
两年前,谷歌负责人桑达尔·皮查伊(Sundar Pichai)表示,该公司从移动优先变成了人工智能第一,并专注于机器学习。 一年后,发布了机器学习套件-一系列工具,您可以使用它们在iOS和Android上有效地使用ML。
在美国,有关ML套件的讨论很多,但几乎没有俄文的信息。 由于我们在Yandex.Money中将其用于某些任务,因此我决定与他人分享经验,并通过示例演示如何使用它来完成有趣的事情。
我的名字叫Yura,去年我一直在Yandex.Money团队的移动钱包上工作。 我们将讨论移动机器学习。
注意事项 社论:这篇文章重述了Yandex.Money Android Paranoid mitap的Yuri Chechetkin的报告“从移动优先到人工智能优先”。
什么是ML套件?
这是Google的移动SDK,可轻松在Android和iOS设备上使用机器学习。 不必成为ML或人工智能方面的专家,因为在几行代码中您可以实现非常复杂的事情。 此外,不必知道神经网络或模型优化如何工作。
ML套件可以做什么?
基本功能非常广泛。 例如,您可以识别文本,面部,查找和跟踪对象,为图像和自己的分类模型创建标签,扫描条形码和QR标签。
我们已经在Yandex.Money应用程序中使用了QR码识别。
还有一个ML套件
- 地标识别;
- 文字书写语言的定义;
- 设备上文本的翻译;
- 快速回信或信件。
除了开箱即用的大量方法外,还支持自定义模型,这实际上提供了无穷的可能性-例如,您可以为黑白照片着色并使其变色。
重要的是,您不需要为此使用任何服务,API或后端。 一切都可以直接在设备上完成,因此我们无需加载用户流量,也不会出现很多网络错误,也不必处理很多情况,例如,互联网中断,连接中断等。 而且,在设备上它的工作速度比通过网络快得多。

文字识别
任务:给定一张照片,您需要使文本以矩形圈出。
我们从Gradle中的依赖关系开始。 连接一个依赖项就足够了,我们已经准备好工作。
dependencies {
值得指定元数据,该元数据表示将从Play Market下载应用程序时将模型下载到设备。 如果您不执行此操作而没有模型就访问API,则会收到错误消息,并且必须在后台下载模型。 如果需要使用多个模型,建议使用逗号分隔它们。 在我们的示例中,我们使用OCR模型,其余名称可在文档中找到。
<application ...> ... <meta-data android:name="com.google.firebase.ml.vision.DEPENDENCIES" android:value="ocr" /> <!-- To use multiple models: android:value="ocr,model2,model3" --> </application>
完成项目配置后,需要设置输入值。 ML Kit适用于FirebaseVisionImage类型,我们有五种方法,我在下面写出了它们的签名。 他们将常用的Android和Java类型转换为ML Kit的类型,使用起来很方便。
fun fromMediaImage(image: Image, rotation: Int): FirebaseVisionImage fun fromBitmap(bitmap: Bitmap): FirebaseVisionImage fun fromFilePath(context: Context, uri: Uri): FirebaseVisionImage fun fromByteBuffer( byteBuffer: ByteBuffer, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage fun fromByteArray( bytes: ByteArray, metadata: FirebaseVisionImageMetadata ): FirebaseVisionImage
注意最后两个-它们使用字节数组和字节缓冲区,并且我们需要指定元数据,以便ML Kit理解如何处理所有这些。 实际上,元数据描述了格式,在这种情况下为宽度和高度,默认格式,IMAGE_FORMAT_NV21和旋转。
val metadata = FirebaseVisionImageMetadata.Builder() .setWidth(480) .setHeight(360) .setFormat(FirebaseVisionImageMetadata.IMAGE_FORMAT_NV21) .setRotation(rotation) .build() val image = FirebaseVisionImage.fromByteBuffer(buffer, metadata)
收集输入数据后,创建一个可识别文本的检测器。
设备和云中有两种类型的检测器,它们实际上是在一行中创建的。 值得注意的是,设备上的检测器只能使用英语。 云探测器支持20多种语言;必须在特殊的setLanguageHints方法中指定它们。
支持的语言数量超过20种,它们都在官方网站上。 在我们的示例中,仅英语和俄语。
输入和检测器后,只需在此检测器上调用processImage方法。 我们以任务的形式获得结果,在该任务上我们挂了两个回调-成功和错误。 标准表达式出现错误,并且onSuccessListener使FirebaseVisionText类型成功。
val result: Task<FirebaseVisionText> = detector.processImage(image) .addOnSuccessListener { result: FirebaseVisionText ->
如何使用FirebaseVisionText类型?
