一年前,当我们同时达到
服务于
我们的12K在线用户的标记时,我们曾考虑过构建大型负载测试的基础架构。 3个月以来,我们制作了该测试的第一个版本,该版本显示了服务的局限性。
具有讽刺意味的是,在测试启动的同时,我们达到了产品的极限,结果服务减少了2个小时。 这进一步鼓励我们开始从逐案进行测试转变为创建有效的承重基础架构。 对于基础架构,我指的是用于处理负载的所有工具:启动和启动的工具,用于负载的集群,集群,类似产品,用于收集指标和准备报告的服务,用于管理所有这些的代码以及用于扩展的服务。
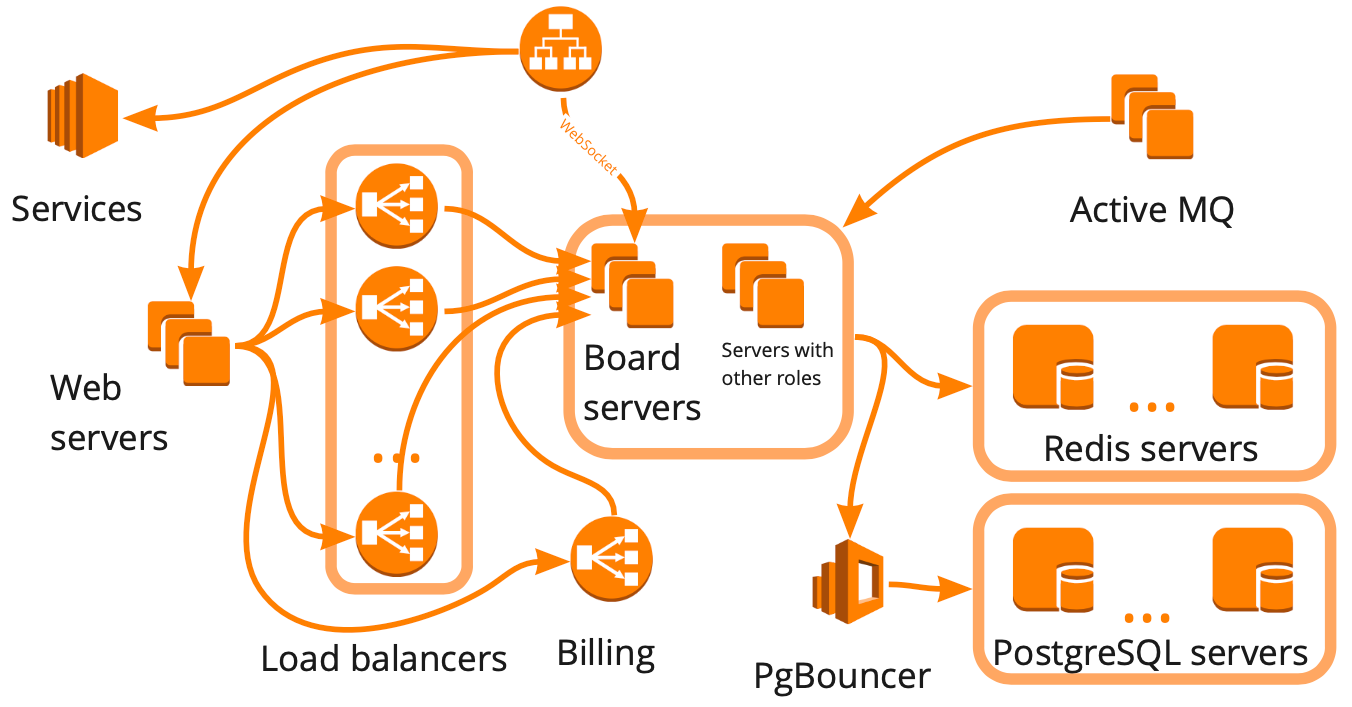
这就是miro.com方案的简化形式:有许多不同的服务器以某种方式相互交互,并且每个服务器执行特定的任务。 看来,为了构建负载测试的基础结构,我们制定这样的方案,考虑所有关系并开始用脚本依次覆盖每个块就足够了。 这种方法不错,但是要花很多个月,由于快速增长,它不适合我们-在过去的六个月中,我们同时从12,000名在线用户增长到2万名在线用户。 此外,我们不知道我们服务的基础架构将如何应对负载的增加:哪些模块将成为瓶颈,哪些模块可以线性扩展。
结果,我们决定使用虚拟用户测试服务,以模拟他们的实际工作,即构建生产克隆并进行大型测试,该测试:
- 在结构上加载与生产相同但在功率方面领先于它的集群;
- 向我们提供所有数据以做出决策;
- 将表明整个基础架构能够承受适当的负载;
- 将是我们将来可能需要进行压力测试的基础。
这种测试的唯一缺点是它的成本价格,因为为此,我们需要一个比生产环境更大的环境。
在本文中,我将向您介绍创建逼真的场景,插件-WS,Stress-client,Taurus-负载集群,销售集群以及显示使用测试的示例。
下一篇文章是关于我们如何管理数百台服务器进行负载测试的。
创建一个现实的场景
要创建一个现实的场景,我们需要:
- 分析用户在产品上的工作,为此,确定对我们重要的指标,开始定期收集它们并分析跳跃;
