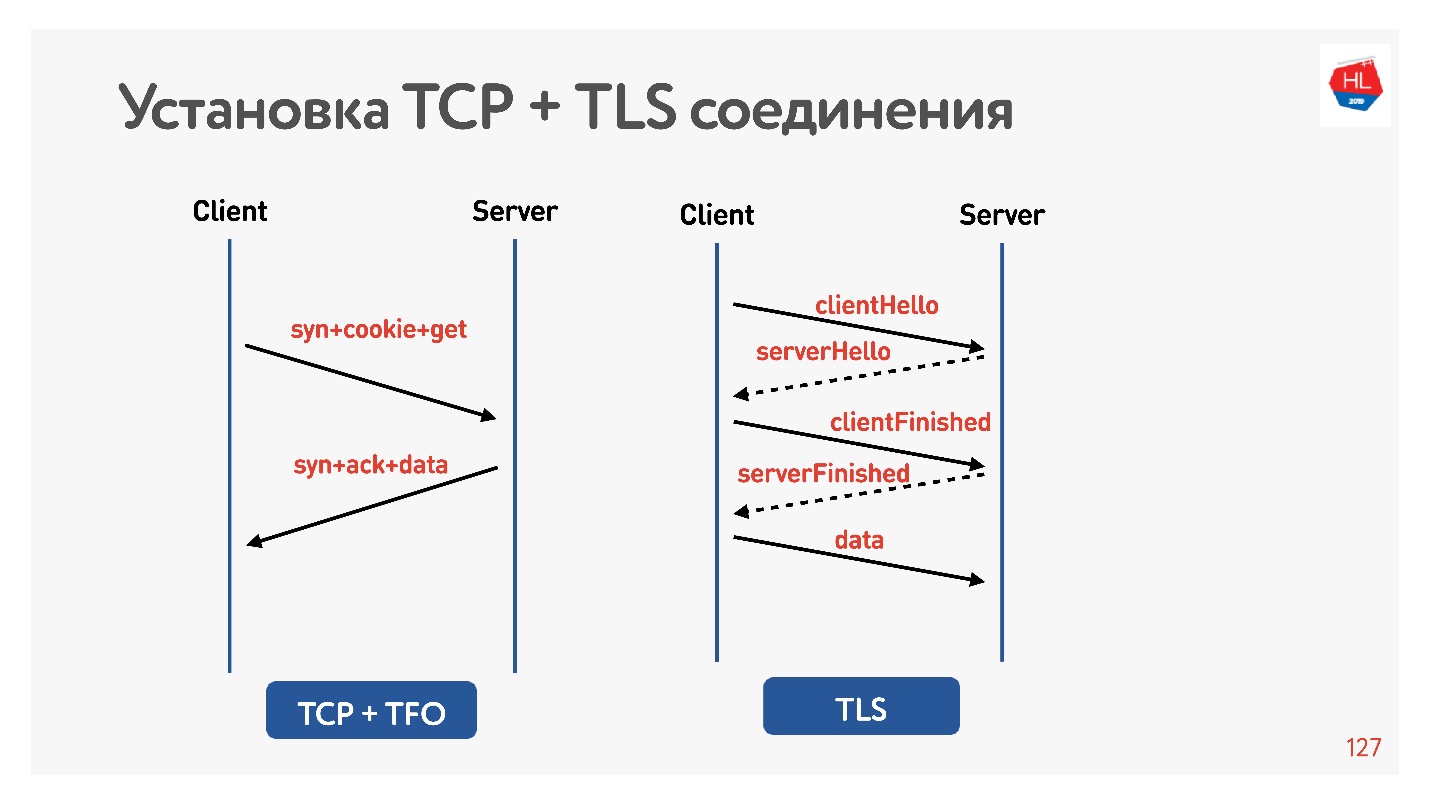
为此,他们认为我们添加了TLS 1.3。 也很容易将其包含在nginx中。
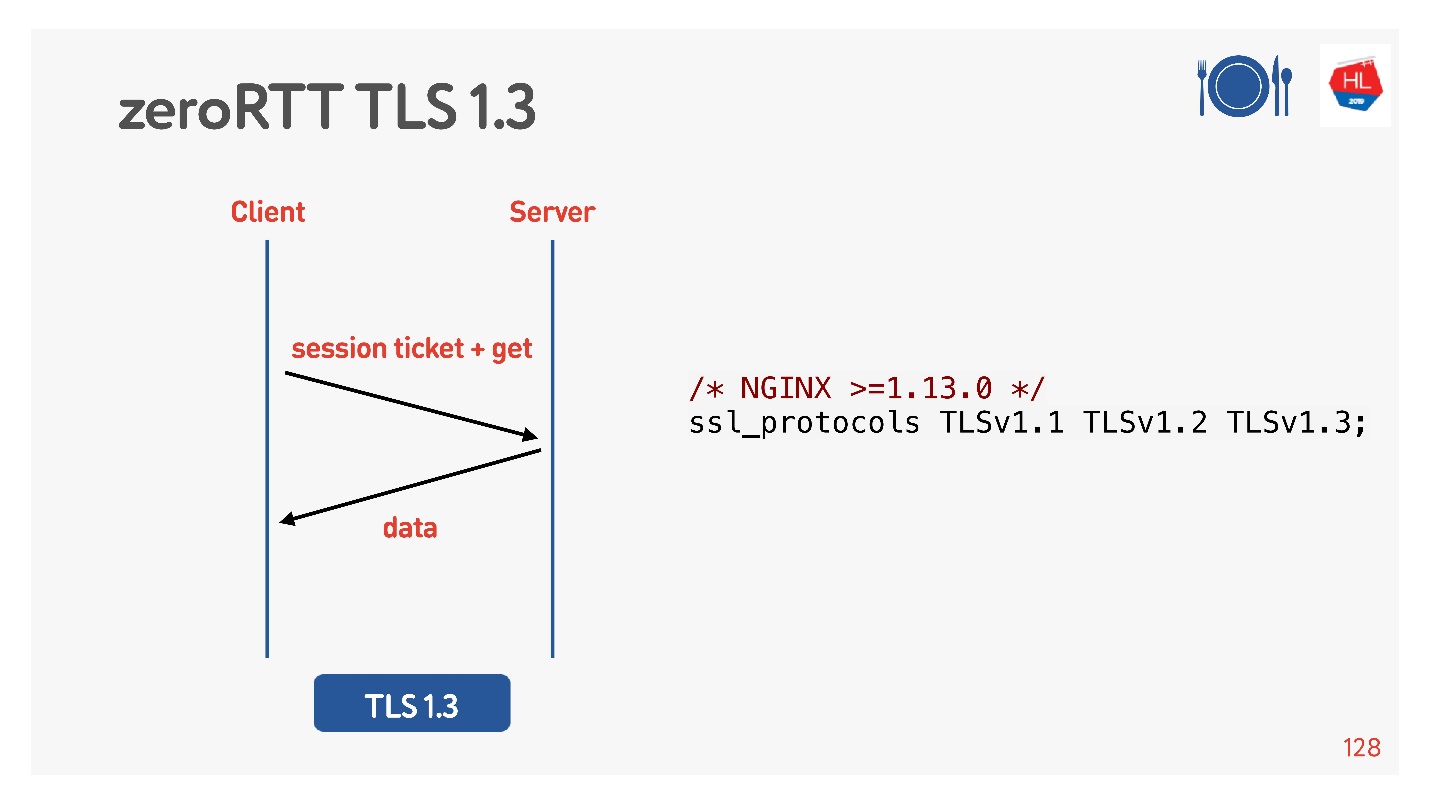
一切似乎都正常。 但是,让我们看看利用所有这些优势的移动客户端上有什么。
客户怎么了
TCP快速打开是一件很酷的事情。 据统计。
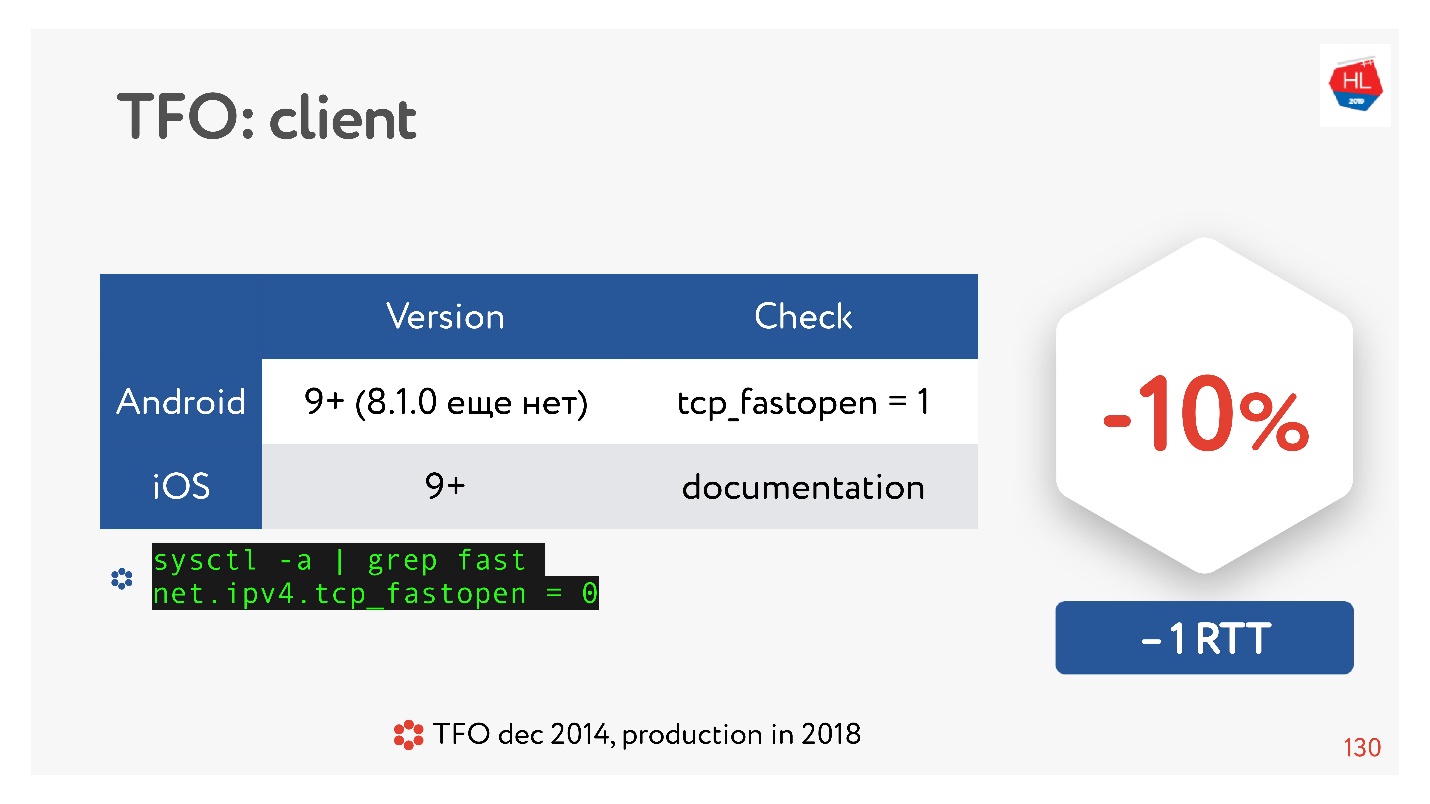
有许多文章说,建立连接的速度可以保证提高10%。 但是在Android 8.1.0(我看过各种设备)上,没有人拥有TFO。 在Android 9上,我在模拟器上看到了TFO,但在实际设备上却没有看到。 iOS好一点了。 在这里您可以看到它:
sysctl -a | grep fast net.ipv4.tcp_fastopen = 0
为什么会这样呢? TCP Fast Open早在2014年就提出来,现在已经是一个标准,在Linux上受支持,一切都很棒。 但是存在一个问题,即TFO握手在某些网络中开始崩溃。 这是因为某些提供程序(或某些设备)习惯于检查TCP并进行优化,而没有想到会有TFO握手。 因此,它的实现花费了很多时间,并且直到现在,移动客户端默认情况下都没有包括它,至少是Android。