它由文本块(TextBlock)组成,文本块又由线(Line)和元素线(Element)组成。 它们彼此嵌套。
此外,这些类中的每一个都有五个方法,这些方法返回有关对象的不同数据。 矩形是文本所在的区域,可信度是所识别文本的准确性,角点是顺时针的角点,从左上角开始,从所识别的语言和文本本身开始。
FirebaseVisionText contains a list of FirebaseVisionText.TextBlock which contains a list of FirebaseVisionText.Line which is composed of a list of FirebaseVisionText.Element. fun getBoundingBox(): Rect
这是为了什么
我们既可以识别图片中的整个文本,也可以识别其单独的段落,片段,线条或单词。 作为示例,我们可以遍历每个阶段,获取一个文本,获取该文本的边框,然后绘制。 很舒服
我们计划在我们的应用程序中使用此工具来识别银行卡,这些卡上的标签是非标准的。 并非所有的卡片识别库都能很好地工作,对于自定义卡片,ML Kit将非常有用。 由于文本很少,因此以这种方式处理非常容易。
识别照片中的物体
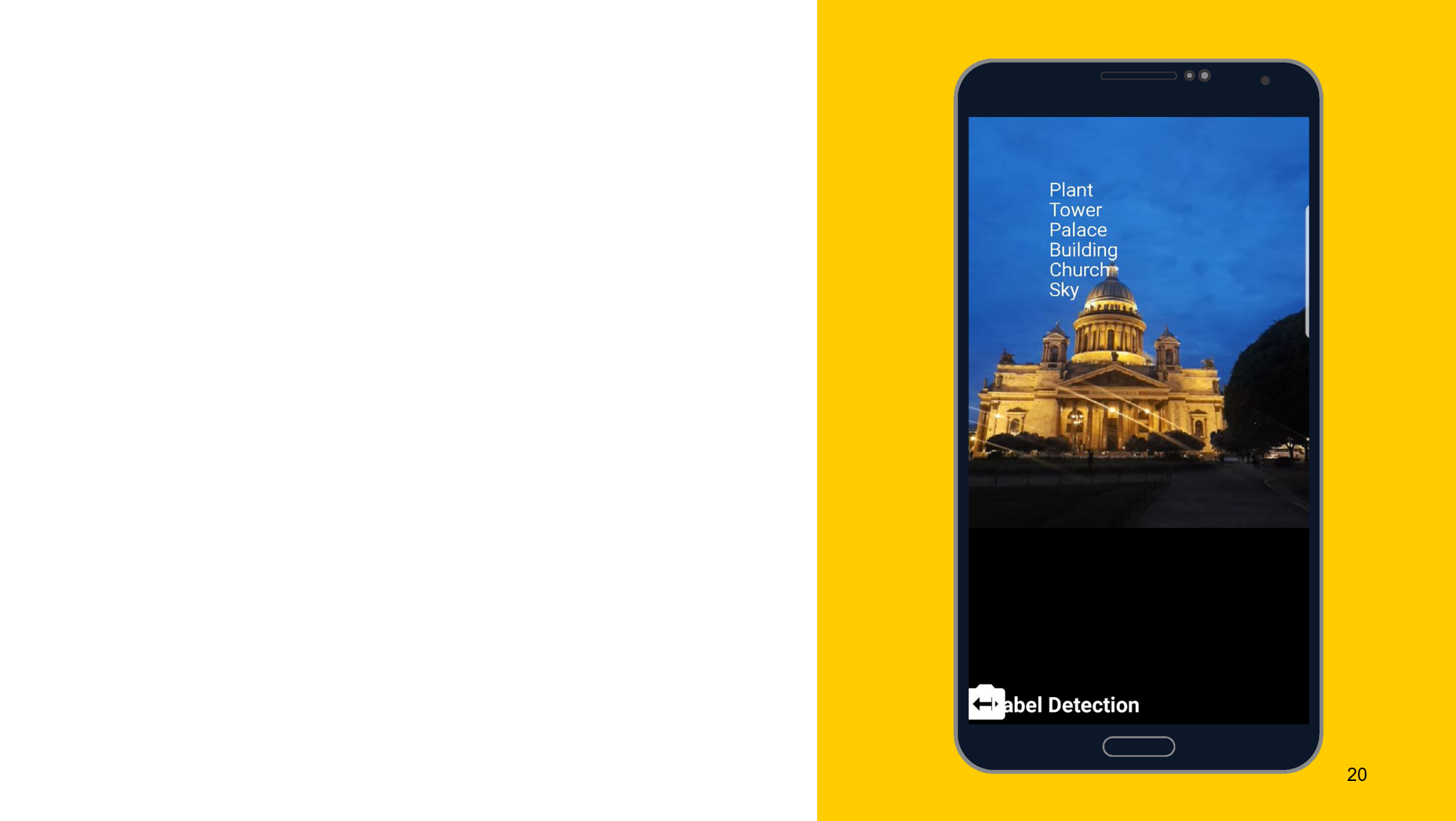
以下面的工具为例,我想证明操作原理大致相同。 在这种情况下,识别对象上所描绘的内容。 我们还创建了两个检测器,一个在设备上,另一个在云上,我们可以指定最低精度作为参数。 默认值为0.5,表示为0.7,可以开始使用了。 我们还以FirebaseImageLabel的形式获得结果,这是标签的列表,每个标签包含一个ID,描述和准确性。
哈罗德躲藏幸福

您可以尝试了解Harold掩饰痛苦的程度以及他是否同时感到高兴。 我们使用面部识别工具,该工具除了可以识别面部特征外,还可以判断一个人的幸福程度。 事实证明,哈罗德感到满意的是93%。 或者他很好地掩盖了痛苦。

从容易到容易,但稍微复杂一些。 定制模型。
任务:对照片中所描绘的内容进行分类。
我拍了笔记本电脑的照片,发现了调制解调器,台式计算机和键盘。 听起来像是事实。 一千个分类器,他选了三个最能描述这张照片的分类器。

使用自定义模型时,我们还可以在设备上或通过云使用它们。
如果我们在云中工作,则需要转到Firebase控制台,“ ML工具包”选项卡,然后点击“自定义”,在这里我们可以将模型上传到TensorFlow Lite,因为ML Kit可以使用此分辨率的模型。 如果在设备上使用它,我们可以简单地将模型作为资产放入项目的任何部分。
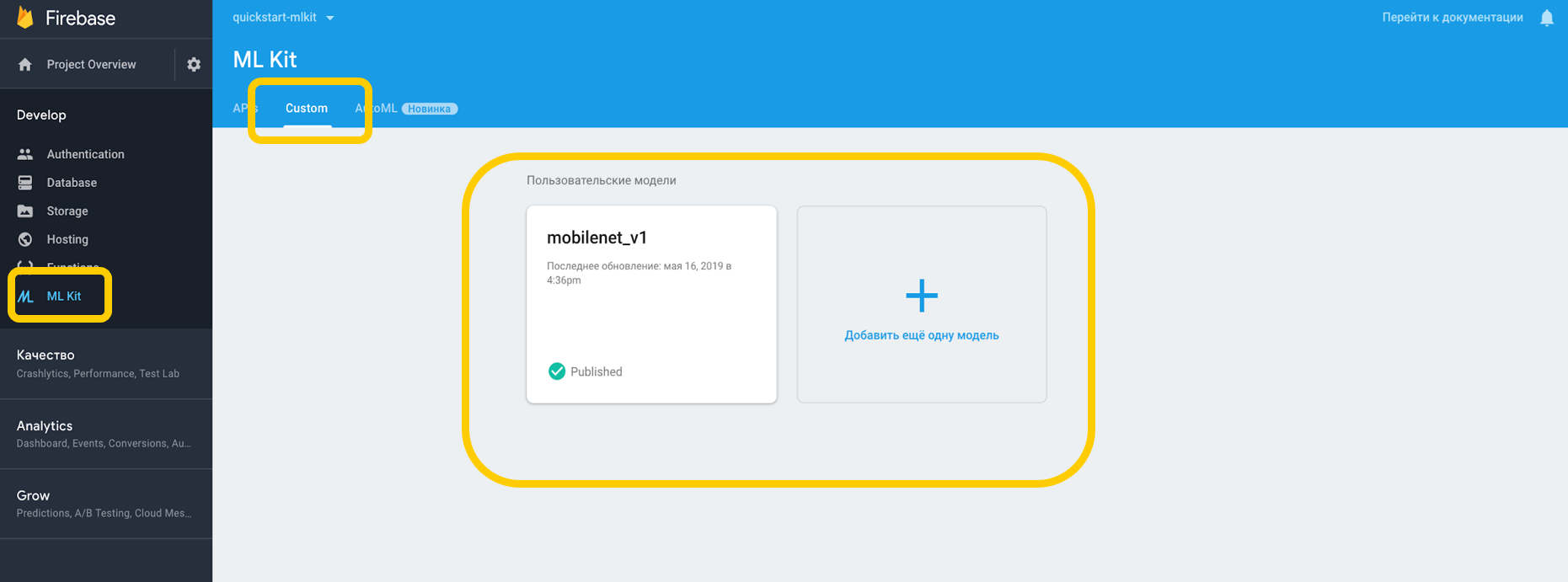
我们指出了对解释器的依赖,该解释器可以使用自定义模型,并且不要忘记使用Internet的许可。
