在上一章中,我们了解到深层神经网络(GNS)往往比浅层神经网络更难训练。 这很不好,因为我们有充分的理由相信,如果我们可以培训STS,他们将在执行任务方面做得更好。 但是,尽管上一章的新闻令人失望,但这并不会阻止我们。 在本章中,我们将开发可用于训练深度网络并将其付诸实践的技术。 我们还将研究更广泛的情况,简要了解GNS在图像识别,语音和其他应用程序中的最新使用。 并且从表面上考虑神经网络和AI可以期待什么。
这将是一章很长的章节,因此让我们回顾一下目录。 它的各个部分之间并不是紧密相连的,因此,如果您对神经网络有一些基本概念,则可以从更感兴趣的部分开始。
本章的主要部分是对最流行的深度网络类型之一的介绍:深度卷积网络(GSS)。 我们将结合使用卷积网络的详细示例,以及代码和其他内容,来解决根据MNIST数据集对手写数字进行分类的问题:

我们从浅层网络开始对卷积网络进行回顾,我们在本书较早的时候曾用它来解决这个问题。 在几个阶段中,我们将创建越来越强大的网络。 在此过程中,我们将了解许多强大的技术:卷积,池化,使用GPU与浅网相比,可大幅增加训练量,训练数据的算法扩展(以减少过度拟合),使用辍学技术(也是为了减少再培训),使用网络集成等。 结果,我们将建立一个能力几乎与人类相同的系统。 在10,000个MNIST验证图像中(系统在训练中没有看到),它将能够正确识别9967。以下是一些未正确识别的图像。 右上角是正确的选项; 我们的程序显示的内容显示在右下角。

其中许多很难分类为人类。 以第一行的第三个数字为例。 在我看来,比起正式版的“ 8”更像是“ 9”。 我们的网络也将其确定为“ 9”。 至少,这样的错误可以完全理解,甚至可以接受。 在总结图像识别的讨论时,将概述神经网络(特别是卷积神经网络)最近取得的巨大进步。
本章的其余部分专门从更广泛和更不详细的角度讨论深度学习。 我们将简要考虑其他NS模型,特别是循环NS和长期短期记忆的单位,以及如何将这些模型用于解决语音识别,自然语言处理等方面的问题。 我们将讨论NS和民防的未来,从诸如意图驱动的用户界面到深度学习在AI中的作用之类的想法。
本章以本书前几章的内容为基础,使用并整合了诸如反向传播,正则化,softmax等思想。 但是,阅读本章并不需要详细说明所有前几章的内容。 但是,阅读
第一章并了解国民议会的基本知识并没有什么害处。 当我使用第2章至第5章中的概念时,将根据需要提供与材料的必要链接。
值得注意的是,本章没有。 这不是有关使用NS的最新,最酷的库的培训材料。 我们不会训练数十层STS来解决前沿研究中的问题。 我们将尝试理解GNS的一些基本原理,并将其应用于MNIST任务的简单易懂的上下文。 换句话说,本章不会把您带到该地区的最前沿。 本章和前几章的目的是将重点放在基础知识上,并使您准备去了解各种各样的当代作品。
卷积神经网络简介
在前面的章节中,我们告诉我们的神经网络,识别手写数字图像非常好:
我们使用相邻层完全相互连接的网络进行此操作。 也就是说,网络的每个神经元都与相邻层的每个神经元相关联:
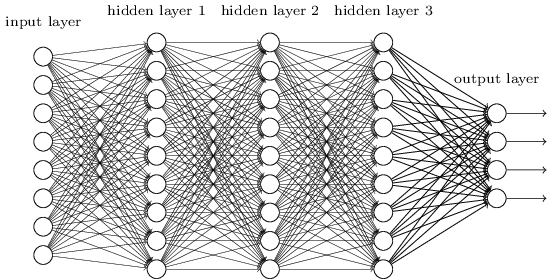
特别是,我们将图像中每个像素的强度编码为输入层相应神经元的值。 对于尺寸为28x28像素的图像,这意味着网络将具有784(= 28×28)个传入神经元。 然后,我们训练了网络的权重和偏移,以使输出(有这样的希望)正确识别传入的图像:“ 0”,“ 1”,“ 2”,...,“ 8”或“ 9”。
我们早期的网络运作良好:我们使用MNIST手写数字提供的训练和测试数据,使分类精度达到了98%以上。 但是,如果您现在评估这种情况,使用具有完全连接的图层的网络对图像进行分类似乎很奇怪。 事实是,这样的网络没有考虑图像的空间结构。 例如,它完全相同地应用于彼此相距较远的像素以及相邻像素。 假设应该基于对训练数据的研究得出关于这种空间结构概念的结论。 但是,如果我们不是尝试从头开始构建网络结构,而是使用一种尝试利用空间结构的架构怎么办? 在本节中,我将介绍卷积神经网络(SNA)。 它们使用特殊的体系结构,特别适合对图像进行分类。 通过使用这样的体系结构,SNA可以更快地学习。 这有助于我们训练更深层次的网络,这些网络可以很好地对图像进行分类。 如今,在大多数图像识别情况下都使用深度SNA或类似的变体。
