文本解析总是从词法分析或标记化开始。 对于使用正则表达式的几乎所有语言,有一种简单的方法可以解决此问题。 好的旧正则表达式的另一种用法。
我经常遇到解析文本的任务。 对于简单的任务,例如分析用户输入的值,基本的正则表达式功能就足够了。 对于诸如编写编译器或静态代码分析之类的复杂而繁重的任务,可以使用专用工具(AntLR,JavaCC,Yacc)。 但是,当正则表达式不足时,我经常遇到中级任务,但我不想在项目中使用繁重的工具。 此外,这些工具通常在编译时阶段运行,并且在运行时不允许更改分析参数(例如,从文件或数据库表中形成关键字列表)。
举例来说,我将给出一个在加速SQL查询过程中出现的任务。 我们分析了SQL查询的日志,并希望根据某些规则查找“不良”查询。 例如,查询中使用OR来检查同一字段的一组值
name = 'John' OR name = 'Michael' OR name = 'Bob'
我们想用
name IN ('John', 'Michael', 'Bob')
正则表达式已无法应对,但我也不想使用AntLR创建完整的SQL解析器。 无需任何专用工具,就可以将请求文本分解为令牌,并使用简单的代码进行解析。
使用正则表达式的基本功能可以解决此问题。 让我们尝试将SQL查询拆分为令牌。 我们将看一下SQL的简化版本,以免在文本中增加细节。 要创建完整的SQL词法分析器,您将不得不编写稍微复杂一些的正则表达式。
这是基本SQL语言令牌的一组表达式:
1. keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b 2. id : [A-Za-z][A-Za-z0-9]* 3. real_number : [0-9]+\.[0-9]* 4. number : [0-9]+ 5. string : '[^']*' 6. space : \s+ 7. comment : \-\-[^\n\r]* 8. operation : [+\-\*/.=\(\)]
我要注意关键字的正则表达式
keyword : \b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b
它具有两个功能。
- 例如,在开头和结尾都使用\ b运算符,以便不从单词organization切掉“ or”或“ prefix”,这是一个关键字,某些正则表达式引擎将在不使用\ b运算符的情况下将其分隔为单独的标记。
- 所有单词均按不包含匹配项的不包含括号(?:)分组。 将来会使用它,以免违反通用表达式中部分正则表达式的索引。
现在,您可以使用分组和运算符|将所有这些表达式组合为一个整体。
(\b(?:select|from|where|group|by|order|or|and|not|exists|having|join|left|right|inner)\b)|([A-Za-z][A-Za-z0-9]*)|([0-9]+\.[0-9]*)|([0-9]+)|('[^']*')|(\s+)|(\-\-[^\n\r]*)|([+\-\*/.=\(\)])
现在,您可以尝试将此表达式应用于SQL表达式,例如
SELECT count(id)
这是Regex测试仪上的结果 。 通过单击链接,您可以浏览表达式和分析结果。 可以看出,例如SELECT立即对应于一个1组,它对应于关键字类型。
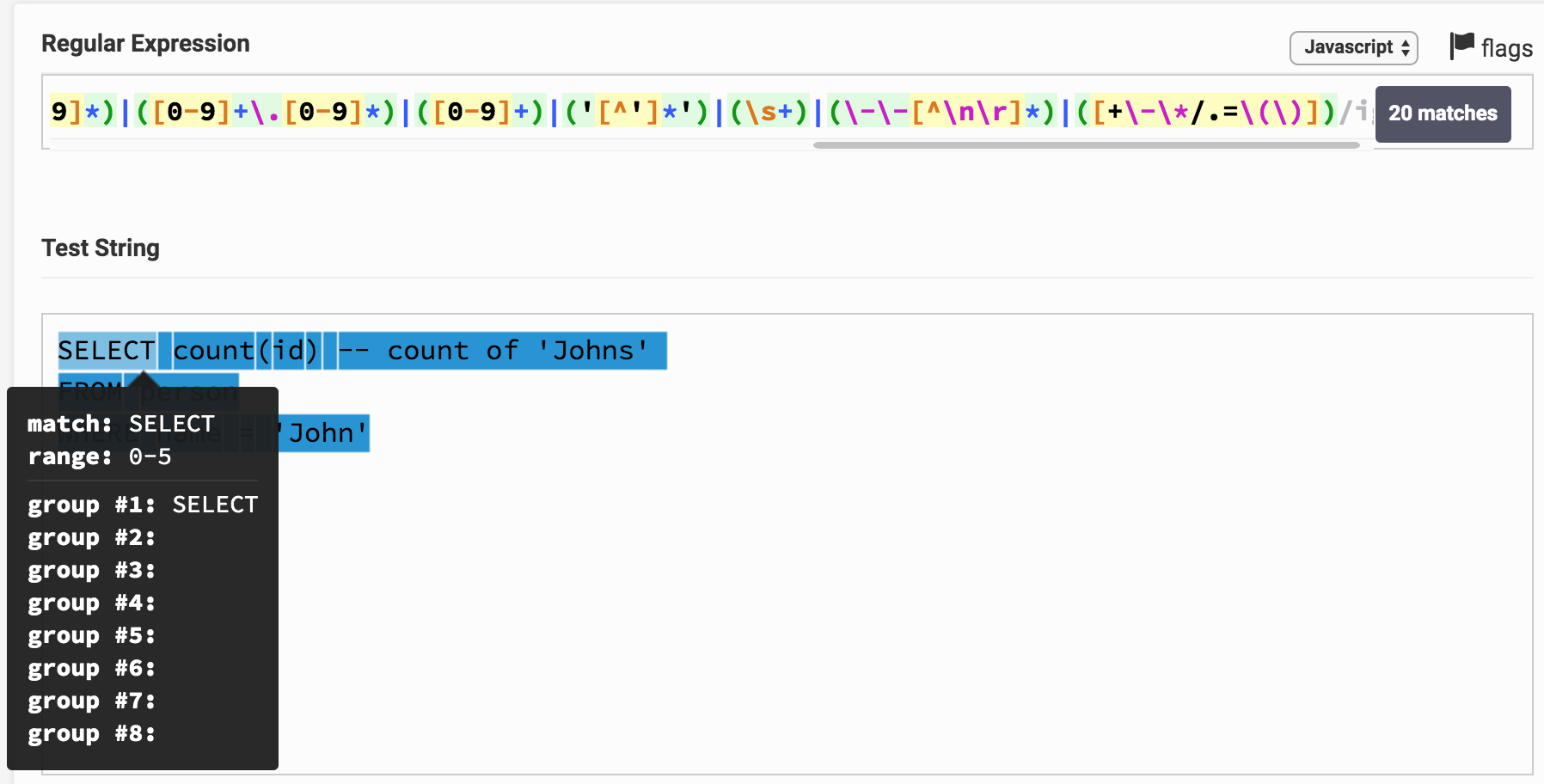
