分析销售渠道是互联网营销(尤其是电子商务)的典型任务。 有了它的帮助,您可以:
- 找出您失去潜在客户的购买步骤。
- 在扩展购买路径的每个步骤的情况下,模拟额外收入流入的数量。
- 评估在各种广告平台上购买的流量的质量。
- 为每个经理评估处理传入应用程序的质量。
在本文中,我将讨论如何从Yandex Metrics Logs API请求R语言的数据,并基于它们构建和可视化渠道。
R语言的主要优点之一是存在大量扩展其基本功能的软件包。 在本文中,我们将介绍rym , funneljoin和ggplot2 。
使用rym我们从Logs API加载数据,使用funneljoin构建行为漏斗,并使用ggplot2可视化结果。

目录内容
从Logs API Yandex Metrics请求数据
谁不知道这里的Logs API是来自Yandex官方帮助的报价。
Logs API允许您接收Yandex.Metrica收集的非聚合数据。 该API适用于希望独立处理统计数据并使用它们来解决独特分析问题的服务用户。
要使用R中的Yandex.Metrica Logs API,我们将使用rym包。
rym -R软件包,它是用于与Yandex Metrica API进行交互的接口。 允许您使用Management API,Reporting API,符合Gore API的Google Analytics(分析)v3和Logs API 。
Rym软件包安装
要使用R中的任何软件包,必须首先安装和下载。 使用install.packages()命令安装一次软件包。 必须使用library()函数在R中的每个新工作会话中连接软件包。
要安装并连接rym软件包rym使用以下代码:
install.packages("rym") library(rym)
使用rym包使用Logs API Yandex Metrics
为了建立行为渠道,我们需要下载您网站上所有访问的表格,并准备数据以进行进一步分析。
Yandex Metrics API中的授权
使用API始于授权。 在rym软件包中rym授权过程是部分自动的,并且在调用其任何功能时开始。
首次访问API时,您将被重定向到浏览器,以确认访问rym软件包的Yandex指标的rym 。 确认后,您将被重定向到将为您生成授权确认代码的页面。 必须将其复制并粘贴到R控制台中,作为对"Enter authorize code:"请求的响应。
接下来,您可以通过对请求"Do you want save API credential in local file ..."回答y或yes ,将"Do you want save API credential in local file ..." 。 在这种情况下,在下一次调用API时,您将不需要通过浏览器重新进行身份验证,并且将从本地文件中加载凭据。
从Yandex Metrica API请求数据
我们从Yandex Metrics API询问的第一件事是可用计数器和已配置目标的列表。 这是使用rym_get_counters()和rym_get_goals()函数完成的。
# library(rym) # counters <- rym_get_counters(login = " ") # goals <- rym_get_goals("0000000", # login = " ")
使用上面的代码示例,用您的Yandex用户名替换" " ,在该名称下您可以使用所需的Yandex指标。 而"0000000"为您需要的计数器编号。 您可以在已加载的计数器表中看到可用的计数器编号。
可用计数器表- 计数器具有以下形式:
# A tibble: 2 x 9 id status owner_login name code_status site permission type gdpr_agreement_accepted <int> <fct> <fct> <fct> <fct> <fct> <fct> <fct> <int> 1 11111111 Active site.ru1 Aerosus CS_NOT_FOUND site.ru edit simple 0 2 00000000 Active site.ru Aerosus RU CS_OK site.ru edit simple 1
id字段显示所有可用的Yandex指标计数器的数量。
目标表如下:
# A tibble: 4 x 5 id name type is_retargeting conditions <int> <fct> <fct> <int> <fct> 1 47873638 url 0 type:contain, url:site.ru/checkout/cart/ 2 47873764 url 0 type:contain, url:site.ru/onestepcheckout/ 3 47874133 url 0 type:contain, url:/checkout/onepage/success 4 50646283 action 0 type:exact, url:click_phone
即 在我使用的计数器中,配置了以下操作:
将来,为了进行数据转换,我们将使用tidyverse库中包含的软件包: tidyr , dplyr 。 因此,在使用以下代码示例之前,请安装并连接这些软件包或整个tidyverse库。
# install.packages("tidyverse") # library(tidyverse) install.packages(c("dplyr", "tidyr")) library(dplyr) library(tidyr)
rym_get_logs()函数允许您从Yandex指标Logs API指标请求数据。