- 制作方便的自定义块,以便我们可以有效地加载业务逻辑的必要部分;
- 使用服务器指标验证脚本的真实性。
现在更多关于每个项目。
用户产品工作分析在我们的服务中,用户可以创建板并在板上使用不同的内容进行处理:照片,文本,mocapas,贴纸,图表等。 我们需要收集的第一个指标是木板的数量及其上内容的分布。
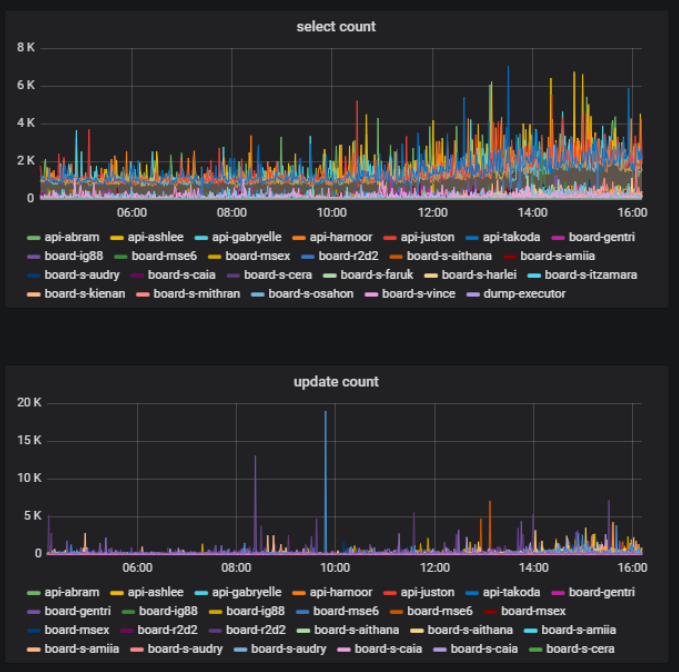
在同一时间的同一板上,一些用户可以主动执行某些操作-创建,删除,编辑-某些用户可以简单地查看所创建的材料。 这也是一项重要的指标-更改板上内容的用户数量与一个板上用户总数的比率。 我们可以在使用数据库的统计数据的基础上获得此信息。
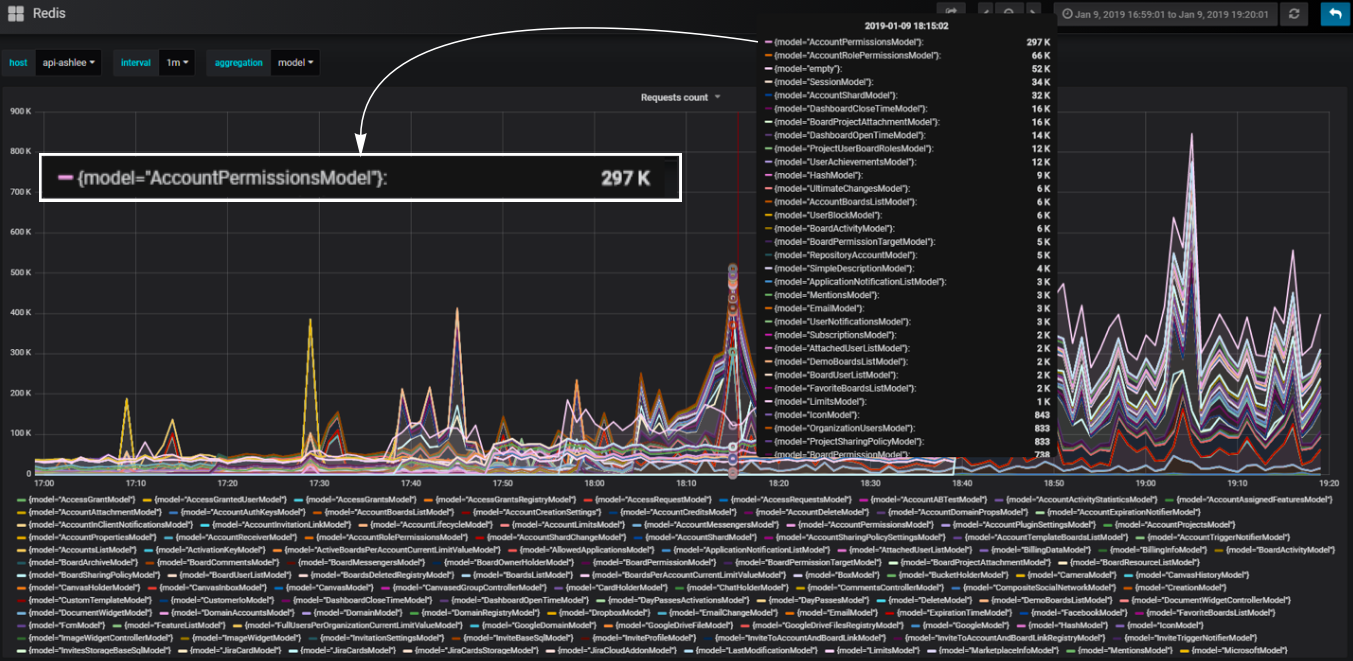
在我们的后端,我们使用组件方法。 我们称之为模型的组件。 我们将代码分成模型,以便对业务逻辑的每个部分都由某个模型负责。 我们可以计算通过每个模型发生的数据库调用的数量,并了解逻辑的哪一部分最多加载数据库。
 方便的自定义块
方便的自定义块例如,我们需要在脚本中添加一个块来加载我们的服务,与您打开包含用户面板列表的仪表板页面时的加载过程相同。 在加载此页面期间,将发送带有大量数据的http请求:面板数,用户有权访问的帐户,该帐户的所有用户,等等。

如何有效加载仪表板? 在分析生产行为时,我们在打开大客户仪表板期间看到数据库中的负载峰值。 我们可以重新创建一个相同的帐户,并更改在脚本中使用其数据的强度,从而有效地加载具有少量匹配的仪表板。 我们还可以创建不均匀的负载以实现更高的真实感。
同时,对于我们而言重要的是,虚拟用户的数量和虚拟用户创建的负载应尽可能与用户和生产负载相似。 为此,我们还在测试中重新创建了平均仪表板上的后台负载。 因此,大多数虚拟用户都在较小的平均仪表板上工作,只有少数用户会像生产中那样造成灾难性的负载。