使用TLS 1.3,可以保证零RTT连接设置更好。 我没有找到可以使用的任何Android设备。 因此,Facebook制作了
Fizz库。 几个月前,它已在开源中可用,您可以将其拖动并使用TLS 1.3。 事实证明,即使安全性也需要拖延,其核心内容却丝毫没有。
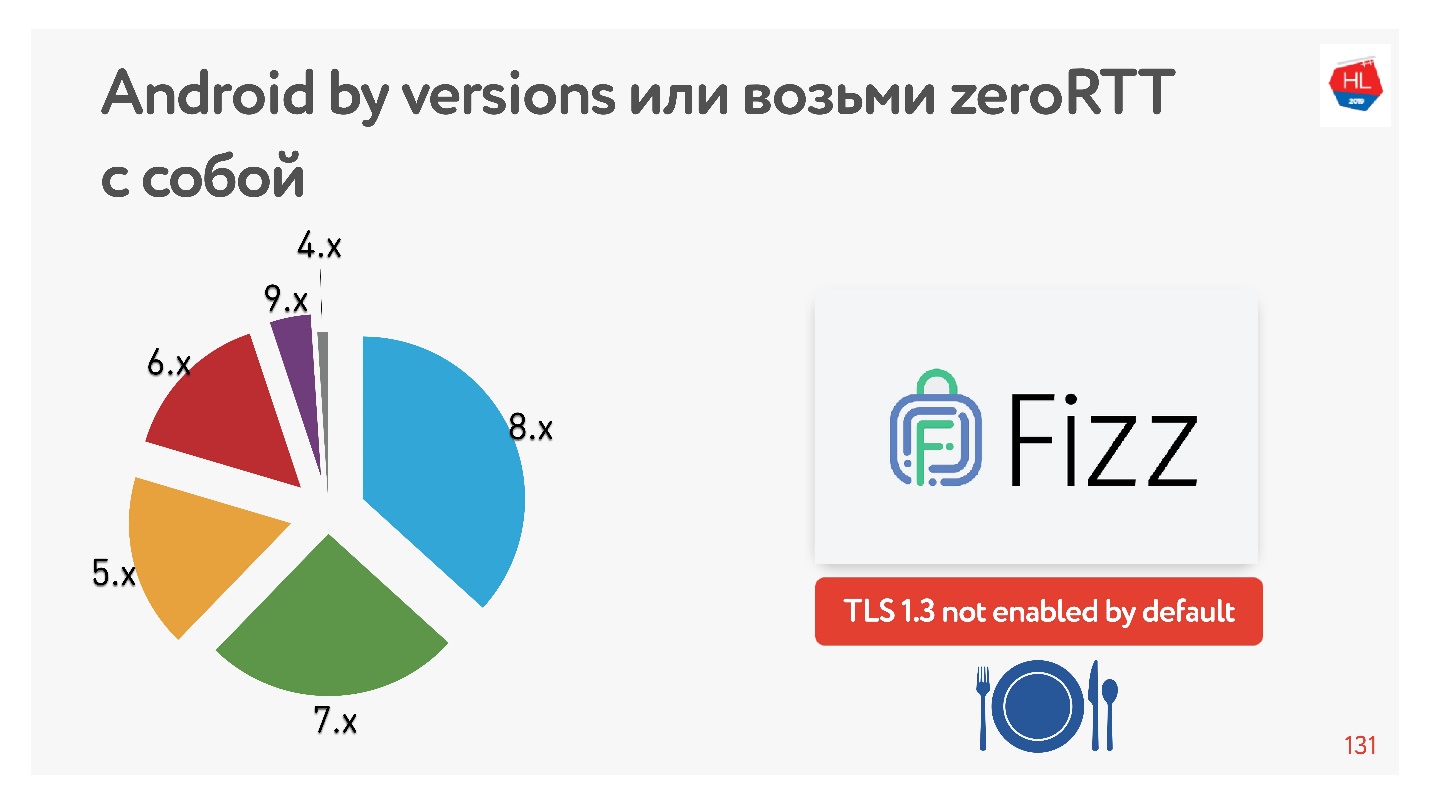
该图显示了我们的移动客户端使用的各种版本的Android。 V 9.x相当多-可以在其中显示TFO,而在其他任何地方都找不到TLS1.3。
关于建立连接的结论:- TFO不适用于95%的设备。
- TLS1.3需要自带。
- 如果需要在UDP中重复此操作,则将所有这些都传输到UDP并重复。
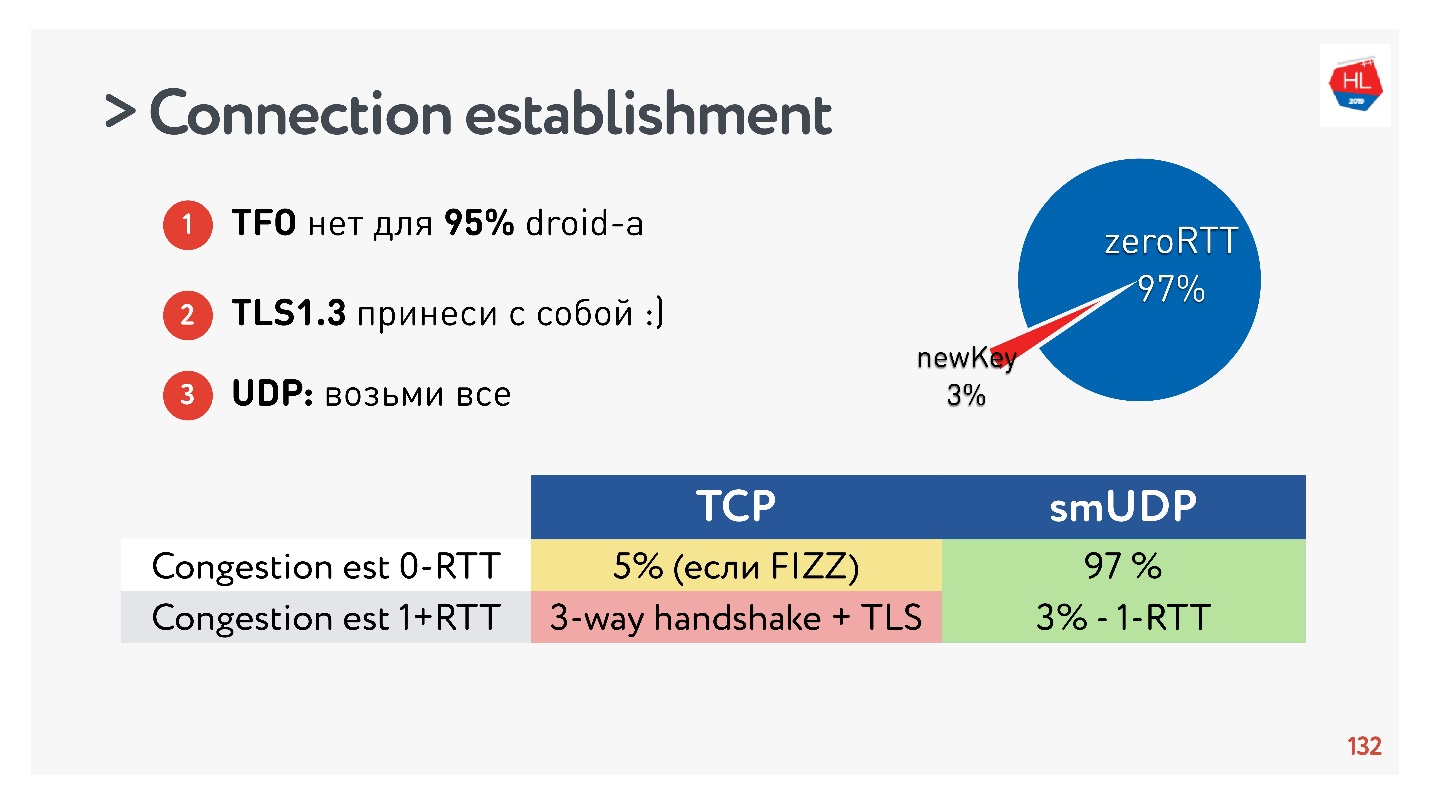
事实证明,已创建的连接中有97%使用现有密钥,即为零RTT创建了97%,而只有3%是新的。 密钥在设备上存储了一段时间。
TCP不能吹牛。 在最多5%的情况下,如果您正确执行所有操作,则将能够获得每个人现在都在谈论的真正的零RTT。
IP地址变更
通常,当您离开家时,手机会从Wi-Fi切换到4G。
TCP的工作方式如下:IP地址已更改-连接失败。
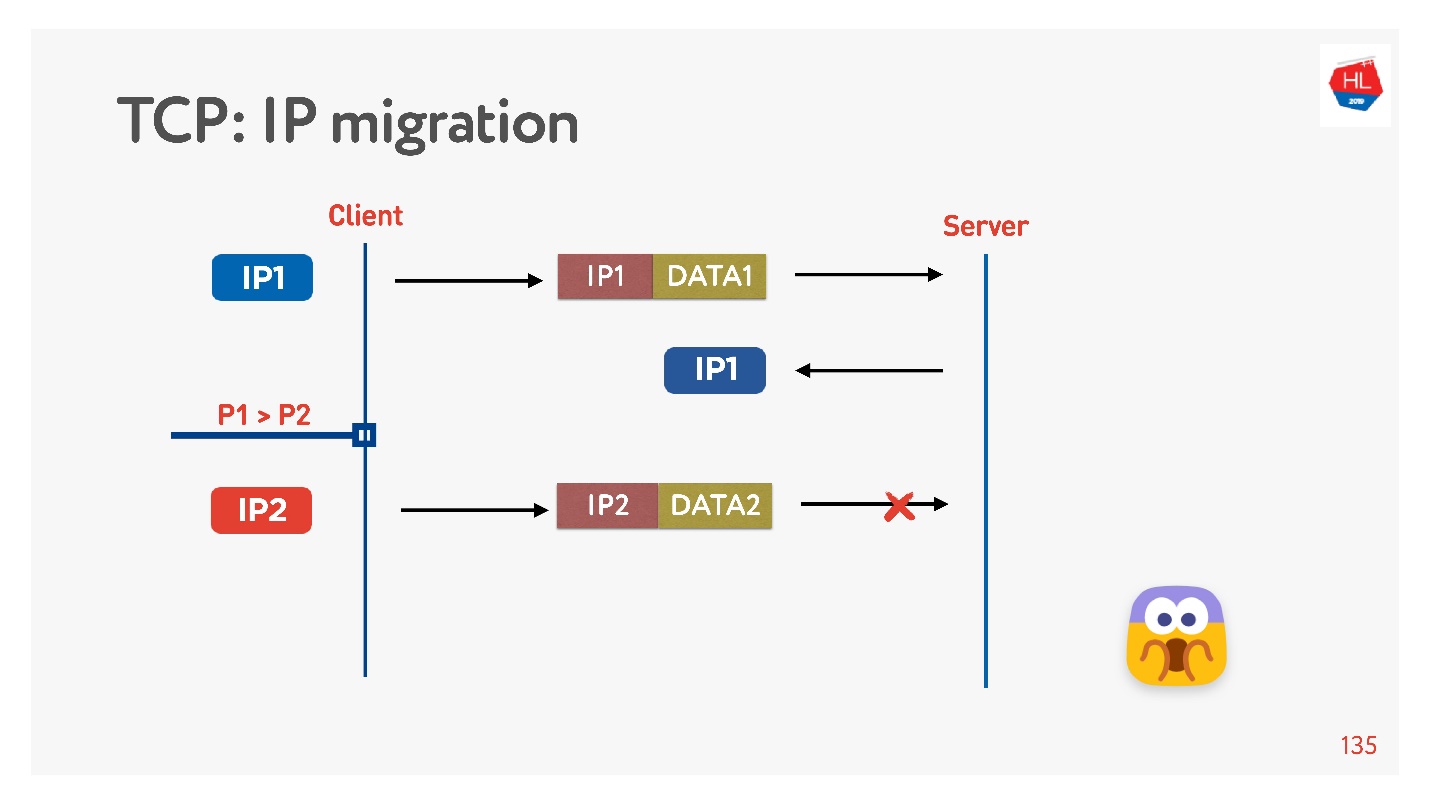
如果您编写UDP协议,则非常简单,只需在每个数据包中实现一个连接ID(CUID),就可以识别它,即使它来自其他IP地址也是如此。

