为了不时转向中枢神经系统,我将在各个大公司(主要是圣彼得堡和莫斯科)采访DevOps的职位。 我注意到,在许多公司(在许多好的公司,例如Yandex)中,他们提出两个类似的问题:
- 什么是inode;
- 由于什么原因有可能在写入磁盘时出错(或例如:为什么磁盘空间可能用完,一个本质)。
经常会发生的事,我确信我对这个话题很了解,但是一旦我开始解释,知识差距就会变得明显。 为了系统化我的知识,填补空白而不再丢脸,我正在写这篇文章,它可能仍然派上用场。
我将“从下面开始”,即 从硬盘驱动器(闪存驱动器,SSD和其他现代设备)中,我们放弃了,例如,考虑使用20或80 GB的旧驱动器,因为块大小为512字节)。
硬盘驱动器不知道如何按字节寻址其空间,有条件地将其分为多个块。 块编号以0开头。(这被称为LBA,此处有详细信息:
en.wikipedia.org/wiki/LBA )
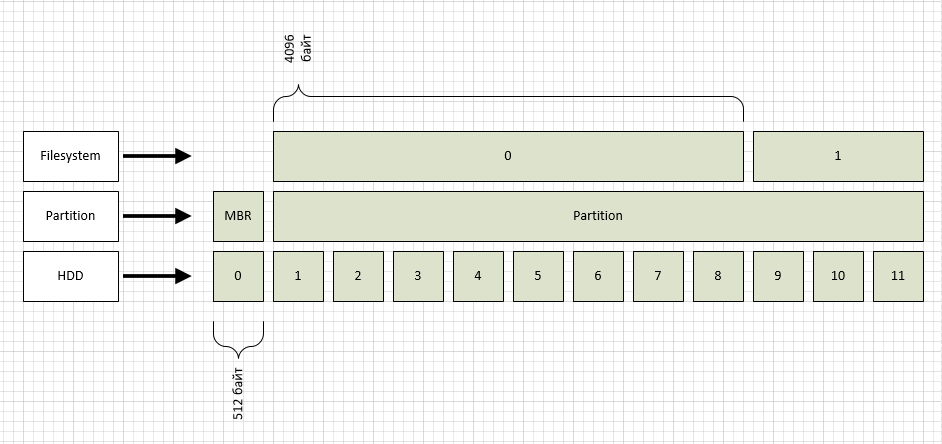
从图中可以看出,我将LBA块指定为HDD级别。 顺便说一句,您可以看到磁盘的块大小:
root@ubuntu:/home/serp
上面的级别标记了分区,一个分区代表整个磁盘(再次为简单起见)。 大多数情况下,使用两种类型的分区标记:msdos和gpt。 因此,msdos是支持高达2Tb磁盘的旧格式,而gpt是可以解决512字节块中最多1 ZB的新格式。 在我们的例子中,我们有一个msdos类型的节,从图中可以看出,这种情况下的节从1号块开始,而零节用于MBR。
在第一部分中,我创建了ext2文件系统,默认情况下,块大小为4096字节,也如图所示。 您可以看到文件系统块大小,如下所示:
root@ubuntu:/home/serp
我们需要的参数是“块大小”。
现在最有趣的是如何读取文件/ home / serp / testfile? 文件由文件系统中存储数据的一个或多个块组成。 知道文件名后,如何找到它? 读什么书?
这是inode派上用场的地方。 ext2fs文件系统具有一个“表”,其中包含有关所有索引节点的信息。 创建文件系统时设置ext2fs情况下的索引节点数。 我们在tune2fs输出的“ Inode count”参数中查看了必要的数字,即 我们有65536件。 索引节点包含我们需要的信息:所需文件的文件系统块列表。 如何找到指定文件的索引节点号?
名称和索引节点号的对应关系包含在目录中,而ext2fs中的目录是特殊类型的文件,即 也有自己的索引节点号。 为了打破这种恶性循环,在根目录中分配了一个“固定的”索引节点号“ 2”。 我们看一下2号索引节点的内容:
root@ubuntu:/
如您所见,所需的目录包含在编号为579的块中。在该目录中,我们将找到主文件夹的节点号,依此类推,直到链子,直到在serp目录中都看到了所请求文件的节点号。 如果突然有人想检查数字是否正确,并且那里是否有正确的信息,这并不困难。 我们做:
root@ubuntu:/
在输出中,您可以读取目录中的文件名。
所以我想到了一个主要问题:“由于什么原因会出现写错误”?
自然,如果文件系统中没有空闲块,就会发生这种情况。 在这种情况下可以做什么? 除了明显的“删除不必要的内容”外,还应该记住,在ext2、3和4文件系统中,还存在“保留的块数”之类的东西。 如果您看上面的清单,那么我们有这样的块“ 13094”。 这些是仅root用户可写的块。 但是如果您需要快速解决此问题,那么如何使所有人都可以使用临时解决方案,从而获得一些可用空间:
root@ubuntu:/mnt
即 默认情况下,您没有5%的磁盘空间可用于写入,并且鉴于现代磁盘的容量,它可能是数百GB。
还有什么呢? 当有空闲块但节点已结束时,可能会出现这种情况。 如果文件系统中有一堆小于文件系统块大小的文件,通常会发生这种情况。 考虑到1个inode花在1个文件或目录上,并且总共有65536个(对于此文件系统)-这种情况远非真实。 从df命令的输出中可以清楚地看到:
serp@ubuntu:~$ df -hi Filesystem Inodes IUsed IFree IUse% Mounted on udev 493K 480 492K 1% /dev tmpfs 493K 425 493K 1% /run /dev/xvda1 512K 240K 273K 47% / none 493K 2 493K 1% /sys/fs/cgroup none 493K 2 493K 1% /run/lock none 493K 1 493K 1% /run/shm none 493K 2 493K 1% /run/user /dev/xvdc1 320K 4,1K 316K 2% /var /dev/xvdb1 64K 195 64K 1% /home /dev/xvdh1 4,0M 3,1M 940K 78% /var/www serp@ubuntu:~$ df -h Filesystem Size Used Avail Use% Mounted on udev 2,0G 4,0K 2,0G 1% /dev tmpfs 395M 620K 394M 1% /run /dev/xvda1 7,8G 2,9G 4,6G 39% / none 4,0K 0 4,0K 0% /sys/fs/cgroup none 5,0M 0 5,0M 0% /run/lock none 2,0G 0 2,0G 0% /run/shm none 100M 0 100M 0% /run/user /dev/xvdc1 4,8G 2,6G 2,0G 57% /var /dev/xvdb1 990M 4,0M 919M 1% /home /dev/xvdh1 63G 35G 25G 59% /var/www
从/ var / www部分可以清楚地看到,文件系统中可用块的数量和可用节点的数量相差很大。
万一我用尽inode,我不会告诉你任何咒语,因为 他们不是(如果不对,请告诉我)。 因此,对于小文件繁多的部分,应正确选择文件系统。 因此,例如在btrfs中,inode不能结束,因为 必要时动态创建新的。