我们都喜欢并在辅助副本上使用可用性组的惊人功能,例如完整性检查,备份等。
实际上,无法将此信息保存在副本数据库中仍然令人头疼(考虑CDC之类的事情甚至会更加不舒服)。
但是,别再抱怨了,这里的主要思想是:亲爱的Microsoft,让我们使用我们的副本来更新统计信息……好吧,并对它们进行更多的处理。
总有一种方法或类似的方法
*几乎总是让我们列出企业版MS SQL Server上可能的解决方案的已知基本详细信息:
- 我们可以使副本可读并从其中读取数据(不是您总是必须这样做,但是如果您真的知道自己在做什么……);
- 我们可以将对象复制到Tempdb(是的,您的多TB表可能不太适合这种操作),或复制到另一个可写的数据库。
- 我们可以将结果写到两个副本都可以访问的共享文件夹中(让它成为文件共享中的文本文件);
- 我们可以从SQL Server将统计信息导出为Blob;
- 我们可以将下载的Blob导入统计信息。
来做吧
我在带有SQL Server 2017的一对虚拟机上有一个测试AG(可以使用任何版本),我将创建一个简单的表来更新统计信息。
这是创建表并将一百万行插入其中的脚本:
DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT t.RN, t.RN FROM ( SELECT TOP (1000000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
现在让我们为列c2创建ST_SampleDataTable_C2统计信息
CREATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2);
然后,我将插入1000行,这将非常重要,因此,我确实需要更新统计信息。
set nocount on; INSERT INTO dbo.SampleDataTable WITH (TABLOCK) SELECT 10000000 + t.RN, 999999999 FROM ( SELECT TOP (1000) ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) RN FROM sys.objects t1 CROSS JOIN sys.objects t2 CROSS JOIN sys.objects t3 CROSS JOIN sys.objects t4 CROSS JOIN sys.objects t5 ) t OPTION (MAXDOP 1);
