您认为用Python编写支持对话的聊天机器人很困难吗? 如果您找到一个好的数据集,那就很容易了。 而且,尽管仍然需要一些数学魔术,但即使没有神经网络也可以做到这一点。
我们将分几个步骤进行:首先,记住如何将数据加载到Python中,然后学习计算单词数,逐步连接线性代数和定理器,最后,我们使用所产生的聊天算法为Telegram打造一个机器人。
本教程适合那些已经接触过Python但对机器学习不是特别熟悉的人。 我故意不使用任何nlp-sh库来显示可以在裸sklearn上组装的东西。
在对话框数据集中搜索答案
一年前,我被要求向那些以前没有从事数据分析的人展示一些可以自己构建的鼓舞人心的机器学习应用程序。 我试图带一个机器人聊天程序,我们真的在一个晚上做到了。 我们喜欢这个过程和结果,并在
我的博客上写了有关它。 现在我认为Habru会很有趣。
所以我们开始。 我们的任务是创建一种算法,为任何短语提供适当的答案。 例如,关于“你好吗?” 回答“优秀,你呢?”。 实现此目的的最简单方法是找到现成的问题和答案数据库。 例如,从大量电影中获取字幕。
但是,我将更加作弊,并从
Yandex.Algorithm 2018竞赛中获取数据-这些与电影中的对话相同,Toloka员工在这些对话中标出了好坏。 Yandex收集了这些数据来训练Alice(她的胆量
1、2、3上的文章)。 实际上,当我想到这个机器人时,我受到了爱丽丝的启发。
Yandex的
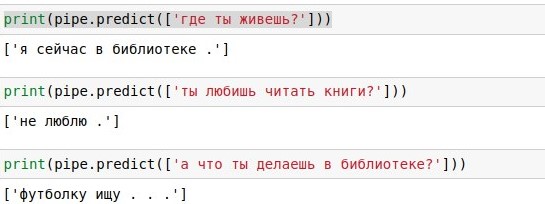
表格显示了最后三个短语及其答案(答复),但我们仅使用最新的短语(context_0)。
有了这样一个对话框数据库,您可以在其中轻松搜索用户的每个副本,并在其上给出现成的答案(如果有很多这样的副本,请随机选择)。 和“你好吗?” 如随附的屏幕截图所示,结果非常好。 这是Python 3中的
jupyter笔记本 (如果有的话)。如果您想自己重复一遍,最简单的方法是安装
Anaconda-它包含Python和大量有用的软件包。 或者,您无法安装任何东西,只能
在Google云中运行笔记本。

逐字搜索的问题是覆盖范围低。 用短语“你好吗?” 在4万个答案的数据库中,尽管具有相同的含义,但没有完全匹配的结果。 因此,在下一部分中,我们将使用不同的数学方法补充代码以实现近似搜索。 在此之前,您可以阅读有关
pandas库的信息,并弄清楚上面代码的6行中的每一行都有什么作用。
文字向量化
现在我们正在讨论如何将文本转换为数值向量,以便对其进行近似搜索。
我们已经在Python中遇到了pandas库-它允许您加载表,在其中搜索等。 现在,让我们接触
scikit-learn (sklearn)库,该库允许进行更复杂的数据操作-所谓的机器学习。 这意味着任何算法都必须首先显示数据(拟合),以便它学习有关数据的重要信息。 结果,该算法“学习”对该数据进行有用的处理-对其进行转换(转换),甚至预测未知值(预测)。
