现代信息系统非常复杂。 最后但并非最不重要的一点是,它们的复杂性归因于其中处理的数据的复杂性。 数据的复杂性通常在于所使用的各种数据模型。 因此,例如,当数据变“大”时,不便特征之一不仅被视为其体积(“ volume”),还被视为其多样性(“ variety”)。
如果您仍然没有发现推理上的缺陷,请继续阅读。

多语言持久性
前面的事实导致有时甚至在一个系统的框架内,也有必要使用几个不同的DBMS来存储数据并解决各种处理任务,每个任务都支持自己的数据模型。 在M. Fowler (许多著名书籍的作者,也是《敏捷宣言》的合著者之一)的帮助下 ,这种情况被称为多变量存储 (“多语言持久性”)。
Fowler还拥有以下在电子商务领域中功能齐全且负载较高的应用程序中组织数据存储的示例。

当然,此示例有些夸张,但是例如在这里 ,可以找到一些有利于出于相应目的选择一个或另一个DBMS的注意事项。
显然,在这样的动物园里当部长并不容易。
- 执行数据存储的代码量与使用的DBMS数量成正比。 如果与该数字的平方不成比例,则用于同步数据的代码量就不错。
- 使用的DBMS数量的倍数增加了为每个使用的DBMS提供企业特征(可伸缩性,容错性,高可用性)的成本。
- 不可能提供整个存储子系统的企业特征-尤其是事务性的。
从动物园负责人的角度来看,一切看起来像这样:
- DBMS制造商的许可和技术支持成本成倍增加。
- 员工肿,交货时间更长。
- 由于数据不一致而造成的直接财务损失或罚款。
系统的总拥有成本(TCO)大大增加。 有什么办法可以摆脱“多元存储”的局面吗?
多模型
“多元存储”一词于2011年开始使用。 意识到这种方法存在的问题以及寻找解决方案的过程花费了数年时间,到2015年,答案由Gartner分析师口中得出:
似乎这次Gartner的分析师并没有误解这一预测。 如果转到DB-Engines上具有主要 DBMS 评级的页面,则可以看到其大多数领导者都将自己定位为多模型DBMS。 在具有任何私人评级的页面上也可以看到相同的内容。
下表显示了DBMS-每个私人评级中的领导者,宣布了其多模型。 对于每个DBMS,都会显示最初支持的模型(只有一个),并指出当前支持的模型。 根据创建者的说法,也有一些DBMS将自己定位为“初始多模型”,它们没有任何初始继承的模型。
此外,对于每个类,我们将展示该类如何实现DBMS中几个模型的支持。 我们将考虑最重要的关系,文档和图形模型,并通过特定DBMS的示例显示“缺失”是如何实现的。
基于关系模型的多模型DBMS
领先的DBMS当前是关系型的;如果RDBMS未显示向多模型的方向移动,则不能认为Gartner预测是正确的。 他们展示了。 现在,多模型DBMS就像一把瑞士刀一样的想法,做得不好,可以立即发送给Larry Ellison。
但是,作者喜欢Microsoft SQL Server中的多模型实现,在该示例中将描述RDBMS对文档和图形模型的支持。
MS SQL Server中的文档模型
关于MS SQL Server如何支持文档模型,有关Habré的文章已经有两篇了,我将只限于简短的重述和评论:
对于关系型DBMS,在MS SQL Server中支持文档模型的方法非常典型:建议将JSON文档存储在纯文本字段中。 文档模型支持是为了提供特殊的运算符来解析此JSON:
这两个运算符的第二个参数是类似JSONPath语法的表达式。
可以抽象地说,与元组不同,以这种方式存储的文档不是关系DBMS中的“一流实体”。 具体来说,MS SQL Server当前在JSON文档的字段上没有索引,这使得很难通过这些字段的值来联接表,甚至很难通过这些值来选择文档。 但是,可以在此字段中创建一个可计算列和一个索引。
另外,MS SQL Server提供了使用FOR JSON PATH语句从表的内容方便地构造JSON文档的功能,从某种意义上说,此功能与以前的普通存储相反。 显然,无论RDBMS有多快,这种方法都与文档DBMS的思想相矛盾,事实上,文档DBMS可以存储对流行查询的现成答案,并且只能解决易于开发的问题,而不能解决速度问题。
最后,MS SQL Server允许您解决问题,这与文档设计相反:您可以使用OPENJSON将JSON分解为表。 如果文档不是完全平坦,则需要使用CROSS APPLY 。
MS SQL Server中的图形模型
在Microsoft SQL Server中实现的图形( LPG )模型的支持也是可以预见的 :建议使用特殊的表来存储节点和存储图边。 分别使用表达式CREATE TABLE AS NODE和CREATE TABLE AS EDGE创建此类表。
第一种类型的表类似于用于存储记录的普通表,唯一的不同是表包含系统字段$node_id数据库中唯一的图形节点标识符。