最初,我们不想用单独的脚本介绍每个服务器角色和每个关系。 在带有仪表板的示例中可以看到这一点-我们仅在测试过程中重复用户打开产品时仪表板在产品上打开时会发生的情况,并且我们不会涵盖其对合成脚本的影响。 默认情况下,这使您可以测试我们从未想到的细微差别。 因此,我们正从业务逻辑的角度着手创建基础结构测试。
我们使用此逻辑来有效加载服务的所有其他块。 同时,从使用功能的逻辑角度来看,每个单独的块可能都不现实; 重要的是要在服务器上提供切合实际的度量标准负载。 然后,我们可以从这些块中创建一个脚本来模仿用户的实际工作。

数据是脚本的一部分。
请记住,数据也是脚本的一部分,并且代码本身的逻辑非常依赖于数据。 在为测试构建大型数据库时-对于大型基础架构测试显然应该很大-我们需要学习如何创建在脚本执行过程中不会失败的数据。 如果累积垃圾数据,该脚本可能会变得不切实际,并且大型数据库将很难修复。 因此,我们开始以与用户相同的方式使用Rest API创建数据。
例如,要创建具有可用数据的板,我们执行API请求以从备份中加载板。 结果,我们得到了真实的真实数据-不同规模的不同电路板。 同时,由于我们以多线程方式提取脚本中的请求,因此数据库正在快速填充。 在速度上,这可与垃圾数据的生成相媲美。
这部分的结果
- 如果您想一次检查所有内容,请使用实际方案。
- 分析实际用户行为以设计脚本结构;
- 立即创建方便的自定义块;
- 通过真实的服务器指标进行配置,而不是通过使用情况分析进行配置;
- 请记住,数据是脚本的一部分。
负载集群
施加负荷的工具方案:
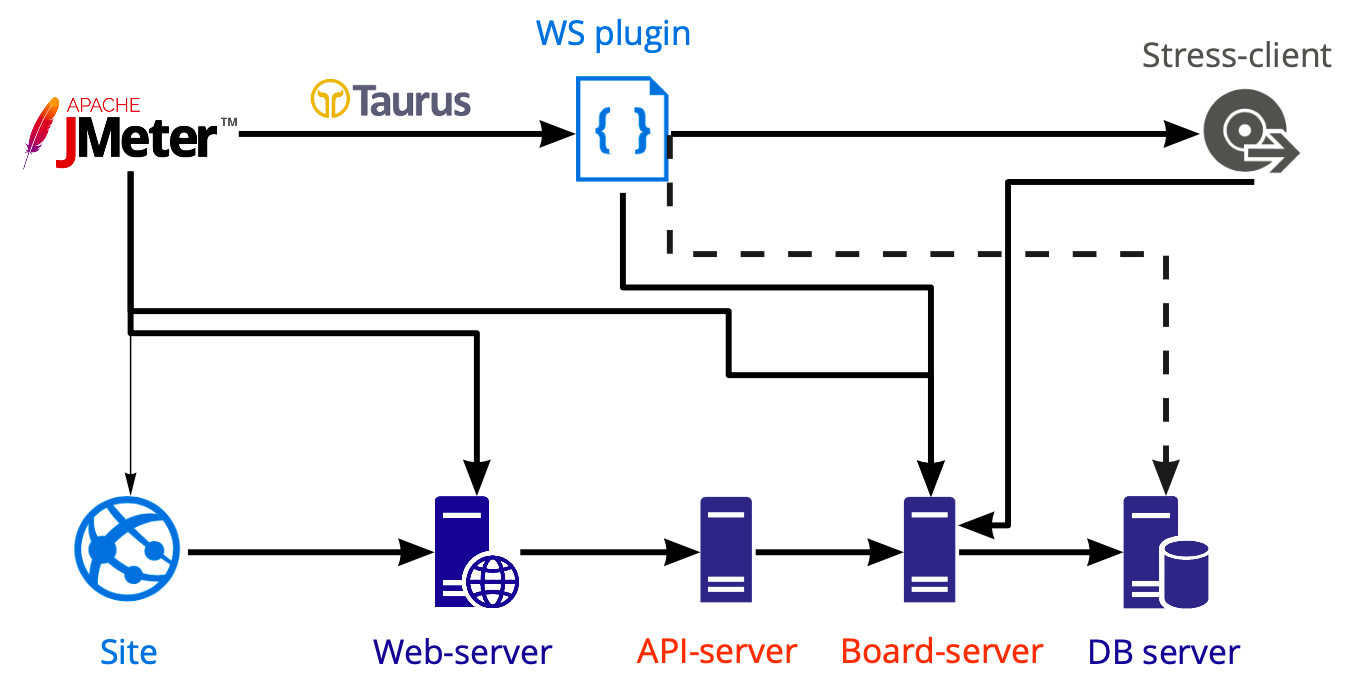
在Jmeter中,我们创建一个脚本,该脚本将使用Taurus启动并用它加载各种服务器:Web,API,板服务器。 我们使用Postgresql而不是Jmeter单独执行数据库测试,因此该图显示了一条虚线。
网络套接字中的自定义工作