在这种情况下,我们希望将文本(“问题”)转换为数值向量。 这是必要的,以便可以使用距离的数学概念来找到彼此“接近”的文本。 勾股定理可以计算出两点之间的距离-作为其坐标差平方和的根。 在数学中,这称为欧几里得度量。 如果我们可以将文本转换为具有坐标的对象,则可以计算欧几里得度量,例如,在数据库中找到最类似于“您在想什么”的问题。
指定文本坐标的最简单方法是对语言中的所有单词进行编号,并说文本的第i个坐标等于其中第i个单词的出现次数。 例如,对于文本“我忍不住哭泣”,单词“ not”的坐标为2,单词“ I”,“ can”和“ cry”的坐标为1,所有其他单词(成千上万)的坐标为0。会丢失有关字序的信息,但效果仍然不错。
问题在于,对于经常找到的单词(例如,粒子“和”和“ a”),坐标虽然会携带很少的信息,却会成比例地过大。 为了缓解此问题,可以将每个单词的坐标除以出现该单词的文本数量的对数-这称为tf-idf,并且效果很好。

只有一个问题:在我们的6万个文本“问题”数据库中,其中包含1.4万个不同的单词。 如果将所有问题转换为向量,则将得到60k * 14k的矩阵。 配合使用它不是很酷,因此我们稍后将讨论缩小尺寸。
尺寸缩小
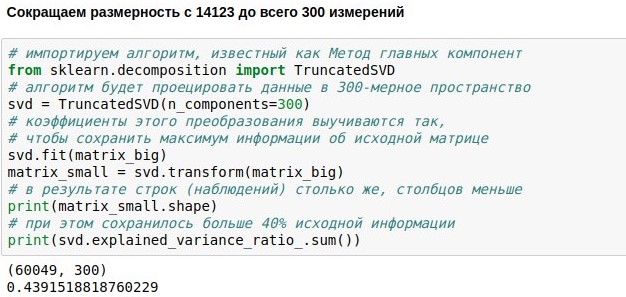
我们已经设定了创建聊天聊天机器人,下载和矢量化数据进行培训的任务。 现在,我们有了一个表示用户副本的数值矩阵。 它由6万行(对话框数据库中有很多副本)和14000列(其中有很多不同的单词)组成。 现在我们的任务是使其更小。 例如,不是将每个文本呈现为14123维,而是仅呈现300维向量。
这可以通过将尺寸为60049x14123的矩阵乘以一个特殊选择的尺寸为14123x300的投影矩阵来实现,结果得到结果60049x300。 PCA算法(
主成分法 )选择投影矩阵,以便可以以最小的标准误差重建原始矩阵。 在我们的案例中,尽管尺寸减小了近50倍,但仍可以保留原始矩阵的44%。
是什么使得这种有效的压缩成为可能? 回想一下,原始矩阵包含用于提及文本中各个单词的计数器。 但是,通常来说,单词不是彼此独立地使用,而是在上下文中使用。 例如,新闻文本中出现“阻塞”一词的次数越多,在文本中出现“电报”一词的可能性就越大。 但是,单词“ blocking”与单词“ caftan”的相关性是负的-它们存在于不同的上下文中。
因此,事实证明,主要成分的方法不会记住所有的1.4万个单词,而是会记住300个典型上下文,然后可以尝试恢复这些单词。 投影矩阵对应于同义单词的列通常彼此相似,因为这些单词通常在同一上下文中找到。 这意味着可以减少冗余测量而不会丢失信息量。
在许多现代应用中,单词投影矩阵是通过神经网络(例如
word2vec )来计算的。 但是实际上,简单的线性代数已经足够获得实用的结果。 主成分的方法在计算上被简化为SVD,它将用于计算矩阵的特征向量和特征值。 但是,可以在不知道详细信息的情况下进行编程。
搜索附近的邻居