# logs <- rym_get_logs(counter = "0000000", date.from = "2019-04-01", date.to = "2019-06-30", fields = "ym:s:visitID, ym:s:clientID, ym:s:date, ym:s:goalsID, ym:s:lastTrafficSource, ym:s:isNewUser", login = " ") %>% mutate(ym.s.date = as.Date(ym.s.date), ym.s.clientID = as.character(ym.s.clientID))
rym_get_logs()函数的主要参数为:
- 计数器-您从中请求日志的计数器编号;
- date.from-开始日期;
- date.to-结束日期;
- 字段-您要加载的字段列表;
- login-Yandex登录,可以使用counter中指定的计数器 。
因此,我们从Logs API请求了访问数据,其中包含以下几列:
- ym:s:visitID-访问ID
- ym:s:clientID-网站上的用户ID
- ym:s:日期-访问日期
- ym:s:目标ID-此访问期间实现的目标的标识符
- ym:s:lastTrafficSource-流量来源
- ym:s:isNewUser-首次访问者
有关可用字段的完整列表,请参阅Logs API 帮助 。
接收到的数据足以使我们建立一个渠道,与此相关的是Logs API的工作已经完成,然后我们进入下一步-对下载数据进行后处理。
漏斗构建funneljoin包
本节提供的大部分信息可从funneljoin README包中获得,该包可通过参考获取 。
funneljoin目标是简化用户行为的渠道分析。 例如,您的任务是查找访问您的网站然后进行注册的用户,并找出从首次访问到注册之间经过了多少时间。 或者,您需要找到两天内查看过产品卡并将其添加到购物篮中的用户。 funneljoin软件包和after_join()函数有助于解决此类问题。
参数after_join() :
- x-一组数据,其中包含有关第一个事件(在第一个示例中,访问站点,在第二个中查看产品卡)的信息。
- y-包含有关第二个事件完成的信息的数据集(在第一个注册示例中,在第二个示例中,将产品添加到购物篮中)。
- by_time-包含有关表x和y中事件发生日期的信息的列。
- by_user-表x和y中具有用户标识的列。
- 模式-用于连接的方法:“内部”,“完整”,“反”,“半”,“右”,“左”。 相反,您也可以使用
after_mode_join (例如,用after_inner_join代替after_join (..., mode = "inner") )。 - type-用于定义事件对的序列的类型,例如“ first-first”,“ last-first”,“ any-firstafter”。 在“渠道类型”部分中介绍了更多详细信息。
- max_gap / min_gap(可选)-按第一事件和第二事件之间的最大和最小持续时间进行过滤。
- gap_col(可选)-是否返回事件之间具有时间差的数字式.gap列。 默认值为FALSE。
安装funneljoin
在撰写本文时, funneljoin软件包尚未在CRAN上发布,因此您可以从GitHub安装它。 要从GitHub安装软件包,您将需要一个附加的软件包devtools 。
install.packages("devtools") devtools::install_github("robinsones/funneljoin")
从Logs API接收的后处理数据
为了更详细地研究渠道构建功能,我们需要将从Logs API获得的数据转换为所需的形式。 如上所述,最方便的数据处理方式是tidyr和dplyr 。
首先,请执行以下操作:
- 在这种情况下, 日志表的一行包含有关一次访问的信息,而ym.s.goalsID列是
[0,1,0,...]格式的数组,其中包含在此访问期间实现的目标的标识符。 为了使数组具有适合进一步工作的形式,有必要从中删除多余的字符,在本例中为方括号。 - 有必要重新设置表格的格式,以便一行包含有关访问期间实现的一个目标的信息。 即 如果在一次访问中实现了三个目标,则此访问将分为三行,并且ym.s.goalsID列中的每一行将仅包含一个目标的标识符。
- 将带有目标列表的表附加到日志表中,以准确了解每次访问期间实现了哪些目标。
- 将具有目标名称的名称列重命名为events 。
以上所有操作都是使用以下代码实现的:
从Logs API接收的数据的后处理代码 # logs_goals <- logs %>% mutate(ym.s.goalsID = str_replace_all(ym.s.goalsID, # "\\[|\\]", "") %>% str_split(",")) %>% # unnest(cols = c(ym.s.goalsID)) %>% mutate(ym.s.goalsID = as.integer(ym.s.goalsID)) %>% # id left_join(goals, by = c("ym.s.goalsID" = "id")) %>% # rename(events = name) # events
对代码的小解释。 %>%运算符称为管道,使代码更易读和紧凑。 实际上,它采用执行一个函数的结果,并将其作为第一个参数传递给下一个函数。 因此,获得了一种传送带,它使您不会因存储中间结果的多余变量而阻塞RAM。
str_replace_all函数删除ym.s.goalsID列中的方括号。 str_split将ym.s.goalsID列中的目标标识符拆分为单独的值,并且unnest将它们拆分为单独的行,从而复制所有其他列的值。
使用mutate我们将目标标识符转换为整数类型。
left_join 目标表left_join到结果,该表存储有关已配置目标的信息。 使用当前表中的ym.s.goalsID列和目标表中的id列作为键。
最后, rename函数将名称列rename命名为events 。
