
嗨,habrozhiteli! “实践中的预测建模”涵盖了预测的所有方面,从数据预处理,数据拆分和模型调整的基本原理的关键阶段开始。 在现实生活中的实际示例中考虑了建模的所有阶段,在每一章中都给出了R中的详细代码。
本书可以用作预测模型的简介及其应用指南。 没有经过数学训练的读者会喜欢特定方法的直观解释,而关注解决实际数据实际问题的注意力将帮助想要提高技能的专家。
作者试图避免复杂的公式,了解基本的统计概念,例如相关性和线性回归分析,足以掌握基本材料,但是需要数学训练才能研究高级主题。
摘录。 7.5。 计算方式
本节将使用R caret,earth,kernlab和nnet软件包中的函数。
R具有许多用于创建神经网络的软件包和功能。 其中包括nnet,nural和RSNNS软件包。 主要关注于nnet软件包,该软件包支持具有一级隐藏变量,减轻重量的神经网络的基本模型,并且具有相对简单的语法。 RSNNS支持广泛的神经网络。 请注意,Bergmeir和Benitez(2012)对R中的各种神经网络包进行了简要说明。那里也提供了RSNNS教程。
神经网络
为了近似回归模型,nnet函数可以同时接收模型公式和矩阵接口。 对于回归,隐藏变量和预测之间的线性关系与linout = TRUE参数一起使用。 对神经网络功能的最简单调用如下所示:
> nnetFit <- nnet(predictors, outcome, + size = 5, + decay = 0.01, + linout = TRUE, + ## + trace = FALSE, + ## + ## .. + maxit = 500, + ## , + MaxNWts = 5 * (ncol(predictors) + 1) + 5 + 1)
该调用将创建一个具有五个隐藏变量的模型。 假设预测变量中的数据在单个尺度上进行了标准化。
为了平均模型,使用插入符号包中的avNNet函数,该函数具有相同的语法:
> nnetAvg <- avNNet(predictors, outcome, + size = 5, + decay = 0.01, + ## + repeats = 5, + linout = TRUE, + ## + trace = FALSE, + ## + ## .. + maxit = 500, + ## , + MaxNWts = 5 * (ncol(predictors) + 1) + 5 + 1)
新数据点由命令处理
> predict(nnetFit, newData) > ## > predict(nnetAvg, newData)
为了重现先前介绍的通过重复采样选择隐藏变量数量和减少权重的方法,我们将训练函数与method =“ nnet”或method =“ avNNet”参数一起应用,首先删除预测变量(以使预测变量之间的最大绝对对相关性不超过0.75):
> ## findCorrelation > ## , > ## > tooHigh <- findCorrelation(cor(solTrainXtrans), cutoff = .75) > trainXnnet <- solTrainXtrans[, -tooHigh] > testXnnet <- solTestXtrans[, -tooHigh] > ## - : > nnetGrid <- expand.grid(.decay = c(0, 0.01, .1), + .size = c(1:10), + ## — + ## (. ) + ## . + .bag = FALSE) > set.seed(100) > nnetTune <- train(solTrainXtrans, solTrainY, + method = "avNNet", + tuneGrid = nnetGrid, + trControl = ctrl, + ## + ## + preProc = c("center", "scale"), + linout = TRUE, + trace = FALSE, + MaxNWts = 10 * (ncol(trainXnnet) + 1) + 10 + 1, + maxit = 500)
多维自适应回归样条
MARS模型包含在多个软件包中,但是最广泛的实现是在Earth软件包中。 使用直接通过和截断的标称相位的MARS模型可以按以下方式调用:
> marsFit <- earth(solTrainXtrans, solTrainY) > marsFit Selected 38 of 47 terms, and 30 of 228 predictors Importance: NumNonHAtoms, MolWeight, SurfaceArea2, SurfaceArea1, FP142, ... Number of terms at each degree of interaction: 1 37 (additive model) GCV 0.3877448 RSS 312.877 GRSq 0.907529 RSq 0.9213739
由于内部实现中的该模型使用GCV方法选择模型,因此其结构与本章前面介绍的模型有所不同。 摘要方法生成更广泛的输出:
> summary(marsFit) Call: earth(x=solTrainXtrans, y=solTrainY) coefficients (Intercept) -3.223749 FP002 0.517848 FP003 -0.228759 FP059 -0.582140 FP065 -0.273844 FP075 0.285520 FP083 -0.629746 FP085 -0.235622 FP099 0.325018 FP111 -0.403920 FP135 0.394901 FP142 0.407264 FP154 -0.620757 FP172 -0.514016 FP176 0.308482 FP188 0.425123 FP202 0.302688 FP204 -0.311739 FP207 0.457080 h(MolWeight-5.77508) -1.801853 h(5.94516-MolWeight) 0.813322 h(NumNonHAtoms-2.99573) -3.247622 