
在过去的几年中,时间序列数据库已经从一种奇怪的事物(高度专门于开放式监视系统(与特定解决方案相关联)或大数据项目)发展为一种“消费品”。 在俄罗斯联邦境内,应特别感谢Yandex和ClickHouse。 到现在为止,如果您需要保存大量的时序数据,则必须要么接受提出一个巨大的Hadoop堆栈并伴随它的需要,要么与每个系统特定的协议进行通信。
似乎在2019年,一篇有关应使用TSDB的文章仅包含一句话:“只使用ClickHouse”。 但是...有些细微差别。
确实,ClickHouse正在积极发展,用户群在不断增长,并且支持非常活跃,但是我们是否已成为ClickHouse在公众面前获得成功的人质,而这却使其他可能更有效/可靠的解决方案蒙上了阴影?
去年年初,我们开始处理自己的监视系统,在此期间出现了选择适当的数据存储库的问题。 我想在这里介绍这种选择的历史。
问题陈述
首先,必要的序言。 为什么我们需要我们自己的监控系统,它是如何安排的?
我们从2008年开始提供支持服务,到2010年,很明显,很难用当时存在的解决方案来汇总客户端基础结构中发生的流程的数据(我们正在谈论,上帝原谅我,仙人掌,Zabbix和新生。石墨)。
我们的主要要求是:
- 在同一系统内同时支持集中式警报管理系统(当时-数十个,将来-数百个)的客户;
- 灵活地管理警报系统(服务人员之间的警报升级,计划会计,知识库);
- 有可能对图形进行更详细的说明(当时的Zabbix是以图片的形式绘制图形);
- 长期存储大量数据(一年或更长时间)以及快速选择它们的能力。
在本文中,我们对最后一点感兴趣。