<uses-permission android:name="android.permission.INTERNET" /> dependencies {
对于设备上的那些模型,您必须在Gradle中指示不应压缩该模型,因为它可能会变形。
android {
在环境中配置完所有内容后,我们必须设置特殊条件,例如,使用Wi-Fi,以及使用Android N时都需要充电,并且要求设备处于空闲状态-这些条件表明手机正在充电或处于待机模式。
var conditionsBuilder: FirebaseModelDownloadConditions.Builder = FirebaseModelDownloadConditions.Builder().requireWifi() if (Build.VERSION.SDK_INT >= Build.VERSION_CODES.N) {
当我们创建一个远程模型时,我们设置初始化和更新条件,以及标记是否应该更新我们的模型。 模型名称应与我们在Firebase控制台中指定的名称匹配。 创建远程模型时,必须在Firebase Model Manager中注册它。
val cloudSource: FirebaseRemoteModel = FirebaseRemoteModel.Builder("my_cloud_model") .enableModelUpdates(true) .setInitialDownloadConditions(conditions) .setUpdatesDownloadConditions(conditions) .build() FirebaseModelManager.getInstance().registerRemoteModel(cloudSource)
我们对本地模型执行相同的步骤,指定其名称,模型路径,然后在Firebase Model Manager中注册它。
val localSource: FirebaseLocalModel = FirebaseLocalModel.Builder("my_local_model") .setAssetFilePath("my_model.tflite") .build() FirebaseModelManager.getInstance().registerLocalModel(localSource)
之后,您需要创建这样的选项,在其中指定模型的名称,安装远程模型,安装本地模型并使用这些选项创建解释器。 我们可以指定一个远程模型,也可以仅指定一个本地模型,而解释器将自己理解要使用的模型。
val options: FirebaseModelOptions = FirebaseModelOptions.Builder() .setRemoteModelName("my_cloud_model") .setLocalModelName("my_local_model") .build() val interpreter = FirebaseModelInterpreter.getInstance(options)
