在开始实施一项新功能之前,您必须公平行事。
复杂功能的开发需要工程师团队的工作的良好协调。
其中最重要的一点是任务并行化的问题。
是否可以使一线士兵免于等待后端实施的麻烦? 有没有办法并行化UI的各个片段的开发?
本文将讨论Web开发中任务并行化的主题。
问题
因此,让我们从确定问题开始。 想象一下,您有一个经验丰富的产品(Internet服务),其中收集了许多不同的微服务。 系统中的每个微服务都是一种微型应用程序,已集成到常规体系结构中,并解决了服务用户的某些特定问题。 想象一下,今天早上(冲刺的最后一天),产品负责人Vasily给您打了个招呼,并宣布:“在下一个冲刺中,我们开始了解数据导入,这将使服务用户更加满意。它将使用户可以立即从以下位置填写服务:密1C!”。
想象一下,您是一名经理或团队负责人,而您并未从业务角度收听所有这些对快乐用户的热情描述。 您估计所有这些将需要多少劳动力。 作为一名优秀的经理,您会尽一切努力减少Vasily对MVP评分任务的胃口(以下简称“最低限度可行产品”)。 同时,不能忽略MVP的两个主要要求-导入系统承受大负载和在后台工作的能力。
您了解,当在同一个用户请求中处理所有数据时,传统方法将行不通。 在这里,您必须围挡所有背景工作者的花园。 您将不得不束缚事件总线,考虑负载平衡器,分布式数据库等的工作方式。 通常,微服务架构的所有乐趣。 结果,您得出结论,此功能的后端开发将继续进行,而不是算命先生。
问题自动出现:“在没有API的情况下,前线士兵在这段时间内会做什么?”。
此外,事实证明,不得立即导入数据。 您必须首先验证它们,然后让用户纠正所有发现的错误。 事实证明,前端的工作流程也很狡猾。 并且有必要像往常一样在“昨天”对功能进行处理。 因此,退伍军人必须以某种方式进行协调,以使他们不会在一个萝卜丛中争吵,不会引起冲突并冷静地看待每一件事(请参阅本文开头的KDPV)。
在不同的情况下,我们可以从后到前开始锯切。 首先,实现后端并确认它能够承受负载,然后将前端平稳地悬挂在其上。 但是要注意的是,规范一般性地描述了新功能,在可用性方面存在差距和争议点。 但是,如果在前端实现的最后发现这种功能将无法满足用户的需求呢? 可用性更改可能需要更改数据模型。 我们必须重做正面和背面,这将非常昂贵。
敏捷正在努力帮助我们。
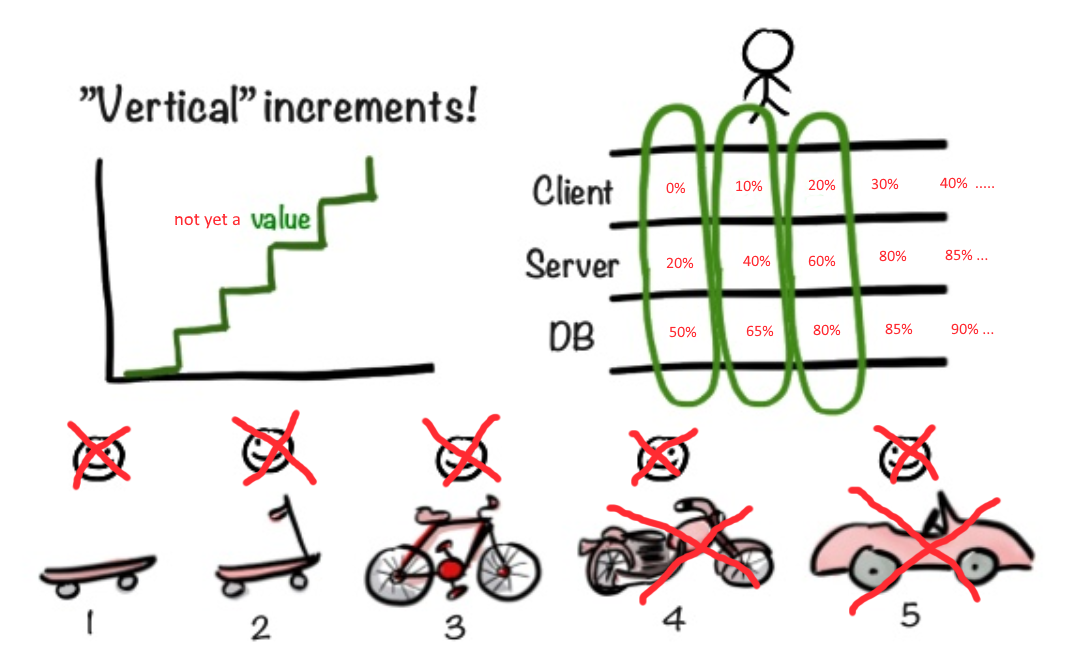
灵活的方法提供了明智的建议。 “从滑板开始,向用户展示。突然,他会喜欢的。如果喜欢,继续前进,拧上新的筹码。”
但是,如果用户在两到三周内立即至少需要一辆摩托车怎么办? 如果要在摩托车的外墙上开始工作,您至少需要确定电动机的尺寸和底盘的尺寸怎么办?