说到存储,要求如下:
- 系统应该可以快速运行;
- 期望系统具有SQL接口;
- 该系统必须稳定并且拥有活跃的用户群和支持(一旦我们面临着需要支持诸如我们停止开发的MemcacheDB或分布式存储MooseFS之类的系统的需求,该系统的Bugtracker用中文进行:为我们的项目重复此故事不想);
- 符合CAP定理:一致性(必要)-数据必须是相关的,我们不希望通知管理系统不接收新数据并且对所有项目的未到达数据发出警报; 分区容限(必要)-我们不想使用裂脑系统; 可用性(在活动副本的情况下并不重要)-发生事故时,我们可以使用代码自行切换到备份系统。
奇怪的是,那时MySQL是我们的理想解决方案。 我们的数据结构非常简单:服务器ID,计数器ID,时间戳和值; 快速的热数据采样由大型缓冲池提供,而历史数据采样由SSD提供。
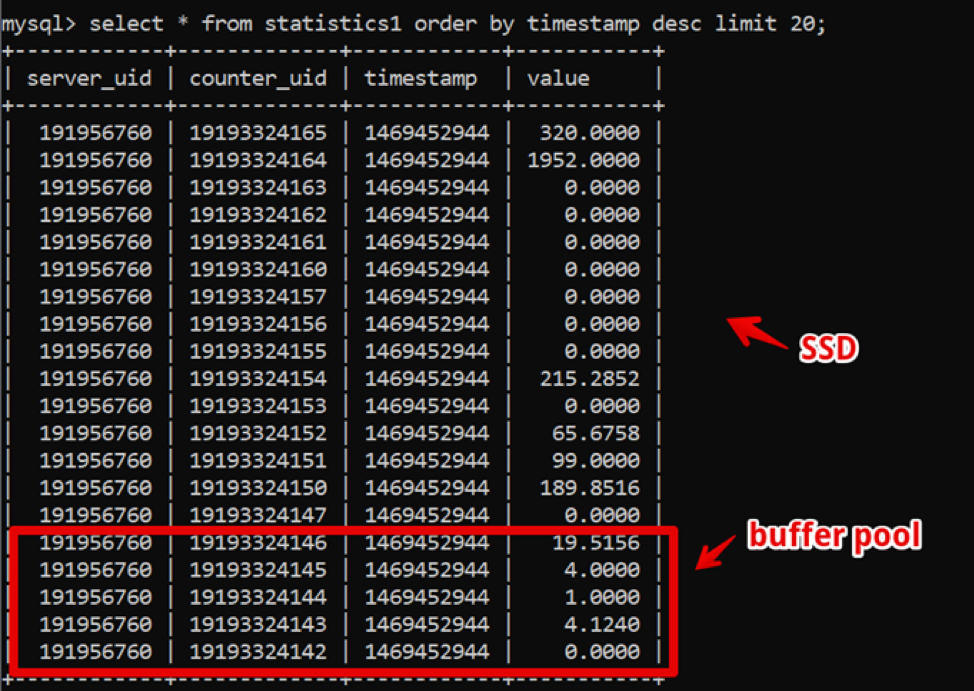
因此,我们获得了两周新数据的采样,并在数据完全渲染之前进行了长达200毫秒的细化,并在该系统中保留了相当长的时间。
同时,时间的流逝和数据量的增长。 到2016年,数据量达到数十TB,就租赁的SSD存储而言,这是一笔不小的支出。
在这一点上,柱状数据库正在积极传播,我们开始积极思考:在柱状数据库中,如您所知,数据存储在列中,如果您查看我们的数据,很容易发现可能如果使用列数据库,请压缩。
但是,公司工作的关键系统继续稳定运行,因此我不想尝试过渡到其他系统。