ML Kit对自定义模型的输入和输出数据的格式一无所知,因此您需要指定它们。
输入数据是多维数组,其中1是图像数,224x224是分辨率,3是三通道RGB图像。 好吧,数据类型是字节。
val input = intArrayOf(1, 224, 224, 3)
输出值为1000个分类器。 我们使用指定的多维数组以字节为单位设置输入和输出值的格式。 除了字节外,还可以使用float,long,int。
现在我们设置输入值。 我们使用Bitmap,将其压缩为224 x 224,将其转换为ByteBuffer,然后使用FirebaseModelInput(使用特殊的构建器)创建输入值。
val bitmap = Bitmap.createScaledBitmap(yourInputImage, 224, 224, true) val imgData = convertBitmapToByteBuffer(bitmap) val inputs: FirebaseModelInputs = FirebaseModelInputs.Builder() .add(imageData) .build()
现在,当有了解释器时,输入和输出值的格式以及输入值本身,我们可以使用run方法执行请求。 我们将以上所有内容作为参数进行传输,结果得到FirebaseModelOutput,其中包含我们指定类型的泛型。 在这种情况下,它是一个Byte数组,之后我们可以开始处理。 这正是我们要求的千个分类器,例如,我们显示了最合适的前3个。
interpreter.run(inputs, inputOutputOptions) .addOnSuccessListener { result: FirebaseModelOutputs -> val labelProbArray = result.getOutput<Array<ByteArray>>(0)
一日实施
一切都很容易实现,并且内置工具可以在一天之内实现对对象的识别。 该工具在iOS和Android上可用,此外,您可以在两个平台上使用相同的TensorFlow模型。
此外,还有许多开箱即用的方法可以解决很多情况。 设备上提供了大多数API,也就是说,即使没有Internet,识别也将起作用。
最重要的是-支持可根据需要用于任何任务的自定义模型。
有用的链接
ML套件文档
Github ML套件演示项目
使用Firebase的移动机器学习(Google I / O'19)
适用于移动开发人员的机器学习SDK(Google I / O'18)
使用Firebase ML Kit(Medium.com)创建信用卡扫描仪