
当您整天听技术面试时,您会注意到模式。 相反,就我们而言,他们的缺席。 我设法只找到两件事保持不变。 我什至想出了一个基于它们的酗酒游戏:每当有人认为问题的答案是一个哈希表,我们就喝一堆,如果正确的答案是一个哈希表,我们就喝两个。 但是我不建议玩,我快死了。
为什么我整天听采访? 因为几年前,我成为了一个
采访平台的创建者之一,该服务是一个
采访平台,IT领域的人们可以在此平台与雇主发展沟通技巧,并在此期间找到工作。
结果,我可以访问有关同一用户在不同采访中如何展示自己的大量数据。 事实证明,它们是如此不可预测,您将不可避免地考虑到一次会议的结果通常具有多大的指示意义。
我们如何获取数据
当进行面试的用户和正在寻找工作的用户找到彼此时,他们在联合代码编辑器中会面。 在那里,可以进行语音交流和通过文本消息进行交流,并且具有用于记录决策的标记板的类似物-您可以立即开始技术问题。
我们面试中的问题通常是从电话面试中问到的有关后端软件开发人员职位的申请人中提出的。 进行访谈的用户通常是大型公司的员工(Google,Facebook,Yelp)或技术偏见强烈的初创公司的代表(Asana,Mattermark,KeepSafe等)。 在每次会议结束时,雇主根据几种标准评估候选人,其中一项是编程技能。 评分的等级从1(一般)到4(非常好!)。 在我们的平台上,大多数情况下,成绩为三级及以上意味着该候选人足够强大,可以进入下一阶段。
在这里您可以说:“这一切都很棒,但是这里有什么特别之处? 许多公司在选择过程中都会收集此类统计信息。” 我们的数据在一方面与这些统计数据有所不同:同一位用户可以参加几次面试,每个面试都来自新公司的新员工。 这为在或多或少稳定的环境中进行非常有趣的比较分析提供了机会。
结论1:不同的访谈结果差异很大
让我们从几张图片开始。 在下面的图形中,矮个子形式的每个图标均显示参与两次或更多次采访的一位用户的平均个人评分。 此图表上未显示的参数之一是时间段。
您可以在这里
查看人们的成功如何随着时间变化。 本着原始混乱的精神。
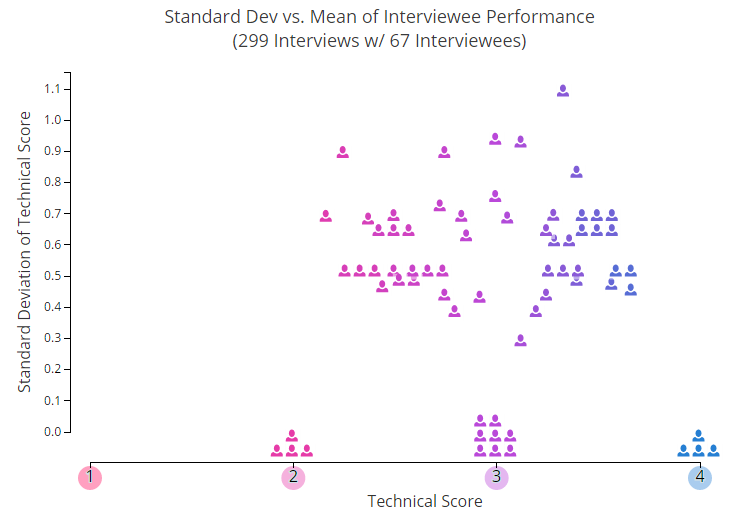
Y轴显示出与平均值的典型偏差-因此,我们上升的越高,访谈的结果就越难以预测。 如您所见,大约有25%的参与者稳定地保持在同一水平,而其余所有参与者则上下跳跃。
仔细研究了此时间表后,尽管有大量数据,您仍可以大致确定出您想邀请哪个用户参加面试。 但是在这里要记住重要的一点:我们取平均值。 现在,假设您需要基于用于计算该评估的单个评估来做出决定。 这是问题开始的地方。
为了更加清晰,您可以打开
图表的交互式下拉版本 。 当您将鼠标悬停在此处时,每个图标都会打开,您可以看到用户在每次采访中获得的等级。 结果可能会让您大吃一惊! 好吧,例如:
- 至少拥有四分之一的人中有很大一部分至少有一次进入“双打”
- 即使您只选择最强的候选人(平均分数从3.3或更高),结果仍然会出现明显波动
- 而“平均”(平均分数-从2.6到3.3),结果特别矛盾
我们想知道候选者的水平和振动幅度之间是否存在任何关系。 换句话说,也许对于那些较弱的人来说,有一些典型的急剧变化,而强大的程序员却是稳定的? 事实证明,没有。 当我们对相对于平均估计的典型偏差进行回归分析时,我们未能建立任何显着的关系(R平方约为0.03)。 这就意味着人们获得不同的成绩,而不管他们的总体水平如何。
我会这样说:当您查看所有这些数据,然后想象您需要根据一次采访的结果选择一个人时,感觉就像您正在通过钥匙孔看一间漂亮,布置豪华的房间。 在一种情况下,您会很幸运地在墙上看到图片,在另一种情况下-您可以看到一堆葡萄酒,在第三种情况下-您会把自己埋在沙发的后面。
在实际情况下,当我们试图决定是否致电申请人在办公室进行面试时,我们通常会尝试避免第一类错误(即不要随机选择缺少律师的人)和第二类错误(即不拒绝那些值得邀请)。 市场领导者通常基于第二类错误带来的危害较小的事实来制定战略。 看来合乎逻辑,对吧? 如果有足够的资源并且申请人数量很大,即使第二类型的错误很多,仍然会有合适的人。
但是,这种第二种犯错的策略具有阴影的一面,现在它使自己感到自己,正蔓延到当前IT领域的招聘危机中。 目前的单次面试能否提供足够的信息? 尽管对有才华的开发人员的需求增加了,我们是否拒绝仅仅因为我们试图通过一个微小的窥视孔来考虑具有很大差异的广泛计划而拒绝有能力的工人?
因此,如果我们忽略隐喻和道德读物:由于面试的结果是如此不可预测,那么强势候选人在电话面试中失败的可能性有多大?
结论2:根据以往尝试的结果,面试失败的可能性
以下是根据平均估算得出的整个用户群的百分比分布。
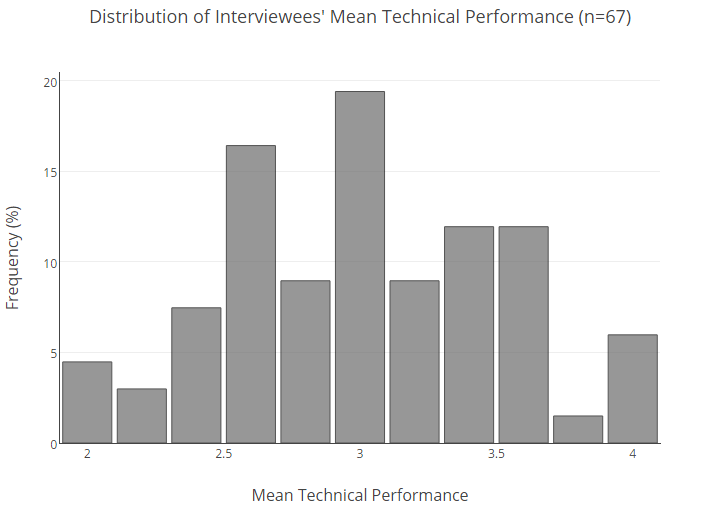
为了了解具有一定平均水平的候选人在面试中表现不佳的可能性,我们必须进行统计。
首先,我们根据平均评分将受访者分为几类(而值则四舍五入到0.25以内)。 然后,对于每个组,计算失败的概率,即获得2或更低的分数。 此外,为了补偿少量数据,我们
对进行了重新采样 。
在编制重新抽样时,我们将未来采访的结果视为多项名义分布。 换句话说,我们提出其结果是由具有四个面的骰子滚动决定的,对于每个组,立方体的重心都以某种方式移动。
然后我们开始扔这些骰子,直到为每个组创建一组新的模拟数据为止。 基于这些数据,计算出具有不同估计值的用户的新故障概率。 在下面,您可以看到在10,000次此类抛出之后收到的图表。
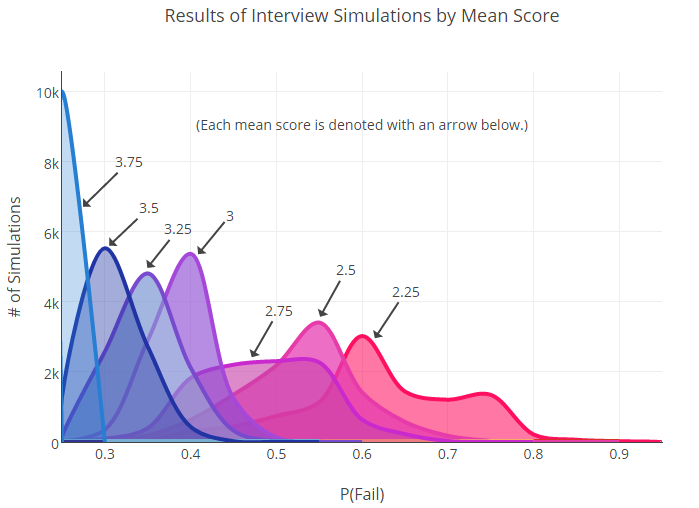