SNA的起源可以追溯到1970年代。 但是,开始其现代发行的开始工作是1998年的工作,“
用于识别文档的梯度学习 ”。 Lekun对SNA中使用的术语发表了有趣的
评论 :“卷积网络等模型与神经生物学的联系非常肤浅。 因此,我称它们为卷积网络,而不是卷积神经网络,因此我们称其为节点元素,而不是神经元。” 但是,尽管如此,SNA还是使用了我们已经研究过的来自NS世界的许多想法:反向传播,梯度下降,正则化,非线性激活函数等。 因此,我们将遵循公认的协议并将其视为一种不适用。 我将它们称为网络和神经网络,以及它们的节点-神经元和元素。
SNA使用三个基本思想:局部接受域,总权重和合并。 让我们依次看一下这些想法。
当地接受领域
在完全连接的网络层中,输入层由神经元的垂直线表示。 在SNA中,以神经元正方形的形式表示输入层更为方便,其尺寸为28x28,其值对应于图像28x28的像素强度:

像往常一样,我们将传入的像素与一层隐藏的神经元相关联。 但是,我们不会将每个像素与每个隐藏的神经元相关联。 我们在传入图像的局部区域组织交流。
更精确地,第一隐藏层的每个神经元将与一小部分传入神经元相关联,例如,对应于25个传入像素的5x5区域。 因此,对于某些隐藏的神经元,连接可能如下所示:
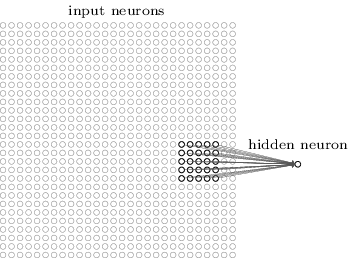
传入图像的这一部分称为此隐藏神经元的局部感受野。 这是一个小窗口,用于查看传入的像素。 每个键学习其重量。 另外,一个隐藏的神经元研究一般位移。 我们可以假设这个特定的神经元正在学习分析其特定的局部感受野。
然后,我们在整个传入图像中移动局部接收场。 每个局部感受野在第一隐藏层中都有其自己的隐藏神经元。 有关更具体的说明,请从左上角的本地接收场开始:

将局部感受野向右移动一个像素(一个神经元),使其与第二个隐藏神经元相关联:

因此,我们构建了第一个隐藏层。 请注意,如果我们的传入图像为28x28,局部接收场为5x5,则隐藏层中将有24x24个神经元。 这是因为我们只能将本地感受野向右(或向下)移动23个神经元,然后才能遇到传入图像的右侧(或底部)。
在此示例中,局部接受场一次移动一个像素。 但是有时会使用不同的步长。 例如,我们可以将本地感受野向侧面移动2个像素,在这种情况下,我们可以讨论步骤2的大小。在本章中,我们将主要使用步骤1,但是您应该知道有时会执行不同大小的步骤的实验。 您可以像其他超参数一样尝试步长。 您也可以更改局部接收场的大小,但通常会发现,较大的局部接收场大小在明显大于28x28像素的图像上效果更好。
总权重和偏移
我提到过,每个隐藏的神经元都有一个偏移量和5x5的权重,与其本地接受域相关。 但是我没有提到我们将对所有24x24隐藏神经元使用相同的权重和位移。 换句话说,对于一个隐藏的神经元j,k,输出将等于:
σ是激活函数,可能是前几章中的S型。 b是总偏移值。 w
l,m-总权重为5x5的数组。 最后,
x,y表示在位置x,y处的输入激活。
这意味着第一隐藏层中的所有神经元都检测到相同的信号,只是位于图像的不同部分。 由隐藏的神经元检测到的信号是导致神经元激活的特定输入序列:可能是图像的边缘或某种形式。 为了理解为什么这样做是合理的,假设我们的重量和位移使得隐藏的神经元可以识别特定局部接收场中的垂直脸。 此功能可能会在图像的其他位置有用。 因此,在整个图像区域上使用相同的特征检测器很有用。 更抽象地讲,SNA很好地适应了图像的平移不变性:例如,将猫的图像向侧面移动一点,它将仍然保留猫的图像。 的确,来自MNIST数字分类问题的图像全部居中并规格化。 因此,MNIST的平移不变性小于随机图片。 尽管如此,诸如面部和角度之类的特征可能仍会在传入图像的整个表面上有用。
因此,有时我们将传入层和隐藏层的映射称为要素映射。 定义特征图的权重称为总权重。 定义特征图的偏差是一般偏差。 通常说总重量和位移确定一个内核或过滤器。 但是在文学界,人们有时使用这些术语的原因略有不同,因此,我不会深入研究术语。 最好让我们看一些具体的例子。