板上的工作发生在WS-connection内部,并且可以在板上进行多用户工作。 现在,在插件管理器内的Jmeter框中,有几个用于使用Web套接字的插件。 逻辑无处不在-插件只是打开一个Web套接字连接,但是无论如何,内部发生的所有操作都需要自己编写。 怎么了 因为我们无法以与HTTP请求相同的方式工作,也就是说,我们无法编写脚本,使用提取器提取动态值并进一步跳过它们。
Web套接字内的工作通常是非常自定义的:您需要使用某些数据自定义来调用某些方法,因此,您自己需要了解请求是否正确执行以及执行所需的时间。 该插件中的Listener也独立编写;我们没有找到一个好的现成的解决方案。
压力客户
我们希望尽可能简单地重复实际用户的操作。 但是我们不知道如何记录和回放WS内部浏览器中发生的情况。 如果我们从头开始在WS中编写所有内容,那么我们将获得一个新的客户端,而不是真正的用户使用的客户端。 如果我们已经有一位新客户,我不想写一个新客户。
因此,我们决定将客户放置在Jmeter中。 并面临许多困难。 例如,在Jmeter中执行js是一个单独的故事,因为 这是受支持功能的绝对
特定版本 。 而且,如果您想使用现有的客户端代码,则很可能不会成功,因为无法在此处启动新构造的结构,因此必须对其进行重写。
第二个困难是我们不想为负载测试支持整个客户端代码。 因此,我们从客户端中删除了所有多余的内容,仅保留了客户端与服务器之间的交互。 这使我们能够使用客户端-服务器方法并执行客户端可以做的所有事情。 优点是客户端与服务器之间的交互很少改变,这意味着很少需要脚本内的代码支持。 例如,在过去的六个月中,我从未对代码进行任何更改,因为它的效果很好。
第三个难题-大型脚本的出现使脚本变得非常复杂。 首先,它可能成为测试的瓶颈。 其次,我们很可能将无法在一台计算机上启动大量线程。 现在我们只能启动730个线程。
我们的Amazon实例示例 Jmeter server AWS: m5.large ($0.06 per Hour) vCPU: 2 Mem (GiB): 8 Dedicated EBS Bandwidth (Mbps): Up to 3,500 Network Performance (Gbps): Up to 10 → ~730
