大家好 我们分享了本文最后一部分的翻译内容,该文章是专为
数据工程师课程的学生准备的。 第一部分可以在
这里找到。
用于实时管道的Apache Beam和DataFlow
Google Cloud设定
注意:我使用Google Cloud Shell启动管道并发布用户日志数据,因为在Python 3中运行管道时遇到问题。GoogleCloud Shell使用Python 2,它与Apache Beam更好地兼容。
要启动传送带,我们需要深入研究设置。 对于以前从未使用过GCP的用户,您必须在此
页面上完成以下6个步骤。
之后,我们需要将脚本上传到Google Cloud Storage,然后将其复制到Google Cloud Shel。 上传到云存储非常简单(可以在
此处找到说明)。 要复制文件,我们可以点击下面图2左侧的第一个图标,从工具栏中打开Google Cloud Shel。
 图2
图2下面列出了复制文件和安装必要的库所需的命令。
创建我们的数据库和表
完成所有配置步骤后,接下来需要做的是在BigQuery中创建数据集和表。 有几种方法可以做到这一点,但最简单的方法是先创建数据集来使用Google Cloud控制台。 您可以按照以下
链接中的步骤创建具有架构的表。 我们的表将有
7列对应于每个用户日志的组件。 为了方便起见,我们将所有列定义为字符串(类型字符串),但timelocal变量除外,并根据我们之前生成的变量命名它们。 该表的布局应类似于图3。
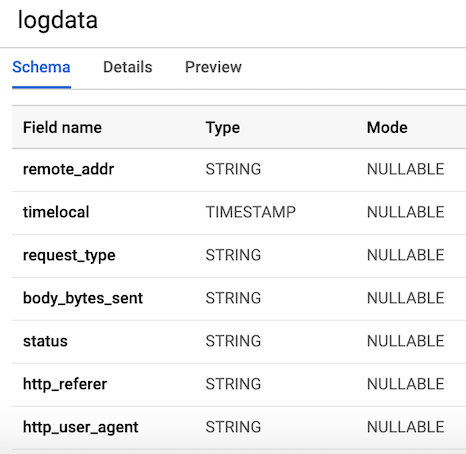 图3.表布局
图3.表布局发布用户日志数据
Pub / Sub是我们管道中的关键组件,因为它允许多个独立的应用程序相互交互。 特别是,它充当中介,使我们能够在应用程序之间发送和接收消息。 我们需要做的第一件事是创建一个主题。 只需转到控制台中的Pub / Sub,然后按CREATE TOPIC。
下面的代码调用我们的脚本来生成上面定义的日志数据,然后连接并将日志发送到Pub / Sub。 我们唯一需要做的就是创建一个
PublisherClient对象,使用
topic_path方法指定主题的路径,并使用
topic_path和data调用
publish函数。 请注意,我们从
stream_logs脚本中导入了
generate_log_line ,因此请确保这些文件位于同一文件夹中,否则您将收到导入错误。 然后,我们可以使用以下命令通过我们的Google控制台运行此命令:
python publish.py
from stream_logs import generate_log_line import logging from google.cloud import pubsub_v1 import random import time PROJECT_ID="user-logs-237110" TOPIC = "userlogs" publisher = pubsub_v1.PublisherClient() topic_path = publisher.topic_path(PROJECT_ID, TOPIC) def publish(publisher, topic, message): data = message.encode('utf-8') return publisher.publish(topic_path, data = data) def callback(message_future):
文件启动后,我们就可以观察到日志数据到控制台的输出,如下图所示。 该脚本将一直起作用,直到我们使用
CTRL + C来完成它为止。
 图4.