我所描述的网络结构只能识别一种物种的局部属性。 为了识别图像,我们需要更多的功能图。 因此,完成的卷积层由几个不同的特征图组成:
该示例显示了3个特征图。 每张卡由一组5x5的总权重和一个公共偏移量确定。 结果,这样的网络可以识别三种不同类型的标志,并且每个标志可以在图像的任何部分中找到。
为了简单起见,我画了三张属性卡。 实际上,SNA可以使用更多(可能更多)功能图。 LeNet-5是早期的SNS之一,它使用6张功能卡(每张功能卡与5x5接收域相关联)来识别MNIST数字。 因此,以上示例与LeNet-5非常相似。 在我们将进一步独立开发的示例中,我们将使用包含20和40个功能卡的卷积层。 让我们快速看一下我们将要检查的迹象:

这20个图像对应于20个不同的属性映射(过滤器或内核)。 每张卡都由一个5x5图像表示,该图像对应于本地接收场的5x5权重。 白色像素表示重量较轻(通常为负值较多),并且特征图对相应像素的反应较小。 较暗的像素意味着更多的权重,并且特征图对相应像素的反应也更多。 粗略地说,这些图像显示了卷积层响应的那些信号。
从这些属性图中可以得出什么结论? 显然,这里的空间结构并不是随机出现的-许多迹象显示出明暗的区域。 这表明我们的网络实际上正在学习与空间结构有关的东西。 但是,除此之外,很难理解这些迹象是什么。 例如,我们显然没有研究
Gabor过滤器 ,该
过滤器已在许多传统的模式识别方法中使用。 实际上,为了更好地准确了解SNA正在研究哪些信号,现在正在进行许多工作。 如果您有兴趣,我建议从
2013年开始。
通用权重和偏移量的最大优点是,这可以大大减少SNA可用参数的数量。 对于每个特征图,我们需要5×5 = 25的总权重和一个公共偏移量。 因此,每个特征图都需要26个参数。 如果我们有20个特征图,则总共将有20个×26 = 520个参数定义卷积层。 为了进行比较,假设我们有一个完全连接的第一层,其中包含28×28 = 784个传入神经元和相对适度的30个隐藏神经元-我们在前面的许多示例中都使用了该方案。 结果是784×30权重,外加30个偏移量,总共23,550个参数。 换句话说,与卷积层相比,完全连接的层将具有40倍以上的参数。
当然,我们不能直接比较参数的数量,因为这两个模型根本不同。 但是从直觉上看,使用卷积平移不变性可以减少获得与完全连接模型可比的效率所需的参数数量。 反过来,这将加快卷积模型的训练,最终帮助我们使用卷积层创建更深的网络。
顺便说一句,“卷积”这个名称来自方程(125)中的运算,有时也称为
卷积 。 更准确地说,有时人们将这个方程写为
1 =σ(b + w ∗ a
0 ),其中a
1表示一个功能卡的一组输出激活,
0表示一组输入激活,而*称为卷积运算。 我们不会深入研究卷积数学,因此您不必特别担心这种联系。 但是值得知道这个名字的来历。
汇聚层
除了SNA中描述的卷积层之外,还存在池化层。 它们通常在卷积后立即使用。 他们致力于简化卷积层输出中的信息。
在这里,我使用的“特征图”一词不是指卷积层计算的函数,而是表示隐藏层神经元输出的激活。 这种自由使用术语的现象经常在研究文献中发现。
池化层接受每个卷积层特征图的输出,并准备压缩的特征图。 例如,池化层的每个元素都可以汇总上一层的2x2神经元的一部分。 案例研究:一种常见的合并程序称为最大合并。 在最大池中,池元素仅从2x2部分提供最大的激活,如下图所示:

由于卷积层神经元的输出给出24x24的值,因此在拉动后我们得到12x12神经元。
如上所述,卷积层通常意味着比单个特征图更多的东西。 我们将最大池分别应用于每个要素地图。 因此,如果我们有三个特征图,则组合的卷积和最大池化层将如下所示:
 可以将最大拉动想象为网络询问图像任何位置是否存在给定符号的一种方式。然后,她丢弃有关其确切位置的信息。直观上很清楚,当找到一个标志时,其确切位置不再像其相对于其他标志的近似位置一样重要。优点是使用池化获得的特征数量要少得多,这有助于减少下一层所需的参数数量。最大池化不是唯一的池化技术。另一种常见的方法称为L2池。在其中,我们取2x2神经元区域的激活平方和的平方根,而不是取最大2x2神经元区域的激活。这些方法的细节有所不同,但从直觉上讲,它类似于最大池:L2池是一种从卷积层压缩信息的方法。在实践中,经常使用两种技术。有时人们使用其他类型的池化。如果您正在努力优化网络质量,则可以使用支持数据来比较几种不同的拉网方法,然后选择最佳方法。但是我们不会担心如此详细的优化。