类似地,第二种类型的表具有系统字段$from_id和$to_id ,此类表中的记录清楚地定义了节点之间的关系。 单独的表用于存储每种类型的关系。
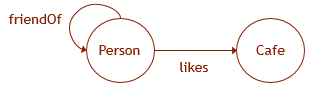 我们举例说明。 让图形数据具有如图所示的方案。 然后,要在数据库中创建相应的结构,您需要执行以下DDL查询:
我们举例说明。 让图形数据具有如图所示的方案。 然后,要在数据库中创建相应的结构,您需要执行以下DDL查询:
CREATE TABLE Person ( ID INTEGER NOT NULL, name VARCHAR(100) ) AS NODE; CREATE TABLE Cafe ( ID INTEGER NOT NULL, name VARCHAR(100), ) AS NODE; CREATE TABLE likes ( rating INTEGER ) AS EDGE; CREATE TABLE friendOf AS EDGE;
此类表的主要特点是可以在查询中使用具有Cypher式语法的图形模式(但是尚不支持“ * ”等)。 另外,基于性能测量,可以假定在这些表中存储数据的方法与在普通表中存储数据的机制不同,并且可以优化为执行这种图形查询。
SELECT Cafe.name FROM Person, likes, Cafe WHERE MATCH (Person-(friendOf)-(likes)->Cafe) AND Person.name = 'John';
此外,在处理此类表时不使用这些图形模式非常困难,因为在普通的SQL查询中,为了解决类似的问题,将需要$node_id更多的努力才能获得系统的“图形”节点标识符( $node_id , $from_id , $to_id ;为此出于同样的原因,这里也不给出数据插入请求,因为它太麻烦了。
总结一下MS SQL Server中文档和图形模型的实现的描述,我会注意到,这种模型在另一模型之上的实现似乎主要在语言设计方面似乎并不成功。 需要将一种语言扩展为另一种语言,语言不是完全“正交”的,兼容性规则可能很奇怪。
基于文档模型的多模型DBMS
在本节中,我将以不是最流行的MongoDB示例为例,说明文档DBMS中多模型的实现(正如所说的,它仅包含有条件的图运算符$lookup和$graphLookup ,它们不适用于分片集合),但是在该示例中,它更为成熟,并且“企业»DBMS MarkLogic 。
因此,让集合包含以下格式的XML文档集(MarkLogic也允许存储JSON文档):
<Person INN="631803299804"> <name>John</name> <surname>Smith</surname> </Person>
MarkLogic的关系模型
可以使用显示模板创建文档集合的关系表示(以下示例中的value元素的内容可以是任意XPath):
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <rows> <row> <view-name>Person</view-name> <columns> <column> <name>SSN</name> <value>@SSN</value> <type>string</type> </column> <column> <name>name</name> <value>name</value> </column> <column> <name>surname</name> <value>surname</value> </column> </columns> </row> <rows> </template>
可以将SQL查询寻址到创建的视图(例如,通过ODBC):
SELECT name, surname FROM Person WHERE name="John"
不幸的是,使用显示模板创建的关系视图是只读的。 在处理请求时,MarkLogic将尝试使用文档索引 。 在MarkLogic中,过去只有有限的关系视图完全基于索引并且可写,但是现在认为它们已被弃用。
MarkLogic中的图模型
有了图( RDF )模型支持,事情几乎是一样的。 同样,使用显示模板,您可以从上面的示例创建文档集合的RDF表示形式:
<template xmlns="http://marklogic.com/xdmp/tde"> <context>/Person</context> <vars> <var> <name>PREFIX</name> <val>"http://example.org/example#"</val> </var> </vars> <triples> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || surname )</value></predicate> <object><value>xs:string( surname )</value></object> </triple> <triple> <subject><value>sem:iri( $PREFIX || @SSN )</value></subject> <predicate><value>sem:iri( $PREFIX || name )</value></predicate> <object><value>xs:string( name )</value></object> </triple> </triples> </template>
可以使用SPARQL查询来解决生成的RDF图:
PREFIX : <http://example.org/example
与关系式不同,MarkLogic图模型以其他两种方式支持:
- DBMS可以是RDF数据的完整独立存储库(与上面提取的摘录相反,其中的三元组称为托管 )。
- 可以将特殊序列化的RDF轻松插入XML或JSON文档中(然后将三元组称为unmanaged )。 这可能是
idref机制等的替代方法。
Optic API很好地说明了MarkLogic中所有内容如何“真正”起作用,尽管它的目的恰恰相反,但它的目的却是相反的-尝试从所使用的数据模型中抽象出来,以确保与不同模型,事务性和公关
多模型DBMS“没有主模型”
DBMS也可以在市场上买到,将自己定位为最初的多模型,没有任何继承的基本模型。 其中包括ArangoDB , OrientDB (自2018年起,开发公司属于SAP)和CosmosDB (Microsoft Azure云平台中包含的服务)。
实际上,ArangoDB和OrientDB中存在“基本”模型。 在这两种情况下,这些都是专有数据模型,是文档概括。 概括主要是为了促进产生图和关系查询的能力。
这些模型是唯一可用于指示的DBMS的模型;它们自己的查询语言旨在与它们一起使用。 当然,这样的模型和DBMS很有希望,但是与标准模型和语言的兼容性不足使得无法在遗留系统中使用这些DBMS-用它们已经使用的DBMS替换它们。
关于Habré上的ArangoDB和OrientDB,已经有一篇很棒的文章: NoSQL数据库中的JOIN 。
Arangodb
ArangoDB声称支持图形数据模型。
ArangoDB中的图节点是普通文档,边是特殊类型的文档,这些文档具有常见的系统字段( _key , _id , _rev )以及系统字段_from和_to 。 传统上,文档DBMS中的文档会合并到集合中。 表示边缘的文档集合在ArangoDB中称为边缘集合。 顺便说一下,边缘集合的文档也是文档,因此ArangoDB中的边缘也可以充当节点。
源数据假设我们有一组persons其文档如下所示:
[ { "_id" : "people/alice" , "_key" : "alice" , "name" : "" }, { "_id" : "people/bob" , "_key" : "bob" , "name" : "" } ]
让我们也有cafes的集合:
[ { "_id" : "cafes/jd" , "_key" : "jd" , "name" : " " }, { "_id" : "cafes/jj" , "_key" : "jj" , "name" : "-" } ]
然后likes集合可能如下所示:
[ { "_id" : "likes/1" , "_key" : "1" , "_from" : "persons/alice" , "_to" : "cafes/jd", "since" : 2010 }, { "_id" : "likes/2" , "_key" : "2" , "_from" : "persons/alice" , "_to" : "cafes/jj", "since" : 2011 } , { "_id" : "likes/3" , "_key" : "3" , "_from" : "persons/bob" , "_to" : "cafes/jd", "since" : 2012 } ]
查询和结果ArangoDB中使用的AQL中的一种图形样式查询,以人类可读的形式返回有关谁喜欢哪个咖啡馆的信息,如下所示:
FOR p IN persons FOR c IN OUTBOUND p likes RETURN { person : p.name , likes : c.name }
