在
上一篇文章中,我讨论了我们的大型负载测试基础架构。 平均而言,我们创建约100台服务器来提供负载,并为我们的服务创建约150台服务器。 所有这些服务器都需要创建,删除,配置和运行。 为此,我们使用与产品上相同的工具来减少手工工作量:
- 创建和删除测试环境-Terraform脚本;
- 配置,更新和运行-Ansible脚本;
- 根据负载进行动态缩放-自行编写的Python脚本。
多亏了Terraform和Ansible脚本,从创建实例到启动服务器的所有操作仅由六个命令执行:
# aws ansible-playbook deploy-config.yml # ansible-playbook start-application.yml # ansible-playbook update-test-scenario.yml --ask-vault-pass # Jmeter , infrastructure-aws-cluster/jmeter_clients:~# terraform apply # jmeter ansible-playbook start-jmeter-server-cluster.yml # jmeter ansible-playbook start-stress-test.yml #
动态服务器扩展
在生产高峰期,我们同时拥有超过2万名在线用户,而在其他时间可能有6000万名在线用户。 不断保持服务器的全部容量是没有意义的,因此我们为在用户输入时打开板子的板子服务器和处理API请求的API服务器设置自动缩放。 现在,在必要时可以创建和删除服务器。
此机制在负载测试中非常有效:默认情况下,我们可以使用最少数量的服务器,并且在测试时,它们会自动以适当的数量增加。 开始时,我们可以有4个板服务器,在高峰时最多可以有40个。同时,不是立即创建新服务器,而是仅在当前服务器加载后才创建。 例如,用于创建新实例的标准可能是CPU利用率的50%。 这使您可以不减慢脚本中虚拟用户的增长速度,也可以不创建不必要的服务器。
这种方法的好处是,借助动态扩展,我们可以了解不同数量的用户需要多少容量,而这在销售中还没有。
按产品收集指标
有很多方法和工具可以监视压力测试,但是我们还是走了自己的路。
我们使用标准堆栈监视生产:Logstash,Elasticsearch,Kibana,Prometheus和Grafana。 我们的测试集群与产品类似,因此我们决定使用相同的指标与产品进行相同的监视。 这有两个原因:
- 无需从头开始构建监控系统,我们已经拥有完整且立即的监控系统;
- 我们还测试了销售监控:如果在测试监控期间我们了解到我们没有足够的数据来分析问题,那么当那里出现问题时,它们将不足以用于生产。
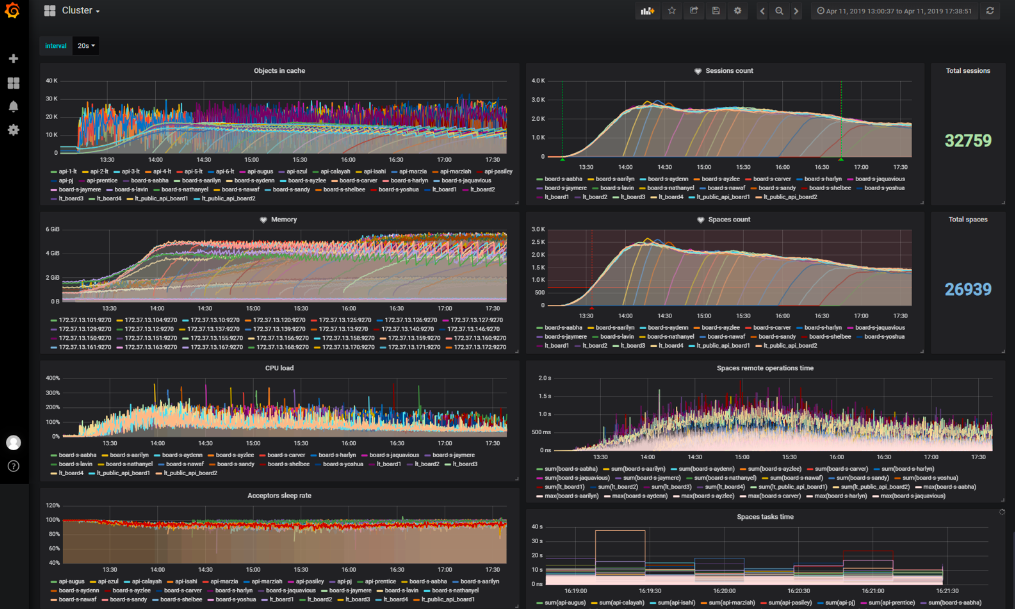
我们在报告中显示的内容
- 展台的技术特征;
- 脚本本身,用文字描述,而不是代码;
- 开发人员和经理所有团队成员都可以理解的结果;
- 展位总体状态图;
- 显示瓶颈或受测试中检查的优化影响的图形。
所有结果都存储在一个地方很重要。 因此,在发射之间将它们相互比较会很方便。
我们在产品中进行报告
(带有报告的白板示例) :
创建报告需要很多时间。 因此,我们计划使用
我们的公共API自动收集一般信息。