可以将最大拉动想象为网络询问图像任何位置是否存在给定符号的一种方式。然后,她丢弃有关其确切位置的信息。直观上很清楚,当找到一个标志时,其确切位置不再像其相对于其他标志的近似位置一样重要。优点是使用池化获得的特征数量要少得多,这有助于减少下一层所需的参数数量。最大池化不是唯一的池化技术。另一种常见的方法称为L2池。在其中,我们取2x2神经元区域的激活平方和的平方根,而不是取最大2x2神经元区域的激活。这些方法的细节有所不同,但从直觉上讲,它类似于最大池:L2池是一种从卷积层压缩信息的方法。在实践中,经常使用两种技术。有时人们使用其他类型的池化。如果您正在努力优化网络质量,则可以使用支持数据来比较几种不同的拉网方法,然后选择最佳方法。但是我们不会担心如此详细的优化。总结
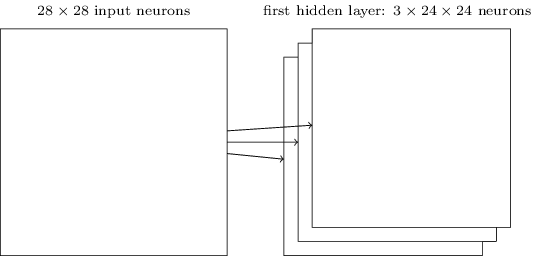
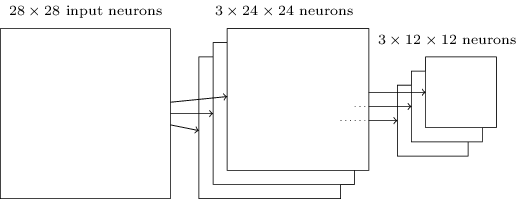
现在,我们可以将所有信息汇总在一起,并获得完整的SNA。它类似于我们最近审查过的体系结构,但是,它具有10个输出神经元的附加层,对应于MNIST数字的10个可能值(“ 0”,“ 1”,“ 2”等):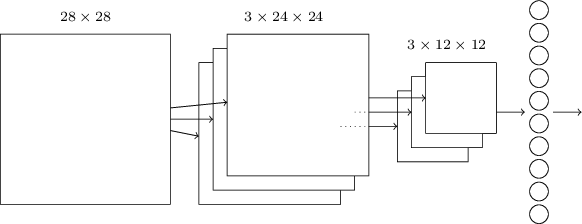 网络从使用的28x28输入神经元开始编码MNIST图像的像素强度。之后是使用局部接收场5x5和3个特征图的卷积层。结果是一层3x24x24隐藏特征神经元。下一步是将最大池化层应用于三个要素地图中每个地图的2x2区域。结果是一层3x12x12的隐藏特征神经元。网络中的最后一层连接已完全连接。也就是说,它将最大池化层的每个神经元连接到10个输出神经元中的每个。我们之前使用了这样的全连接架构。请注意,在上图中,为简单起见,我使用了单个箭头,未显示所有链接。您可以轻松想象它们。这种卷积架构与我们之前使用的非常不同。但是,总体情况是相似的:一个由许多简单元素组成的网络,其行为由权重和偏移确定。目标保持不变:使用训练数据以权重和偏移量训练网络,以便网络很好地对传入的号码进行分类。特别是,如前几章所述,我们将使用随机梯度下降和反向传播训练网络。步骤与以前几乎相同。但是,我们需要对反向传播过程进行一些更改。事实是,我们的反向传播衍生产品旨在用于具有完全连接层的网络。幸运的是,为卷积和最大池化层更改导数非常简单。如果您想了解详细信息,请您尝试解决以下问题。我会警告您,这将需要很多时间,除非您完全了解反向传播的区别的早期问题。
网络从使用的28x28输入神经元开始编码MNIST图像的像素强度。之后是使用局部接收场5x5和3个特征图的卷积层。结果是一层3x24x24隐藏特征神经元。下一步是将最大池化层应用于三个要素地图中每个地图的2x2区域。结果是一层3x12x12的隐藏特征神经元。网络中的最后一层连接已完全连接。也就是说,它将最大池化层的每个神经元连接到10个输出神经元中的每个。我们之前使用了这样的全连接架构。请注意,在上图中,为简单起见,我使用了单个箭头,未显示所有链接。您可以轻松想象它们。这种卷积架构与我们之前使用的非常不同。但是,总体情况是相似的:一个由许多简单元素组成的网络,其行为由权重和偏移确定。目标保持不变:使用训练数据以权重和偏移量训练网络,以便网络很好地对传入的号码进行分类。特别是,如前几章所述,我们将使用随机梯度下降和反向传播训练网络。步骤与以前几乎相同。但是,我们需要对反向传播过程进行一些更改。事实是,我们的反向传播衍生产品旨在用于具有完全连接层的网络。幸运的是,为卷积和最大池化层更改导数非常简单。如果您想了解详细信息,请您尝试解决以下问题。我会警告您,这将需要很多时间,除非您完全了解反向传播的区别的早期问题。挑战赛
- . (BP1)-(BP4). , , - , . ?