2017年,在圣何塞举行的Percona Live会议上,Clickhouse开发人员可能首次宣布自己。 乍一看,该系统已准备好投入生产(嗯,Yandex.Metrica是苛刻的生产),支持既快速又简单,最重要的是操作简单。 自2018年以来,我们已开始过渡过程。 但是到那时,已经有了许多经过成人和时间考验的TSDB系统,我们决定根据我们的要求分配大量的时间并比较替代方案,以确保没有替代的Clickhouse解决方案。
除了已经指出的存储要求之外,还出现了新的存储要求:
- 新系统应该在相同数量的铁上至少提供与MySQL相同的性能;
- 新系统的存储空间应大大减少;
- DBMS应该仍然易于管理;
- 我想在更改DBMS时最小化应用程序。
我们开始考虑什么系统
Apache Hive / Apache Impala破旧的Hadoop堆栈。 实际上,这是一个SQL接口,建立在HDFS上以本机格式存储数据的基础上。
优点
- 通过稳定的操作,非常容易缩放数据。
- 有用于数据存储(较少空间)的列解决方案。
- 在有资源的情况下非常快速地执行并行任务。
缺点
- 这是Hadoop,很难操作。 如果我们还没有准备好在云中采用现成的解决方案(并且我们还没有准备好承担费用),则整个堆栈都必须由管理员组装和支持,但是我真的不希望这样做。
- 数据聚合非常快 。
但是:

通过扩展计算服务器的数量来实现速度。 简而言之,如果我们是一家从事分析和业务的大公司,则至关重要的是尽快收集信息(即使以使用大量计算资源为代价)-这可能是我们的选择。 但是我们还没有准备好扩大铁库以加速任务。
德鲁伊/皮诺特别是有关TSDB的更多信息,但还是有关Hadoop堆栈的信息。
有一篇