基础架构即代码
我们负责产品质量的不是质量检查工程师,而是整个团队。 压力测试是质量保证工具之一。 很酷,如果团队认为重要的是要在负载下检查所做的更改。 要开始考虑,她需要对制作负责。 在这里,我们得到了DevOps文化原则的帮助,我们在工作中开始实施这些原则。
但是,开始考虑进行压力测试只是第一步。 如果不了解生产设备,团队将无法通过测试来思考。 当我们开始设置团队中进行负载测试的过程时,我们遇到了这样的问题。 当时,团队无法确定生产设备,因此他们很难进行测试设计。 原因有很多:缺乏最新的文档或一个人无法掌握整个图片; 开发团队的多重成长。
为了帮助团队了解销售工作,可以将基础结构方法用作代码,我们在开发团队中开始使用该代码。
使用这种方法我们已经开始解决哪些问题:
- 一切都必须编写脚本,并且可以随时提出。 这样可以大大减少数据中心发生事故时的销售恢复时间,并使您能够保留适当数量的相关测试环境;
- 合理的节省:当OpenStack可以替代昂贵的平台(例如AWS)时,我们可以在Openstack上部署环境;
- 团队自己进行压力测试,因为他们了解设备的销售情况。
- 该代码代替了文档,因此无需无休止地对其进行更新,它始终是完整且最新的。
- 您无需再在狭窄的领域中寻求单独的专家来解决普通问题。 任何工程师都可以弄清楚代码。
- 有了清晰的销售结构,安排研究负载测试(如混乱的猴子测试或长内存泄漏测试)要容易得多。
我想将此方法不仅扩展到基础架构的创建,而且还扩展到各种工具的支持。 例如,
在上一篇文章中讨论的数据库测试,我们完全变成了代码。 因此,我们有一组脚本,而不是预先准备的站点,可以使用这些脚本在7分钟内在一个完全空的AWS账户中获取配置的环境并可以开始测试。 出于同样的原因,我们现在正在仔细考虑
Gatling ,创建者将其定位为“将代码作为代码进行测试”的工具。
基础结构作为代码的方法需要一种类似的方法来对其进行测试,并且需要团队编写脚本来提高新功能的基础结构。 所有这些都应该包含在测试中。 还有各种测试框架,例如
Molecule 。 有用于混乱猴子测试的工具,对于AWS有付费工具,对于Docker有
Pumba等等。 它们使您能够解决不同类型的任务:
- 如何检查AWS中的一个实例是否崩溃,以检查其余服务器上的负载是否重新平衡,以及该服务是否可以从如此急剧的请求重定向中幸存下来;
- 如何模拟网络的慢速运行,网络中断和其他技术问题,之后服务基础结构的逻辑不应中断。
在我们的近期计划中解决此类问题。
结论
- 浪费时间进行测试基础架构的手工编排是不值得的;最好是自动执行这些操作,以便更可靠地管理所有环境,包括产品。
- 动态扩展显着降低了维护销售和大型测试环境的成本,还减少了扩展时的人为因素。
- 您不能使用单独的监视系统进行测试,而要从市场上获取它。
- 重要的是,压力测试报告应在一个地方自动收集并具有统一的视图。 这将使他们能够轻松地比较和分析更改;
- 当团队对销售负责时,压力测试将成为公司的一个流程。
- 负载测试-基础架构测试。 如果负载测试成功,则可能是编译不正确。 验证测试的正确性需要对销售有深刻的了解。 团队应该有机会独立地了解销售手段。 我们使用“基础结构即代码”方法解决了这个问题;
- 基础结构准备脚本还需要像其他任何代码一样进行测试。