我们讨论了SNA背后的想法。让我们通过实现一些SNA并将其应用于MNIST数字分类问题来了解它们在实践中如何工作。我们将使用network3.py程序,它是先前各章中创建的network.py和network2.py程序的改进版本。 network3.py程序使用Theano库文档(尤其是LeNet-5 实现)中的思想,这些思想来自Misha Denil和Chris Olah 的异常实现。该程序代码可在GitHub上获得。在下一节中,我们将研究network3.py程序的代码,在本节中,我们将其用作创建SNA的库。使用Numpy矩阵库以python编写了network.py和network2.py程序。他们基于第一原理进行工作,并获得了反向传播,随机梯度下降等最详细的信息。但是现在,当我们了解这些细节时,对于network3.py,我们将使用Theano机器学习库(请参阅科学工作及其描述)。 Theano还在于在为NA流行的库的心脏Pylearn2和keras,以及来自Caffe和火炬。使用Theano有助于在SNA中实施反向传播,因为它会自动计数所有卡。 Theano还比我们之前的代码(编写该代码是为了便于理解,而不是为了高速工作)要快得多,因此可以合理地将其用于训练更复杂的网络。特别是,Theano的一项出色功能就是在CPU和GPU上都运行代码(如果有)。在GPU上运行可以显着提高速度,并有助于训练更复杂的网络。要与本书并行工作,您需要在系统上安装Theano。为此,请按照项目主页上的说明进行操作。在编写和启动示例时,Theano 0.7已可用。我在没有GPU的Mac OS X Yosemite上进行了一些实验。一些在带有NVIDIA GPU的Ubuntu 14.04上。有些在那里,那里。要启动network3.py,请将代码中的GPU标志设置为True或False。此外,以下说明可以帮助您在GPU上运行Theano 。在线查找培训材料也很容易。如果您没有自己的GPU,则可以使用Amazon Web Services EC2 G2。但是即使使用GPU,我们的代码也无法很快运行。许多实验会从几分钟到几个小时不等。它们在单个CPU上最复杂的将执行几天。与前几章一样,我建议开始实验并继续阅读,并定期检查其操作。不使用GPU,建议您减少最复杂实验的训练时间。为了获得比较的基本结果,让我们从一个浅层结构开始,该结构具有一个包含100个隐藏神经元的隐藏层。我们将研究60个时代,使用学习速度η= 0.1,迷你包装的大小为10,并且我们将不进行正则化学习。在本节中,我设置了特定的培训时代。我这样做是为了使学习过程更清晰。实际上,使用早期停止,跟踪确认集的准确性并在我们确信确认的准确性不再提高时停止训练是很有用的:>>> import network3 >>> from network3 import Network >>> from network3 import ConvPoolLayer, FullyConnectedLayer, SoftmaxLayer >>> training_data, validation_data, test_data = network3.load_data_shared() >>> mini_batch_size = 10 >>> net = Network([ FullyConnectedLayer(n_in=784, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
最佳分类精度为97.80%。 这是分类精度test_data,它是从培训时代开始估算的,在其中,我们从validation_data获得了数据的最佳分类精度。 使用验证数据做出有关准确性评估的决定有助于避免再培训。 然后,我们将这样做。 您的结果可能会略有不同,因为网络权重和偏移量是随机初始化的。
使用相似的网络体系结构和训练超参数,97.80%的准确度非常接近第3章中获得的98.04%的准确度。 特别是,两个示例都使用浅层网络,其中一个隐藏层包含100个隐藏神经元。 两个网络都学习了60个时代,其中最小数据包大小为10,学习率η= 0.1。
但是,早期的网络存在两个差异。 首先,我们进行了正则化以帮助减少再培训的影响。 对当前网络进行规范化可以提高准确性,但不会提高很多,因此我们暂时不会考虑。 其次,尽管早期网络的最后一层使用了S型激活和交叉熵代价函数,但当前网络使用了具有softmax的最后一层,而对数似然函数则作为代价函数。 如第3章所述,这不是重大更改。 由于某些深层原因,我没有从一种方法切换到另一种方法-主要是因为在现代网络中更经常使用softmax和对数似然函数对图像进行分类。
我们可以使用更深的网络架构来改善结果吗?