您可能会注意到,请求的整个文本竟然分成了子字符串,每个子字符串对应于某个组。 通过组号,您可以将其与令牌(令牌)的类型相关联。
用支持正则表达式的任何编程语言将给定算法变成程序并不困难。 这是一个用Java实现此功能的小类。
RegexTokenizer.java(以及更多类) package org.example; import java.util.ArrayList; import java.util.Enumeration; import java.util.List; import java.util.regex.Matcher; import java.util.regex.Pattern; import java.util.stream.Collectors; public class RegexTokenizer implements Enumeration<Token> {
在此类中,该算法使用命名组来实现,但并非所有引擎中都存在。 使用此功能,您可以按名称访问组,而不是按索引访问组,这比按索引访问更为方便。
在我的I7 2.3GHz上,此类显示了每秒5-20 MB的分析速度(取决于表达式的复杂性)。 可以通过一次分析多个文件来并行化该算法,从而提高了整体工作速度。
我在网络上发现了几种类似的算法,但是遇到了一些选项,这些选项没有形成共同的正则表达式,而是将每种令牌类型的正则表达式始终应用到行首,然后从行首丢弃找到的令牌,然后再次尝试应用所有正则表达式。 这工作慢了大约10到20倍,需要更多的内存,并且算法更加复杂。 仅使用基于DFA( 确定性有限状态机)的正则表达式实现,我才能实现更快的工作速度。 在正则表达式引擎中,通常使用NKA-一种不确定的有限状态机)。 DFA的速度提高了2-3倍,但是由于运算符的限制,正则表达式的编写更加困难。
在我的SQL示例中,我稍微简化了正则表达式,并且不能将生成的令牌生成器视为SQL查询的完整词法分析器,但本文的目的是展示原理,而不是创建真正的SQL令牌生成器。 我在实践中使用了这种方法,并为SQL,Java,C,XML,HTML,JSON,Pascal甚至是COBOL创建了成熟的词法分析器(我不得不对此进行修补)。
以下是一些用于编写正则表达式进行词法分析的简单规则。
- 如果可以将同一令牌分配给不同的类型(例如,可以将任何关键字识别为标识符),则必须在开始时定义较窄的类型。 然后,将首先应用它的正则表达式,并确定令牌的类型。 例如,在我的示例中, 关键字在id之前定义,并且select令牌将被识别为keyword ,而不是id
- 首先定义较长的令牌,然后定义较短的令牌。 例如,您首先需要定义<= , > = ,然后分离>> << =,在这种情况下,文本<=将被正确识别为小于或等于运算符的单个标记,而不是两个单独的标记<和=
- 学会使用先行和后退 。 例如,SQL中的*字符具有乘法运算符和表中所有字段的含义。 使用简单的后向,您可以将这两种情况分开,例如, 这里 regexp (?<=。\ S | select \ s ) *仅在值“表的所有字段”中查找字符*。
- 为文本中出现的错误定义正则表达式有时很有用。 例如,如果执行语法突出显示,则可以将未完成的字符串标记的类型定义为
'[^\n\r]* 。 在编辑文本的过程中,用户可能没有时间关闭字符串中的引号,但是您的标记生成器将能够正确识别此情况并正确突出显示它。
使用这些规则并应用该算法,您可以将文本快速拆分为几乎所有语言的标记。