h(2.99573-NumNonHAtoms) 2.520305 h(2.57858-NumNonHBonds) -0.564690 h(NumMultBonds-1.85275) -0.370480 h(NumRotBonds-2.19722) -2.753687 h(2.19722-NumRotBonds) 0.123978 h(NumAromaticBonds-2.48491) -1.453716 h(NumNitrogen-0.584815) 8.239716 h(0.584815-NumNitrogen) -1.542868 h(NumOxygen-1.38629) 3.304643 h(1.38629-NumOxygen) -0.620413 h(NumChlorine-0.46875) -50.431489 h(HydrophilicFactor- -0.816625) 0.237565 h(-0.816625-HydrophilicFactor) -0.370998 h(SurfaceArea1-1.9554) 0.149166 h(SurfaceArea2-4.66178) -0.169960 h(4.66178-SurfaceArea2) -0.157970 Selected 38 of 47 terms, and 30 of 228 predictors Importance: NumNonHAtoms, MolWeight, SurfaceArea2, SurfaceArea1, FP142, ... Number of terms at each degree of interaction: 1 37 (additive model) GCV 0.3877448 RSS 312.877 GRSq 0.907529 RSq 0.9213739
在此推导中,h(·)是铰链函数。 在给出的结果中,当分子量小于5.77508时,组分h(MolWeight-5.77508)等于零(如图7.3的上部所示)。 反射的铰链功能的形式为h(5.77508-MolWeight)。
Earth包中的plotmo函数可用于构建类似于图2所示的图。 7.5。 您可以使用train通过外部重采样配置模型。 以下代码重现了图5中所示的结果。 7.4:
> # - > marsGrid <- expand.grid(.degree = 1:2, .nprune = 2:38) > # > set.seed(100) > marsTuned <- train(solTrainXtrans, solTrainY, + method = "earth", + # - + tuneGrid = marsGrid, + trControl = trainControl(method = "cv")) > marsTuned 951 samples 228 predictors No pre-processing Resampling: Cross-Validation (10-fold) Summary of sample sizes: 856, 857, 855, 856, 856, 855, ... Resampling results across tuning parameters: degree nprune RMSE Rsquared RMSE SD Rsquared SD 1 2 1.54 0.438 0.128 0.0802 1 3 1.12 0.7 0.0968 0.0647 1 4 1.06 0.73 0.0849 0.0594 1 5 1.02 0.75 0.102 0.0551 1 6 0.984 0.768 0.0733 0.042 1 7 0.919 0.796 0.0657 0.0432 1 8 0.862 0.821 0.0418 0.0237 : : : : : : 2 33 0.701 0.883 0.068 0.0307 2 34 0.702 0.883 0.0699 0.0307 2 35 0.696 0.885 0.0746 0.0315 2 36 0.687 0.887 0.0604 0.0281 2 37 0.696 0.885 0.0689 0.0291 2 38 0.686 0.887 0.0626 0.029 RMSE was used to select the optimal model using the smallest value. The final values used for the model were degree = 1 and nprune = 38. > head(predict(marsTuned, solTestXtrans)) [1] 0.3677522 -0.1503220 -0.5051844 0.5398116 -0.4792718 0.7377222
两个函数用于评估MARS模型中每个预测变量的重要性:来自Earth包的evimp和来自插入符号包的varImp(第二个调用第一个):
> varImp(marsTuned) earth variable importance only 20 most important variables shown (out of 228) Overall MolWeight 100.00 NumNonHAtoms 89.96 SurfaceArea2 89.51 SurfaceArea1 57.34 FP142 44.31 FP002 39.23 NumMultBond s 39.23 FP204 37.10 FP172 34.96 NumOxygen 30.70 NumNitrogen 29.12 FP083 28.21 NumNonHBonds 26.58 FP059 24.76 FP135 23.51 FP154 21.20 FP207 19.05 FP202 17.92 NumRotBonds 16.94 FP085 16.02
这些结果的缩放范围为0到100,与表中给出的结果不同。 7.1(表7.1中显示的模型未经历完整的生长和截断过程)。 请注意,紧随其后的几个变量对于模型而言意义不大。
SVM,支持向量法