如何确保在应用程序的其他层确定之前,不延迟外观的实现?
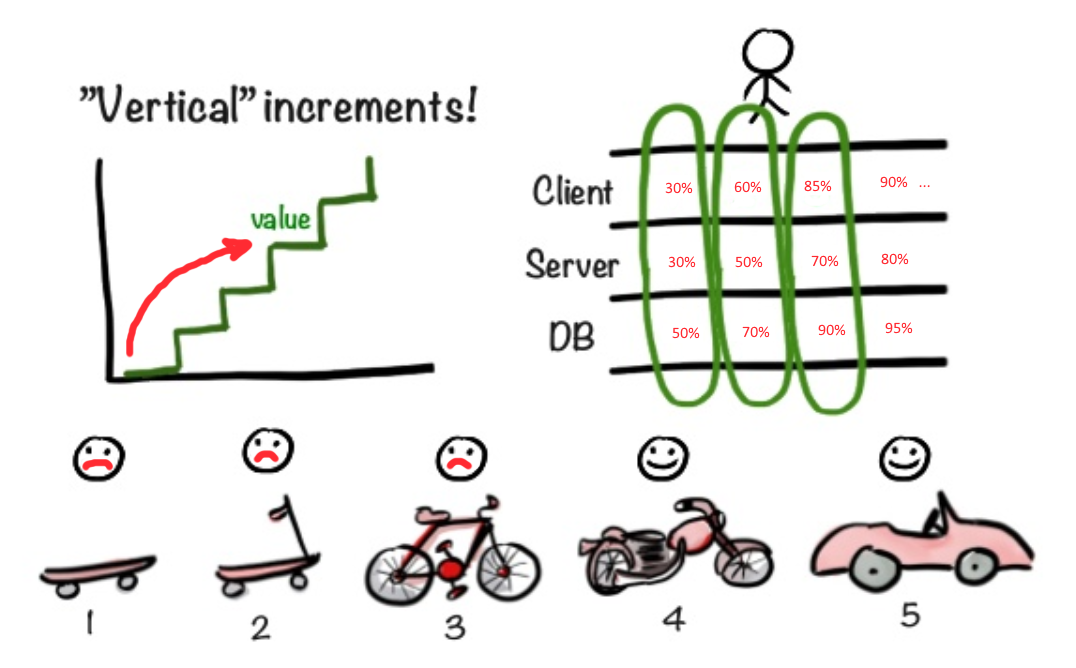
在我们的情况下,最好使用其他方法。 最好立即开始制作立面(正面),以确保MVP的最初想法正确。 一方面,将装饰性的外墙滑向产品负责人瓦西里(Vasily),背后似乎一无所有,这似乎是骗子。 另一方面,我们通过这种方式很快就获得了用户首先会遇到的部分功能反馈。 您可能有一个非常酷的体系结构,但是如果没有可用性,那么整个应用程序将被抛弃在应用程序的边缘,而不了解细节。 因此,在我看来,尽快提供功能最强大的UI而不是使前端进度与后端进度同步,是更为重要的。 发行未完成的UI和测试支持没有意义,其功能不能满足主要要求。 同时,发布80%的所需UI功能(但没有可用的后端)很可能是有利可图的。
一些技术细节
因此,我已经简要描述了我们将要实现的功能。 添加一些技术细节。
用户应该能够将大数据文件上传到服务。 该文件的内容必须采用特定格式(例如CSV)。 该文件必须具有特定的数据结构,并且某些必填字段不能为空。 换句话说,在后端卸载后,您将需要验证数据。 验证可以持续相当长的时间。 您无法保持与后端的连接处于打开状态(超时会断开连接)。 因此,我们必须快速接受文件并开始后台处理。 验证结束时,我们必须通知用户他可以开始编辑数据。 用户必须纠正验证期间检测到的错误。
修复所有错误后,用户单击导入按钮。 已更正的数据发送回后端。 完成导入过程。 我们必须告知前端所有导入阶段的进度。
最有效的警报方式是WebSockets。 从前端开始,通过一定时间的Websocket,将发送请求以获取后台数据处理的当前状态。 对于后台数据处理,我们需要后台处理程序,分布式命令队列,事件总线等。
数据流如下(供参考):
- 通过文件浏览器API,我们要求用户从磁盘中选择所需的文件。
- 通过AJAX,我们将文件发送到后端。
- 我们正在等待数据文件的验证和解析完成(我们通过Websocket轮询后台操作的状态)。
- 验证完成后,我们将加载准备导入的数据并将其呈现在导入页面上的表中。
- 用户编辑数据,更正错误。 通过单击页面底部的按钮,我们将更正后的数据发送到后端。
- 再次在客户端,我们对后台操作状态进行定期轮询。
- 在当前导入结束之前,用户应该无法开始新的导入(即使在相邻的浏览器窗口或相邻计算机上)。
发展计划
Mocap UI与 原型用户界面

让我们立即强调一下线框,样机,原型之间的区别。
上图显示了线框。 这只是一张图纸(数字或纸上-没关系)。 其他两个概念更为复杂。
Mocap是未来界面的一种表示形式,仅用作表示形式,随后将被完全替换。 该表格将在将来作为样本存档。 真正的界面将使用其他工具完成。 可以在矢量编辑器中完成具有足够设计细节的Mocap,但是前端开发人员只需将其放在一旁,然后将其作为模型进行窥视。 Mocap甚至可以在专门的浏览器构造器中制作,并且互动性有限。 但是他的命运没有改变。 他将成为《设计指南》专辑中的模特。
使用与将来的用户界面相同的工具(例如,React)来创建原型。 原型代码托管在常规应用程序存储库中。 它不会像mocap一样被替换。 首先,它用于测试概念(概念证明,PoC)。 然后,如果它通过了测试,他们将开始开发它,并将其逐渐转变为成熟的用户界面。
现在到了要点...