现在我有1000个条目,其中的C2列中的值是999999999。这绝对意味着升序密钥问题,我确实需要更新副本上的统计信息,以便不对主服务器进行繁琐的计算和阻止他为客户服务。
使用旧的DBCC SHOW_STATISTICS命令,让我们检查一下统计信息。
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
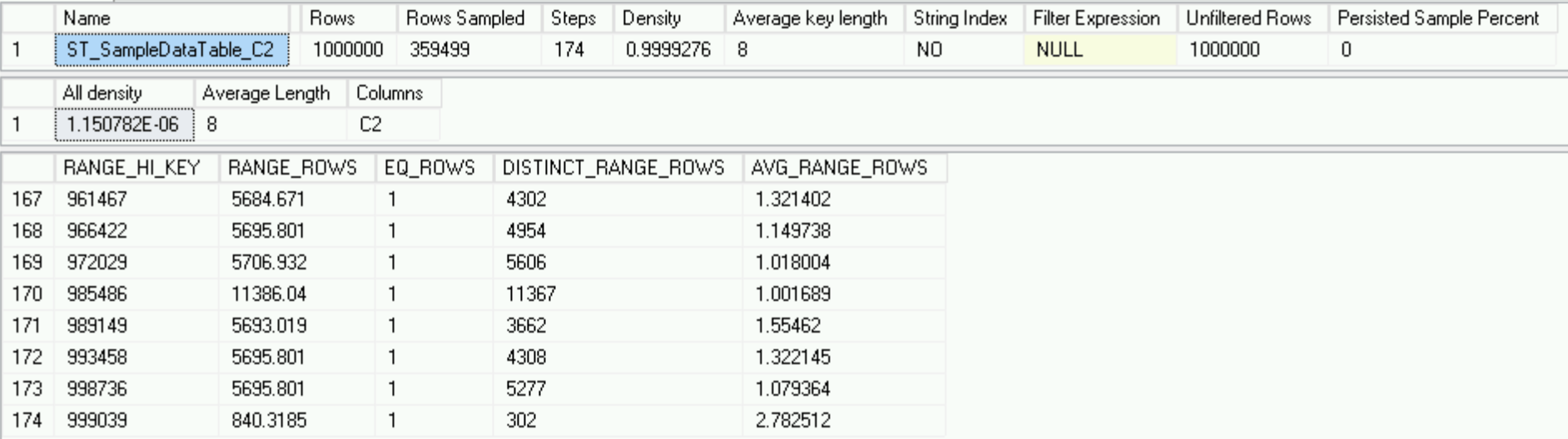
在我们的王国中,一切都完美无缺,我们的统计数据也处于完美的状态,尽管它只考虑了100万行,并且没有那么有害的1000行,最终这些行应成为这些统计的一部分。
另外,我们可以使用DBCC SHOW_STATISTICS命令的STATS_STREAM参数查看统计信息流:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

博客已经写了好几年了,但这只是一个字符集,但是我仍然不确定这是否是一个完整记录的功能(尽管它从未使人们停止使用它)。
提示
让我们将副本上的表复制到tempdb(尽管我的AG处于同步模式,但同样的事情也可以异步完成,只是数据可能会稍有延迟)。
use TempDB; DROP TABLE IF EXISTS dbo.SampleDataTable; CREATE TABLE dbo.SampleDataTable ( C1 BIGINT NOT NULL, C2 BIGINT NOT NULL, CONSTRAINT PK_SampleDataTable PRIMARY KEY (C1) ); INSERT INTO dbo.SampleDataTable SELECT C1, C2 FROM AvGroupDb.dbo.SampleDataTable;
现在,我们准备通过对副本数据库中的tempdb进行全面扫描来更新统计信息。
use TempDB; UPDATE STATISTICS ST_SampleDataTable_C2 ON dbo.SampleDataTable(C2) WITH FULLSCAN;
(
译者注-Nico忘记创建统计信息,并使用了UPDATE STATISTICS操作的错误语法,它应该是CREATE而不是UPDATE,即不是更新统计信息而是创建统计信息 )