在前面的部分中,我们将对话框上载到python,对其进行了矢量化处理并缩小了尺寸,现在,我们希望最终学习如何在300维空间中搜索最近的邻居,并最终有意义地回答问题。
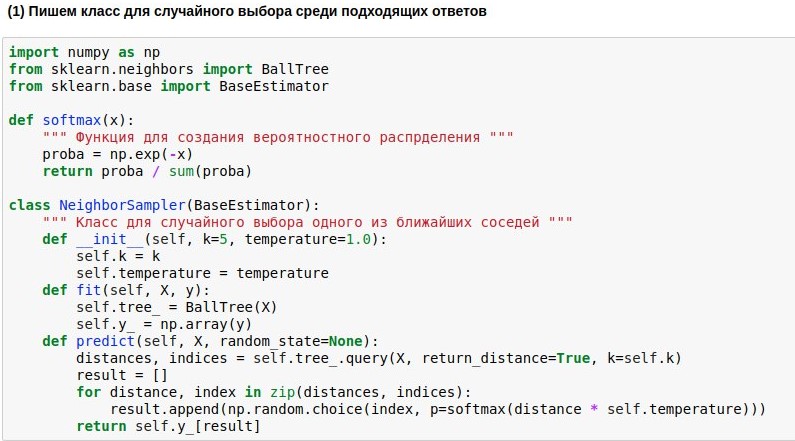
由于我们学会了如何将问题映射到维数不是很高的欧几里得空间,因此可以很快地在其中寻找邻居。 我们将使用现成的
BallTree邻居搜索算法。 但是,我们将编写包装模型,该模型将选择k个最近的邻居中的一个,并且邻居越近,选择他的可能性就越高。 总是选择最亲近的邻居是无聊的,但完全不被束缚是很危险的。
因此,我们希望将查询到参考文本的找到的距离转换为选择这些文本的概率。 为此,您可以使用softmax函数,该函数通常仍然位于神经网络的出口。 她将自己的论点转化为一组非负数,它们的总和为1-正是我们所需要的。 此外,我们可以将获得的“概率”用于答案的随机选择。
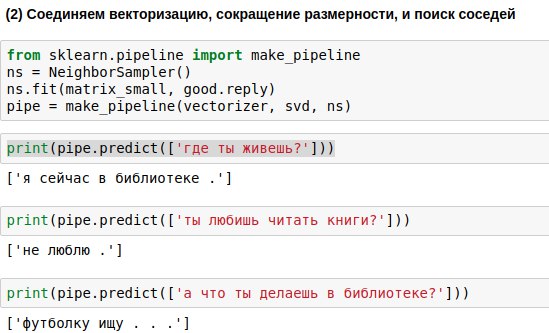
用户将输入的短语必须通过所有三种算法传递-矢量化器,主成分法和响应选择算法。 要编写更少的代码,您可以将它们链接到一个链(管道)中,并依次应用算法。
结果,我们得到了一种算法,该算法可以根据用户的问题找到与其相似的问题并给出答案。 有时,这些答案甚至听起来几乎是有意义的。
在Telegram上发布机器人
我们已经想出了如何创建一个聊天机器人聊天室,该聊天室将为用户请求提供大致相关的答案。 现在,我向您展示如何在Telegram上发布这样的聊天机器人。
使用此功能最简单的方法是为python准备好的包装器Telegram API,例如
pytelegrambotapi 。 因此,分步说明:
- 使用@botfather注册您将来的机器人,并获取访问令牌,您需要将其插入代码中。
- 一次运行安装命令-在命令行上pip install pytelegrambotapi(或通过!直接在记事本中)。
- 像截图一样运行代码。 该单元将进入执行模式(*),并且在此模式下,您可以根据需要与您的机器人进行尽可能多的通信。 要停止漫游器,请按Ctrl +C。 令人难过但很重要的事实:如果您在俄罗斯,那么很可能在启动此单元之前,需要打开VPN以便在连接电报时不会出错。 VPN的一种更简单的替代方法是将所有代码(而不是在本地计算机上)写在google colab中( 类似这样 )。
- 如果您希望该机器人永久运行,则需要将其代码放在某些云服务上,例如AWS,Heroku,now.sh或Yandex.Cloud。 您可以在这些服务的站点上或Habré上的文章中以最小的详细信息了解如何运行它们。 例如,一个萝卜,上面有一个小机器人的例子,该机器人在heroku上运行并将日志记录在mongodb中。
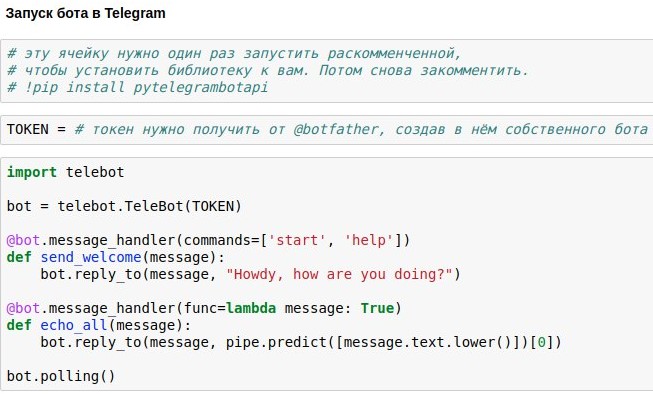
我特意不上传本文的完整代码-自己打印并通过自己的努力得到一个运行正常的机器人,您将获得更多的乐趣和有益的经验。 好吧,或者如果您懒得这样做,可以与
我的机器人
版本聊天。