图4. publish_logs.py输出
为我们的管道编写代码
现在我们已经准备好一切,我们可以继续进行最有趣的部分-使用Beam和Python编写管道代码。 要创建Beam管道,我们需要创建管道对象(p)。 创建管道对象之后,可以使用
pipe (|)运算符一个接一个地应用几个函数。 通常,工作流程如下图所示。
[Final Output PCollection] = ([Initial Input PCollection] | [First Transform] | [Second Transform] | [Third Transform])
在我们的代码中,我们将创建两个用户定义的函数。
regex_clean函数,它使用
re.search函数扫描数据并根据
regex_clean列表检索相应的行。 该函数返回以逗号分隔的字符串。 如果您不是正则表达式专家,建议您阅读本
教程并在记事本中练习以检查代码。 之后,我们定义了一个名为
Split的自定义ParDo函数,该函数是Beam变换的并行处理形式。 在Python中,这是通过特殊方式完成的-我们必须创建一个继承自DoFn Beam类的类。 Split函数从前一个函数中获取一个已解析的字符串,并返回一个字典列表,其中包含与BigQuery表中的列名相对应的键。 此功能有一些值得注意的地方:我必须在该功能中导入
datetime才能使其正常工作。 我在文件开头收到导入错误,这很奇怪。 然后,此列表传递到
WriteToBigQuery函数,该函数将我们的数据简单地添加到表中。 批数据流作业和流数据流作业的代码如下所示。 批处理和流代码之间的唯一区别是,在批处理中,我们使用Beam的
ReadFromText函数从
src_path读取CSV。
批处理DataFlow作业(包处理)
import apache_beam as beam from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import bigquery import re import logging import sys PROJECT='user-logs-237110' schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' src_path = "user_log_fileC.txt" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'status': element[3], 'body_bytes_sent': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(): p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.textio.ReadFromText(src_path) | "clean address" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) p.run() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
流数据流作业
from apache_beam.options.pipeline_options import PipelineOptions from google.cloud import pubsub_v1 from google.cloud import bigquery import apache_beam as beam import logging import argparse import sys import re PROJECT="user-logs-237110" schema = 'remote_addr:STRING, timelocal:STRING, request_type:STRING, status:STRING, body_bytes_sent:STRING, http_referer:STRING, http_user_agent:STRING' TOPIC = "projects/user-logs-237110/topics/userlogs" def regex_clean(data): PATTERNS = [r'(^\S+\.[\S+\.]+\S+)\s',r'(?<=\[).+?(?=\])', r'\"(\S+)\s(\S+)\s*(\S*)\"',r'\s(\d+)\s',r"(?<=\[).\d+(?=\])", r'\"[AZ][az]+', r'\"(http|https)://[az]+.[az]+.[az]+'] result = [] for match in PATTERNS: try: reg_match = re.search(match, data).group() if reg_match: result.append(reg_match) else: result.append(" ") except: print("There was an error with the regex search") result = [x.strip() for x in result] result = [x.replace('"', "") for x in result] res = ','.join(result) return res class Split(beam.DoFn): def process(self, element): from datetime import datetime