在本文中,我们将处理数据对齐,并从站点
pwnable.kr解决第17个任务。
组织信息特别是对于那些想要学习新知识并在信息和计算机安全性的任何领域中发展的人们,我将撰写和讨论以下类别:
- PWN;
- 密码学(加密);
- 网络技术(网络);
- 反向(反向工程);
- 隐写术(Stegano);
- 搜索和利用Web漏洞。
除此之外,我将分享我在计算机取证,恶意软件和固件分析,对无线网络和局域网的攻击,进行笔测试和编写漏洞利用程序方面的经验。
为了使您可以查找有关新文章,软件和其他信息的信息,我
在Telegram中创建了一个
频道,并创建了一个
小组来讨论 ICD领域中的
所有问题 。 另外,我会亲自考虑您的个人要求,问题,建议和建议,
并会回答所有人 。
提供所有信息仅出于教育目的。 对于由于使用本文档而获得的知识和方法对某人造成的任何损害,本文档的作者不承担任何责任。
数据对齐
对齐计算机随机访问内存中的数据是内存中数据的一种特殊排列,以加快访问速度。 使用内存时,进程将使用机器字作为主体。 不同类型的处理器可以具有不同的大小:1、2、4、8等。 个字节。 将对象保存在内存中时,可能会发生某些字段超出这些字边界的情况。 与对齐数据相比,某些处理器可以处理未对齐数据的时间更长。 非复杂的处理器通常无法处理未对齐的数据。
为了更好地想象对齐和未对齐数据的模型,请考虑以下对象的示例-数据结构。
struct Data{ int var1; void* mas[4]; };
由于x32和x64处理器中的int变量的大小不是4个字节,而void *变量的值分别是4和8个字节,因此x32和x64处理器的这种结构将在内存中表示如下。

具有这种结构的X64处理器将无法工作,因为数据未对齐。 为了进行数据对齐,有必要向该结构添加另一个4字节字段。
struct Data{ int var1; int addition; void* mas[4]; };
因此,x64处理器的数据结构数据将在内存中对齐。

Memcpy工作解决方案
我们单击memcpy签名图标,并被告知需要通过SSH与密码guest连接。
连接后,我们会看到相应的横幅。
让我们找出服务器上有哪些文件,以及我们拥有的权限。

我们有一个自述文件。 阅读后,我们了解到该程序在端口9022上运行。

连接到端口9022。我们提供了一个实验-比较memcpy的慢速版本和快速版本。 然后,程序将以一定的时间间隔输入一个数字,并发出报告,以比较该功能的慢速版本和快速版本。 有一件事情:实验10,而报告-5。
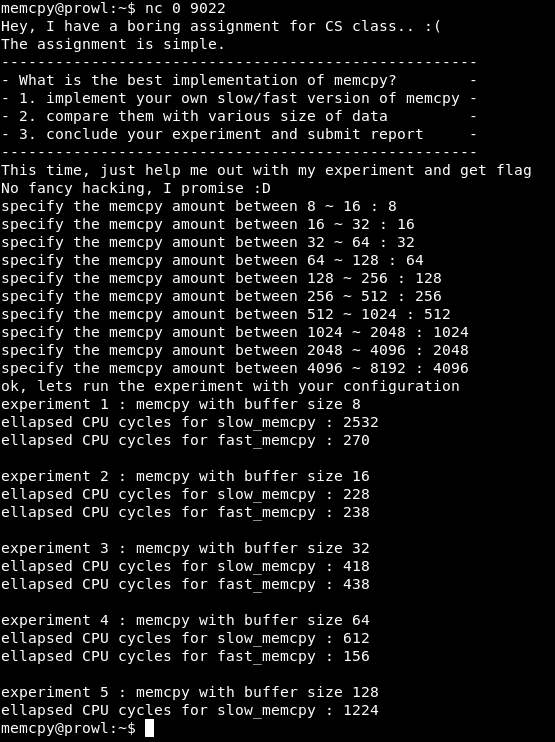
让我们整理一下原因。 在代码中找到该位置以比较结果。
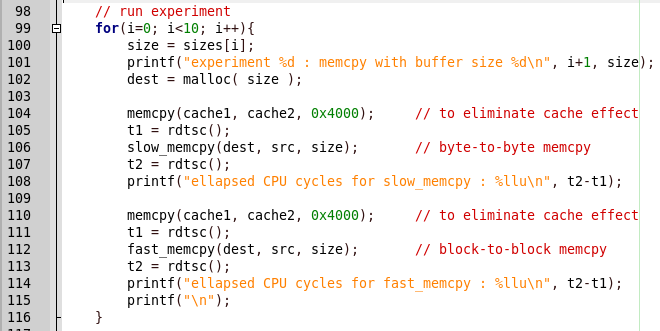
一切都很简单,首先调用slow_memcpy,然后调用fast_memcpy。 但是在程序报告中有一个关于该函数的缓慢发布的结论,当调用快速实现时,该程序将崩溃。 让我们看一下快速的实现代码。
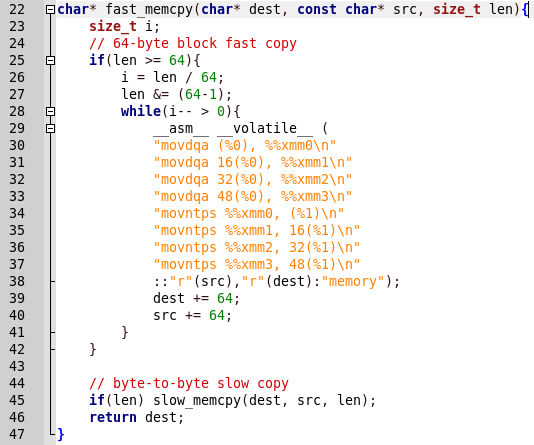
复制是使用汇编器函数完成的。 我们通过命令确定这是SSE2。 如此处所述:SSE2使用了x86体系结构中包含的八个128位寄存器(xmm0至xmm7),并引入了SSE扩展名,每个寄存器均被视为2个连续的双精度浮点值。 而且,此代码正在处理对齐的数据。