显然,您需要确保它具有正确的密钥,所有内容都已解密,等等。 但原则上,您可以开始对此地址进行回复,因此不会有任何问题。
在TCP中,IP迁移是不可能的。
如果您使用UDP,并且使用的是同一台服务器,则需要做一点魔术,在每个数据包中包含CID,并且在更改IP地址时将能够使用已建立的连接。
连接重用
所有人都说您需要重用连接,因为连接是非常昂贵的事情。

但是重复使用化合物存在陷阱。
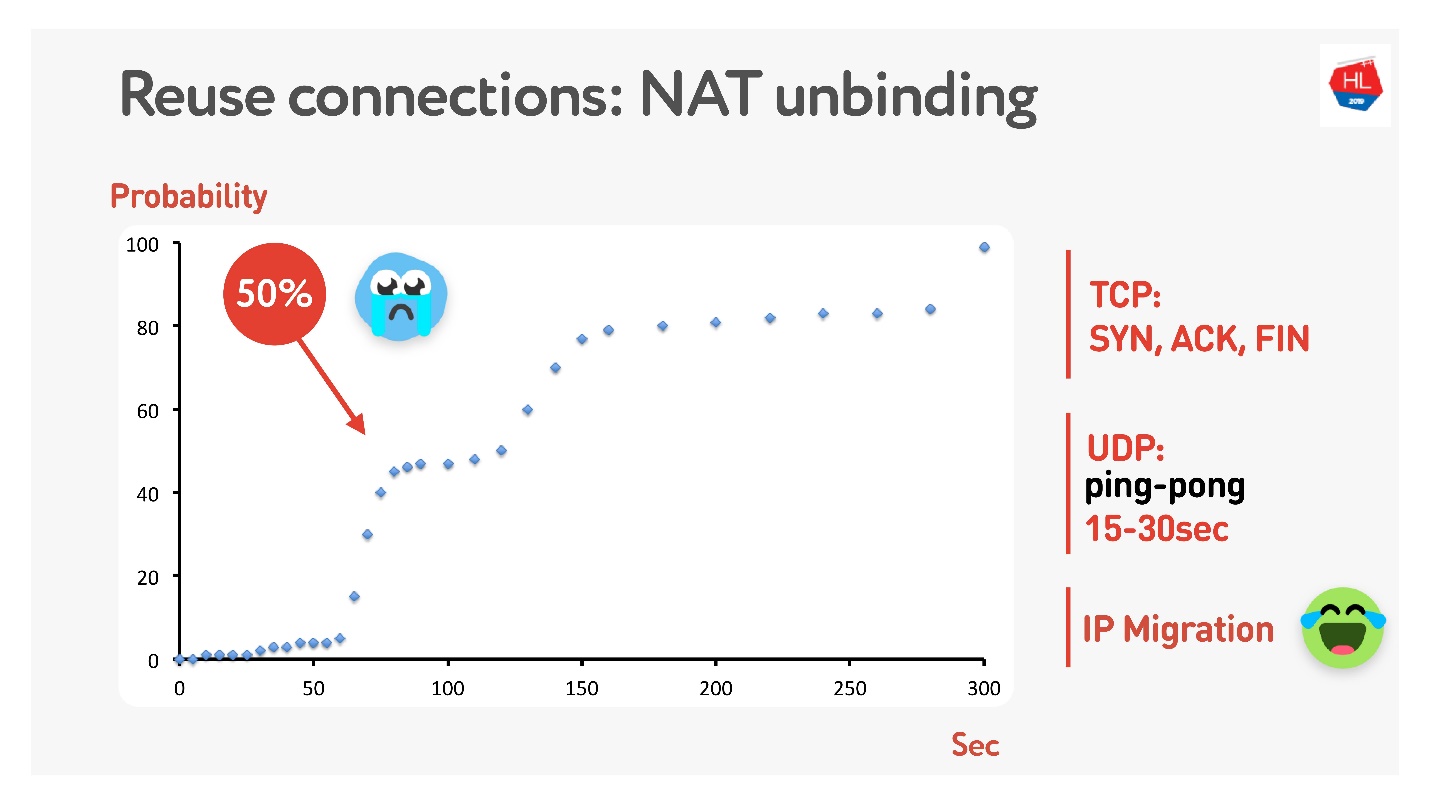
很多人很可能记得(如果没有,请参见
此处 ),并不是每个人都有公共地址,但是有NAT,通常在家庭路由器上存储映射一段时间。 对于TCP,很明显要存储多少,但是对于UDP,则不清楚。 NAT在超时上运行,如果您仔细测量该超时,我们会在大约15-30秒内得知超过50%的连接将开始失败。
没关系-我们将制作一个乒乓球包15秒钟。 对于连接仍然断开的情况,可以使用IP迁移,它可以廉价地更改路由器上的端口。
分组起搏
如果您正在执行UDP协议,这是非常重要的事情。

如果非常简单,则将数据包连续发送到网络的时间越长,数据包丢失的可能性就越大。 如果您过滤掉数据包,则数据包丢失将降低。
关于此工作原理的理论很多,但我喜欢这一理论。
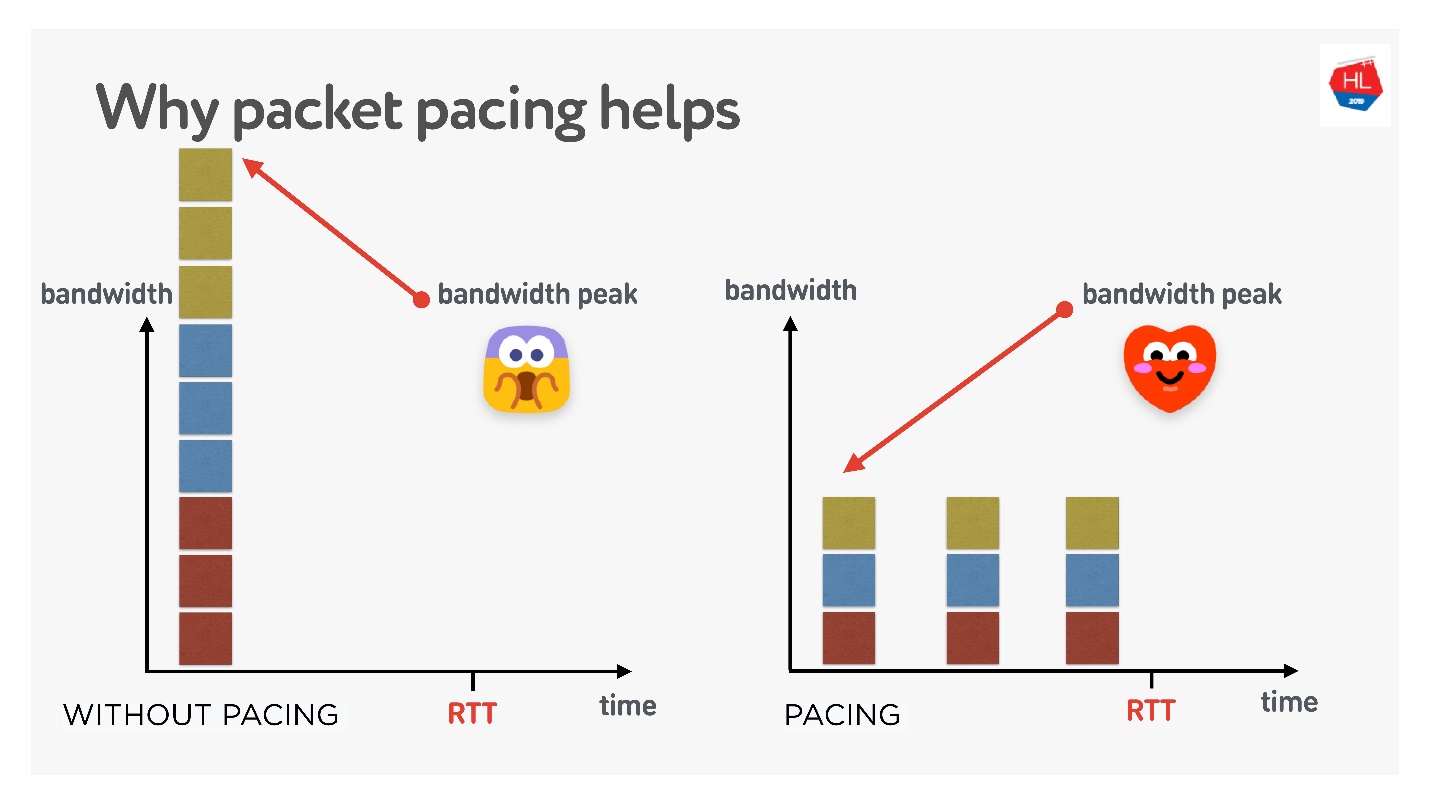
一次创建3个连接。 您拥有所谓的初始窗口-同时创建10个软件包。 当然,此时带宽可能还不够。 但是,如果您仔细分配它们,将它们分开,那么一切都会好起来的,如右图所示。
因此,如果为发送数据包设置统一的速率,将它们稀疏化,则同时发生缓冲区溢出的可能性将降低。 这还没有得到证明,但是从理论上讲,结果是这样的。