想象一下,来自设计工作室的同事向我们展示了他们的创作过程:未来界面的模型。 我们的任务是计划工作,以便尽快使退伍军人的并行工作成为可能。
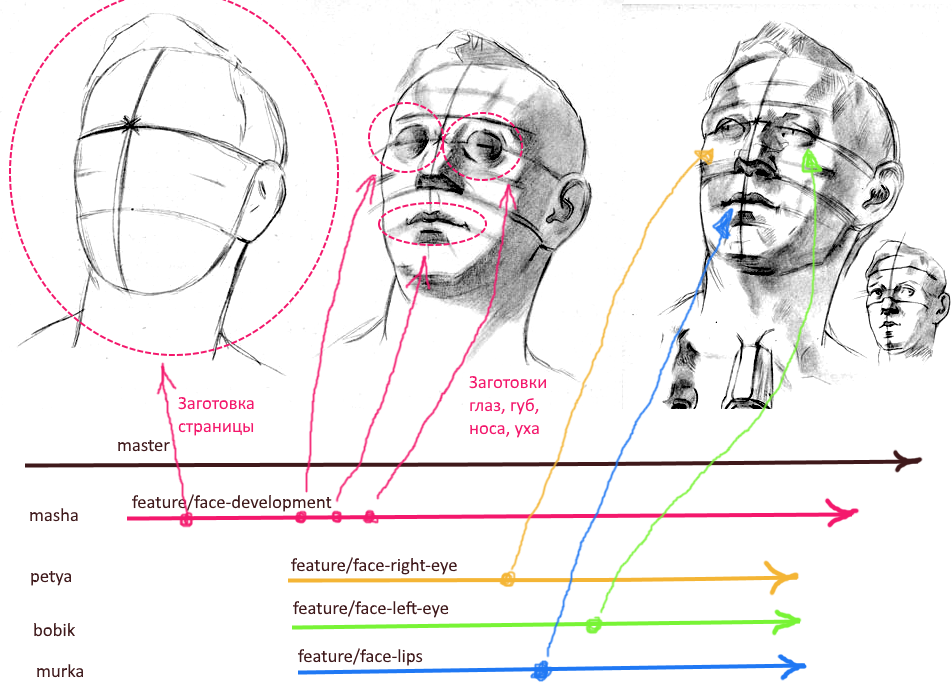
由于算法的编译从流程图开始,因此我们开始使用简约的线框创建原型(请参见上图)。 在此线框上,我们将将来的功能分为大块。 这里的主要原则是集中责任。 您不应将一项功能划分为不同的模块。 苍蝇飞到一个街区,炸肉排到另一个街区。
接下来,您需要尽快创建空白页面(虚拟),配置“路由”,然后在菜单中放置指向该页面的链接。 然后,您需要为基本组件创建空白(为原型线框中的每个块创建一个空白)。 并将这个特殊的框架提供给新功能的开发分支。
我们在git中获得以下分支层次结构:
master ---------------------- > └ feature/import-dev ------ >
“ import-dev”分支将为整个功能发挥开发早午餐的作用。 建议在此分支机构中固定一位负责人(维护人员),该负责人并行处理所有从事该功能的同事。 还建议不要直接提交此分支,以减少在原子拉取请求的此分支中存在合并时发生冲突和意外更改的机会。
因为 现在,我们已经为页面上的主要块创建了组件,然后您可以立即为每个UI块创建单独的分支。 最终的层次结构可能如下所示:
master ----------------------- > └ feature/import-dev ------- > ├ feature/import-head ---- > ├ feature/import-filter -- > ├ feature/import-table --- > ├ feature/import-pager --- > └ feature/import-footer -- >
注意: 在什么时候创建这些原子早午餐并不重要,上面提到的命名约定也不是唯一合适的命名规则。 可以在开始工作之前立即创建早午餐。 早午餐的名称应该对开发中的所有参与者都清楚。 该名称应尽可能短,同时应明确指出分支负责功能的哪一部分。
通过上述方法,我们确保了多个UI开发人员的无冲突操作。 每个UI片段在项目层次结构中都有其自己的目录。 片段目录包含主要组件,其样式集和自己的子组件集。 每个片段也可以具有自己的状态管理器(MobX,Redux,VueX参与者)。 片段的组件也许使用了某些全局样式。 但是,禁止在开发新页面的一部分时更改全局样式。 更改设计的一般原子的默认行为和样式也不值得。
注意: “设计原子”是指我们服务的标准组件集中的一个元素-请参见Atomic Design ; 在我们的案例中,假定已经实施了原子设计系统。
因此,我们在物理上将前线士兵彼此分开。 现在,他们每个人都可以安静地工作,而不必担心与合并冲突。 同样,任何人都可以随时从其分支在feature / import-dev中创建拉取请求。 现在已经可以平静地抛出静态内容,甚至可以在一个状态存储中形成交互。
但是我们如何确保UI片段可以相互交互?
我们需要实现片段之间的链接。 JS服务充当与后备交换数据的网关,适合于片段之间的链接。 通过同一服务,您可以实现事件通知。 通过订阅某些事件,这些片段将隐式包括微服务的整个生命周期。 一个片段中数据的更改将使得有必要更新另一个片段的状态。 换句话说,我们通过数据和事件模型对片段进行了集成。
要创建此服务,我们需要在git中再增加一个分支:
master --------------------------- > └ feature/import-dev ----------- > ├ feature/import-js-service -- > ├ feature/import-head -------- > ├ feature/import-filter ------ > ├ feature/import-table ------- > ├ feature/import-pager ------- > └ feature/import-footer ------ >
注意: 不要害怕分支的数量,不要犹豫产生分支。 Git使您可以有效地处理大量分支。 养成习惯后,就很容易分支:
$/> git checkout -b feature/import-service $/> git commit . $/> git push origin HEAD $/> git checkout feature/import-dev $/> git merge feature/import-service
对于某些人来说,这似乎很紧张,但是将冲突最小化的好处更为可观。 此外,当您是分支的唯一所有者时,可以安全地推入-f,而不必担心会破坏某人的本地提交历史记录。
伪数据
因此,在上一阶段,我们准备了集成JS服务(importService),并准备了UI片段。 但是如果没有数据,我们的原型将无法工作。 除了静态装饰之外,什么也没画。
现在,我们需要确定一个示例数据模型,并以JSON或JS文件的形式创建此数据(选择一种还是另一种取决于项目中的导入设置;是否配置了json-loader)。 我们的importService及其测试(我们稍后会考虑)从这些文件中导入模拟来自真实后端的响应所必需的数据(尚未实现)。 将该数据放在何处并不重要。 最主要的是,它们可以轻松导入importService本身,并在我们的微服务中进行测试。
建议立即与后面的开发人员讨论数据格式,字段命名约定。 例如,您可以同意使用符合OpenAPI规范的格式。 无论遵循哪种支持格式规范,我们都会严格按照支持数据格式创建伪造数据。
注意: 不要害怕在假数据模型上犯错误; 您的任务是制作数据合同的草稿版本,然后仍将与后端开发人员达成协议。
合约
伪数据可以作为一个良好的开始,以便在后端开始着手将来的API规范。 在这里,由谁以及如何高质量地实施模型草案都无关紧要。 至关重要的是在前后开发人员的参与下进行的联合讨论和协调。
您可以使用专用工具来描述合同(API规范)。 例如, OpenAPI / Swagger 。 以一种很好的方式,当使用这种工具描述API时,不需要所有开发人员都在场。 可以由一名开发人员(规范编辑器)完成。 对新API进行集体讨论的结果是产生了诸如MFU(会议跟进)之类的工件,根据这些工件,规范编辑器还为将来的API构造了参考。
在规范草案的结尾,应该花很长时间来验证正确性。 集体讨论中的每个参与者都可以独立于其他参与者进行粗略检查,以验证是否考虑了他的观点。 如果看起来有些不正确,则可以通过编辑器规范进行澄清(正常工作的通讯)。 如果每个人都对规范感到满意,则可以将其发布并用作服务的文档。
单元测试
注意: 对我来说,单元测试的价值非常低。 在这里,我同意David Heinemeier Hansson @ RailsConf的观点 。 “单元测试是确保程序能够按预期完成工作的好方法。” 但是我承认特殊情况下,单元测试会带来很多好处。