很棒的文章比较了Druid和Pinot与ClickHouse的优缺点 。
简而言之:在以下情况下,德鲁伊/黑皮诺看起来比Clickhouse更好:
- 您的数据具有不同的性质(在我们的案例中,我们仅记录服务器指标的时间序列,实际上,这是一张表。但是可能还有其他情况:设备时间序列,经济时间序列等-每种都有自己的结构,必须进行汇总和处理)。
- 而且,这些数据很多。
- 具有时间序列的表和数据会出现和消失(也就是说,某种数据集进入后,将对其进行分析和删除)。
- 没有明确的标准可以划分数据。
在相反的情况下,ClickHouse显示得更好,这就是我们的情况。
Clickhouse它属于测试的候选清单。
InfluxdbClickHouse的外国替代品。 缺点:高可用性仅存在于商业版本中,但必须进行比较。
它属于测试的候选清单。
卡桑德拉一方面,我们知道它已被
SignalFX或OkMeter等监视系统用于存储度量标准时间序列。 但是,有一些细节。
通常,Cassandra不是列数据库。 它看起来更像是小写字母,但是每行可以具有不同数量的列,因此很容易组织列表示。 从这个意义上讲,很明显,由于限制为20亿列,您可以在列中存储一些数据(是的,相同的时间序列)。 例如,在MySQL中有4096列的限制,如果尝试执行相同的操作,很容易偶然发现代码1117的错误。
Cassandra引擎专注于在没有向导的情况下在分布式系统中存储大量数据,而在上述CAP定理中,Cassandra则更多地是关于AP,即关于数据可访问性和对分区的抵抗力。 因此,如果您只需要写入该数据库而很少读取该数据库,那么该工具将非常有用。 