因此,使用未对齐的数据,程序可能会崩溃。 对齐是由128位(即16个字节)执行的,因此块必须等于16。我们需要找出堆上第一个块(let X)中已经有多少个字节,然后我们必须分别传输尽可能多的字节(let Y),以便( X + Y)%16为0。
由于所有操作占用的堆块都是2的倍数,因此将X迭代为2、4、8等。 直到16。
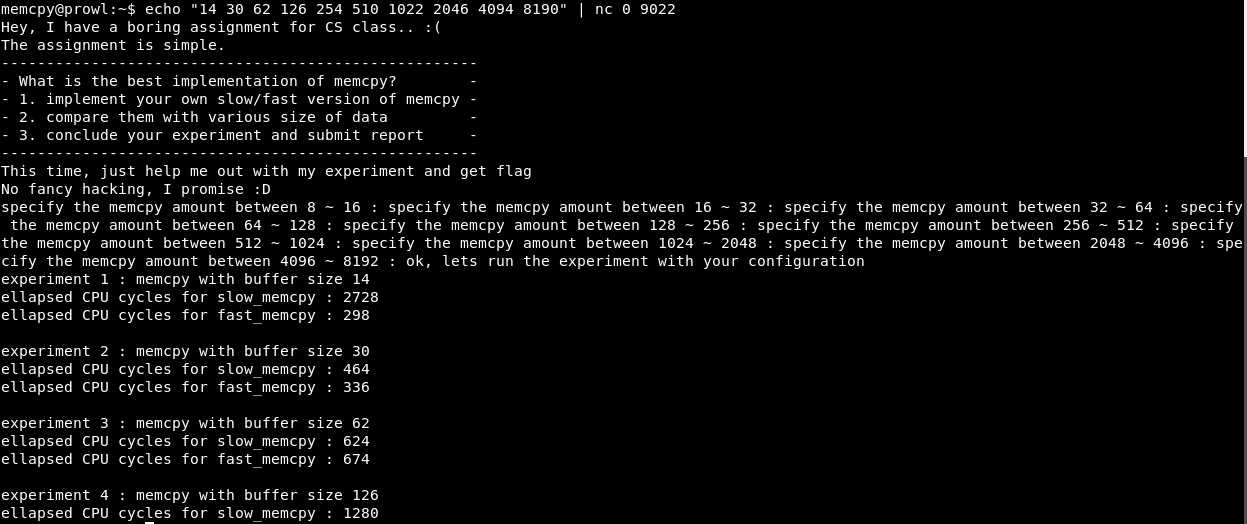
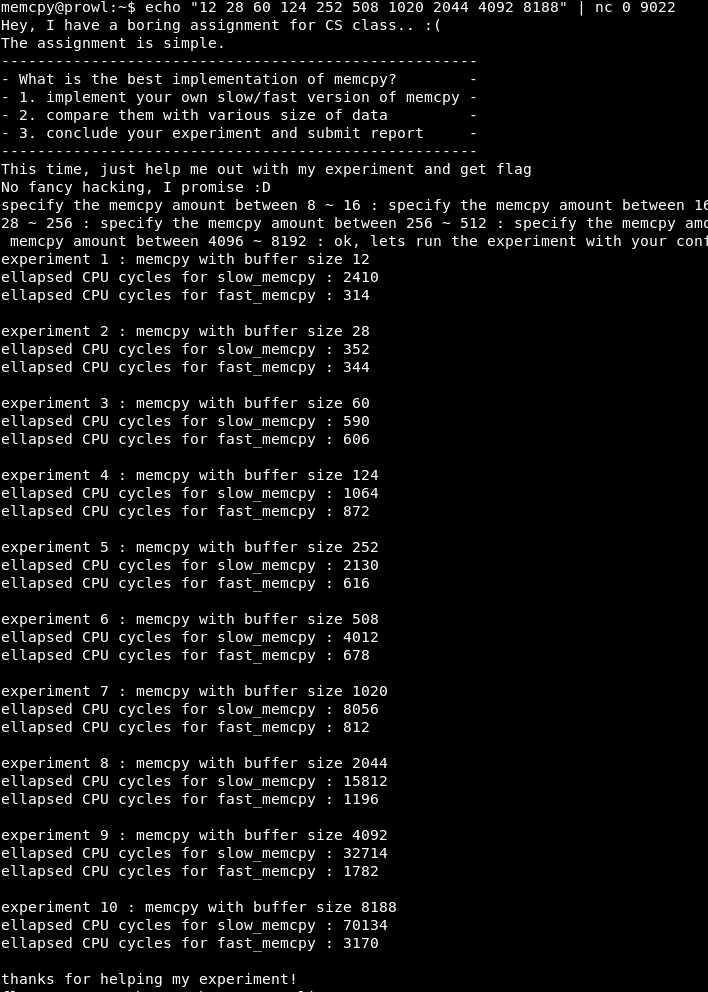
如您所见,在X = 4时,程序成功运行。

我们得到外壳,读取标志,得到10分。
您可以通过
Telegram加入我们。 下次我们将处理堆溢出。