element = element.split(",") d = datetime.strptime(element[1], "%d/%b/%Y:%H:%M:%S") date_string = d.strftime("%Y-%m-%d %H:%M:%S") return [{ 'remote_addr': element[0], 'timelocal': date_string, 'request_type': element[2], 'body_bytes_sent': element[3], 'status': element[4], 'http_referer': element[5], 'http_user_agent': element[6] }] def main(argv=None): parser = argparse.ArgumentParser() parser.add_argument("--input_topic") parser.add_argument("--output") known_args = parser.parse_known_args(argv) p = beam.Pipeline(options=PipelineOptions()) (p | 'ReadData' >> beam.io.ReadFromPubSub(topic=TOPIC).with_output_types(bytes) | "Decode" >> beam.Map(lambda x: x.decode('utf-8')) | "Clean Data" >> beam.Map(regex_clean) | 'ParseCSV' >> beam.ParDo(Split()) | 'WriteToBigQuery' >> beam.io.WriteToBigQuery('{0}:userlogs.logdata'.format(PROJECT), schema=schema, write_disposition=beam.io.BigQueryDisposition.WRITE_APPEND) ) result = p.run() result.wait_until_finish() if __name__ == '__main__': logger = logging.getLogger().setLevel(logging.INFO) main()
输送机启动
我们可以通过几种不同的方式启动管道。 如果需要,我们可以从终端本地运行它,远程登录GCP。
python -m main_pipeline_stream.py \ --input_topic "projects/user-logs-237110/topics/userlogs" \ --streaming
但是,我们将使用DataFlow启动它。 我们可以通过设置以下必需参数来使用以下命令来执行此操作。
- project-您的GCP项目的ID。
runner是一个管道运行程序,它将分析您的程序并构建您的管道。 要在云中运行,必须指定一个DataflowRunner。staging_location -Cloud Dataflow云存储的路径,用于索引流程处理程序所需的代码包。temp_location托管管道操作期间创建的临时作业文件的Cloud Dataflow云存储路径。streaming
python main_pipeline_stream.py \ --runner DataFlow \ --project $PROJECT \ --temp_location $BUCKET/tmp \ --staging_location $BUCKET/staging --streaming
当此命令运行时,我们可以转到Google控制台中的“数据流”标签并查看我们的管道。 通过单击管道,我们应该看到类似于图4的内容。出于调试目的,转到日志然后再到Stackdriver查看详细日志可能非常有用。 在许多情况下,这帮助我解决了管道问题。
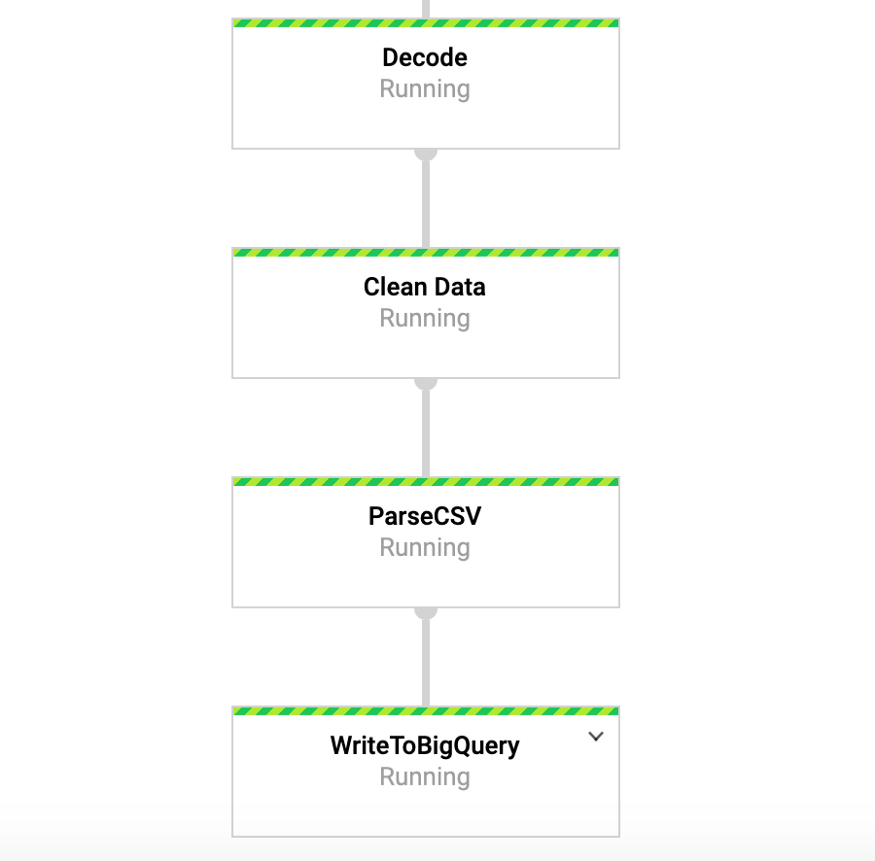 图4:梁式输送机
图4:梁式输送机在BigQuery中访问我们的数据
因此,我们应该已经开始将表中的数据输入管道。 为了测试这一点,我们可以转到BigQuery并查看数据。 使用下面的命令后,您应该看到数据集的前几行。 现在我们已经将数据存储在BigQuery中,我们可以进行进一步的分析,并与同事共享数据并开始回答业务问题。
SELECT * FROM `user-logs-237110.userlogs.logdata` LIMIT 10;
 图5:BigQuery
图5:BigQuery结论
我们希望这篇文章将成为创建流数据管道以及寻找使数据更易于访问的方法的有用示例。 以这种格式存储数据有很多好处。 现在我们可以开始回答重要问题,例如,有多少人使用我们的产品? 用户群是否随着时间增长? 人们与产品互动最多的是什么? 并且在不应该存在的地方有任何错误吗? 这些是组织感兴趣的问题。 根据这些问题的答案所产生的想法,我们将能够改进产品并增加用户兴趣。
Beam对于此类练习非常有用,并且还有许多其他有趣的用例。 例如,您可以实时分析交易所报价的数据并基于该分析进行交易,也许您有来自车辆的传感器数据,并且想要计算流量水平。 例如,您也可以是一家游戏公司,该公司收集用户数据并使用它来创建仪表板以跟踪关键指标。 好的,先生们,这个话题已经在其他文章上了,感谢您的阅读,对于那些想查看完整代码的人,下面是指向我的GitHub的链接。
https://github.com/DFoly/User_log_pipeline
仅此而已。
阅读第一部分 。