返回到DBCC SHOW_STATISTICS并查看它:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2')
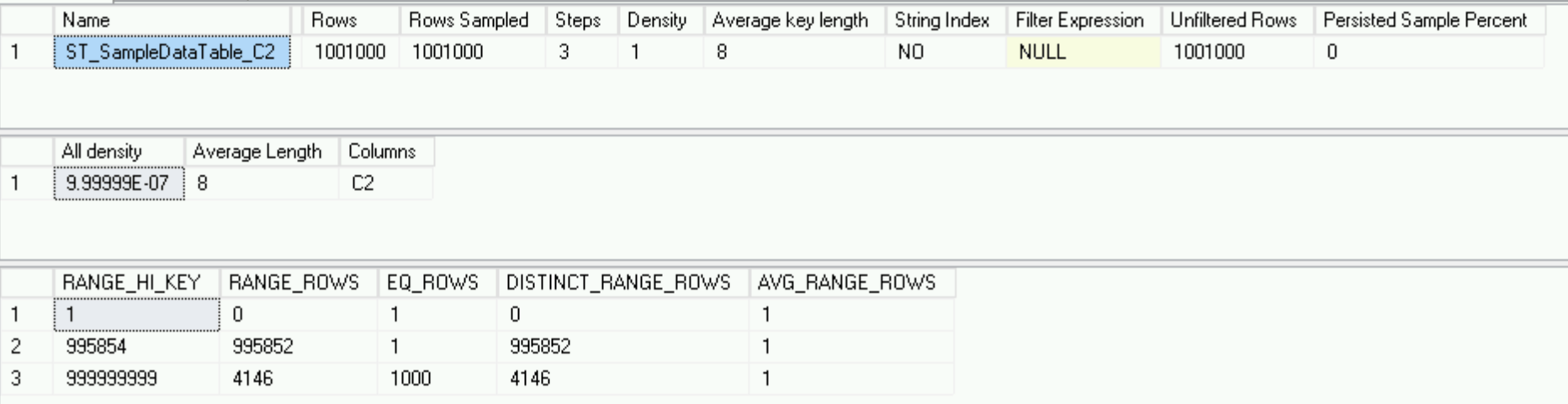
它看起来与主服务器完全不同-仅3行,而178条,但是它完美地描述了数据-我们有一百万条唯一的行和1000条具有相同C2列值的行-直方图越好。
让我们看一下统计流程:
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2') WITH STATS_STREAM;

您无需成为天才就可以注意到该流看起来完全不同-我们在更新的流中看到了5689A0C6字符,而在原始流中,我们看到了所有这些零之间的EDF10EB4。
让我们集中精力将数据导出到SQL Server外部某个文本文件,并借助出色的BCP命令来完成此操作,该命令要求启用CMDSHELL(注意:您可能不希望在生产服务器上使用此命令):
EXEC xp_cmdshell 'BCP "DBCC SHOW_STATISTICS(''AvGroupDb.dbo.SampleDataTable'', ''ST_SampleDataTable_C2'') WITH STATS_STREAM" queryout \\SharedServer\Tempdb\stats.txt -c -T';
这是stats.txt文件在我们的球中的大小:

只有几千字节! 易于传输,易于管理。
返回主服务器
在主服务器上,我们需要创建一个临时表来存储统计信息流,然后才能在主SampleDataTable表中更新统计信息流(实际上,我们可以将此表扩展为许多数据库,表,统计信息)。
CREATE TABLE dbo.TempStats( Stats_Stream VARBINARY(MAX), Rows BIGINT, DataPages BIGINT );
让我们将数据从文本文件导入到新的临时表中,并查看导入的内容:
BULK INSERT dbo.TempStats FROM '\\SharedServer\Tempdb\stats.txt' SELECT * FROM dbo.TempStats;