在哪里获得数百台服务器以及如何保存
接下来,问题来了:一台机器上有730个线程,但我们要50K。 在哪里筹集这么多服务器? 我们正在创建一个云解决方案,因此购买用于测试云解决方案的服务器似乎很奇怪。 另外,购买新铁的过程总是有一定的缓慢性。 因此,我们还需要在云中对其进行提升,因此我们最终在云提供商和云负载工具之间进行选择。
我们没有使用Blazemeter和RedLine13等云加载工具,因为它们的使用限制不适合我们。 我们有不同的测试站点,因此我们想找到一个通用的解决方案,该解决方案将允许90%的开发使用,包括在本地测试中。
结果,我们在云提供商之间进行选择。
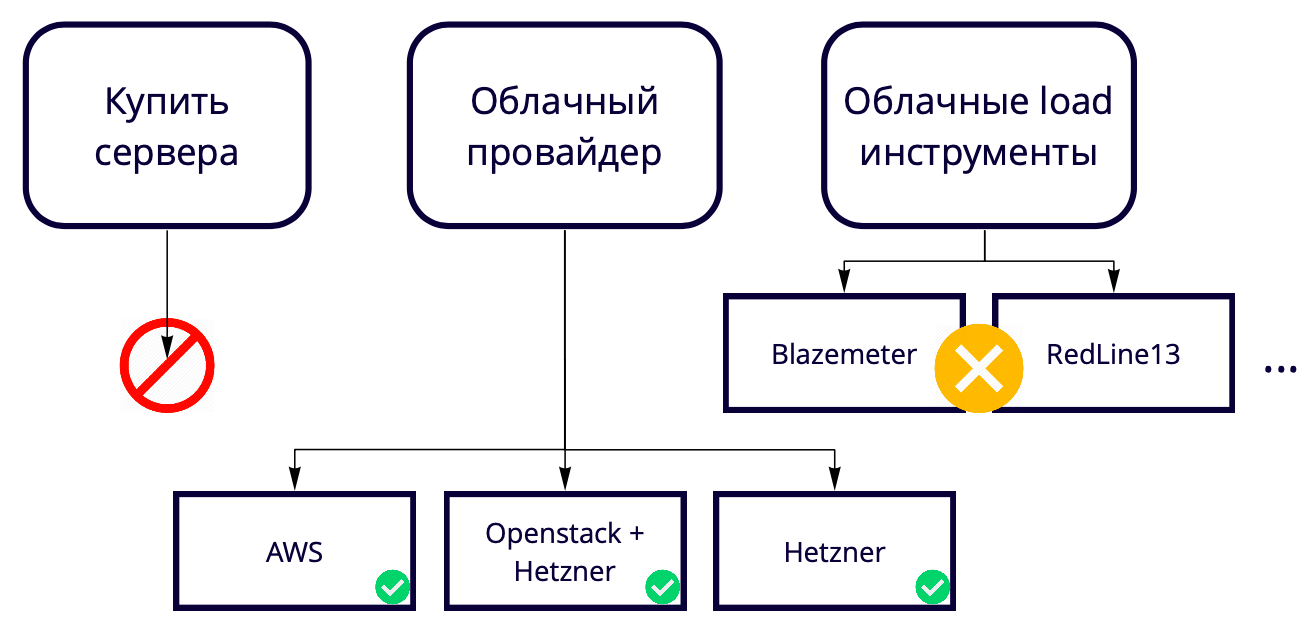
我们的生产是在AWS上进行的,因此我们主要在此进行测试,并且我们希望测试平台与生产尽可能相似。 亚马逊具有许多付费功能,例如我们在产品中使用的一些平衡器。 如果在AWS中不需要这些功能,那么您可以在Hetzner中将它们便宜17倍。 或者,您可以将服务器保留在Hetzner中,使用Openstack并自己编写平衡器和其他功能,因为使用Openstack可以重复整个基础架构。 我们成功了。
在AWS中使用69个实例测试5万用户每月需要花费大约3000美元。 如何保存? 例如,AWS有临时实例-竞价型实例。 它们的妙处在于我们不会一直保持它们不变,我们只会在测试期间提高它们的成本,而它们的成本要低得多。 细微的差别是,在我们进行测试时,其他人可以以更高的价格购买它们。 幸运的是,这从未发生过,但是我们已经节省了至少60%的成本,而他们却为此而牺牲。
负载集群
我们使用Jmeter框集群。 它的效果很好,不需要进行任何修改。 它有几个启动选项。 当一个向导启动N个实例时,我们使用最简单的方法,并且可能有数百个实例。