在这里,将Cassandra用作“冷”存储是合乎逻辑的。 即,作为存储大量历史数据的长期可靠场所,这些历史数据很少需要,但必要时可以获取。 尽管如此,出于完整性考虑,我们将对其进行测试。 但是,正如我之前所说,没有希望为选定的数据库解决方案主动重写代码,因此我们将对其进行一定程度的测试-而不使数据库结构适应于Cassandra的具体要求。
普罗米修斯好吧,出于兴趣,我们决定测试Prometheus商店的性能-只是为了了解我们是比当前解决方案快还是慢。
方法和测试结果
因此,我们在以下6种配置中测试了5个数据库:ClickHouse(1个节点),ClickHouse(3个节点的分布式表),InfluxDB,Mysql 8,Cassandra(3个节点)和Prometheus。 测试计划如下:
- 填写一周的历史数据(每天8.4亿个值; 20.8万个指标);
- 生成记录负载(考虑了6种负载模式,请参见下文);
- 在录制的同时,我们会定期制作样本,以模拟使用图表的用户的要求。 为了不使事情变得过于复杂,我们每周选择10个指标(在CPU图表上也是如此)来选择数据。
我们通过模拟监视代理程序的行为进行加载,该监视代理程序每15秒将值发送到每个指标。 在这种情况下,我们感兴趣的是:
- 数据写入的指标总数;
- 以一个度量标准发送值的间隔;
- 批量大小。
大约批量大小。 由于不建议将几乎所有的实验库都装入单个插入,因此我们将需要一个中继来收集传入的度量并将其尽可能地分组,并使用包插入将其写入数据库。