当您需要穿过数据包时(执行调步):
- 创建窗口时。
- 例如,当您放大窗口时,建议添加尽可能多的可发送给RTT / 2的数据包。 这不会降低传送时间,但会减少数据包丢失。
- 在拥塞丢失的情况下,为了减小窗口,您需要对数据包进行更多的涂抹。 4/5 RTT是根据经验选择的数字。
MTU
编写UDP协议时,请务必记住有关MTU的信息。 MTU是您可以转发的数据大小。
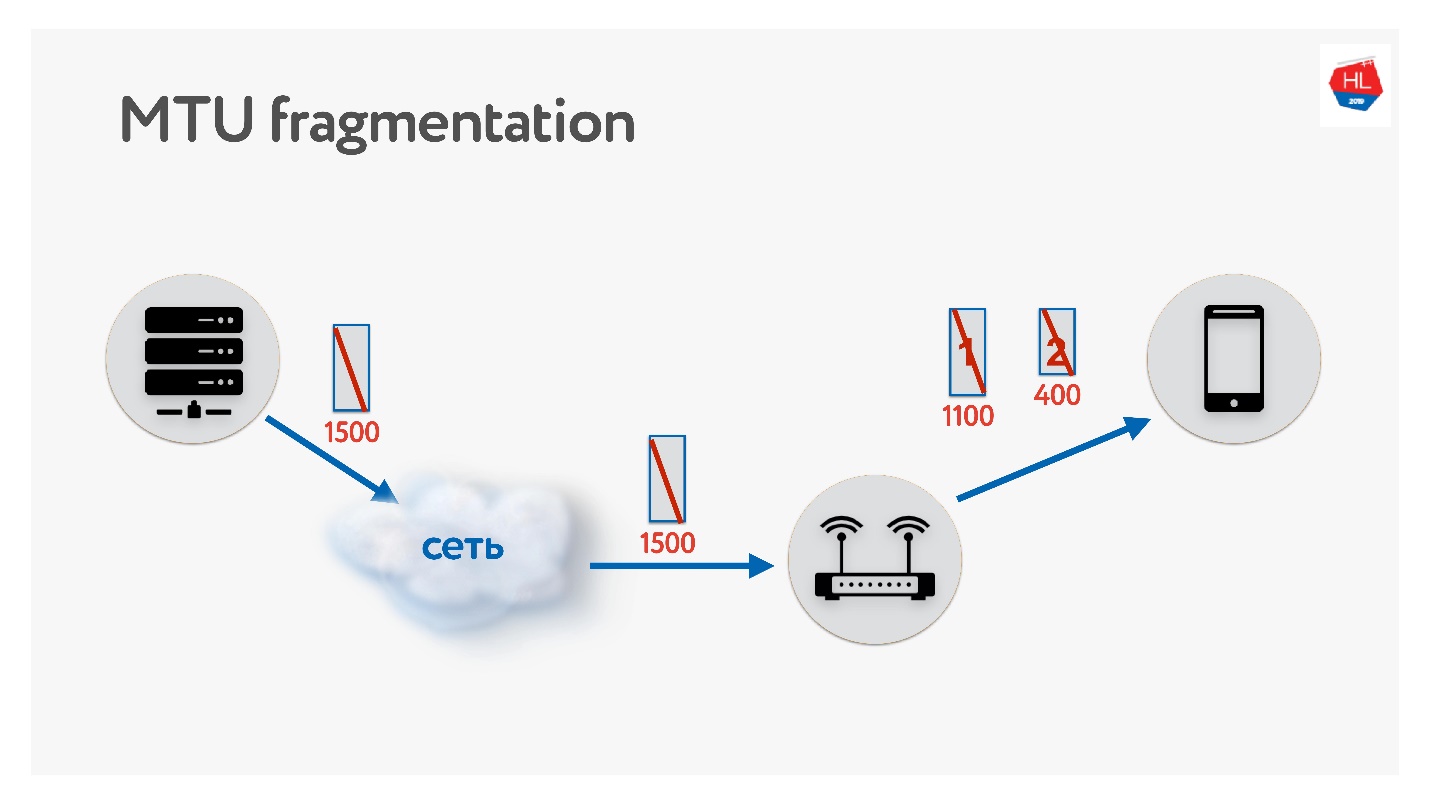
我们将例如大小为1500的数据包从服务器发送到客户端。如果路径上存在不支持此MTU大小的路由器,它将对其进行分段。 唯一的碎片问题是,如果丢失一个数据包,则两个数据包都会丢失,所有这些都必须重新传输。 因此,TCP具有确定MTU的算法-PMTU。

每个路由器查看其接口的MTU,将其发送到一个客户端,另一个路由器将其发送到其客户端,每个人都知道他们在客户端上有多少个MTU。 然后该标志禁止分段,并发送大小为MTU的数据包。 如果此时网络中有人意识到自己的MTU较小,那么他将通过ICMP表示:“抱歉,由于需要分段,数据包丢失了”,并指出MTU的大小。 我们将更改此尺寸并继续发货。 在最坏的情况下,我们的开销很少是RTT / 2。 这是在TCP中。
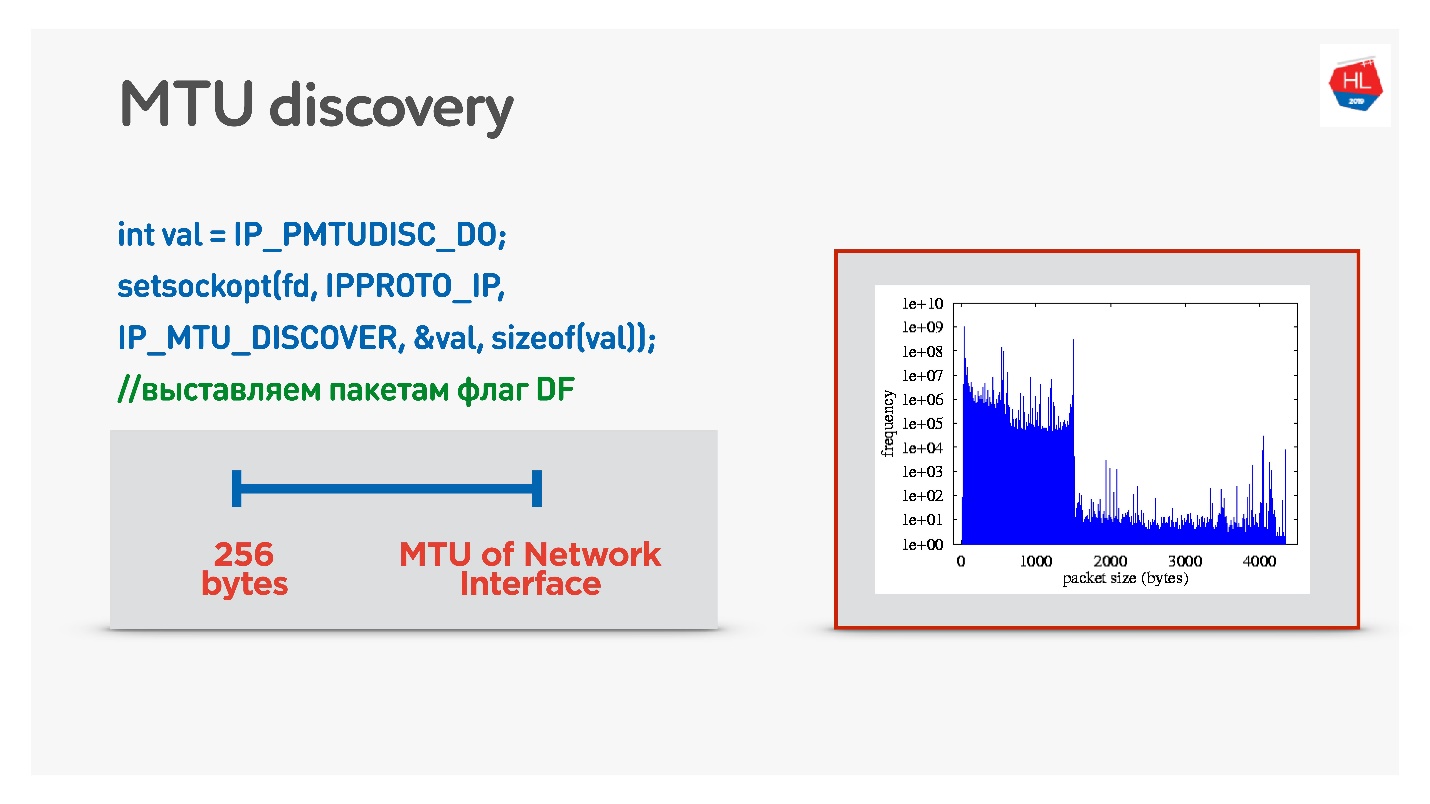
如果在UDP中您不想打扰ICMP,则可以执行以下操作:发送常规数据时允许分段。 也就是说,发送零散的数据包-让它们工作。 同时,为了启动一个禁止碎片的过程,二进制搜索将选择最佳的MTU,然后我们将进行选择。 这并不完全有效,因为起初MTU似乎会变热。
一个更棘手的选择是查看移动客户端之间的MTU分布。

从所有客户端,我们发送了各种大小的数据包,禁止分段。 也就是说,如果数据包没有到达,它将丢弃,最小的MTU应该达到100%。 但是丢包很小,因此图表上有两个幻灯片:
- 1350字节-我们立即获得95%的交付,而不是98%。
- 1500字节-MTU,此后已经有80%的客户端将不会收到此类数据包。
实际上,我们可以这样说:我们忽略了1-2%的客户,让他们生活在零散的包裹中。 但是我们会立即从所需的内容开始-这是从1350开始的。
纠错(SACK,NACK,FEC)
如果要制定协议,则需要更正错误。 如果数据包丢失(这对于无线网络是正常的),则需要对其进行还原。
在最简单的情况下(
此处有更多详细信息),通过重传超时(RTO)进行中继。 如果数据包丢失,请等待重传时间,然后再次发送。
下一个算法是
快速重传 。 这些都是TCP算法,但是可以轻松移植到UDP。
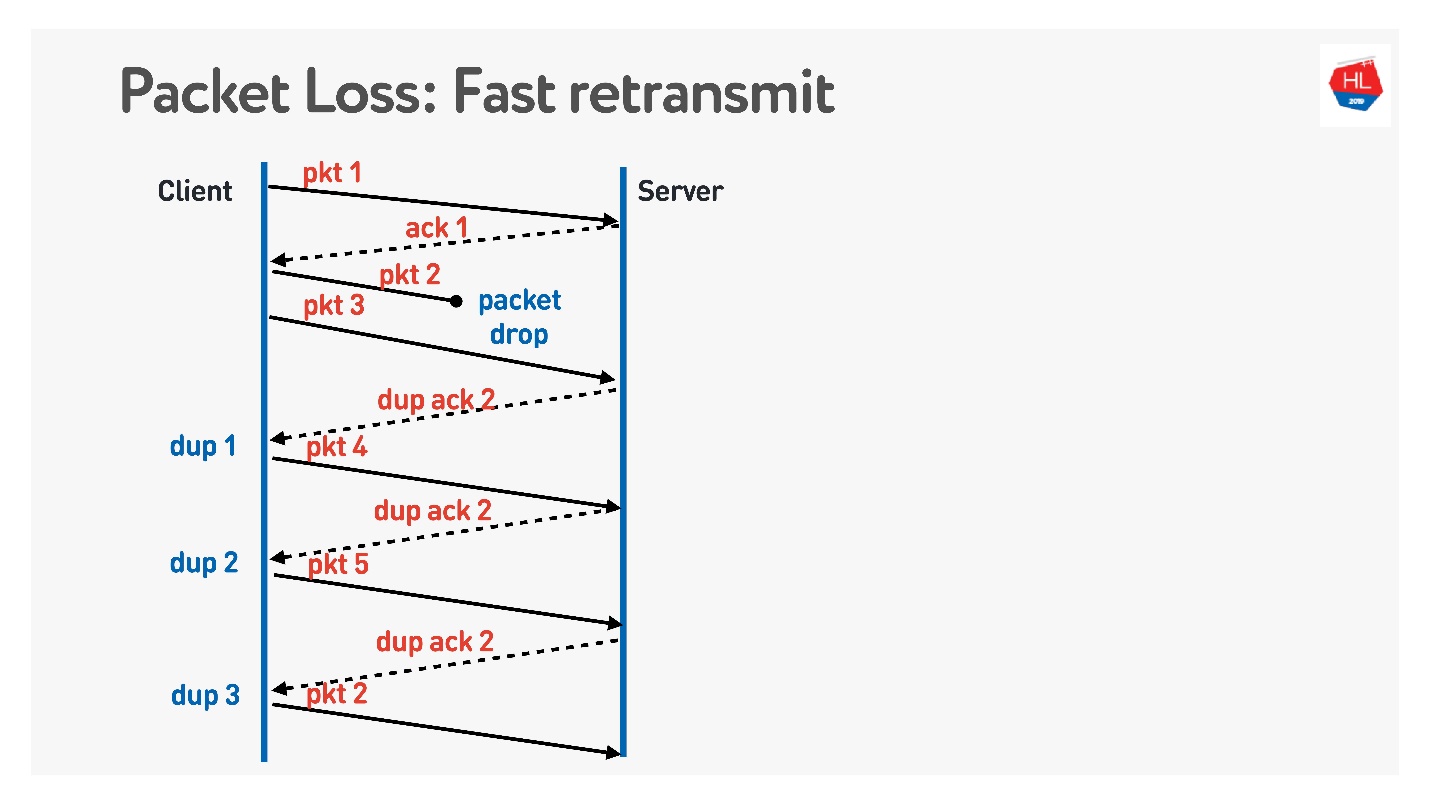
当数据包消失时,我们继续发送-传输其他数据包。 这时,服务器说收到了下一个数据包,但是没有上一个数据包。 为此,他进行了一个棘手的确认,该确认等于包号+ 1,并设置了重复的ack标志。 他如此发送了这些重复确认,并且在第三次我们通常了解到该数据包已消失并再次发送。
您还想做些经典的事情,TCP中没有的东西以及他们建议在UDP中做的事情就是
Forward Error Correction 。