让我们从在网络的最开始插入一个卷积层开始。 我们将使用5x5的局部接收场,步长为1和20个功能卡。 我们还将插入一个最大池层,该池使用2x2池窗口组合功能。 因此,整个网络架构将与上一节中讨论的架构相似,但具有一个额外的完全连接层:
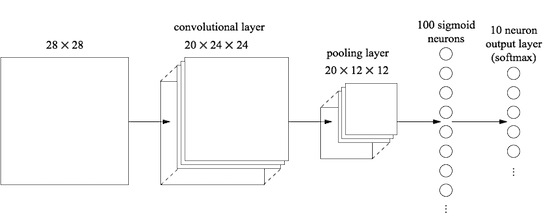
在这种体系结构中,卷积层和池化层在传入的训练图片中包含的局部空间结构中进行训练,而最后一个完全连接的层在更抽象的级别上进行训练,整合了来自整个图像的全局信息。 这是SNA中的常用方案。
让我们训练这样的网络,看看它的行为。
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2)), FullyConnectedLayer(n_in=20*12*12, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
我们获得了98.78%的准确度,大大高于之前的任何结果。 我们将错误减少了三分之一以上-出色的结果。
在描述网络结构时,我将卷积和池化层视为单层。 将它们视为单独的层,或视为单个层-优先考虑。 network3.py认为它们是一层,因为这样代码更紧凑。 但是,很容易修改network3.py,以便可以分别设置图层。
锻炼身体
- 如果降低全连接层并仅使用卷积/池层和softmax层,我们将获得什么样的分类精度? 包含完全连接的层是否有帮助?
我们可以将结果提高98.78%吗?
让我们尝试插入第二个卷积/池化层。 我们将其插入到现有的卷积/池化和完全连接的隐藏层之间。 我们再次使用本地5x5接收域和2x2部分中的池。 让我们看看当我们训练一个具有与以前几乎相同的超参数的网络时会发生什么:
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2)), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2)), FullyConnectedLayer(n_in=40*4*4, n_out=100), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.1, validation_data, test_data)
再一次,我们有了改进:现在,我们获得了99.06%的准确性!
目前,出现了两个自然问题。 第一:使用第二个卷积/池化层是什么意思? 您可以假设在第二个卷积/池化层,输入了“ 12x12”图像,其“像素”代表原始传入图片中某些局部特征的存在(或不存在)。 也就是说,我们可以假定原始传入图像的某个版本进入了该层的输入。 这将是一个更加抽象和简洁的版本,但是它仍然具有足够的空间结构,因此使用第二个卷积/提取层进行处理是有意义的。
令人愉快的观点,但这提出了第二个问题。 在上一层的输出上,获得20个单独的KP,因此20x12x12组输入数据进入第二个卷积/池化层。 事实证明,在卷积/池层中包含了20个单独的图像,而在第一个卷积/池层中却没有一个图像。 那么,来自第二个卷积/池层的神经元如何对许多这些传入图像做出响应? 实际上,我们只允许在进入其局部感受野的所有20x5x5神经元的基础上训练该层的每个神经元。 用一种不太正式的语言,第二个卷积/池层中的特征检测器将有权访问第一层的所有特征,但只能在其特定的局部接受域内。
顺便说一下,如果图像是彩色的,则在第一层中会出现这样的问题。 在这种情况下,我们将为每个像素有3个输入属性,分别对应于原始图像的红色,绿色和蓝色通道。 然后,我们还将使符号检测器可以访问所有颜色信息,但只能在其本地接受域的框架内。
挑战赛
- 使用双曲正切形式的激活函数。 在本书的前面,我多次提到证据,证明tanh函数(双曲正切)可能比S形更适合用作激活函数。 我们没有做任何事情,因为我们在乙状结肠方面取得了很好的进步。 但是,让我们尝试使用tanh作为激活函数的一些实验。 尝试训练具有卷积层和完全连接层的tang激活网络(您可以将activation_fn = tanh作为参数传递给ConvPoolLayer和FullyConnectedLayer类)。 首先从与S型网络相同的超参数开始,然后训练20个时代的网络,而不是60个时代的网络。网络的行为如何? 如果我们持续到60年代,将会发生什么? 尝试建立一个直到60年代按切线和S型曲线确定工作精度的图表。 如果您的结果与我的结果相似,您会发现基于切线的网络学习得更快,但是两个网络的最终精度是相同的。 你能解释为什么会这样吗? 是否可以通过S型来达到相同的学习速度-例如,通过更改学习速度或通过缩放(记住σ(z)=(1 + tanh(z / 2))/ 2)? 尝试五六个不同的超参数或网络体系结构,寻找切线可以在S型曲线之前的位置。 我注意到这个任务是开放的。 就个人而言,尽管我没有进行全面的实验,但在切线时并没有发现任何明显的优势,也许您会发现它们。 无论如何,我们很快就会发现切换到线性化线性激活函数的优势,因此我们将不再研究双曲正切问题。