现在我们已经决定了假数据,我们可以开始测试基本功能了。 要测试前端组件,可以使用诸如业力,笑话,摩卡,柴,茉莉花之类的工具。 通常,将带有后缀“ spec”或“ test”的同名文件放在要测试的JS资源旁边:
importService ├ importService.js └ importService.test.js
后缀的具体值取决于项目中JS软件包收集器的设置。
当然,在背部处于“避孕”状态的情况下,很难通过单元测试来涵盖所有可能的情况。 但是单元测试的目的有些不同。 它们旨在测试各个逻辑块的操作。
例如,最好通过单元测试来涵盖各种类型的助手,通过这种测试,JS组件和服务之间可以共享逻辑或某些算法。 同样,这些测试可以涵盖MobX,Redux,VueX的组件和存储中响应用户数据更改的行为。
集成和端到端测试
集成测试意味着检查系统行为是否符合规范。 即 已检查用户将准确看到规格中描述的行为。 与单元测试相比,这是更高级别的测试。
例如,当用户删除所有文本时,在必填字段下检查错误的测试。 或用于在尝试保存无效数据时检查是否生成错误的测试。
E2E测试(端到端)的工作水平更高。 他们验证UI的行为是正确的。 例如,检查将数据文件发送到服务后,是否向用户显示了一个扭曲,表明正在进行异步过程。 或检查服务的标准组件的可视化是否与设计者的指南相对应。
这种测试适用于某些UI自动化框架。 例如,它可以是Selenium 。 此类测试与Selenium WebDriver一起在某些浏览器(通常是带有“无头模式”的Chrome)中运行。 它们工作了很长时间,但减轻了质量检查专家的负担,为他们进行了烟雾测试。
编写这些类型的测试非常耗时。 我们越早开始编写它们,越好。 尽管我们没有完整的备份,但我们已经可以开始描述集成测试了。 我们已经有了规范。
通过对E2E的描述,障碍物测试甚至更少。 我们已经从设计原子库中绘制了标准组件。 实现了特定的用户界面。 在importService中的伪造数据和API上进行了一些交互。 至少在基本情况下,没有什么可以阻止您启动UI自动化。
通过编写这些测试,如果没有困惑的人,您可以再次使单个开发人员感到困惑。 为了描述测试,您可以创建一个单独的分支(如上所述)。 在测试分支中,有必要定期从分支“ feature / import-dev ”更新更新。
合并的一般顺序如下:
- 例如,分支“ 功能/导入过滤器 ”中的开发人员创建了PR。 预览此PR,“ feature / import-dev ”分支的维护者注入该PR。
- 维护者宣布更新已经发布。
- 分支“ feature / import-tests-e2e ”中的开发人员通过“ -dev分支”中的合并来进行极端更改。
CI和测试自动化
前端测试是通过可通过CLI使用的工具实施的。 在package.json中,编写了用于运行不同类型测试的命令。 这些命令不仅由本地环境中的开发人员使用。 在CI(连续集成)环境中运行测试也需要它们。