在一种关系样式中,当我们更有可能“计算”关系而不是存储它们时,可以按以下方式重写此查询(顺便说一句,您可以不用likes集合):
FOR p IN persons FOR l IN likes FILTER p._key == l._from FOR c IN cafes FILTER l._to == c._key RETURN { person : p.name , likes : c.name }
两种情况下的结果将相同:
[ { "person" : "" , likes : "-" } , { "person" : "" , likes : " " } , { "person" : "" , likes : " " } ]
更多查询和结果如果以上结果的格式似乎对于关系型DBMS比对文档型更为典型,则可以尝试以下查询(或者可以使用COLLECT ):
FOR p IN persons RETURN { person : p.name, likes : ( FOR c IN OUTBOUND p likes RETURN c.name ) }
结果如下:
[ { "person" : "" , likes : ["-" , " "] } , { "person" : "" , likes : [" "] } ]
东方
在OrientDB中,在文档模型之上的图形模型的实现基于文档字段具有或多或少的标准标量值之外还具有诸如LINK , LINKLIST , LINKSET , LINKMAP和LINKBAG之类的类型的值的LINKBAG 。 这些类型的值是指向系统文档标识符的链接或链接集合。
系统分配的文档标识符具有“物理意义”,指示记录在数据库中的位置,并且看起来像这样: @rid : #3:16 。 因此,引用属性的值实际上更可能是指针(如在图形模型中),而不是选择条件(如在关系模型中)。
与ArangoDB中一样,在OrientDB中,边表示为单独的文档(尽管如果边没有自己的属性,则可以将其设置为轻量级,并且单独的文档将不与之对应)。
源数据在接近OrientDB数据库转储格式的格式中 ,来自上一个示例的ArangoDB的数据看起来像这样:
[ { "@type": "document", "@rid": "#11:0", "@class": "Person", "name": "", "out_likes": [ "#30:1", "#30:2" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#12:0", "@class": "Person", "name": "", "out_likes": [ "#30:3" ], "@fieldTypes": "out_likes=LINKBAG" }, { "@type": "document", "@rid": "#21:0", "@class": "Cafe", "name": "-", "in_likes": [ "#30:2", "#30:3" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#22:0", "@class": "Cafe", "name": " ", "in_likes": [ "#30:1" ], "@fieldTypes": "in_likes=LINKBAG" }, { "@type": "document", "@rid": "#30:1", "@class": "likes", "in": "#22:0", "out": "#11:0", "since": 1262286000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:2", "@class": "likes", "in": "#21:0", "out": "#11:0", "since": 1293822000000, "@fieldTypes": "in=LINK,out=LINK,since=date" }, { "@type": "document", "@rid": "#30:3", "@class": "likes", "in": "#21:0", "out": "#12:0", "since": 1325354400000, "@fieldTypes": "in=LINK,out=LINK,since=date" } ]
如我们所见,顶点还存储有关传入和传出边缘的信息。 使用 Document API时,您必须自己遵循参照完整性,而Graph API会注意这一点。 但是,让我们看看在未集成到编程语言和查询语言的“干净”状态下对OrientDB的调用是什么样的。