使用拉直的线性元素
目前,我们开发的网络
是1998年硕果累累的工作中使用的网络选项
之一 ,其中MNIST的任务(即LeNet-5网络)首次提出。 这是进行进一步实验的良好基础,可以提高对问题和直觉的理解。 尤其是,我们可以通过多种方式来更改我们的网络以寻找改善结果的方式。
首先,让我们更改神经元,以便可以使用拉直的线性元素(ReLU)代替使用S型激活函数。 也就是说,我们将使用形式为f(z)≡max(0,z)的激活函数。 我们将训练一个60个时代的网络,速度为η= 0.03。 我还发现,使用带有正则化参数λ= 0.1的L2正则化会更方便一些:
>>> from network3 import ReLU >>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
我的分类精度为99.23%。 与乙状结肠结果相比有一定改善(99.06%)。 但是,在所有实验中,我发现基于ReLU的网络要比基于S型激活功能且具有令人羡慕的恒定性的网络领先。 显然,切换到ReLU来解决此问题具有真正的优势。
是什么使ReLU激活功能优于S型或双曲线正切? 目前,我们对此并不特别了解。 通常认为,函数max(0,z)在较大的z处不会饱和,与S型神经元不同,这有助于ReLU神经元继续学习。 我没有争辩,但是这样的借口不能被称为全面的借口,这只是某种观察(我提醒您我们在
第2章中讨论了饱和)。
ReLU在最近几年开始被积极使用。 采用它们是出于经验原因:有些人尝试ReLU,通常只是基于预感或启发式论证。 他们取得了良好的结果,实践得到了推广。 在理想的世界中,我们会有一个理论告诉我们哪些应用程序哪些激活功能最适合哪些应用程序。 但就目前而言,我们仍然有很长的路要走。 如果通过选择一些更加合适的激活功能可以进一步改善网络的运行,我将不会感到惊讶。 我还期望在未来的几十年中会发展出良好的激活函数理论。 但是今天,我们必须依靠经验不足的经验法则和经验法则。
扩展训练数据
可能有助于我们改善结果的另一种方法是通过算法扩展训练数据。 扩展训练数据的最简单方法是将每个训练图像向上,向下,向右或向左移动一个像素。 这可以通过运行
expand_mnist.py程序来完成。
$ python expand_mnist.py
该计划的启动将50,000个MNIST训练图像转变为250,000个训练图像的扩展集。 然后,我们可以使用这些训练图像来训练网络。 我们将使用与ReLU相同的网络。 在我的第一个实验中,我减少了训练时代的数量-这很有意义,因为我们的训练数据多了5倍。 但是,扩展数据集会大大降低再培训的效果。 因此,在进行了几次实验之后,我回到了60年代。无论如何,让我们训练:
>>> expanded_training_data, _, _ = network3.load_data_shared( "../data/mnist_expanded.pkl.gz") >>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
使用高级培训数据,我获得了99.37%的准确性。 这种几乎微不足道的变化大大提高了分类精度。 而且,正如我们前面所讨论的,算法数据扩展可以进一步发展。 提醒您:2003年,
Simard,Steinkraus和Platt将其网络的准确性提高到99.6%。 他们的网络与我们的网络相似,他们使用了两个卷积/池层,然后是具有100个神经元的完全连接层。 他们的体系结构的细节各不相同-例如,他们没有机会利用ReLU-但是,提高工作质量的关键是扩展培训数据。 他们通过旋转,传输和扭曲MNIST训练图像来实现这一目标。 他们还开发了“弹性变形”过程,模拟了书写时手臂肌肉的随机振动。 通过结合所有这些过程,他们显着增加了培训数据库的有效数量,因此达到了99.6%的准确性。
挑战赛
- 卷积层的思想是不管图像中的位置如何工作。 但是,当我们仅移动输入图像时,对我们的网络进行了更好的培训似乎有点奇怪。 您能解释一下为什么这实际上很合理吗?