如果现在我们在CI中运行该构建并且没有错误,那么我们期待已久的原型将交付给测试环境(前端的80%功能尚未实现后端)。 我们可以向瓦西里展示未来微服务的大致行为。 瓦西里(Vasiliy)踢出了这个原型,也许会发表一些言论(也许甚至是认真的言论)。 在此阶段,进行调整并不昂贵。 在我们的案例中,后勤需要进行重大的体系结构更改,因此在后勤上的工作可能比在前工作要慢。 只要没有最终确定支持,对计划的更改就不会导致灾难性的后果。 如有必要,请在此阶段进行一些更改,我们将要求您对API规范进行调整(以夸大的形式)。 此后,重复上述步骤。 前线工作人员仍然不依赖后端。 各个前端专家彼此独立。
后端。 存根控制器
在后端开发API的起点是批准的API规范( OpenAPI / Swagger )。 如果有规范,支持也将变得更容易并行化。 对规范的分析应使开发人员考虑架构的基本元素。 在继续实施单个API调用之前,需要创建哪些通用组件/服务。 同样,您可以在UI的空白处应用该方法。
我们可以从头开始,即 从我们背部的外层(从控制器)。 在这一阶段,我们从路由,控制器空白和伪造数据开始。 我们还没有服务层(BL)和数据访问(DAL)。 我们只需将数据从JS传输到后端,并对控制器进行编程,以使它们实现基本情况的预期答案,并从假数据中分出部分即可。
完成此阶段后,前线士兵应获得静态测试数据的工作后端。 而且,前线士兵正是在这些数据上编写集成测试。 原则上,此时切换JS网关(importService)以使用背面的控制器空白应该不难。
从概念上讲,通过Websocket进行请求的响应部分与Web API控制器没有什么不同。 我们还在测试数据上做出此“答案”,并将importService连接到此准备。
最终,必须将所有JS转移到与真实服务器一起使用。
后端。 控制器的定稿。 DAO存根
现在该轮到外部支撑层完成了。 对于控制器,在BL中一对一地实现服务。 现在,服务将可以处理假数据。 在此阶段的补充是,在服务中,我们已经实现了真正的业务逻辑。 在此阶段,建议根据规范的业务逻辑开始添加新测试。 重要的是不要使集成测试失败。
注意:我们仍然不依赖于是否在数据库中实现了数据方案。
后端。 完成DAO。 实际分贝
在数据库中实施了数据方案之后,我们可以将之前步骤中的测试数据传输到该数据方案,然后将基本的DAL切换为与实际的数据库服务器一起使用。 因为 我们将为前端创建的初始数据传输到数据库,所有测试应保持相关性。 如果有任何一项测试失败,则说明出现了问题,您需要了解。
注意: 通常,在数据库中使用数据方案的可能性很高,因此很少有新功能可用。 也许将在BL中实现服务的同时对数据库进行更改。
在此阶段结束时,我们将获得完整的微服务alpha版本。 此版本已经可以显示给内部用户(产品负责人,产品技术人员或其他人员)以用作MVP进行评估。
将继续进行Agile的标准迭代,以修复错误,实施其他芯片并进行最终抛光。
结论
我认为您不应盲目地将以上内容用作行动指南。 首先,您需要尝试并适应您的项目。 上述方法能够使各个开发人员彼此独立,并允许他们在某些条件下并行工作。 带有早午餐和数据传输的所有手势,对伪造数据实施空白似乎是相当大的开销。 由于并发性增加,因此产生了此间接费用的利润。 如果开发团队由 一挖半 两个完整的堆栈或一个带有一个后端的freotovik,那么这种方法可能会带来很多好处。 尽管在这种情况下,某些观点很可能会提高开发效率。
当我们一开始就快速实现与将来的实际实现尽可能接近的工件,并在项目的文件结构级别和代码管理系统(git)级别将不同部分的工作物理地分开时,这种方法的好处就会显现出来。
希望本文对您有所帮助。
感谢您的关注!