
万维网是数据的海洋。 在这里,您几乎可以看到您感兴趣的任何信息。 但是,从互联网“拉”该信息已经更加困难。 有几种获取数据的方法,网络抓取是其中一种。
什么是网页抓取? 简而言之,它是一项允许您从HTML页面检索数据的技术。 使用抓取时,无需复制粘贴必要的信息或将其从屏幕传输到记事本。 信息将以方便您的形式出现在您的计算机上。
在网站Kinopoisk.ru的示例上进行网络爬网
为自己设定目标是一个好主意,以免刮do。 我认为这将是Kinopoisk.ru和IMDB.com上电影收视率的比较,以及各类型电影的平均收视率 。 为了进行分析,拍摄了从2010年到2018年发行的电影,票数至少为500。
首先,加载我们需要的库:
# library(rvest) library(selectr) library(xml2) library(jsonlite) library(tidyverse)
接下来,我得到一年中满足选择条件的电影数量(超过500票)。 这样做是为了找出包含数据的页面总数并“生成”指向它们的链接,因为 链接的结构相似。
# 2018 url <- "https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/1/#results"
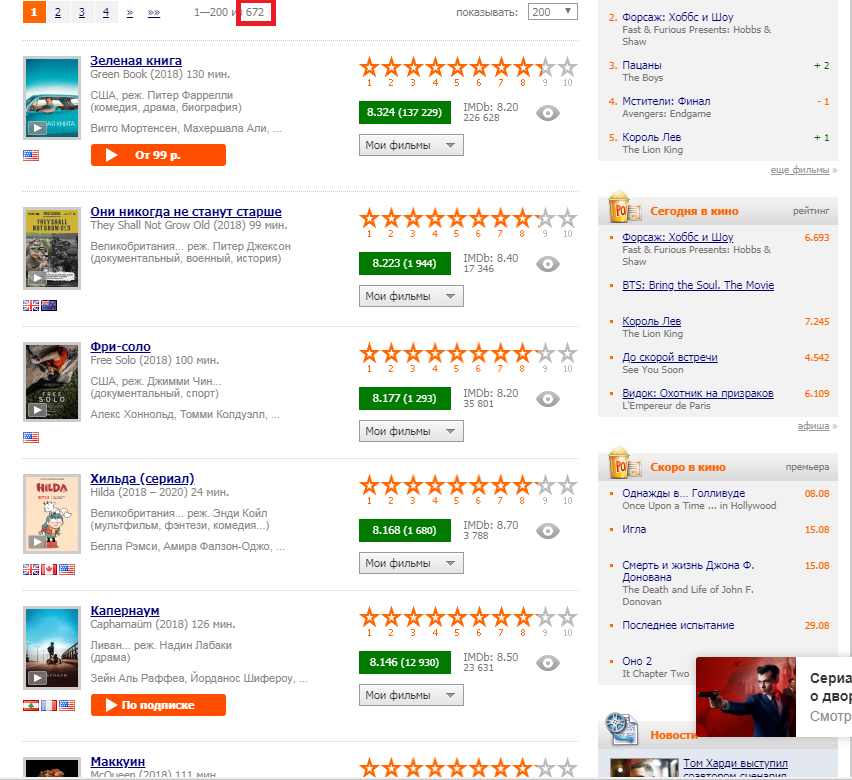