现在, logs_goals表具有进一步工作所需的外观 。
接下来,创建三个新表:
- first_visits-所有新用户的第一次会话的日期
- 购物车-将产品添加到购物篮的日期
- 订单-订单
表创建代码 # first_visits <- logs_goals %>% filter(ym.s.isNewUser == 1 ) %>% # select(ym.s.clientID, # clientID ym.s.date) # date # cart <- logs_goals %>% filter(events == " ") %>% select(ym.s.clientID, ym.s.date) # orders <- logs_goals %>% filter(events == " ") %>% select(ym.s.clientID, ym.s.date)
每个新表都是对在最后一步中获得的主logs_goals表进行过滤的结果。 过滤是通过filter功能执行的。
要构建渠道,对于我们而言 , 只需在新表中保留有关用户ID和事件日期的信息即可,这些信息存储在ym.s.clientID和ym.s.date列中。 使用select功能选择所需的列。
渠道类型
type参数接受first , last , any和lastbefore与first , last , any和firstafter any firstafter 。 以下是可以使用的最有用组合的示例:
first-first :获取每个用户最早的x和y事件。 例如,我们要获取首次访问的日期和首次购买的日期,在这种情况下,请使用漏斗类型first-first 。
# first-first first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "first-first")
# A tibble: 42 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1552251706539589249 2019-04-18 2019-05-15 2 1554193975665391000 2019-04-02 2019-04-15 3 1554317571426012455 2019-04-03 2019-04-04 4 15544716161033564779 2019-04-05 2019-04-08 5 1554648729526295287 2019-04-07 2019-04-11 6 1554722099539384487 2019-04-08 2019-04-17 7 1554723388680198551 2019-04-08 2019-04-08 8 15547828551024398507 2019-04-09 2019-05-13 9 1554866701619747784 2019-04-10 2019-04-10 10 1554914125524519624 2019-04-10 2019-04-10 # ... with 32 more rows
我们得到一个表,其中有1行包含有关用户首次访问该网站的日期以及其第一次订购日期的数据。
first-firstafter :获取最早的x ,然后第一个y在第一个x之后 。 例如,某个用户反复访问您的网站,在访问过程中,他将产品添加到购物篮中,如果您需要获取将第一个产品添加到购物篮中的日期以及最接近该订单的订单日期,请使用first-firstafter漏斗类型。
cart %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "first-firstafter")
# A tibble: 49 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-02 2019-04-05 2 1552251706539589249 2019-05-15 2019-05-15 3 1552997205196001429 2019-05-23 2019-05-23 4 1553261825377658768 2019-04-11 2019-04-11 5 1553541720631103579 2019-04-04 2019-04-05 6 1553761108775329787 2019-04-16 2019-04-16 7 1553828761648236553 2019-04-03 2019-04-03 8 1554193975665391000 2019-04-13 2019-04-15 9 1554317571426012455 2019-04-04 2019-04-04 10 15544716161033564779 2019-04-08 2019-04-08 # ... with 39 more rows
lastbefore-firstafter :第一个x,然后是y,然后是下一个x 。 例如,用户重复访问了您的网站,其中一些会话以购买结束。 如果您需要在购买之前获取上次会话的日期及其后的购买日期,请使用渠道类型lastbefore-firstafter 。
first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "lastbefore-firstafter")