如您所见,有许多交叉点。 这很重要:重叠的事实告诉我们,某些组之间可能没有统计学上的显着差异(例如2.75和3)。
当然,当我们拥有更多数据(更多)时,组之间的界限将更加清晰。 另一方面,需要大量样本来发现故障率指标之间的差异这一事实可能表明,对于普通用户而言,结果最初具有很大的可变性。
最后,我们可以放心地说:刻度的两个极点之间的差异(2.25和3.75)是显着的,但是两者之间的一切都已经不那么明确了。
但是,基于此分布,我们尝试计算具有一个或另一个平均评分的候选人在一次面试中表现不佳的百分比概率:
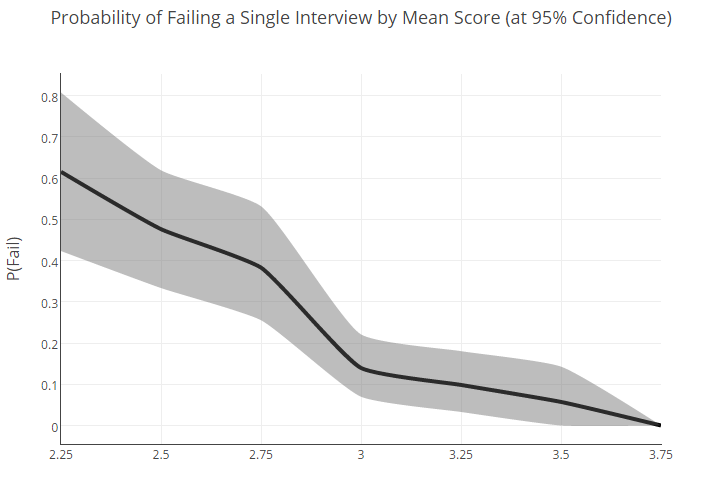
具有良好总体水平(即平均评分约为3)的人可能以22%的概率失败的事实表明,我们现在使用的选择方案可以而且应该加以改进。 “平均”的有雾结果仅证实了这一结论。
那么,采访注定要失败吗?
一般而言,“访谈”一词在我们的脑海中唤起了一种有益的影像,并给出了可重复的结果。 但是,我们收集的数据说明的是完全不同的东西。 这与我在雇用员工方面的个人经验以及我在社区中经常听到的意见有一些共同点。
扎克·霍尔曼(Zack Holman)的文章“
启动面试是F *****”强调了选择候选人的理由与他们要做的工作之间的差异。 TripleByte先生们已经处理了自己的数据,
得出了类似的结论 。
被拒绝的平台最近提供了生动的证据,表明采访过程中存在不一致之处。
可以说,许多在与A公司进行电话采访后被筛选出来的人在另一次采访中表现出最好的结果,最终出现在一些被认为是不错的公司中-现在六个月后,他们收到了A公司招聘人员的谈话要约。尽管双方都做出了种种努力,但这种昧,不可预测,最终随机挑选候选人的过程仍在继续,就像在魔术圈里一样。
因此,是的,当然,可以得出的结论之一是技术面试陷入僵局,它们没有提供足够的可靠信息来预测单个面试的结果。 对算法问题的访谈是社区中非常热门的话题,我们希望在将来对其进行详细分析。
追踪候选人的成功与面试类型之间的关系将特别有趣-我们平台上出现了越来越多的方法和变化。 实际上,这是我们的长期目标之一:如何挖掘收集的数据,检查当前的候选人选择策略的范围,并得出一些由数据支持的严肃结论,以得出哪些面试形式可以提供最有用的信息。
同时,我倾向于这样一个想法,那就是从一个概括的角度来看总比由一个会议的任意结果来指导一个重要的决定要好。 广义的数据使我们不仅可以对那些在个别情况下回答能力异常弱的人进行校正,还可以对那些纯粹靠运气留下好印象或最终在这个怪物面前低下头并记住了《破解编码面试》的人进行校正。
我知道,公司在野外某处收集候选人技能的其他证据并不总是可行的,甚至是不可能的。 但是,例如,如果某个边缘案件或某个人根本没有按照您的预期展现自己,那么在做出最终决定之前,再次与他们交谈并切换到其他材料可能很有意义。