查询和结果一个与OrientDB中的ArangoDB示例中的查询目的类似的查询如下所示:
SELECT name AS person_name, OUT('likes').name AS cafe_name FROM Person UNWIND cafe_name
结果将获得如下:
[ { "person_name": "", "cafe_name": " " }, { "person_name": "", "cafe_name": "-" }, { "person_name": "", "cafe_name": "-" } ]
如果结果的格式再次显得过于“相关”,则需要使用UNWIND()删除该行:
[ { "person_name": "", "cafe_name": [ " ", "-" ] }, { "person_name": "", "cafe_name": [ "-" ' } ]
OrientDB查询语言可以描述为带有类似Gremlin的插入的SQL。 2.2版引入了类似Cypher的请求表MATCH :
MATCH {CLASS: Person, AS: person}-likes->{CLASS: Cafe, AS: cafe} RETURN person.name AS person_name, LIST(cafe.name) AS cafe_name GROUP BY person_name
结果的格式将与上一个查询中的相同。 与第一个查询一样,请考虑需要删除哪些内容以使其更具“关系性”。
Azure CosmosDB
在较小程度上,上述有关ArangoDB和OrientDB的内容指的是Azure CosmosDB。 CosmosDB提供以下数据访问API:SQL,MongoDB,Gremlin和Cassandra。
SQL API和MongoDB API用于访问文档模型中的数据。 Gremlin API和Cassandra API-分别用于访问图形和列中的数据。 所有模型中的数据均以CosmosDB内部模型: ARS (“ atom-record-sequence”)的格式保存,该模型也与文档之一很接近。

但是,在服务中创建帐户时,用户选择的数据模型和使用的API是固定的。 不可能以另一种模型的格式访问在一个模型中加载的数据,这将由以下示例说明:

因此,如今,Azure CosmosDB中的多模型只是使用支持同一制造商的不同模型的多个数据库的良机,这并不能解决多变量存储的所有问题。
基于图模型的多模型DBMS?
值得注意的是,市场上没有基于图形模型的多模型DBMS(除了同时支持两个图形模型(RDF和LPG)的多模型支持,请参见先前的出版物 )。 最大的困难是在文档图形模型之上的实现,而不是关系的实现。
即使在图形模型形成时,也考虑过如何在图形模型上实现关系模型的问题。 如David McGovern 所说 ,例如:
图方法没有内在的东西可以阻止在图数据库上创建一个层(例如,通过适当的索引),该层可以实现以下关系视图:(1)从常规键值对中恢复元组,以及(2)通过关系类型。
在图的顶部实现文档模型时,请记住以下几点:
- JSON数组的元素被认为是有序的,来自图边缘的顶部-否;
- 文档模型中的数据通常是非规范化的,您仍然不希望存储同一附件文档的多个副本,并且子文档通常没有标识符。
- 另一方面,文档DBMS的思想是文档是现成的“单元”,不需要每次都重新构建。 需要在图模型中提供快速获得与完成文档相对应的子图的能力。
一些广告本文的作者与NitrosBase DBMS的开发有关,该数据库的内部模型是图形的,而外部模型(关系和文档)是其表示。 所有模型都是平等的:使用自然的查询语言,几乎任何数据都可用。 而且,以任何表示形式,数据都可能发生变化。 更改将反映在内部模型中,并因此反映在其他表示中。
NitrosBase中的模型匹配是什么样子-希望在以下文章之一中进行描述。
结论
我希望对读者来说,所谓的“多模型化”的总体轮廓或多或少变得清晰。 完全不同的DBMS被称为多模型,并且“对多个模型的支持”看起来可能有所不同。 要了解每种情况下的“多模型”,回答以下问题很有用:
- 是支持传统模型还是单个混合模型?
- 模型是“相等的”还是其中一个受其他模型约束?
- 模型是否彼此“无动于衷”? 可以将一种模型中记录的数据以另一种模型读取甚至覆盖吗?
我认为已经有可能对多模型DBMS的相关性问题做出肯定的回答,但是有趣的问题是,在不久的将来,哪种类型的DBMS会有更多需求。 似乎支持传统模型(主要是关系模型)的多模型DBMS的需求将越来越大。 , , , — .