# A tibble: 50 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-05 2019-04-05 2 1552251706539589249 2019-05-15 2019-05-15 3 1552251706539589249 2019-05-16 2019-05-16 4 1552997205196001429 2019-05-23 2019-05-23 5 1553261825377658768 2019-04-11 2019-04-11 6 1553541720631103579 2019-04-05 2019-04-05 7 1553761108775329787 2019-04-16 2019-04-16 8 1553828761648236553 2019-04-03 2019-04-03 9 1554193975665391000 2019-04-15 2019-04-15 10 1554317571426012455 2019-04-04 2019-04-04 # ... with 40 more rows
在这种情况下,我们收到了一张表格,其中一行包含每笔订单完成前最后一种产品被添加到购物篮中的日期以及订单本身的日期。
any-firstafter :获得所有x和其后的第一个y 。 例如,一个用户重复访问了您的站点,在每次访问期间,他都向购物篮中添加了各种产品,并定期向所有添加的产品下订单。 如果您需要获取所有添加到购物篮中的商品的日期以及订购日期,请使用漏斗类型any-firstafter 。
cart %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "any-firstafter")
# A tibble: 239 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1551433754595068897 2019-04-02 2019-04-05 2 1551433754595068897 2019-04-02 2019-04-05 3 1551433754595068897 2019-04-03 2019-04-05 4 1551433754595068897 2019-04-03 2019-04-05 5 1551433754595068897 2019-04-03 2019-04-05 6 1551433754595068897 2019-04-05 2019-04-05 7 1551433754595068897 2019-04-05 2019-04-05 8 1551433754595068897 2019-04-05 2019-04-05 9 1551433754595068897 2019-04-05 2019-04-05 10 1551433754595068897 2019-04-05 2019-04-05 # ... with 229 more rows
- any-any:将所有x和所有y放在每个x旁边。 例如,您希望接收到该网站的所有访问的列表,其中包括每个用户的所有后续订单。
first_visits %>% after_inner_join(orders, by_user = "ym.s.clientID", by_time = "ym.s.date", type = "any-any")
# A tibble: 122 x 3 ym.s.clientID ym.s.date.x ym.s.date.y <chr> <date> <date> 1 1552251706539589249 2019-04-18 2019-05-15 2 1552251706539589249 2019-04-18 2019-05-15 3 1552251706539589249 2019-04-18 2019-05-15 4 1552251706539589249 2019-04-18 2019-05-16 5 1554193975665391000 2019-04-02 2019-04-15 6 1554193975665391000 2019-04-02 2019-04-25 7 1554317571426012455 2019-04-03 2019-04-04 8 15544716161033564779 2019-04-05 2019-04-08 9 1554648729526295287 2019-04-07 2019-04-11 10 1554722099539384487 2019-04-08 2019-04-17 # ... with 112 more rows
程序步骤
上面的示例演示了使用after_inner_join()函数,在所有事件都由单独的表分隔开的情况下(在我们的情况下,根据first_visits , cart和orders表after_inner_join() ,使用它很方便。
但是Logs API可以为您提供有关一个表中所有事件的信息,并且funnel_start()和funnel_step()函数将是创建一系列操作的更便捷方法。 funnel_start帮助设置渠道的第一步,并采用五个参数:
- tbl-事件表;
- moment_type-渠道中的第一个事件;
- moment-包含事件名称的列的名称;
- tstamp-带有事件发生日期的列的名称;
- user-带有用户标识符的列的名称。
logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID")
# A tibble: 52 x 2 ym.s.clientID `ym.s.date_ ` <chr> <date> 1 1556018960123772801 2019-04-24 2 1561216372134023321 2019-06-22 3 1556955573636389438 2019-05-04 4 1559220890220134879 2019-05-30 5 1553261825377658768 2019-04-11 6 1561823182372545402 2019-06-29 7 1556047887455246275 2019-04-23 8 1554722099539384487 2019-04-17 9 1555420652241964245 2019-04-17 10 1553541720631103579 2019-04-05 # ... with 42 more rows
funnel_start返回一个包含ym.s.clientI和ym.s.date_列的表ym.s.date_ (列名称以及日期,_和事件名称)。