似乎,如果我们知道软件包可能会丢失,则可以采用一组软件包,向其中添加XOR软件包,并在接收数据时立即在客户端上立即解决此问题而无需在客户端上进行其他重新传输。 但是,如果几个软件包消失了,就会出现问题。 似乎可以通过奇偶校验保护,Reed-Solomon等解决。
我们以这种方式进行了尝试,事实证明,实际上这些数据包消失了。
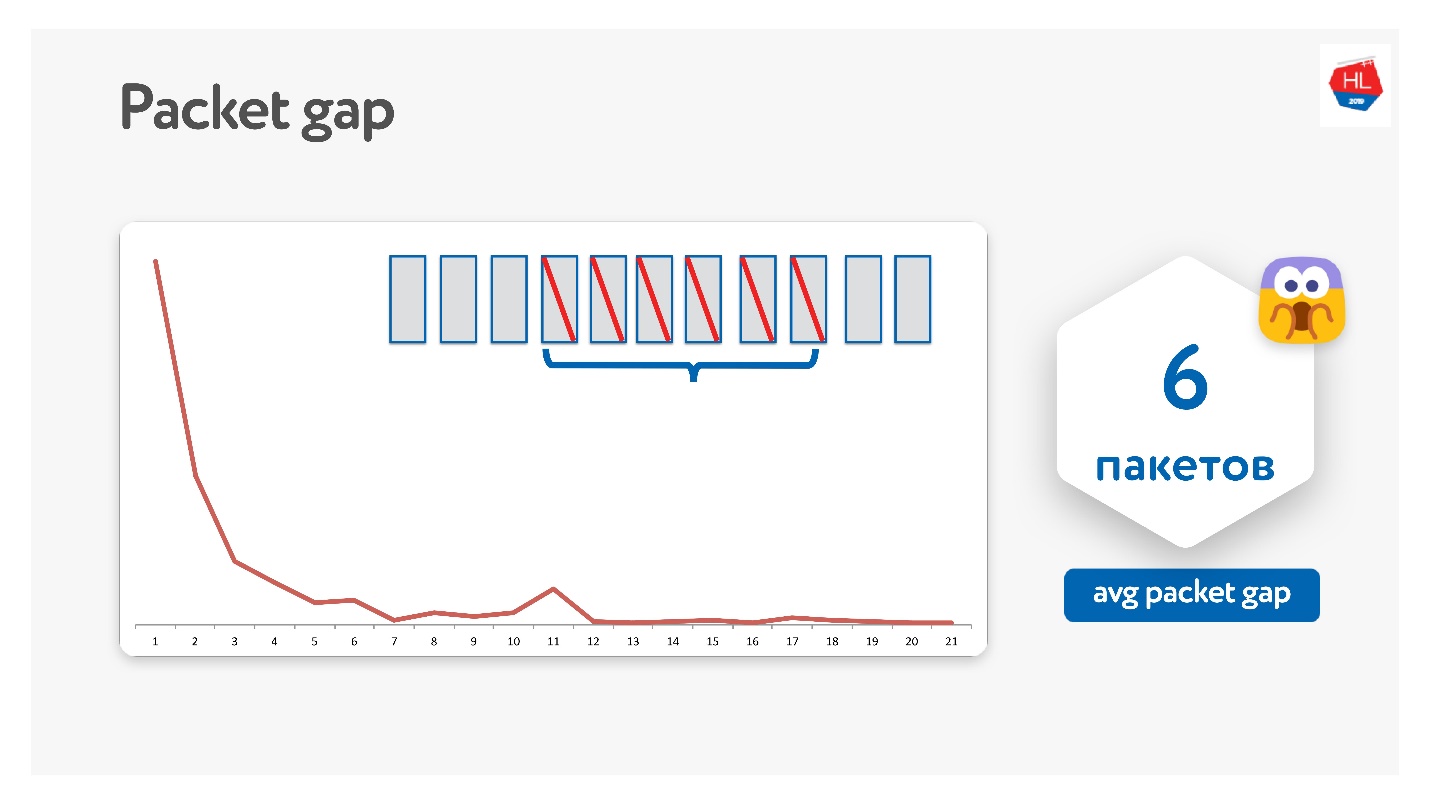
原来的平均数据包间隔为6。这是一个非常不方便的数据包间隔-您需要大量的纠错码。 同时,在11点有一个高峰-我不知道为什么,但是有时每包11个一包就会消失。 由于此数据包间隙,这是行不通的。
谷歌还尝试了这一方法,每个人都梦想着FEC,但是到目前为止,还没有人做过。
当FEC可以提供帮助时,还有另一种选择。

除了通过“重发超时”,“快速重发”进行重发外,还有一个
尾部丢失探测器 。 当您发送数据并且尾巴不见了时,这种事情就发生了。 也就是说,您发送了部分数据,发送了第五个数据包-它已经到达。 然后,例如由于网络故障,数据包开始消失。 数据包消失,消失,并且您仅收到第五个数据包的确认。
要了解是否已达到此数据,请在一段时间后开始执行TLP(尾部损耗探测),然后询问是否收到结束信息。 事实是数据传输已结束,并且您没有发送任何东西,则快速重传将无法工作。 要解决此问题,请执行TLP。
您可以将FEC添加到TLP。 您可以查看所有未到达的数据包,对它们进行奇偶校验,然后使用某些奇偶校验数据包发送TLP。
这一切都很酷,似乎可行。 但是有这样一个问题。
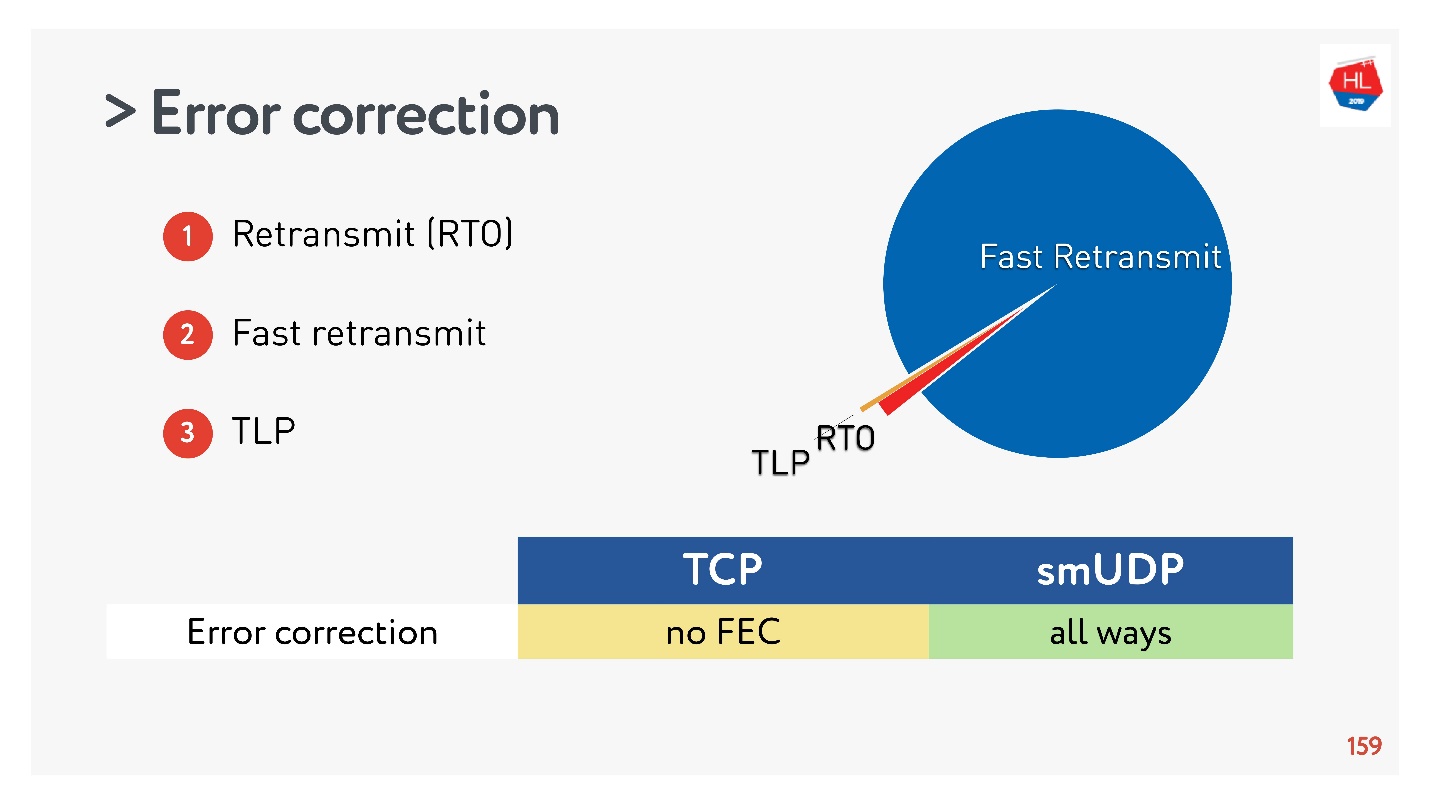
我们收集了统计数据,事实证明,98%的错误是通过快速重传修复的。 其余的通过“重新发送超时”进行修复,而不到1%的通过TLP进行修复。 如果您修复其他FEC,它将小于0.5%。
TCP不支持FEC。 在UDP中,这样做并不困难,但是在一般情况下,标准的TCP恢复算法就足够了。
性能表现
通过将TCP与UDP进行比较可能不会损害性能。
TCP是一种非常古老的协议,具有许多不同的优化功能,例如LSO(大段卸载)和零复制。 现在,对于UDP,所有功能均不可用。 因此,相对于来自相同服务器的TCP,UDP性能仅为20%。 但是已经有现成的解决方案(
UDP GSO ,
zerocopy )可以使Linux支持这一解决方案。
支持对零复制和LSO进行优化的主要问题是失去了步调。