我们的任务是“拉出”数字672,在图中用红色矩形突出显示。 为此,我们需要网页抓取。
Kinopoisk.ru网站使用rvest软件包抓取网页
首先,我们需要“读取”收到的URL。 为此,请使用read_html()包的read_html()函数。
# XML HTML webpage <- read_html(url)
然后,使用rvest软件包的功能rvest我们首先“提取” HTML文档中我们需要的部分( html_nodes()函数),然后从这一部分中以对我们方便的形式提取我们所需的信息( html_text() , html_table()函数, html_attr()其他)
但是,我们如何理解需要提取的元素呢? 为此,我们必须将鼠标悬停在我们感兴趣的信息上,单击LMB并选择“查看代码”。 在我们的例子中,我们得到以下图片:
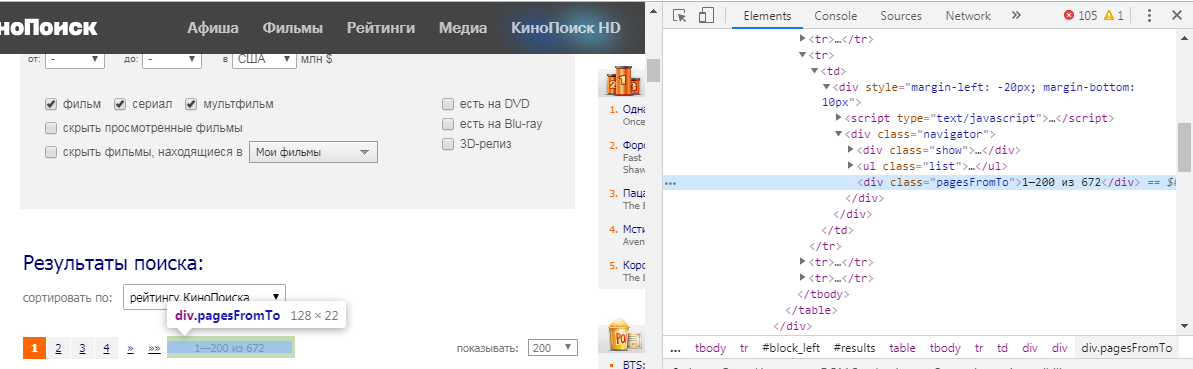
html_nodes()函数的格式为html_nodes(x, css) 。 x是先前定义的网页,但是在CSS中,我们编写了id或element类。 在我们的例子中是:
number_html <- html_nodes(webpage, ".pagesFromTo")