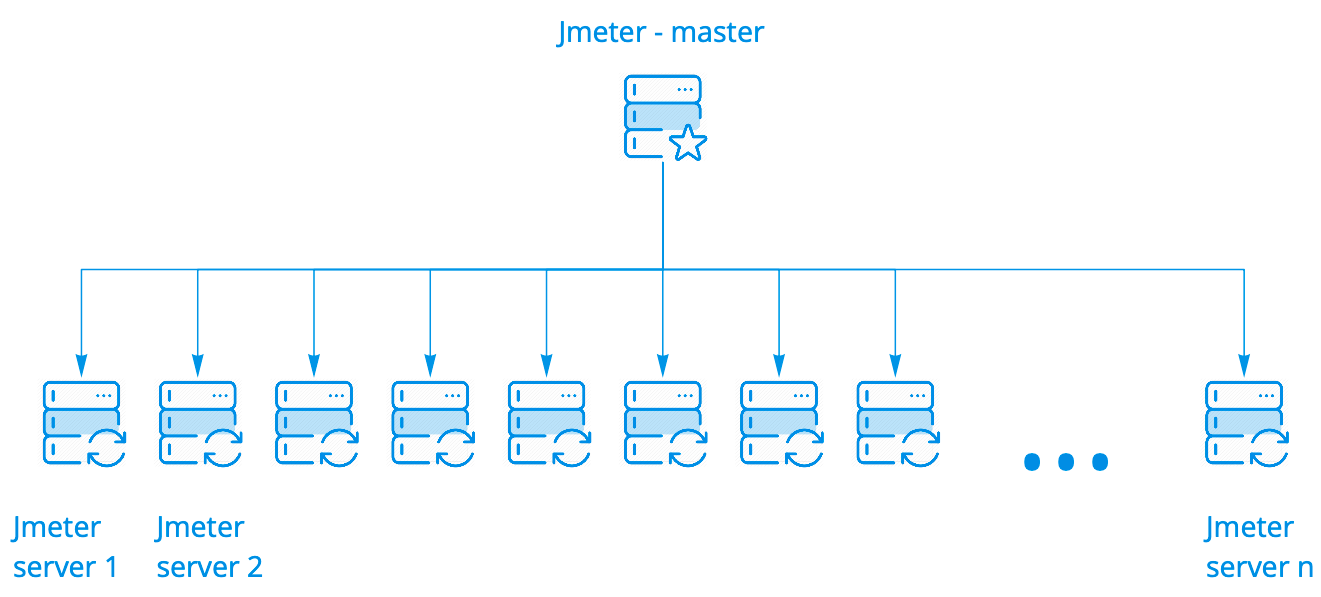
该向导在Jmeter服务器上运行脚本,同时与它们保持联系,实时收集所有实例的常规统计信息并将其显示在控制台中。 尽管我们看到了在一百台服务器上启动的结果,但所有这些看上去都与在一台服务器上运行脚本完全相同。
为了对所有实例上的脚本执行结果进行详细分析,我们使用Kibana。 Parsim使用Filebeat记录日志。

Apache JMeter的Prometheus侦听器
Jmeter有一个
用于Prometheus的
插件,该
插件开箱即用地提供了有关测试中JVM和线程使用情况的所有统计信息。 这使您可以查看用户登录,注销等的频率。 可以对插件进行自定义,以将脚本上的数据发送给Prometheus并在Grafana中实时查看它们。
金牛座
我们想用Taurus解决当前的许多问题,但尚未解决:
- 配置而不是脚本克隆。 如果您在Jmeter上进行了测试,则可能需要使用带有不同源参数集的脚本来运行脚本,而这些脚本必须为其创建副本。 在Taurus中,可以有一种情况,并可以通过配置来控制启动参数。
- 使用集群时用于管理Jmeter服务器的配置;
- 一个在线结果分析器,它使您可以与Jmeter线程分开收集结果,而不会增加脚本本身的负担;
- 与CI的便捷集成;
- 测试分布式系统的能力。
这部分的结果
- 如果我们在Jmeter中使用代码,那么最好立即考虑一下它的性能,因为否则我们可以测试Jmeter,而不是我们的产品。
- Jmeter集群是一件很了不起的事情:它易于配置,易于监视。
- 大型集群可以保留在现场实例中,它会便宜得多。
- 请注意Jmeter内部的侦听器,以使该脚本不会减慢大量服务器上的工作。
使用基础架构测试的示例
上面的整个故事主要是关于为服务限制测试创建现实的方案。 以下示例显示了如何重用负载测试的基础结构来解决本地问题。 我将详细介绍两个测试,但一般来说,我们会定期进行大约10种类型的负载测试。