SVM模型的实现包含在多个R.包中,Chang和Lin(Chang和Lin,2011年)使用e1071包中的svm函数来使用LIBSVM库的接口进行回归。 kernlab软件包中包含用于Karatzogl回归的SVM模型的更完整实现(Karatzoglou等,2004),其中包括用于回归模型的ksvm函数和大量核函数。 默认情况下,使用径向基函数。 如果成本和核参数值已知,则可以按以下方式执行模型的近似:
> svmFit <- ksvm(x = solTrainXtrans, y = solTrainY, + kernel ="rbfdot", kpar = "automatic", + C = 1, epsilon = 0.1)
为了估计σ,使用了自动分析。 由于y是一个数值向量,因此该函数显然近似于回归模型(而不是分类模型)。 您可以使用其他内核函数,包括多项式(kernel =“ polydot”)和线性函数(kernel =“ vanilladot”)。
如果值未知,则可以通过重新采样来估计它们。 在训练中,方法参数的“ svmRadial”,“ svmLinear”或“ svmPoly”值选择不同的内核函数:
> svmRTuned <- train(solTrainXtrans, solTrainY, + method = "svmRadial", + preProc = c("center", "scale"), + tuneLength = 14, + trControl = trainControl(method = "cv"))
tuneLength参数使用14个默认值。

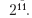
σ的默认估计是通过自动分析执行的。
> svmRTuned 951 samples 228 predictors Pre-processing: centered, scaled Resampling: Cross-Validation (10-fold) Summary of sample sizes: 855, 858, 856, 855, 855, 856, ... Resampling results across tuning parameters: C RMSE Rsquared RMSE SD Rsquared SD 0.25 0.793 0.87 0.105 0.0396 0.5 0.708 0.889 0.0936 0.0345 1 0.664 0.898 0.0834 0.0306 2 0.642 0.903 0.0725 0.0277 4 0.629 0.906 0.067 0.0253 8 0.621 0.908 0.0634 0.0238 16 0.617 0.909 0.0602 0.0232 32 0.613 0.91 0.06 0.0234 64 0.611 0.911 0.0586 0.0231 128 0.609 0.911 0.0561 0.0223 256 0.609 0.911 0.056 0.0224 512 0.61 0.911 0.0563 0.0226 1020 0.613 0.91 0.0563 0.023 2050 0.618 0.909 0.0541 0.023 Tuning parameter 'sigma' was held constant at a value of 0.00387 RMSE was used to select the optimal model using the smallest value. The final values used for the model were C = 256 and sigma = 0.00387.
finalModel子对象包含由ksvm函数创建的模型:
> svmRTuned$finalModel Support Vector Machine object of class "ksvm" SV type: eps-svr (regression) parameter : epsilon = 0.1 cost C = 256 Gaussian Radial Basis kernel function. Hyperparameter : sigma = 0.00387037424967707 Number of Support Vectors : 625 Objective Function Value : -1020.558 Training error : 0.009163
作为参考向量,模型使用了训练集的625个数据点(即训练集的66%)。
kernlab软件包包含用于在rvm函数中进行回归的RVM模型的实现。 它的语法与ksvm示例中介绍的语法非常相似。
KNN方法
卡伦包knnreg近似于KNN回归模型; 火车功能将模型设置为K:
> # . > knnDescr <- solTrainXtrans[, -nearZeroVar(solTrainXtrans)] > set.seed(100) > knnTune <- train(knnDescr, + solTrainY, + method = "knn", + # + # + preProc = c("center", "scale"), + tuneGrid = data.frame(.k = 1:20), + trControl = trainControl(method = "cv"))
关于作者:
Max Kun是辉瑞全球(Pfizer Global)统计非临床研究与开发部门的负责人。 他从事预测模型已经超过15年,是R语言的多个专业软件包的作者,实践中的预测建模涵盖了预测的各个方面,从数据预处理,数据拆分和基本原理的关键阶段开始
模型设置。 建模的所有阶段均在实际示例中考虑。
从现实生活中,每一章都在R中提供了详细的代码。
凯杰·约翰逊(Kjell Johnson )从事药物研究的统计和预测模型领域已有十多年了。 专注于预测建模的公司Arbor Analytics的联合创始人; 此前曾担任辉瑞全球统计研究与开发部门的负责人。 他的科学工作致力于统计方法论和学习算法的应用和开发。
»这本书的更多信息可以
在出版商的网站上找到»
目录»
摘录小贩优惠券可享受25%的折扣-
应用预测模型支付纸质版本的书后,就会通过电子邮件发送电子书。