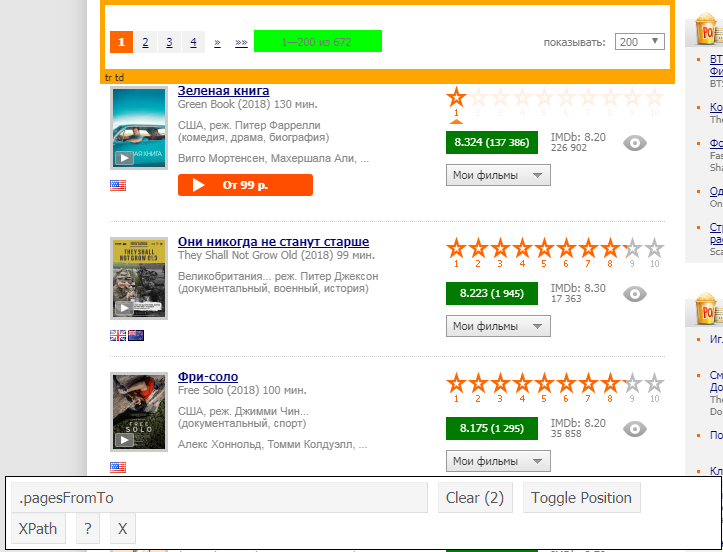
另外,要“检测”所需的元素,可以使用selectorGadget扩展,它显示了我们需要明确输入的内容:
接下来,使用html_text函数,从所选元素中提取文本部分:
number <- html_text(number_html) [1] "1—50 672" "1—50 672"
我们从Kinopoisk的HTML页面获得了所需的号码,但是现在我们需要“清除”它。 这是刮擦的标准过程,因为很少需要我们需要的形式的元素。
由于影片的总数在页面的顶部和底部显示,并且它们的css选择器完全相同,因此我们得到了2个相同的元素。 因此,对于初学者来说,我们删除了多余的元素:
number <- number[1] [1] "1—50 672"
接下来,我们需要去除向量中达到672的部分。您可以用不同的方法来完成此操作,但是所有方法的基础都是编写正则表达式。 在这种情况下,我用一个空格“替换”了“ 1-50 of”部分(可以使用str_remove代替str_replace ),然后删除多余的空格( str_trim函数),最后将向量从字符转换为数字类型。 在输出中,我得到672。确实如此,2018年有很多电影在Kinopoisk上获得了500多个用户投票。