数据库测试
我们可以在数据库中加载什么测试? 繁重的查询是不太可能的,因为如果我们仅查看查询计划,就可以在单线程模式下对其进行测试。
一个有趣的情况是,当我们运行测试并看到磁盘上的负载时。 该图显示了iowait如何上升。
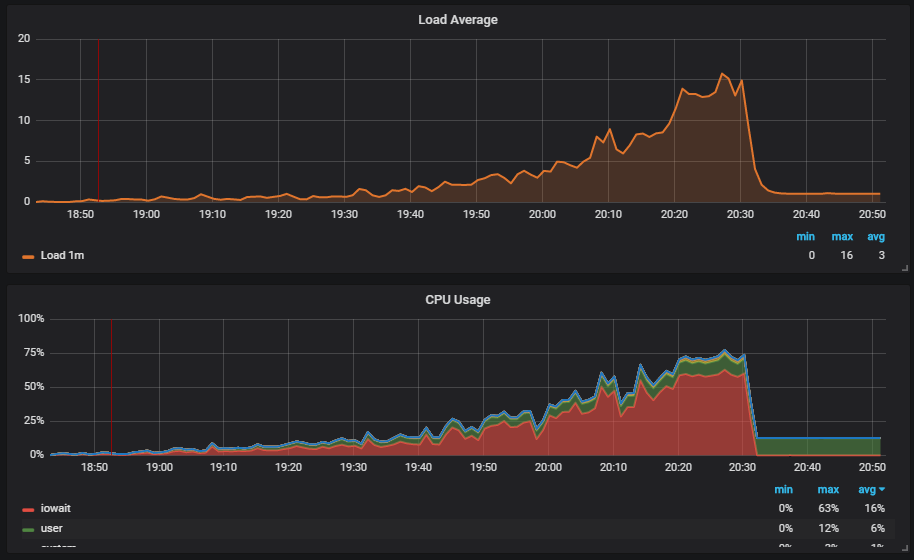
此外,我们看到这会影响用户。
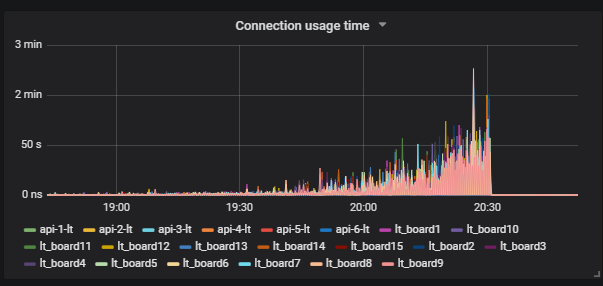
我们了解原因:吸尘器不起作用,也没有从数据库中删除垃圾数据。 如果您尚未使用Postgresql,那么Vacuum就像Java中的垃圾收集器一样。

此外,我们看到
Checkpoint开始无法按计划进行工作。 对我们来说,这表明Postgresql配置与数据库的工作强度不符。
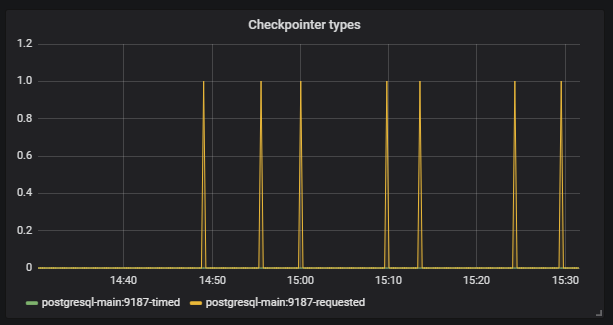
我们的任务是正确配置数据库,以免此类情况再次发生。 相同的Postgresql有许多设置。 为了进行微调,您需要进行短暂的迭代:更正配置,启动,检查,更正配置,启动,检查。 当然,为此您需要对基础施加良好的负载,但是为此,您只需要大型基础架构测试即可。
特殊之处在于,为了使测试正常加速并且不会在不需要的地方下降,超频应该很长。 测试大约需要三个小时,而且看起来不再是短暂的迭代。
我们正在寻找解决方案。 我们找到一种Postgresql工具
-Pg_replay 。 他可以多线程准确地复制日志中记录的内容以及记录时的情况。 我们如何有效地使用它? 我们折叠数据库转储,然后将保存在日志中的所有事件记录到日志中,然后我们有机会部署转储并播放多线程数据库所发生的一切。
在哪里写日志? 记录日志的一种流行解决方案是将其收集在产品上,因为这提供了最现实的可复制脚本。 但是有很多问题:
- 对于测试,您需要使用销售数据,但并非总是可能的。
- 该过程使用昂贵的syslog操作;
- 磁盘正在加载。
