这篇文章的想法是通过对文章
“有关inode的事情”的评论中的讨论而自发产生的。
事实是,我们服务的内部细节是存储大量小文件。 目前,我们大约有数百TB的此类数据。 我们碰到了一些明显的但不是很耙的东西,成功地走了过去。
因此,我分享我们的经验,也许有人会派上用场。
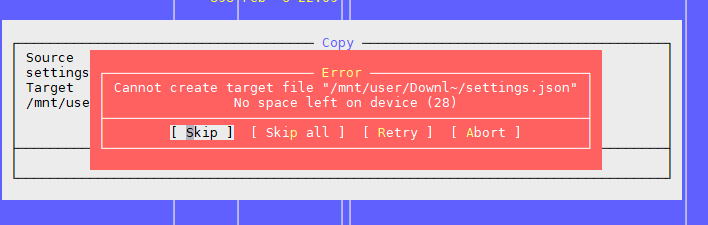
问题一:“设备上没有剩余空间”
如以上文章所述,问题是文件系统上有可用块,但索引节点已结束。
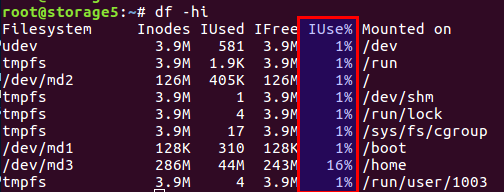
您可以使用
df -ih检查已使用和可用的索引节点的数量:
简而言之,我不会重述该文章,简而言之,既有直接在磁盘上存储数据的块,又有用于元信息的块,它们也是inode(索引节点)。 它们的编号是在文件系统初始化期间设置的(我们正在谈论ext2及其子代),并且不会进一步更改。 数据块和索引节点的平衡是根据平均数据计算得出的,在我们的示例中,当有许多小文件时,平衡应转向索引节点的数量-应该有更多的索引节点。
Linux已经提供了具有不同余额的选项,所有这些预先计算的配置都在
/etc/mke2fs.conf文件中。
因此,在通过mke2fs初始化文件系统的过程中,可以指定所需的配置文件。
以下是文件中的一些示例:
small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } big = { inode_ratio = 32768 } largefile = { inode_ratio = 1048576 blocksize = -1 }
调用mke2fs时,可以使用-T选项选择所需的用例。 如果没有现成的解决方案,您也可以手动设置必要的参数。
有关更多详细信息,请
mke2fs.conf和
mke2fs手册。
上述文章中未提及的功能-您可以设置数据块的大小。 显然,对于大文件,有意义的是具有较大的块大小,而对于小文件则应具有较小的块大小。
但是,值得考虑这样一个有趣的功能,例如处理器体系结构。
我曾经以为较大的照片文件需要更大的块大小。 它位于家中,在ARM体系结构上的家文件名为WD。 我毫不犹豫地将块大小设置为8k或16k,而不是标准的4k,之前已经测量了节省量。 直到磁盘还活着时,存储本身没有发生故障的那一刻,一切都很棒。 将磁盘放入带有常规Intel处理器的常规计算机中后,我感到惊讶:不支持的块大小。 航行了 有数据,一切都很好,但无法读取。 处理器i386等不知道如何使用与内存页大小不匹配的块大小,但是恰好是4k。 通常,这种情况以使用用户空间中的实用程序结束,一切都很缓慢而令人沮丧,但是数据得以保存。 谁在乎-谷歌实用程序
fuseext2的名称。 道德:要么事先考虑所有情况,要么不打造超级英雄,而将主妇的标准设置用于家庭主妇。
UPD 根据用户的评论,
berez澄清说 ,对于i386,块大小不应超过4k,但不必完全是4k,即 有效1k和2k。
因此,我们如何解决问题。
首先,当一个多TB的磁盘上装有数据时,我们遇到了一个问题,我们无法重做文件系统配置。
其次,该决定是紧急的。
结果,我们得出的结论是,我们需要通过减少文件数量来更改余额。
为了减少文件数量,决定将文件放在一个公共归档中。 考虑到我们的具体情况,我们将所有文件放在一个档案馆中一段时间,并每天晚上将cron任务存档。
选择了一个zip存档。 在上一篇文章的评论中,提出了tar,但有一个复杂之处:它没有目录,并且文件已穿入其中(出于某种原因,``tar''是磁带驱动器的遗留内容``Tape Archive''的缩写),即。 如果您需要在归档文件的末尾读取文件,则需要读取整个归档文件,因为每个文件相对于归档文件的开头都没有偏移量。 因此,这是一个漫长的过程。 在zip中,一切都更好:它在归档文件中具有相同的目录和文件偏移表,并且每个文件的访问时间不取决于其位置。 嗯,在我们的情况下,可以将压缩选项设置为“ 0”,因为所有文件都已经预先用gzip压缩过。
客户端通过nginx获取文件,根据旧的API,仅指定了文件名,例如:
http://www.server.com/hydra/20170416/0453/3bd24ae7-1df4-4d76-9d28-5b7fcb7fd8e5
为了实时解压缩文件,我们找到并连接了nginx-unzip-module模块(
https://github.com/youzee/nginx-unzip-module ),并设置了两个上游模块。
结果是此配置:

设置中的两个主机如下所示:
server { listen *:8081; location / { root /home/filestorage; } }
server { listen *:8082; location ~ ^/hydra/(\d+)/(\d+)/(.*)$ { root /home/filestorage; file_in_unzip_archivefile "/home/filestorage/hydra/$1/$2.zip"; file_in_unzip_extract "$2/$3"; file_in_unzip; } }
以及上游nginx上的上游配置:
upstream storage { server server.com:8081; server server.com:8082; }
运作方式:
- 客户到前台nginx
- 前nginx尝试从第一个上游提供文件,即 直接从文件系统
- 如果没有文件,它将尝试从第二个上游提供文件,该文件将尝试在存档中查找文件
第二个问题:再次,“设备上没有剩余空间”
当目录中有很多文件时,这是我们遇到的第二个问题。
我们正在尝试创建一个文件,系统发誓没有空间。 更改文件名,然后尝试再次创建。
原来如此。
看起来像这样:

检查inode没有任何帮助-有很多免费的。
检查位置是一样的。
我们认为目录中可能有太多文件,但是对此有一个限制,但又不是:每个目录的最大文件数:〜1.3×10 ^ 20
是的,如果更改名称,则可以创建文件。
结论是文件名有问题。
进一步的搜索显示,构造目录索引时问题出在哈希算法中,因为文件数量众多,因此产生了所有后果。 可以在这里找到更多详细信息:
https :
//ext4.wiki.kernel.org/index.php/Ext4_Disk_Layout#Hash_Tree_Directories您可以禁用此选项,但是...在对所有文件进行排序时,按名称搜索文件可能会变得异常长。
tune2fs -O "^dir_index" /dev/sdb3
通常,变通方法可能如何起作用。
道德:目录中的许多文件通常是错误的。 这不是必需的。
通常,在这种情况下,它们通过文件名的首字母或某些其他参数(例如,日期)创建子目录,在大多数情况下,这样可以节省时间。
但是,即使将小文件划分为多个目录,它们的总数仍然很差-然后看到第一个问题。
第三个问题:如何查看文件列表(如果有很多)
在我们的情况下,当我们有很多文件时,一种或另一种方式遇到了如何查看目录内容的问题。
标准解决方案是
ls 。
好的,让我们看看4772098文件会发生什么:
$ time ls /home/app/express.repository/offercache/ >/dev/null real 0m30.203s user 0m28.327s sys 0m1.876s
30秒...太长了。 而且大部分时间都需要处理用户空间中的文件,而根本不需要处理内核中的文件。
但是有一个解决方案:
$ time find /home/app/express.repository/offercache/ >/dev/null real 0m3.714s user 0m1.998s sys 0m1.717s
3秒 快10倍。
万岁!
UPD来自
berez用户的更快解决方案是禁用
ls排序
time ls -U /home/app/express.repository/offercache/ >/dev/null real 0m2.985s user 0m1.377s sys 0m1.608s
第四个问题:使用文件时的大型LA
当您需要将一堆文件从一台计算机复制到另一台计算机时,会定期出现这种情况。 同时,LA通常会不切实际地增长,因为一切都取决于磁盘本身的性能。
您想要的最合理的方法是使用SSD。 真的很酷。 唯一的问题是多TB SSD的成本。
但是,如果磁盘是普通磁盘,则需要复制文件,这也是一个生产系统,在该系统中,过载会导致客户不满意的惊叹声吗? 至少有两个有用的工具:
nice和
ionice 。
nice -分别降低了进程的优先级,sheduler将更多的时间片分配给其他优先级更高的进程。
在我们的实践中,它有助于将nice设置为最大值(最小优先级为19,最大优先级为-20(负20))。
ionice相应地调整输入/输出的优先级(I / O调度)
如果您使用RAID并需要突然进行同步(重启失败或在更换磁盘后需要恢复RAID阵列),则在某些情况下应降低同步速度,以便其他进程可以或多或少地正常工作。 为此,以下命令将有所帮助:
echo 1000 > /proc/sys/dev/raid/speed_limit_max
第五个问题:如何实时同步文件
为了避免文件丢失,我们拥有相同数量的大量文件,这些文件需要备份到第二台服务器,因此...不断地写入文件,因此,为了使丢失最少,您需要尽快复制它们。
标准解决方案:通过SSH进行Rsync。
除非您需要每隔几秒钟执行一次,否则这是一个不错的选择。 并且有很多文件。 即使您不复制它们,您仍然需要以某种方式了解发生了什么变化,并且比较几百万个文件是磁盘上的时间和负载。
即 我们需要立即知道要复制的内容,而不必每次都进行比较。
救赎-
lsyncd 。
Lsyncd 实时同步(镜像)守护程序 。 它也可以通过rsync起作用,但是它另外使用inotify和fsevents监视文件系统的更改,并仅开始复制那些已经出现或更改的文件。
第六个问题:如何了解谁加载磁盘
每个人都可能知道这一点,但是
iotop完整
iotop :为了监视磁盘子系统,有
iotop命令(如
top ,但显示了最积极地使用磁盘的进程。

顺便说一下,好的旧顶部也清楚地表明磁盘是否存在问题。 为此,有两个最合适的参数:
平均负载和
IOwait 。
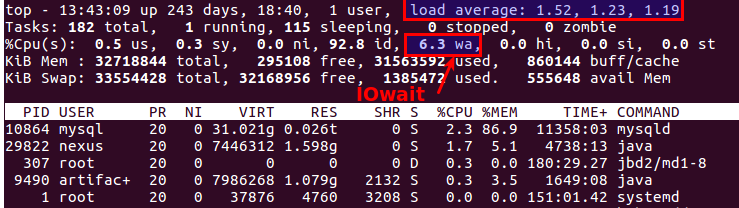
第一个显示服务队列中有多少个进程,通常多于2个-已经出问题了。 通过主动复制到备份服务器,我们最多允许6-8个用户,之后情况被视为异常。
第二个是处理器忙于磁盘操作的数量。 IOwait> 10%是一个令人担忧的原因,尽管在具有特定负载配置文件的服务器上,它稳定在40-50%,这确实是正常现象。
我将在这里结束,尽管也许我们不必面对许多问题,但我很乐意等待对有趣的真实案例的评论和描述。