number <- str_replace(number, ".{2,}", "") number <- as.numeric(str_trim(number)) [1] 672
接下来我们要做什么? 如果您浏览一下Kinopoisk上的页面,您会发现搜索页面的地址具有相同的结构,只是数量不同。 因此,为了避免每次都手动输入页面地址,我们将计算页面数并“生成”所需的地址数。 这样做是这样的:
# page_number <- ceiling(number/50) # page <- sapply(seq(1:page_number), function(n){ list_page <- paste0("https://www.kinopoisk.ru/top/navigator/m_act[year]/2018/m_act[rating]/1%3A/order/rating/page/", n, "/#results") })
输出是14个地址。 在此示例中, ceiling函数将数字四舍五入为BIG整数。
然后,我们将lapply函数用于页面地址的输入,该函数从Kinopoisk页面“提取”有关电影的名称,等级,票数和主要类型(最多3个)的信息。 功能代码可以在Github上的存储库中找到。
结果,我们得到了一张包含8111张电影的桌子。
值得注意的是Sys.sleep函数的使用。 使用它,您可以设置表达式之间的延迟时间。 为什么需要这个? 如果您希望在一年内收到信息,则没有必要。 但是,如果您对大量的电影/年感兴趣,那么在经过一定数量的请求后,Kinopoisk会认为您是机器人,并且您会收到一份空白列表。 为避免这种情况,您必须输入延迟时间。
同样, “废弃”网站IMDB.com。
资料分析
我们有两个表格,一个关于IMDB电影的信息,另一个来自Kinopoisk。 现在我们需要将它们结合起来。 我们将根据“名称”和“年份”列进行合并。 为了减少名称中出现的差异,即使在抓取阶段,我也删除了所有标点符号,并将字母转换为小写。 结果,在所有连接和删除之后,我们从两个站点都获得了3450部具有我们所需信息的电影。
我对两个站点上电影的收视率差异感兴趣,因此我们将创建DELTA变量,这是IMDB和Kinopoisk估算值之间的差异。 如果DELTA为正,则IMDB分数较高;如果为负,则较低。
首先,为DELTA指标构建直方图:
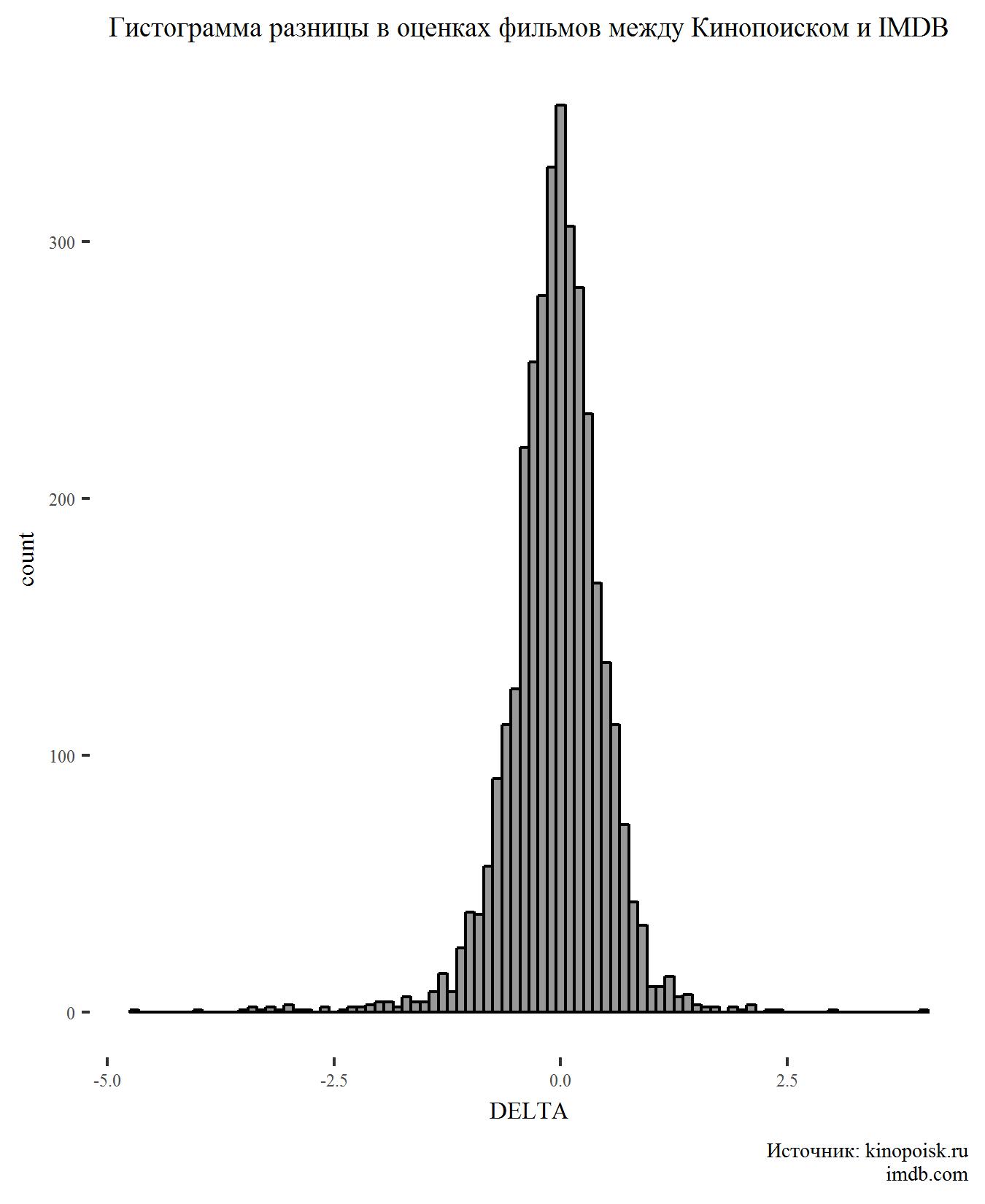
图表上没有什么奇怪的。 收视率的差异具有正态分布,并且在零附近出现峰值,这表明这两个站点的用户通常会同意电影的收视率。
收敛,但不完全一致。 通过两个独立样本的t检验,我们可以说,对Kinopoisk的评分较高,并且该差异具有统计学意义(p值<0.05)。