我们进行大型测试的方法在这里对我们有所帮助。 我们在测试环境中进行转储,运行大型测试并记录执行实际脚本时发生的所有事件的日志。 接下来,我们使用自己的
marucy工具来测试数据库:
- 在AWS中创建一个实例;
- 我们需要的转储已部署;
- 启动Pg_replay并播放必要的日志;
- 我们使用监控来分析Prometheus + Grafana的结果。 存储库中有仪表板的示例。
开始marucy时,我们可以传递少量可以更改的参数,例如脚本的强度。
结果,我们使用现实的脚本来创建测试,然后在不使用大型群集的情况下进行测试。 重要的是要考虑到,对于测试任何sql数据库,脚本必须是不均匀的,否则数据库本身的行为将与产品不同。
降解监测
对于降级测试,我们使用实际方案。 我们的想法是,我们需要确保该服务在下一个发行版之后不会更慢地运行。 如果我们的开发人员更改了代码,从而导致请求执行时间增加,我们可以将新值与参考值进行比较,并在构建中出现错误时发出信号。 对于参考值,我们采用适合我们的当前值。
控制查询执行时间很有用,但我们走得更远。 我们希望看到发布后真实用户在工作期间的响应时间没有变长。 我们以为在进行压力测试时,我们可能可以检查一下,但是只有几十种情况。 运行现有的功能测试并同时查看一千个案例,效率更高。

它对我们如何运作? 组装后,有一个主机部署到测试台。 然后,功能测试会与负载测试同时自动运行。 然后,我们在《魅力》中获得了一份有关功能测试如何在负载下进行的报告。
例如,在此报告中,我们看到比较测试的参考值下降了。
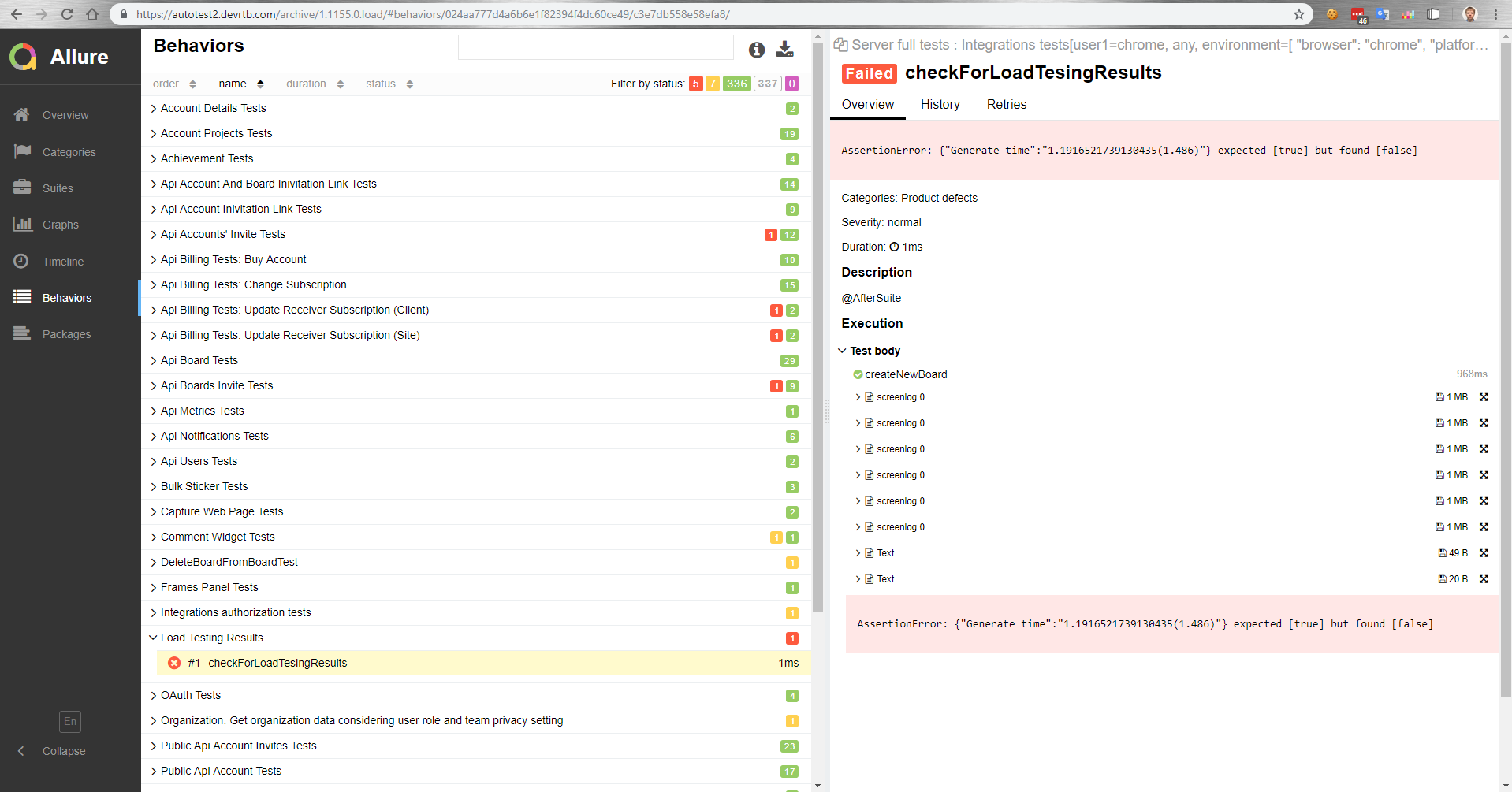
同样在功能测试中,我们可以测量浏览器中操作的执行时间。 或者,由于增加了负载下操作的执行时间,因此功能测试根本无法成功,因为客户端上的超时将起作用。
这部分的结果
- 真实的测试可以让您廉价地测试数据库并轻松配置它;
- 可以在负载下进行功能测试。
下一篇文章是关于我们如何管理数百台服务器进行负载测试的。