可以使用funnel_step()函数添加以下步骤。 在funnel_start我们已经指定了所有必需列的标识符,现在我们需要使用moment_type参数指定哪个事件将是漏斗中的下一步 ,并且连接类型是type (例如"first-first" , "first-any" )。
logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_step(moment_type = " ", type = "first-last")
# A tibble: 319 x 3 ym.s.clientID `ym.s.date_ ` `ym.s.date_ ` <chr> <date> <date> 1 1550828847886891355 2019-04-01 NA 2 1551901759770098825 2019-04-01 NA 3 1553595703262002507 2019-04-01 NA 4 1553856088331234886 2019-04-01 NA 5 1554044683888242311 2019-04-01 NA 6 1554095525459102609 2019-04-01 NA 7 1554100987632346537 2019-04-01 NA 8 1551433754595068897 2019-04-02 2019-04-05 9 1553627918798485452 2019-04-02 NA 10 155418104743178061 2019-04-02 NA # ... with 309 more rows
使用funnel_step您可以使用任意数量的步骤来构建渠道。 在我的示例中,要为每个用户构建一个完整的渠道,您可以使用以下代码:
用于为每个用户构建完整渠道的代码 # # events - " " logs_goals <- logs_goals %>% filter(ym.s.isNewUser == 1 ) %>% mutate(events = " ") %>% bind_rows(logs_goals) # logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_step(moment_type = " ", type = "first-last") %>% funnel_step(moment_type = " ", type = "first-last") %>% funnel_step(moment_type = " ", type = "first-last")
现在,蛋糕上的樱桃是summarize_funnel() 。 该功能可让您显示从上一步切换到下一个步骤的用户百分比,以及从第一步切换到下一个步骤的用户百分比。
my_funnel <- logs_goals %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_steps(moment_type = c(" ", " ", " "), type = "first-last") %>% summarize_funnel()
# A tibble: 4 x 4 moment_type nb_step pct_cumulative pct_step <fct> <dbl> <dbl> <dbl> 1 18637 1 NA 2 1589 0.0853 0.0853 3 689 0.0494 0.579 4 34 0.0370 0.749
nb_step — , , pct_cumulative — , pct_step — .
my_funnel , ggplot2 .
ggplot2 — R, . , , .
ggplot2 , 2005 . , photoshop, , .
# install.packages("ggplot2") library(ggplot2) my_funnel %>% mutate(padding = (sum(my_funnel$nb_step) - nb_step) / 2) %>% gather(key = "variable", value = "val", -moment_type) %>% filter(variable %in% c("nb_step", "padding")) %>% arrange(desc(variable)) %>% mutate(moment_type = factor(moment_type, levels = c(" ", " ", " ", " "))) %>% ggplot( aes(x = moment_type) ) + geom_bar(aes(y = val, fill = variable), stat='identity', position='stack') + scale_fill_manual(values = c('coral', NA) ) + geom_text(data = my_funnel, aes(y = sum(my_funnel$nb_step) / 2, label = paste(round(round(pct_cumulative * 100,2)), '%')), colour='tomato4', fontface = "bold") + coord_flip() + theme(legend.position = 'none') + labs(x='moment', y='volume')
:
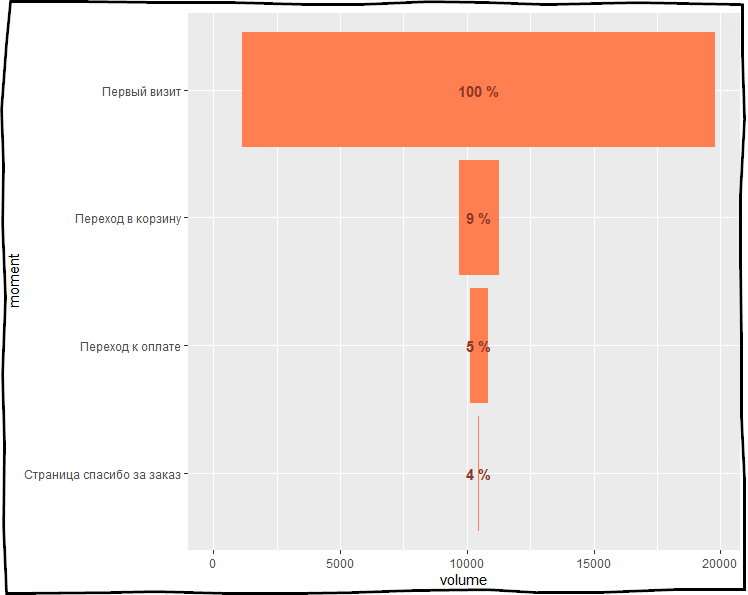
.