上市时间或杀死TCP的原因
最近,当移动无线网络变得流行时,出现了许多不同的TCP标准:TLP,TFO,新的拥塞控制,RACK,BBR等。

但是主要的问题是许多协议尚未实现,因为据说TCP已经僵化了。 在许多情况下,运营商会查看TCP数据包并期望看到期望的结果。 因此,很难更改。
此外,移动客户端的更新时间很长,我们无法提供这些更新。 如果查看客户端上可用的最新最新更新以及服务器上的最新更新,可以说客户端上几乎没有任何内容。
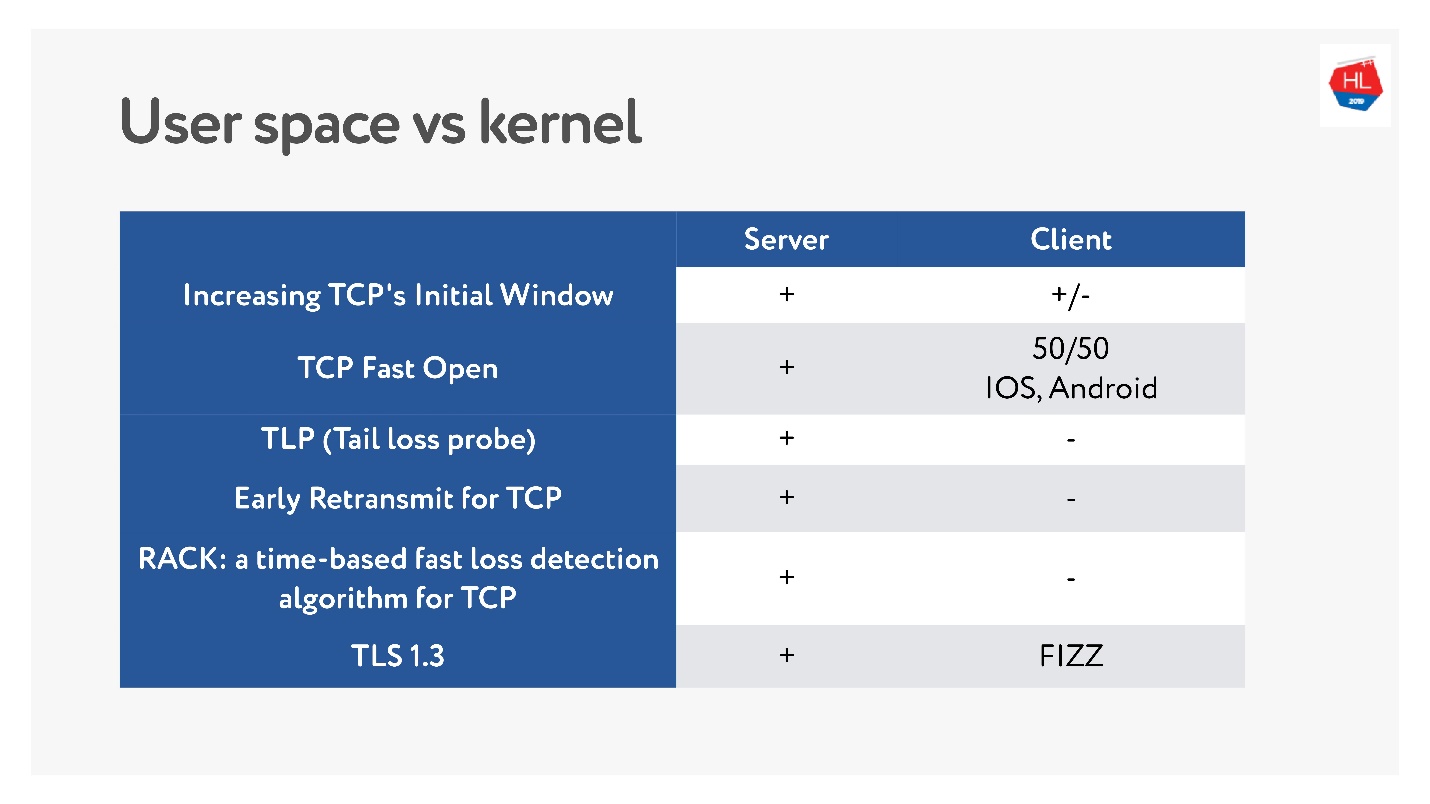
因此,至少在您积累了所有这些功能之后,决定在用户空间中写协议的决定似乎并不那么糟糕。

使用TCP,功能已滚动多年。 对于UDP协议,您可以在客户端和服务器的一次更新中从字面上升级版本。 但是您将需要添加版本协商。
TCP与自制UDP。 最后的战斗
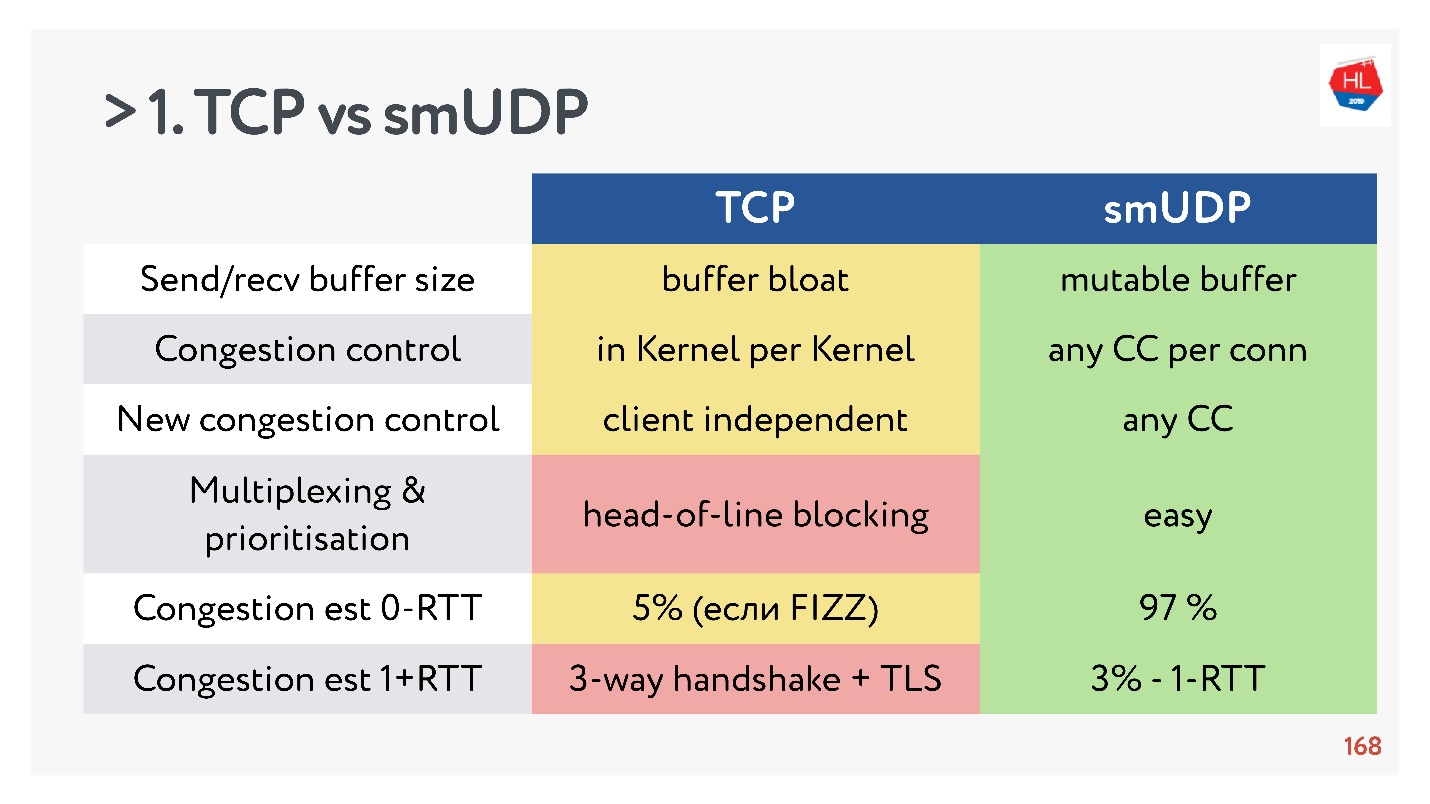
- 发送/接收缓冲区:可变缓冲区可以为您的协议完成,TCP缓冲区会出现问题。
- 您可以使用现有的拥塞控制。 在UDP中,它们是任意的。
- 很难将新的拥塞控件添加到TCP,因为您需要修改确认,因此无法在客户端上执行此操作。
- 复用是一个关键问题。 发生行头阻塞,当丢失数据包时,您将无法多路复用到TCP。 因此,不应该严重增加基于TCP的HTTP2.0。
- 可以在TCP中获得0-RTT的连接设置的情况非常少见,大约为5%,对于自制UDP大约为97%。

- IP迁移不是一个重要的功能,但是在复杂的订阅和服务器上存储状态的情况下,绝对是必需的,但它不是在TCP中实现的。
- Nat解除绑定不支持UDP。 在这种情况下,UDP通常需要做乒乓数据包。
- UDP中的数据包步调很简单,虽然没有优化,但在TCP中此选项不起作用。
- MTU和纠错均具有可比性。
- 如果要分配大量流量,TCP的速度当然比现在的UDP快。 但是随后,某些优化需要很长时间才能交付。
如果收集所有最重要的内容,则UDP更可能比利弊更多。
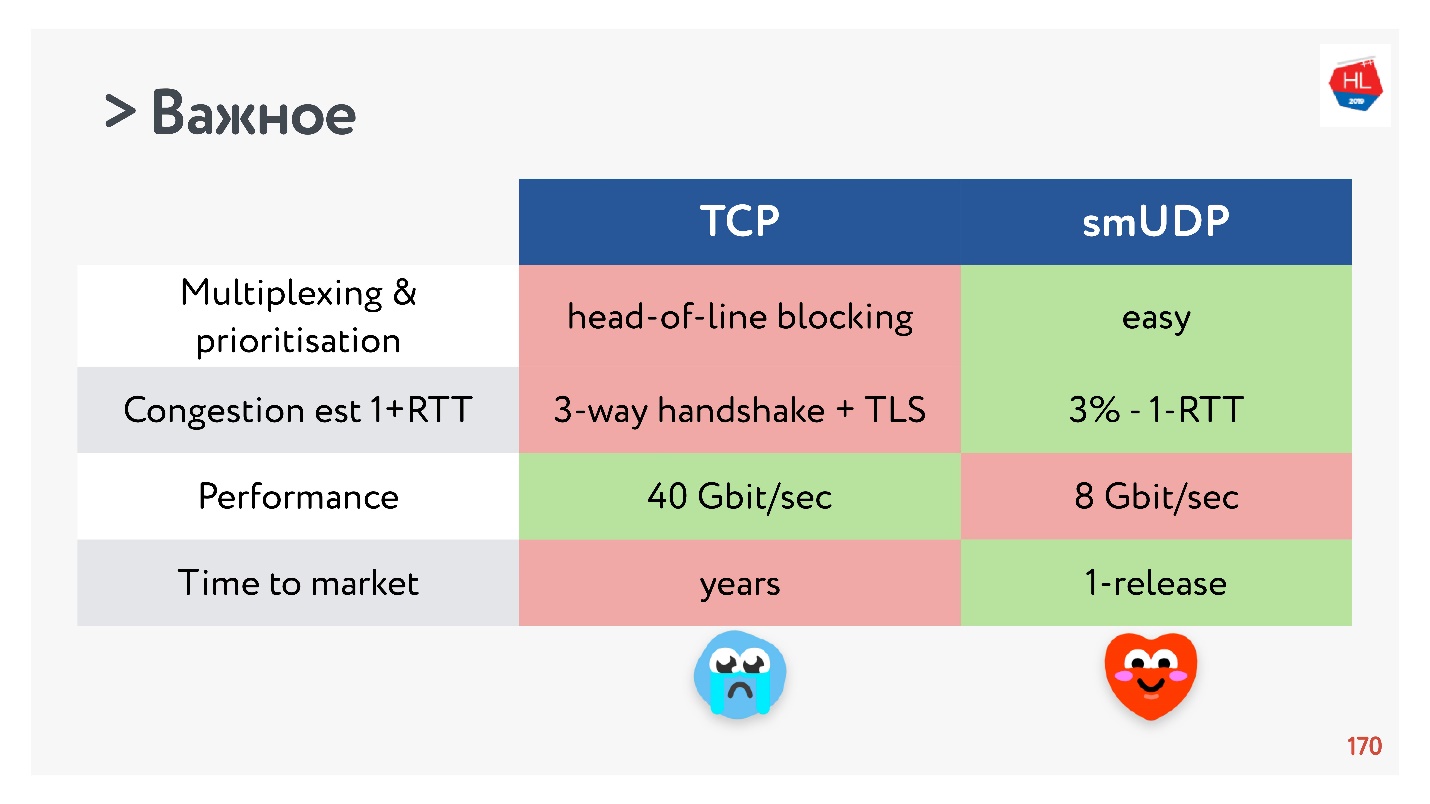 选择UDP!
选择UDP!在用户上测试自制的UDP
我们已经建立了一个测试平台。
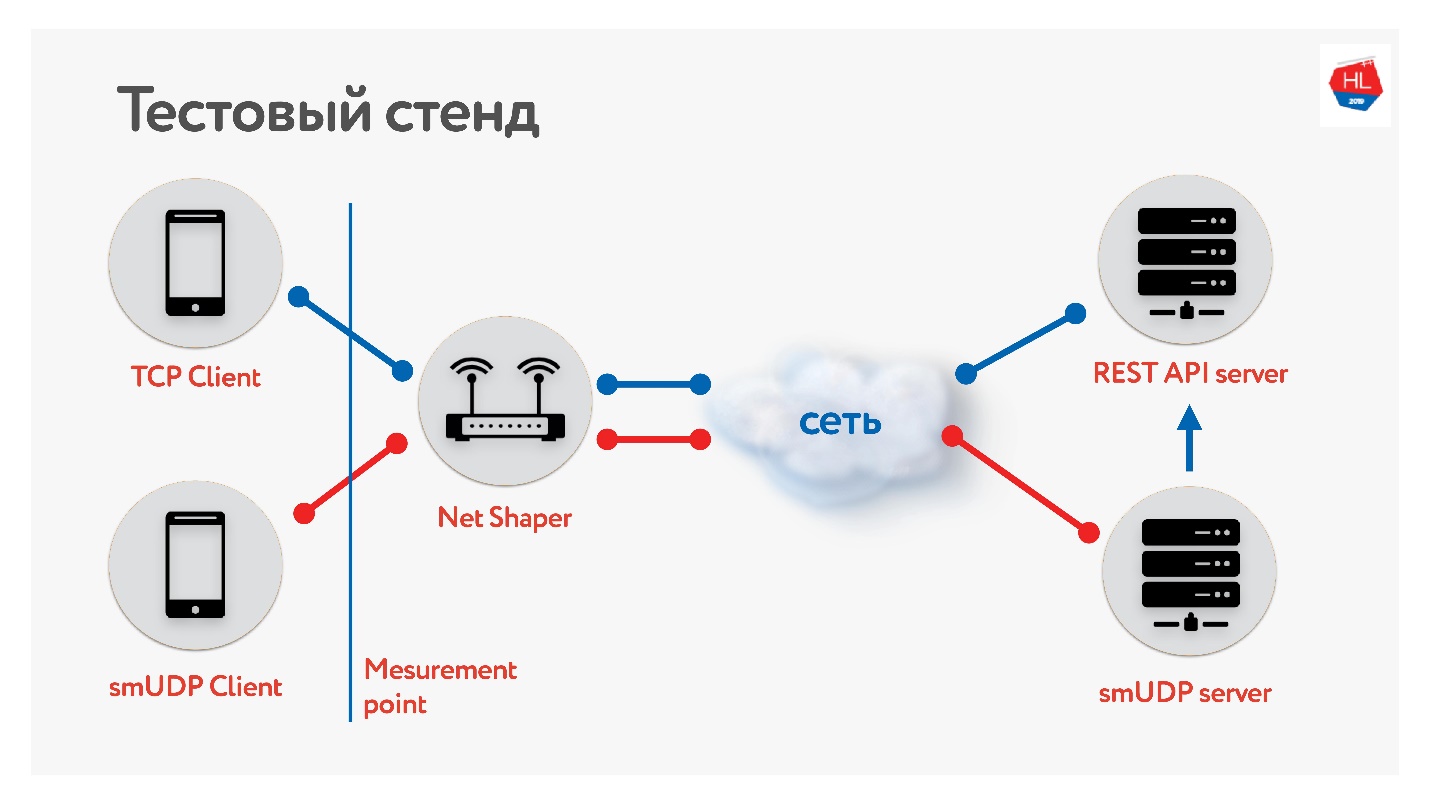
在TCP和UDP上有一个客户端。 我们通过网络整形器对流量进行归一化,然后将其发送到Internet和服务器。 一种是REST API服务,第二种是使用UDP。 UDP使用同一数据中心内的同一REST API来检查数据。 我们收集了移动客户端的不同配置文件并
启动了测试 。