另外,为了更好地理解以后如何解释接收到的数据,可以想象我们不仅在发送大量指标,而且这些指标被组织到服务器中-每个服务器125个指标。 在这里,服务器只是一个虚拟实体-仅了解例如10,000个指标对应于大约80个服务器。
因此,考虑到所有这些,我们的基准的6种记录加载模式:
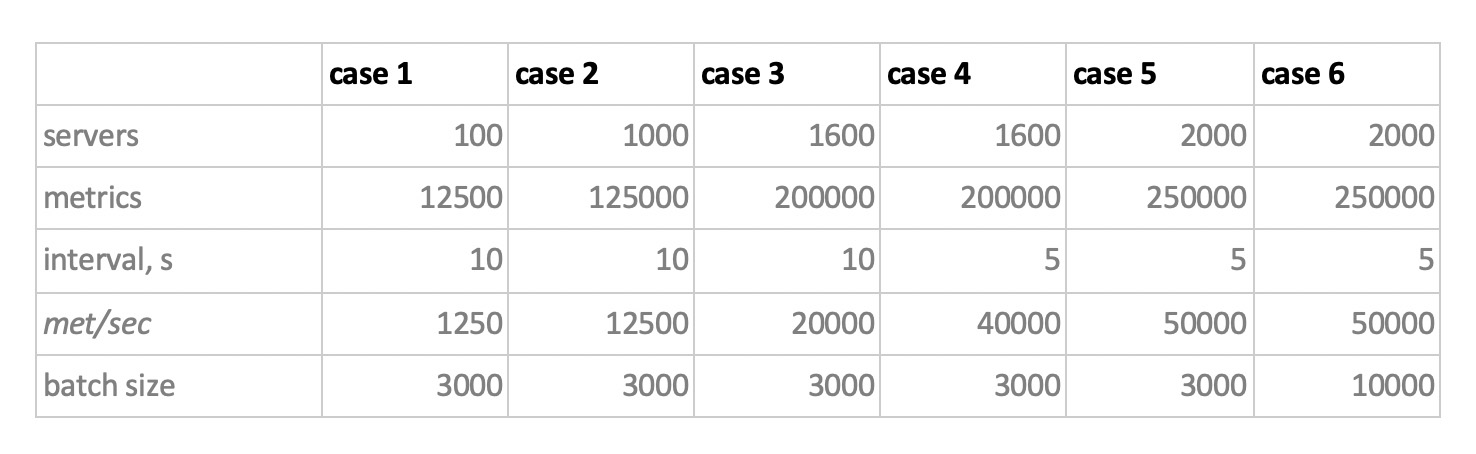
有两点。 首先,对于卡桑德拉来说,这样的批次大小太大,我们使用的值为50或100。其次,由于prometeus严格在拉动模式下工作,即 他步行并从度量标准源收集数据(甚至是pushgateway,尽管其名称没有从根本上改变情况),相应的负载是使用静态配置的组合来实现的。
测试结果如下:
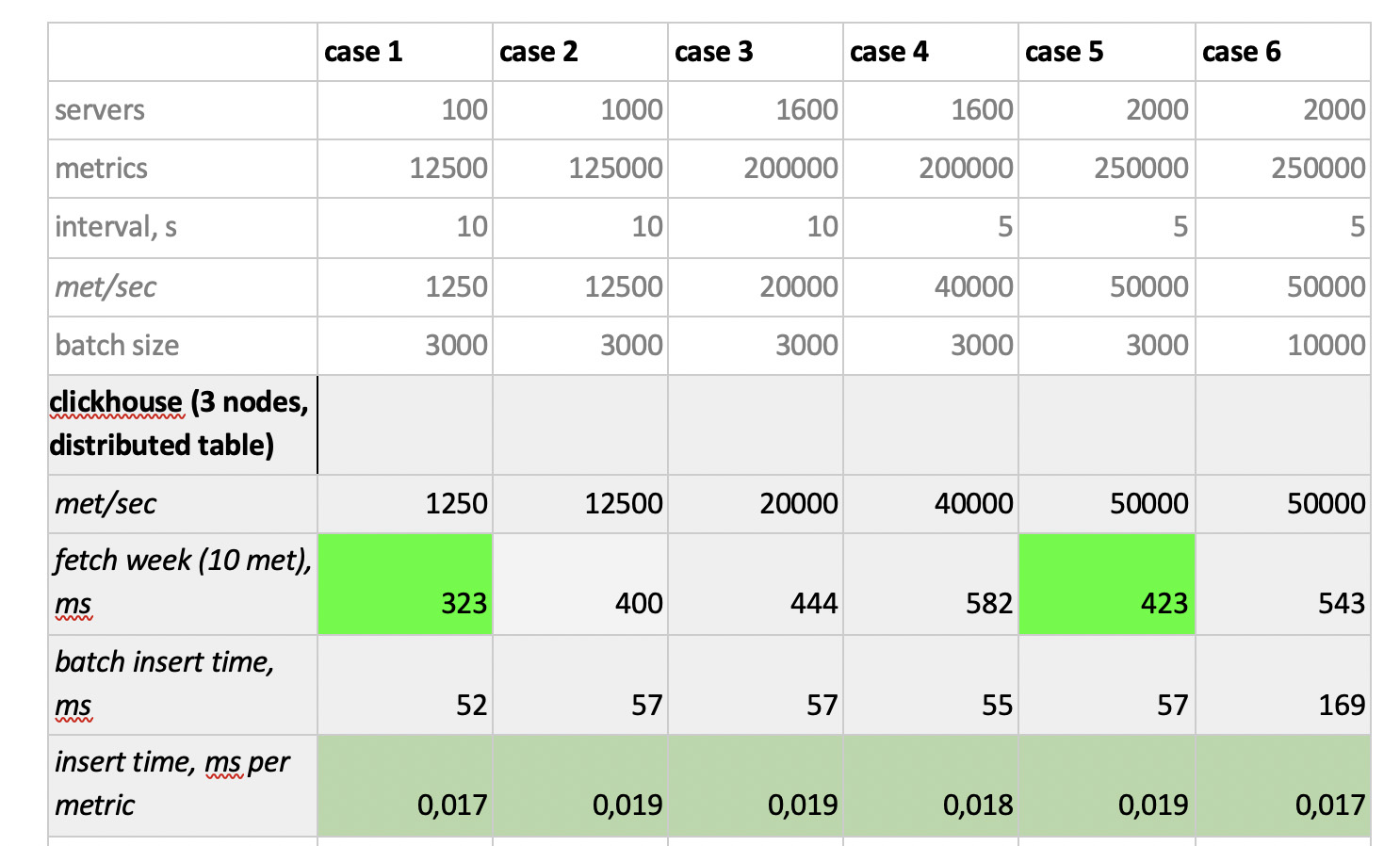
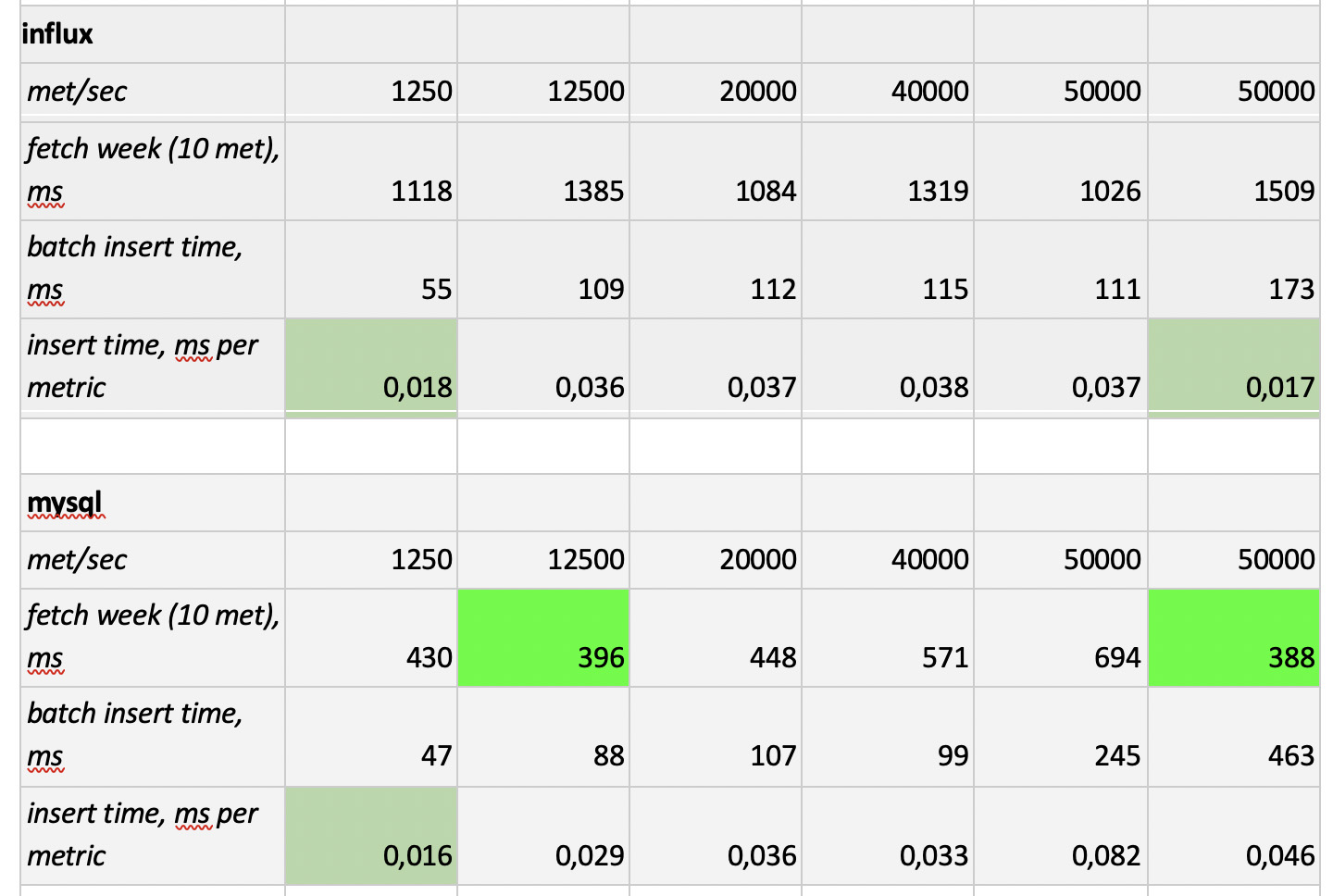
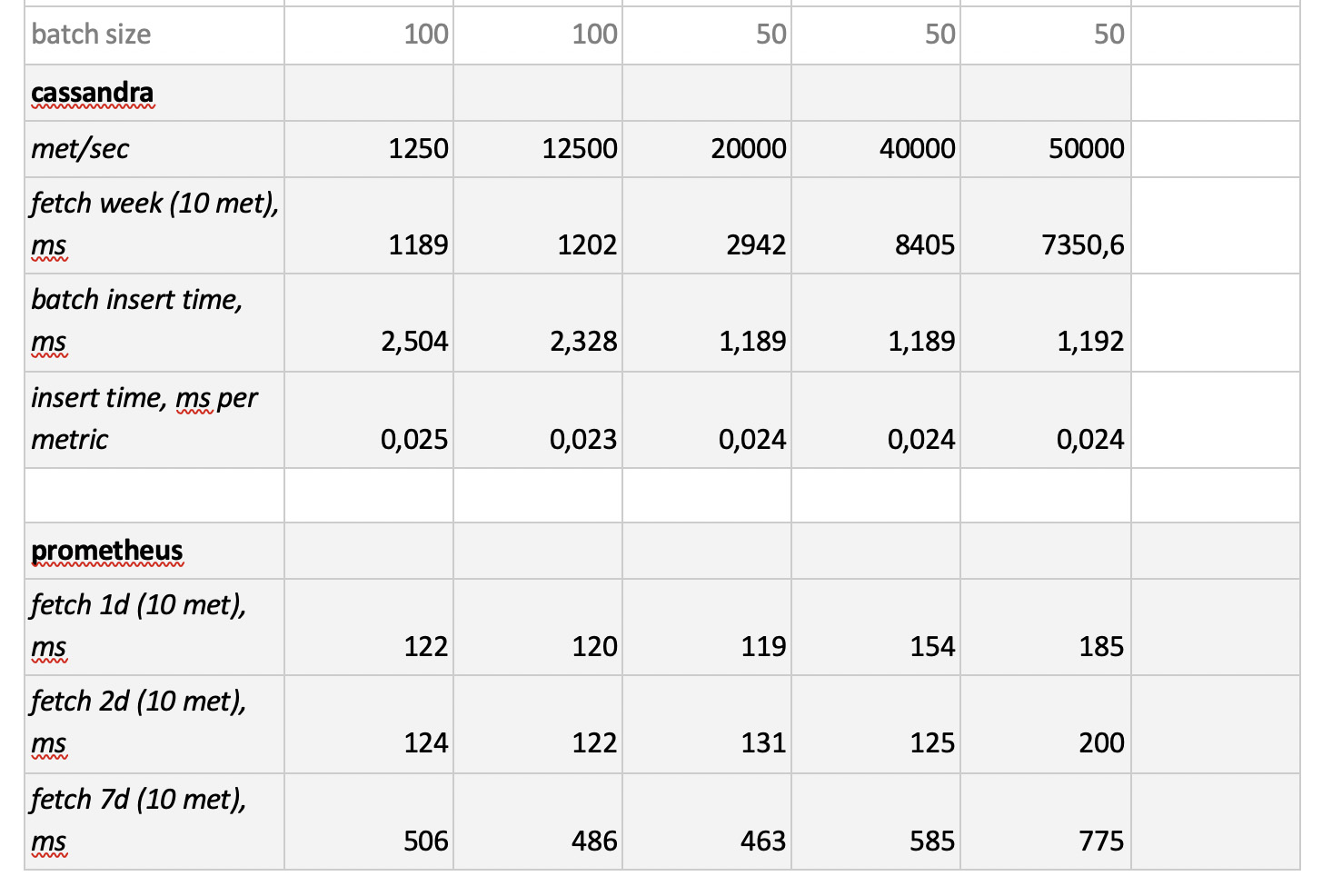 值得注意的是
值得注意的是 :Prometheus的采样速度非常快,Cassandra的采样速度非常慢,InfluxDB的采样速度令人无法接受。 ClickHouse在录制速度方面获胜,而Prometheus不参加比赛,因为它确实插入了自身,并且我们不进行任何测量。
结果 :ClickHouse和InfluxDB发挥了最大的优势,但是Influx的集群只能基于企业版构建,这需要花钱,而ClickHouse却不花钱,而且是俄罗斯制造的。 顺理成章的是,在美国,选择可能倾向于inInfluxDB,而在我们的情况下,则选择ClickHouse。