- my_funnel .
ggplot — , , , X moment_type .geom_bar — — , aes .scale_fill_manual — , , .geom_text — , % .coord_flip — , .theme — : , .. .labs — .
, , , , .
lapply , R. , , bind_rows .
# first_visits <- rename(first_visits, firstSource = ym.s.lastTrafficSource) # logs_goals <- select(first_visits, ym.s.clientID, firstSource) %>% left_join(logs_goals, ., by = "ym.s.clientID") # my_multi_funnel <- lapply(c("ad", "organic", "direct"), function(source) { logs_goals %>% filter(firstSource == source) %>% select(events, ym.s.clientID, ym.s.date) %>% funnel_start(moment_type = " ", moment = "events", tstamp = "ym.s.date", user = "ym.s.clientID") %>% funnel_steps(moment_type = c(" ", " ", " "), type = "first-last") %>% summarize_funnel() %>% mutate(firstSource = source) }) %>% bind_rows() #
# A tibble: 12 x 5 moment_type nb_step pct_cumulative pct_step firstSource <fct> <int> <dbl> <dbl> <chr> 1 14392 1 NA ad 2 154 0.0107 0.0107 ad 3 63 0.00438 0.409 ad 4 14 0.000973 0.222 ad 5 3372 1 NA organic 6 68 0.0202 0.0202 organic 7 37 0.0110 0.544 organic 8 13 0.00386 0.351 organic 9 607 1 NA direct 10 49 0.0807 0.0807 direct 11 21 0.0346 0.429 direct 12 8 0.0132 0.381 direct
my_multi_funnel , .
# my_multi_funnel %>% mutate(padding = ( 1 - pct_cumulative) / 2 ) %>% gather(key = "variable", value = "val", -moment_type, -firstSource) %>% filter(variable %in% c("pct_cumulative", "padding")) %>% arrange(desc(variable)) %>% mutate(moment_type = factor(moment_type, levels = c(" ", " ", " ", " ")), variable = factor(variable, levels = c("pct_cumulative", "padding"))) %>% ggplot( aes(x = moment_type) ) + geom_bar(aes(y = val, fill = variable), stat='identity', position='stack') + scale_fill_manual(values = c('coral', NA) ) + geom_text(data = my_multi_funnel_df, aes(y = 1 / 2, label =paste(round(round(pct_cumulative * 100, 2)), '%')), colour='tomato4', fontface = "bold") + coord_flip() + theme(legend.position = 'none') + labs(x='moment', y='volume') + facet_grid(. ~ firstSource)
:

?
first_visits ym.s.lastTrafficSource firstSource .left_join ym.s.clientID . firstSource .lapply ad, organic direct. bind_rows .facet_grid(. ~ firstSource) , firstSource .
聚苯乙烯
. PS , R. R4marketing , R .
:
结论
, , R :
- .;
- R RStudio;
rym , funneljoin ggplot2 ;rym rym_get_logs() .;funneljoin .ggplot2 .
, Logs API , : CRM, 1 . , : , -.