通过测量门户的平均值,我们可以将调用API的时间减少10%,将图片的时间减少7%。 用户活动仅增长了1%,但我们不放弃,我们认为这会更好。

在负载方面,我们目前在自制UDP上大约有1000万用户,流量高达80 Gb / s,每秒600万个数据包,以及20台服务器都可以为之服务。
UDP清单
如果您要编写协议,则需要一个清单:
- 起搏
- MTU发现。
- 需要修复错误 。
- 流量控制和拥塞控制。
- (可选)您可以支持IP迁移,TLP很简单。
请记住,通道是不对称的,并且当您从服务器接收数据时,您的上载可能是空闲的,请尝试使用它。
QUIC
说谷歌没有,这是不诚实的。

Google在HTTP 2.0下实现了QUIC协议,该协议支持几乎相同的功能。
为什么QUIC没那么快
当QUIC问世时,人们非常讨厌Google所说的一切都运行得更快,而“我在家中用计算机对其进行测量-却运行得更慢”。
 本文提供了
本文提供了大量图片和测量结果。
好吧,事实证明我们徒劳地做到了这一切,人们为我们衡量了吗? 即使有代码示例,也可以进行实际的家庭测量。

实际上,只有在并行化请求,在实际网络上工作以及将分组丢失分为拥塞丢失和随机丢失之前,情况才会有所改善。 我们需要真实网络的真实仿真。
他们说,有一个积极的方面,QUIC既不好也不坏。 因此,在完美的网络中,QUIC运作良好。
未来
谷歌最近将HTTP 2.0命名为QUIC HTTP 3之上,不要混淆,因为HTTP 2.0可以位于TCP之上和QUIC之上。 现在是HTTP 3。
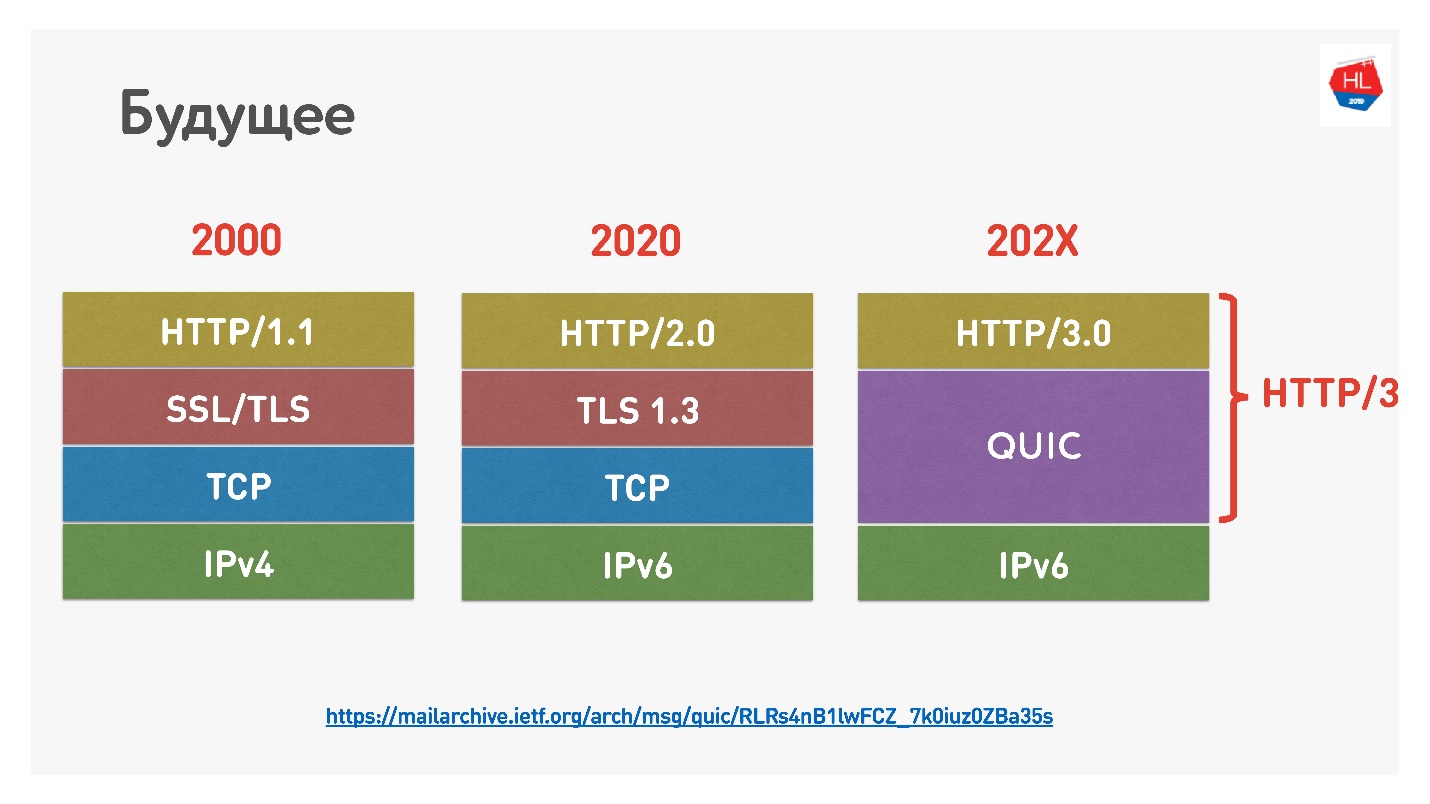
还有
Google QUIC-这是在Chrome中实现的QUIC,以及iQUIC-标准化的QUIC。 标准化的QUIC并未在任何地方实现,标准的iQUIC服务器并未与Google QUIC握手。 现在他们承诺将解决这个问题,并且很快就会出现。
QUIC无处不在
如果您仍然不相信TCP已经失效,那么我会告诉您,当您使用Chrome,Android和不久的iOS并转至google,youtube等时,您将使用QUIC和UDP(
prooflink )。
QUIC现在是:
- 占所有网站的1.9%;
- 所有流量的12%;
- 移动网络上视频流量的30%。
如果您不相信,该如何检查您是否使用QUIC? 在Chrome Wireshark中打开。 我一直在寻找iQUIC,但在任何地方都找不到,但是GQUIC确实发生了。
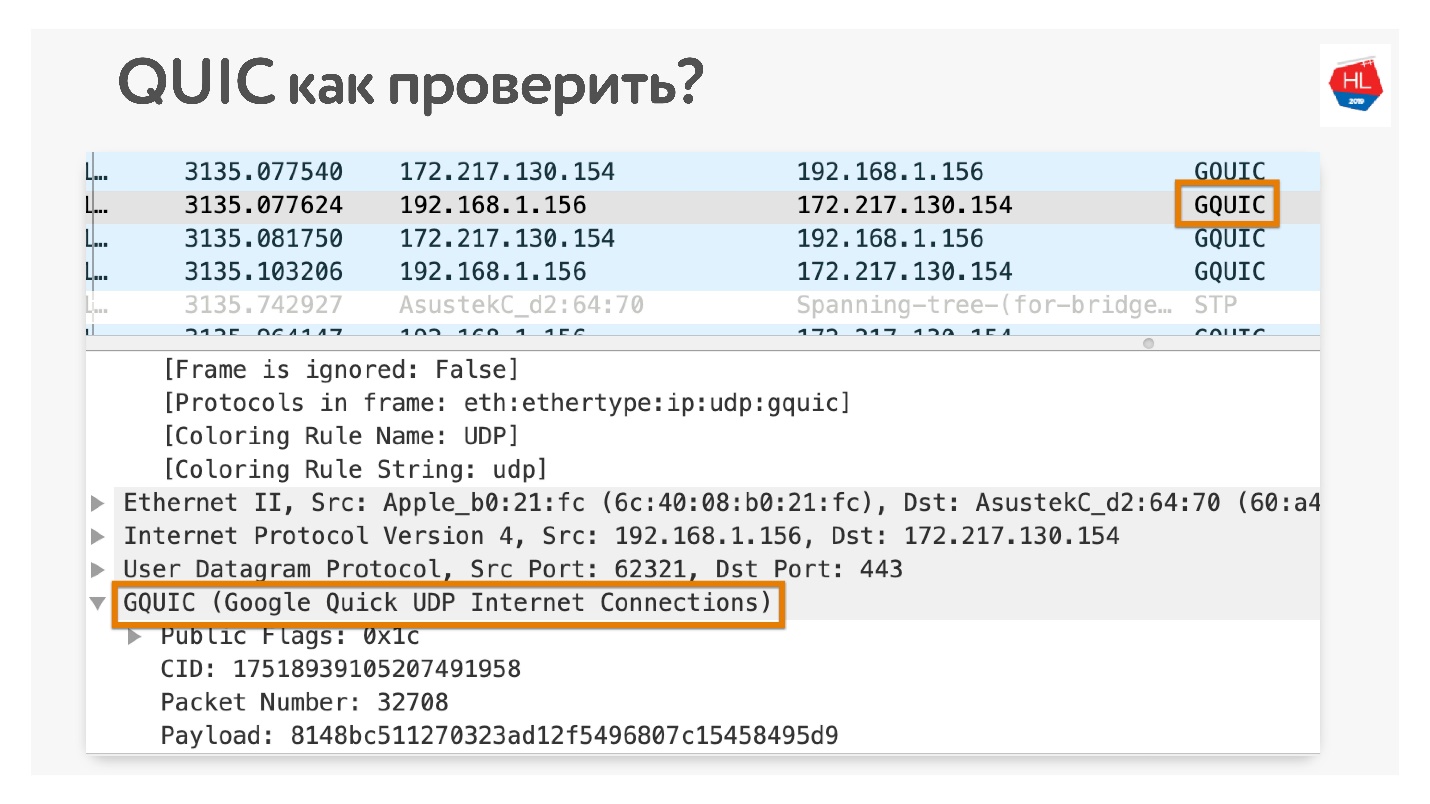
您也可以在浏览器中联机并查看那里有什么GQUIC。