我们可以看到与在副本上计算出的数据相同的数据,但是此数据已经在我们的主服务器上,剩下要做的就是更新表中的统计信息。 可以使用带有STATS_STREAM = ...参数的UPDATE STATISTICS操作来执行此操作。
DECLARE @script NVARCHAR(MAX) SELECT @script = 'UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM = ' + CONVERT(nvarchar(max), [Stats_Stream],1) FROM dbo.TempStats PRINT @script; EXECUTE sp_executesql @script;
该脚本读取上面的导入值(是的,我知道-我为一个表做了此示例,并且没有打扰多个统计信息,表,数据库等),生成UPDATE STATISTICS语句,将其显示在屏幕上,最后,实现它。
这是我在输出中得到的:
UPDATE STATISTICS dbo.SampleDataTable(ST_SampleDataTable_C2) WITH STATS_STREAM =
在主服务器上运行DBCC SHOW_STATISTICS可得到我所希望的结果-与我们在副本服务器上看到的结果相同。 圆是封闭的。
DBCC SHOW_STATISTICS('dbo.SampleDataTable', 'ST_SampleDataTable_C2');
这个故事真正令人敬畏的部分是带有统计信息的对象的大小非常小,我们可以非常轻松/即时地将其传输到主服务器。
不太基本的场景。
如果在相同副本之间有多个AG,其中一个副本是一个AG中的主副本,另一个是第二个AG中的主副本,则可以将BLOB数据插入副本之间的数据流中,并使用传输的数据添加一个小型数据库。
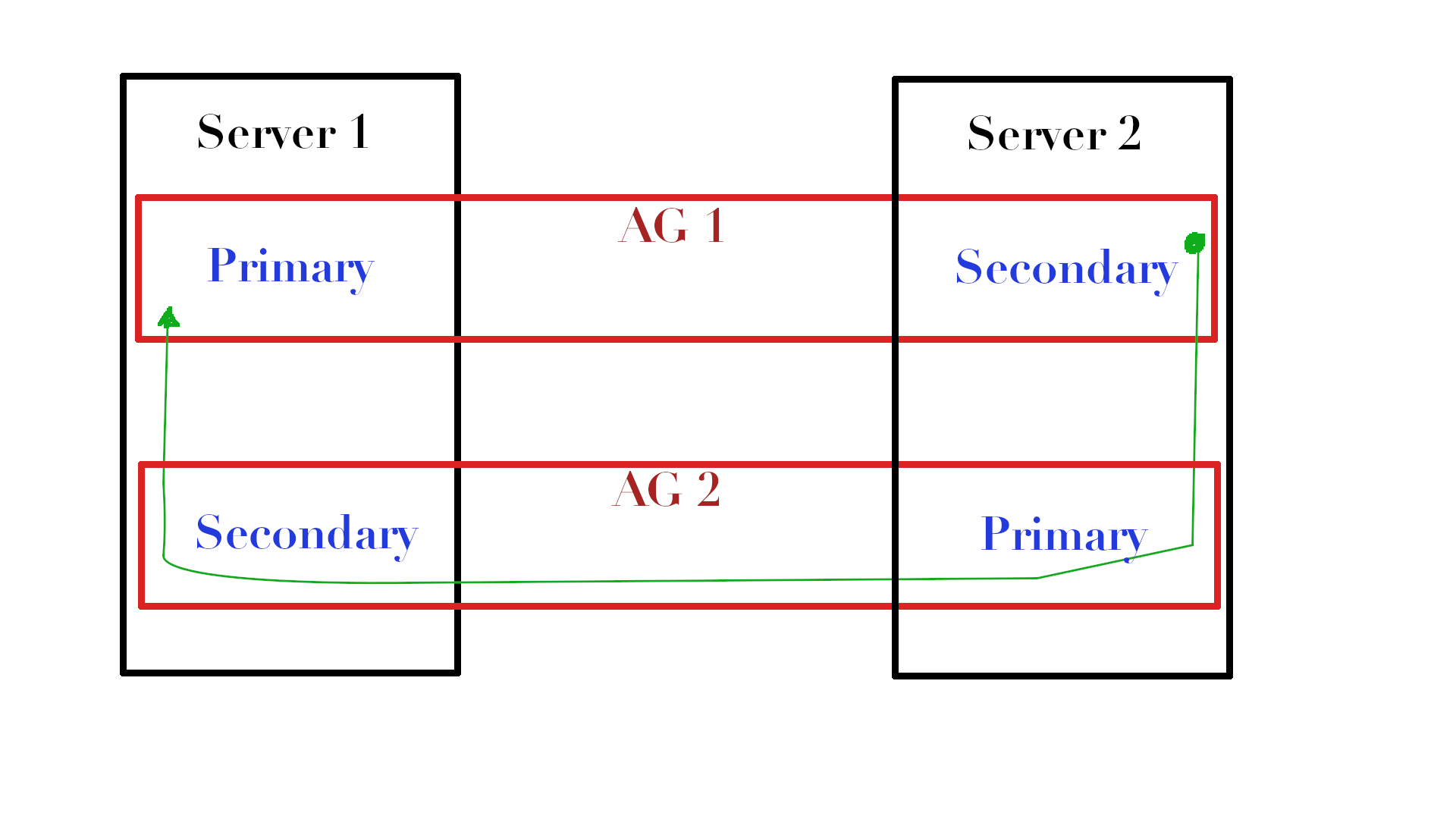
看图片。 如果我们有两个位于不同服务器上的AG(AG1和AG2),并且我们要在AG1的Server1上有一个特定的表,要为其更新统计信息,则可以在Server2上复制此表(我们将其称为dbo.MyTable )在tempdb中进行更新,并使用AG2将具有统计信息流的对象发送回Server1,在这里只需将统计信息从该流导入到我们需要的统计信息中即可。
是的,我知道,这听起来令人迷惑,但只是将其视为提供结果的反馈渠道,而不是将其放在文件中。
值得怀疑的地方
您可能有一些异议,例如:
- 如果可以在主服务器上安全地进行复制,为什么还要在副本上进行复制呢? (好吧,想法是卸载主服务器)
- 但是我们可能不加载副本(是的,但是如果它空闲,这就是为什么我们要使用它的功能)
- 而且我们无法以某种方式在主服务器上采取行动? (不,我们只是从副本中读取数据并发送回几千字节,在我们这个世纪中,千兆字节和TB听起来像是“ shtoa?”)( 请注意翻译器-通常,对于可读的副本AG, 我们可以 )
- 如果在此过程中主服务器开始自行更新统计信息,该怎么办? (在这种情况下,它可以中断第二个过程,或者使用更新的数据重新启动)。
AG反馈渠道
这是一个从副本服务器到主服务器的反馈的通道-在我们承诺同步AG中的事务之后,主服务器将等待副本服务器的确认-我认为该通道可用于实现此改进。 看一下
Simon Su在帖子中拍摄的照片。
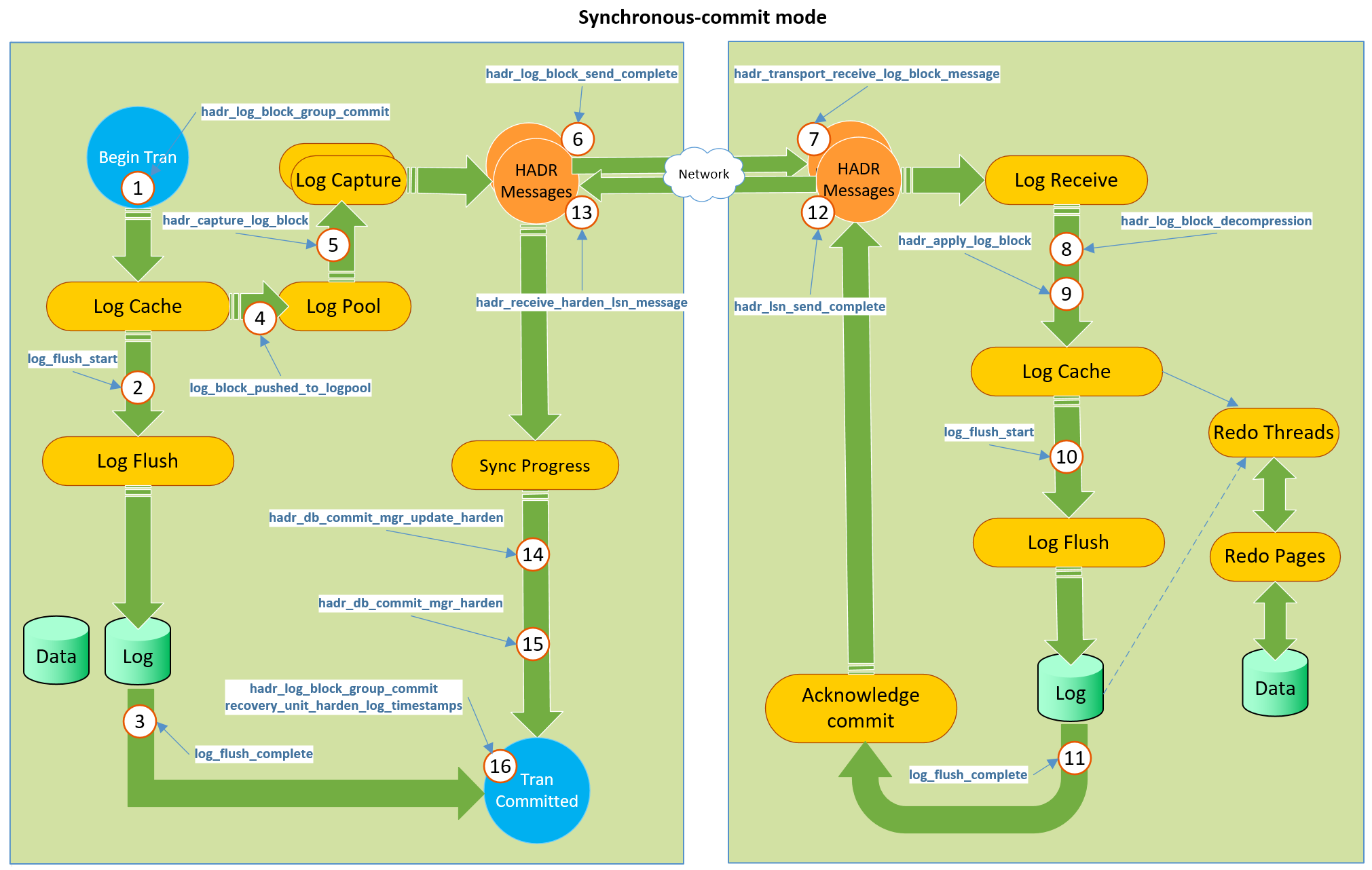
它代表了现有反馈渠道的整个机制。 副本使用步骤12及后续步骤向主服务器确认信息已保存。 在对副本重新计数之后,可以使用同一通道来发送统计信息流对象。 当然,我们不必为此使用tempdb,而是在数据库内部创建一个不应永久存储的内存中对象(查看您的“ In-Memory OLTP Schema-Only”表,或考虑Oracle中的NOLOGGING表),并且应该在操作结束时将其删除-这真的很酷。
一般思想
它不应该取决于是否同步副本-大多数时间统计信息不会每隔几秒钟更新一次,这使我们进入了想法的第二部分-调用主服务器上的更新统计信息,例如使用
UPDATE STATISTICS dbo.MyAwesomeTable(HugeImportantStatOnC17) WITH FULLSCAN, SECONDARY
SECONDARY参数指示在何处执行操作。
就像备份一样,我们应该能够在设置中指定首选副本来执行UPDATE STATISTICS(或将来进行的其他任何操作)。
我确信此功能将鼓励许多企业版用户迁移到新版本的SQL Server,这将允许在副本之间分配繁重的操作。
对于当前情况-我确切地看到了如何使用Powershell自动化此解决方案。
微软,该你了! ;)
在这里投票建议的功能。
译者注:与往常一样,我们欢迎您提供有关翻译和样式的任何建议和评论。
我通常将翻译中的主要副本称为“主要服务器”,而将次要副本称为简单副本。 也许这不是完全正确的,但是我的耳朵比msdn上的“主要”和“次要”副本所受的伤害要小。