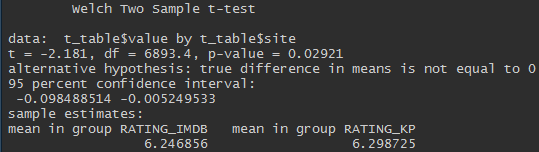
尽管差异很大,但差异很小。
接下来,让我们看看评分的差异如何取决于票数。
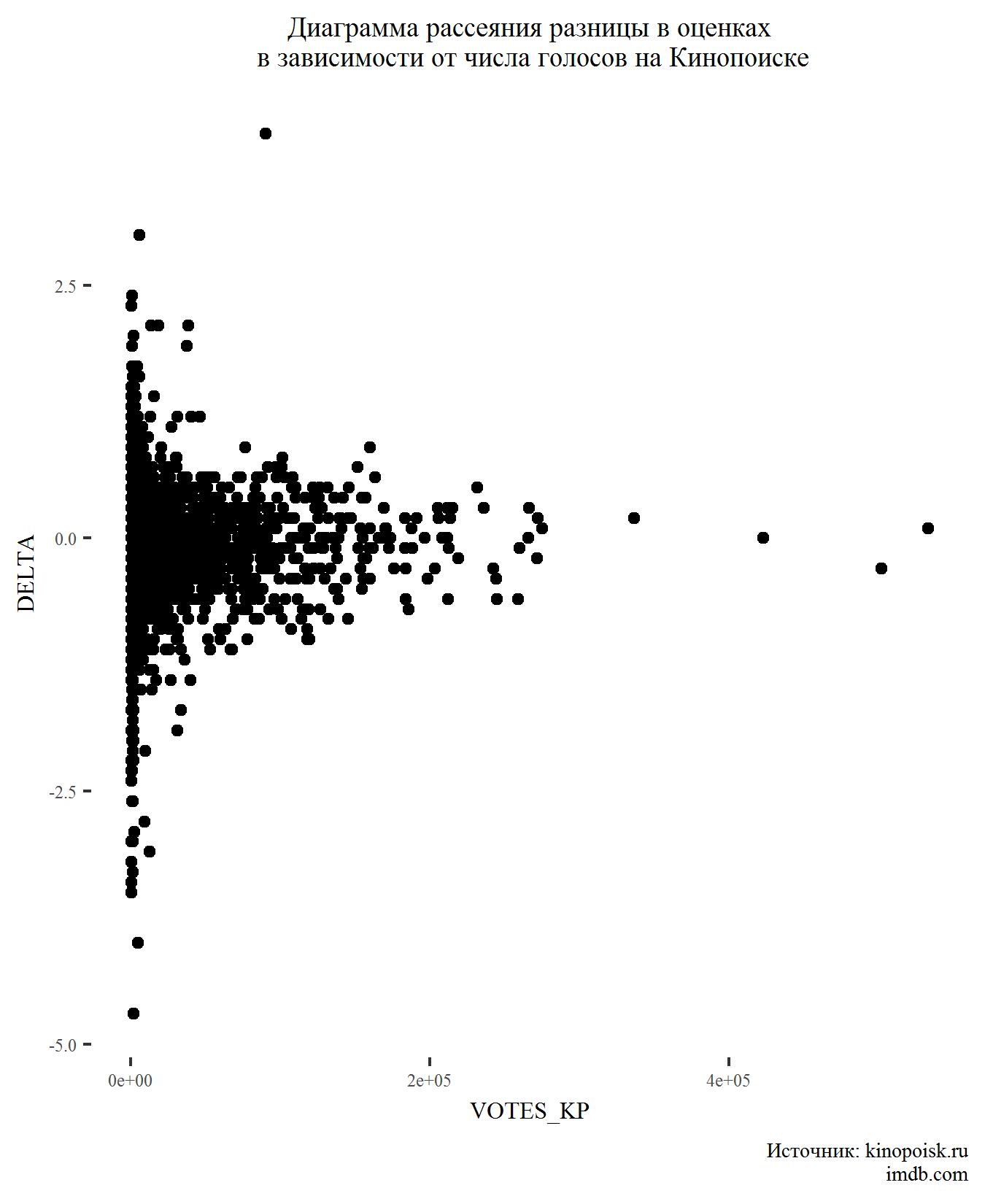
这里也没有什么意外的。 票数很高的电影通常收视率差异很小。
现在让我们继续按类型评估电影。 值得一提的是,一部电影最多可以有三种类型,但只有一部级别,因此一部电影可以“进入考验”,喜剧和情节剧。
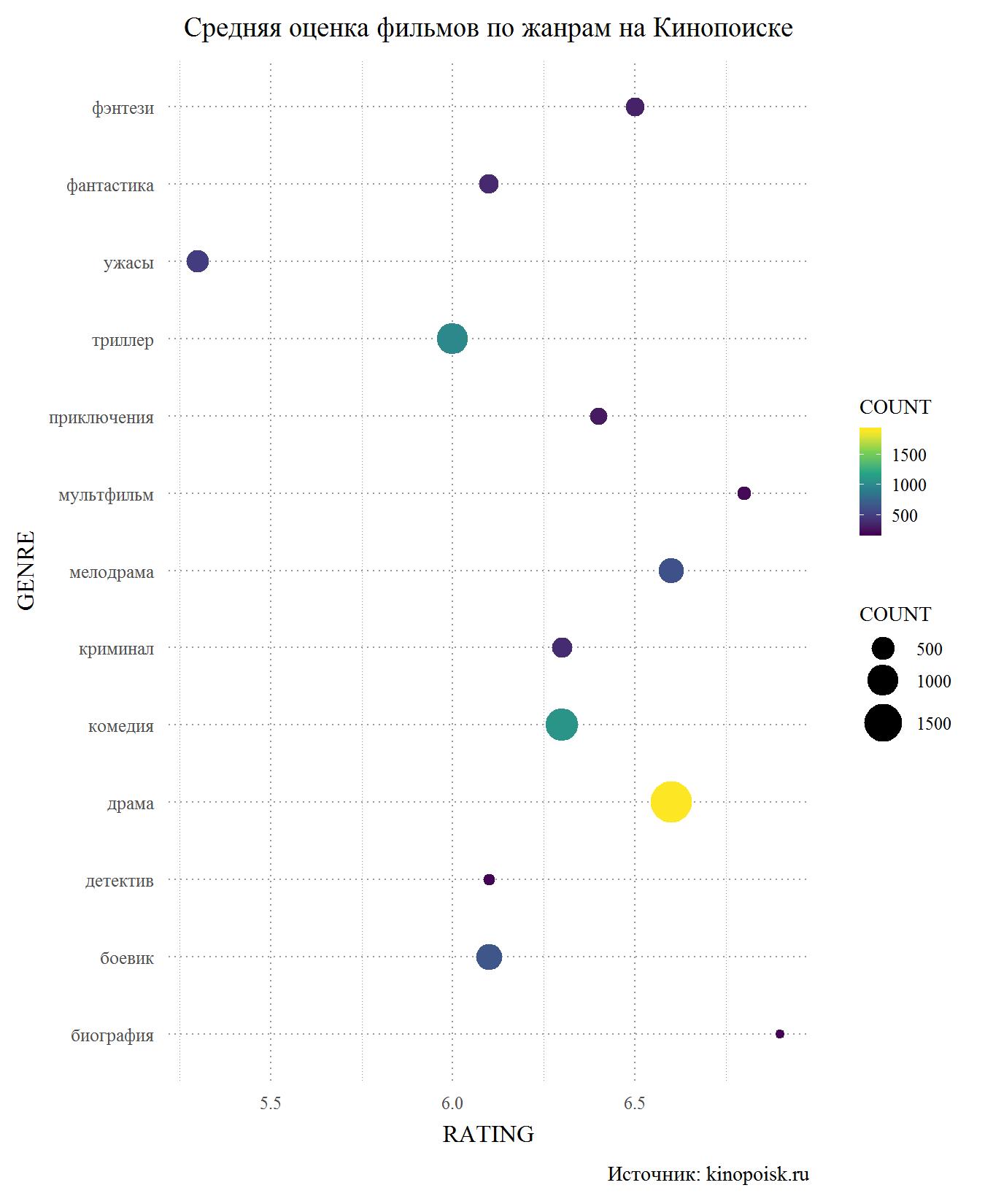
让我们从Kinopoisk开始。 在数据库中至少有150种露面的流派中,恐怖是明显的局外人。 低用户也对恐怖片,动作侦探以及科幻小说感到惊讶。 另一方面,Kinopoisk上的情节剧电影表现出色,平均收视率高于6.5,仅次于卡通片和传记片,后者在数据库中要小得多
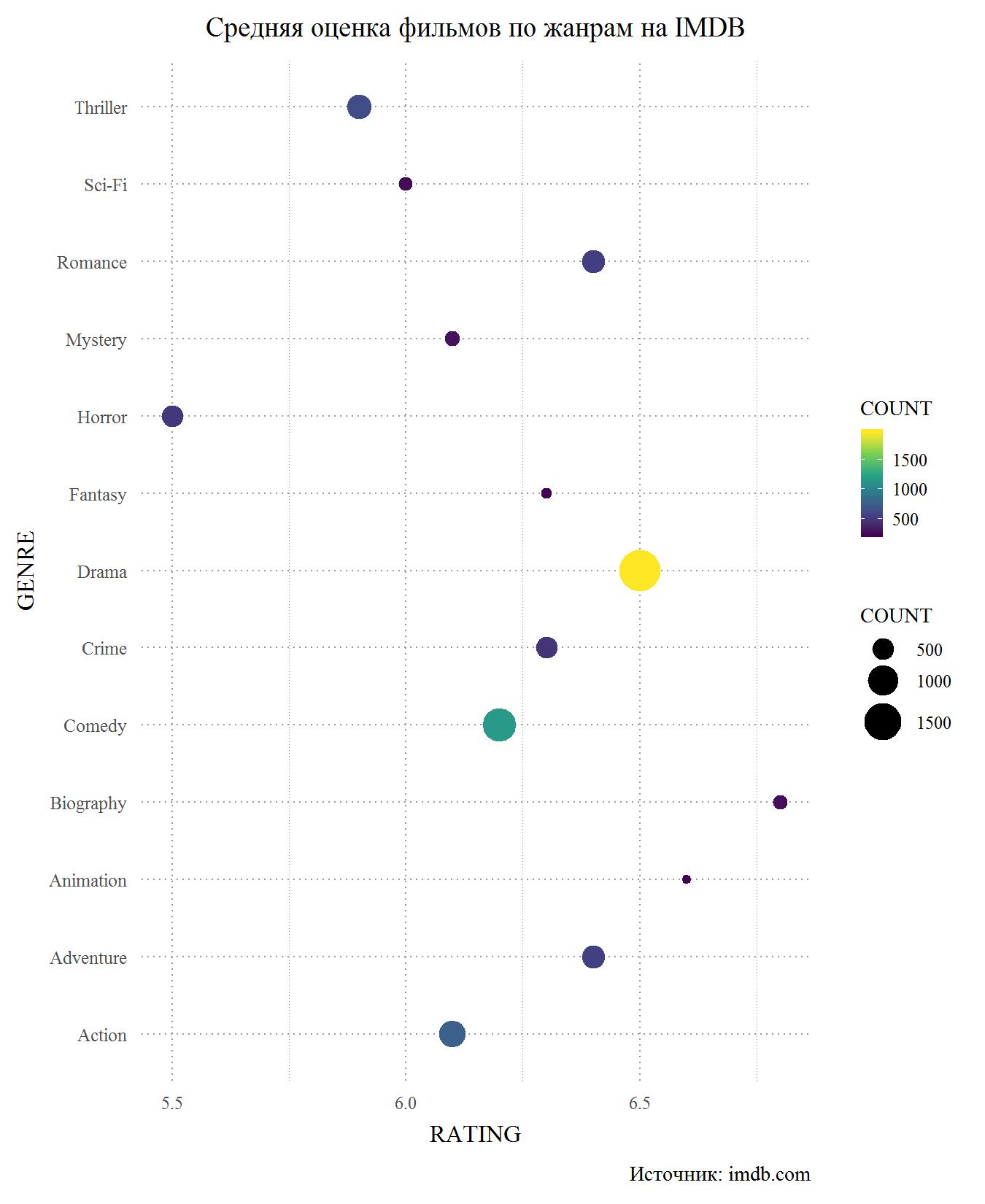
现在考虑相同的图表,但适用于IMDB。 原则上,他再次确认两个站点之间的评级差异不明显。 这不足为奇,因为许多用户在两个站点上都有帐户,并且不太可能在不同站点上给出不同的评级。 同样,主要的失败者是恐怖,我们可以说他们是电影中收视率最低的类型。 