一些未来
多路径正在等待我们。
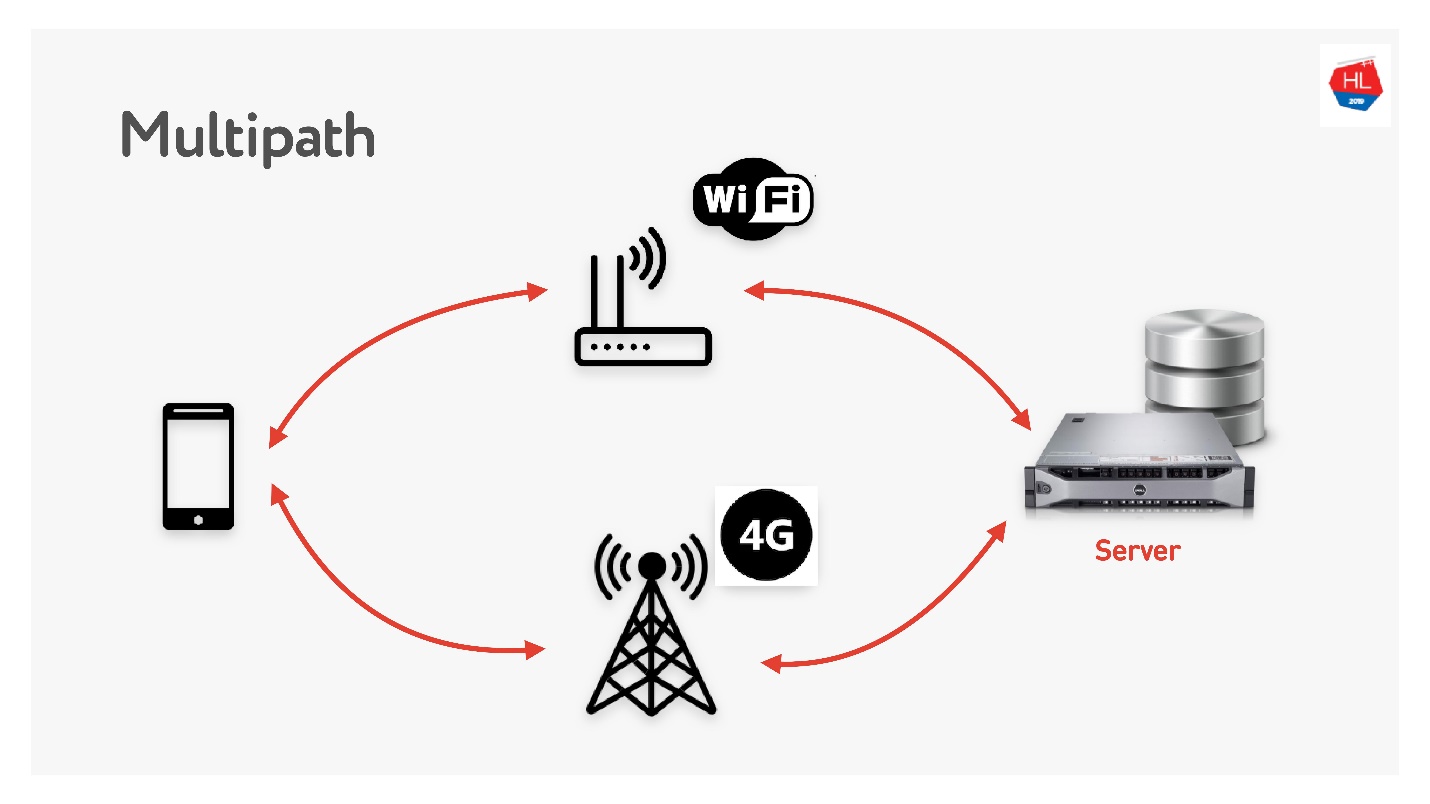
当您同时具有Wi-Fi和3G的移动客户端时,可以同时使用两个通道。 多路径TCP现在正在开发中,并将很快在Linux内核中可用。 显然,它不会很快送达客户,我认为可以在UDP上更快地完成。
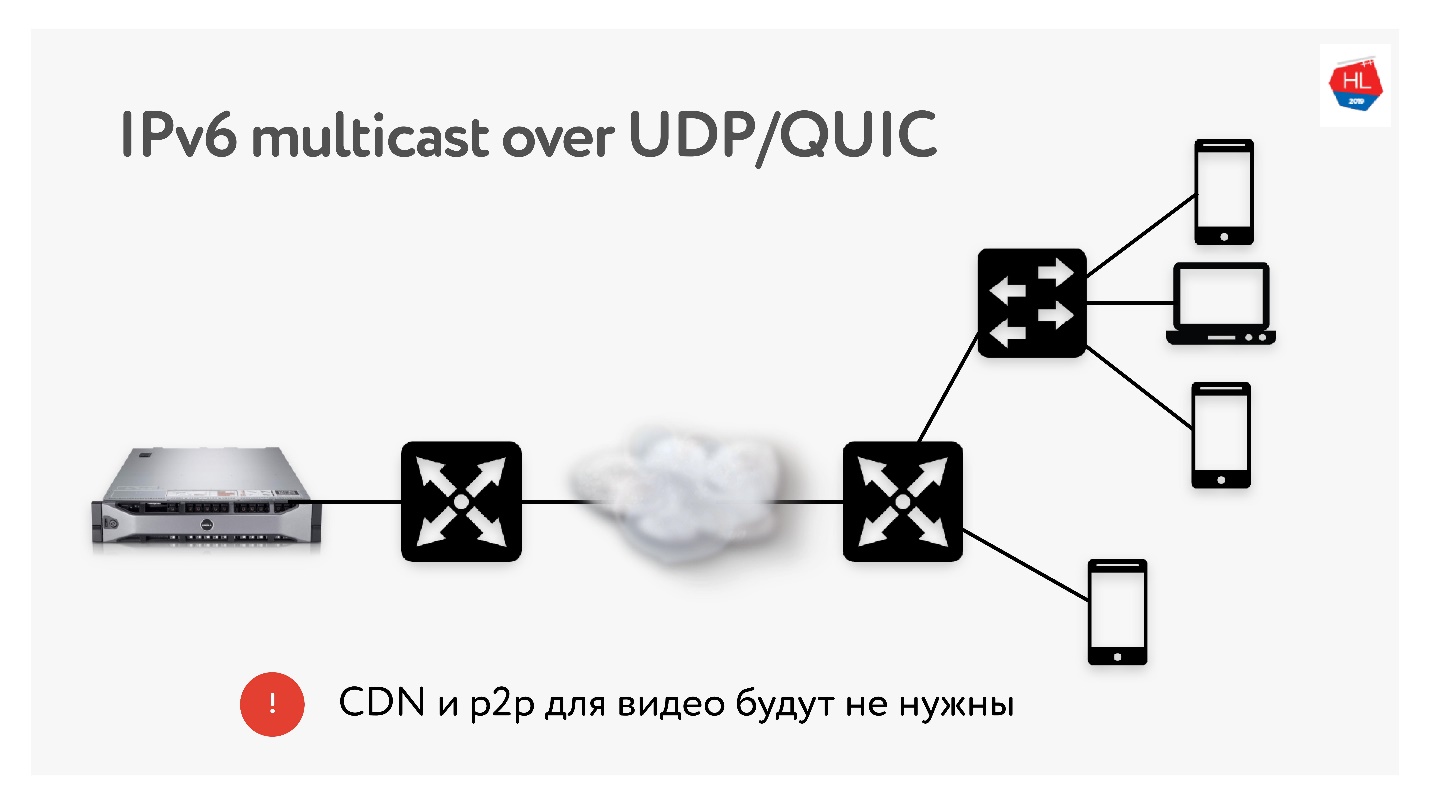
由于我们每次都要进行大量3 TB的转换,因此当需要将相同的内容交付给世界各地的许多用户时,我们经常使用CDN和p2p分发之类的技术。
在IPv6中,使用UDP进行多播,这将允许一次将数据包传递给多个订阅的用户。 因此,我认为,如果我们使用多播向IPv6交付所有内容,则在不久的将来将不需要CDN和p2p技术。
结论
希望您能理解:
- 网络的实际运行方式,并且可以通过UDP重复进行TCP传输,并且性能更好。
- 如果配置正确,TCP并不是很糟糕,但是它确实放弃了,并且几乎不再开发。
- 不要相信会在用户空间中无法正常工作的UDP仇恨者。 所有这些问题都可以解决。 尝试-这是不久的将来。
- 如果您不相信它,那么您可以并且应该用手触摸网络。 我展示了几乎所有内容都可以检查的内容。
您阅读了所有内容,并弄清楚接下来要做什么?
- 根据情况(网络配置文件+负载配置文件)配置协议(TCP,UDP-没关系)。
- 使用我告诉您的TCP配方:TFO,发送/接收缓冲区,TLS1.3,CC ...
- 如果有资源,请建立UDP协议。
- 如果已完成UDP,请检查UDP检查列表是否已完成所需的所有操作。 忘记任何无用的内容,例如节奏,都行不通。
如果您没有资源,请为QUIC准备基础架构。 迟早他会来找你的。
我们正在确定未来。 我们决定使用哪种协议。 如果您想使用QUIC-如果需要UDP或使用TCP,请使用QUIC-自己决定未来。
有用的链接
在9月7日之前,您仍然可以提交 Moscow HighLoad ++ 的申请 ,并分享如何为高负载准备服务。 但是该程序已经逐渐被填充,已经从Odnoklassniki收到了有关好友图的新体系结构,针对高负载优化礼品服务以及如果您对所有内容进行了优化且数据无法足够快地到达用户该怎么办的报告 。