我很难评估为什么会发生这种情况,因为我一生中唯一看过的恐怖电影是《格林姆斯》。 预算类别最低的可能是恐怖,廉价演员的疲软行为和坦率的坏场景来自哪里。 拥有科幻小说和IMDB惊悚片的人落后了,但激进分子的表现更好。 领导人中又有传记电影和卡通片。 该剧名列第三,但情节剧的得分低于6.5,达到了冒险电影的水平。 同样在IMDB下面的喜剧中。
结论和有关“外部因素”的一些知识
尽管收视率有所不同(在Kinopoisk上,收视率略高),但还是有点。 根据各种流派,巨大的差异也是不可察觉的。 拥有数十甚至数十万张选票的大片,如果有分歧,则在0.5分之内。
票数少(尤其是在“怪胎”上)的电影,票数最多不超过一万,通常在收视率上会有很大差异。 但是,对IMDB的评级最大的不同是该电影在国外网站获得30,000票,在Kinopoisk上获得超过90,000票。 这是Alexei Pimanov“ Crimea”的创作。 这部电影受到外国观众的喜爱吗? 几乎没有 电影制作人很可能对IMDB使用与Kinopoisk中相同的“营销政策” 。 只是如果Kinopoisk“清理”了这种估算,那么它们仍保留在IMDB中。 我认为这就是为什么“克里米亚”是“好小金奇克”的原因。
如果有任何意见,建议和投诉,我将不胜感激
Github仓库链接
我的社交圈个人资料