添加额外的全连接层
有可能改善这种情况吗? 一种可能性是使用完全相同的过程,但同时增加完全连接层的大小。 我用300个神经元和1000个神经元运行了程序,结果分别为99.46%和99.43%。 这很有趣,但并不比以前的结果(99.37%)更具说服力。
如何添加额外的完全连接层? 让我们尝试添加一个额外的完全连接层,以便我们有两个隐藏的100个神经元完全连接层:
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer(n_in=40*4*4, n_out=100, activation_fn=ReLU), FullyConnectedLayer(n_in=100, n_out=100, activation_fn=ReLU), SoftmaxLayer(n_in=100, n_out=10)], mini_batch_size) >>> net.SGD(expanded_training_data, 60, mini_batch_size, 0.03, validation_data, test_data, lmbda=0.1)
因此,我实现了99.43%的验证准确性。 扩展后的网络再次没有大大提高性能。 在对300和100个神经元的完全连接层进行相似的实验之后,我得到了99.48%和99.47%的准确度。 鼓舞人心,但不像是真正的胜利。
这是怎么回事? 扩展的或附加的完全连接的层是否有可能无法解决MNIST问题? 还是我们的网络可以取得更好的成绩,但我们的发展方向错误? 例如,也许我们可以使用更严格的正则化来减少再培训。 一种可能性是第3章中提到的辍学技术。回想一下,排除的基本思想是在训练网络时随机删除各个激活。 结果,该模型变得更能抵抗个人证据的丢失,因此,它不太可能依赖训练数据的一些小的非标准特征。 让我们尝试将异常应用于最后一个完全连接的层:
>>> net = Network([ ConvPoolLayer(image_shape=(mini_batch_size, 1, 28, 28), filter_shape=(20, 1, 5, 5), poolsize=(2, 2), activation_fn=ReLU), ConvPoolLayer(image_shape=(mini_batch_size, 20, 12, 12), filter_shape=(40, 20, 5, 5), poolsize=(2, 2), activation_fn=ReLU), FullyConnectedLayer( n_in=40*4*4, n_out=1000, activation_fn=ReLU, p_dropout=0.5), FullyConnectedLayer( n_in=1000, n_out=1000, activation_fn=ReLU, p_dropout=0.5), SoftmaxLayer(n_in=1000, n_out=10, p_dropout=0.5)], mini_batch_size) >>> net.SGD(expanded_training_data, 40, mini_batch_size, 0.03, validation_data, test_data)
使用这种方法,我们达到了99.60%的准确度,这比以前的准确度要好得多,尤其是我们的基本评估-具有100个隐藏神经元的网络,其准确度为99.37%。
这里有两个变化值得注意。
首先,我将训练时代的数量减少到40个:例外减少了重新训练的时间,而且我们学习得更快。
其次,完全连接的隐藏层包含1000个神经元,而不是以前的100个。 当然,事实上,例外是在训练过程中消除了许多神经元,因此我们应该期待某种扩展。 实际上,我对300和1000个神经元进行了实验,在1000个神经元的情况下,我得到了更好的确认。
使用网络集成
提高效率的一种简单方法是创建多个神经网络,然后让它们投票以进行更好的分类。 例如,假设我们使用上述配方训练了5个不同的NS,并且每个NS的准确率均接近99.6%。 尽管所有网络都将显示相似的准确性,但是由于随机初始化不同,它们可能具有不同的错误。 可以合理地假设,如果以5 NA投票,它们的总体分类将优于任何网络的分类。
听起来实在令人难以置信,但是组装这种合奏对国民议会和其他MO技术来说都是常见的窍门。 实际上,它提高了效率:我们获得了99.67%的精度。 换句话说,我们的网络整体正确分类了所有10,000个验证图片,但33个除外。
其余错误如下所示。 根据MNIST数据,右上角的标签是正确的分类,而右下角的标签是网络集成收到的标签:
值得留意图像。 前两位数字6和5是我们合奏的真正错误。 但是,可以理解,这样的错误可能是人为错误。 这个6确实非常类似于0,而5则非常类似于3。第三个图片,据说是8,看起来更像是9。 另一方面,第四个图像6确实被网络错误地分类了。
依此类推。 在大多数情况下,网络解决方案似乎是合理的,并且在某些情况下,他们可以比个人编写的数字更好地对数字进行分类。 总的来说,我们的网络表现出了非凡的效率,尤其是当我们回想起它们正确分类了9967个图像时,我们在此不介绍它们。
在这种情况下,可以理解几个明显的错误。甚至一个谨慎的人有时也会犯错。因此,我只能期望只有非常准确和有条理的人才能取得更好的结果。我们的网络正在接近人类的表现。为什么我们只将异常应用于完全连接的层
如果仔细查看上面的代码,您会发现我们仅将异常应用于完全连接的网络层,而不应用于卷积层。原则上,类似的过程可以应用于卷积层。但这是没有必要的:卷积层具有显着的内置抗重新训练能力。这是因为总权重使卷积滤波器可以一次学习整个图片。结果,他们不太可能因训练数据中的某些局部失真而跳闸。因此,不需要特别将其他正则化规则应用于它们,例如异常。继续前进
您可以进一步提高解决MNIST问题的效率。罗德里戈·本宁森(Rodrigo Benenson)整理了内容丰富的平板电脑,展示了多年来的进展以及与工作的联系。许多作品使用GSS的方式与我们使用它们的方式大致相同。如果翻阅工作,您会发现许多有趣的技术,并且您可能希望实现其中的一些技术。在这种情况下,明智的做法是从可以快速培训的简单网络开始实施,这将帮助您快速开始了解正在发生的事情。在大多数情况下,我不会尝试回顾最近的工作。但是我无法抗拒一个例外。这是2010年的一部作品。我喜欢她的朴素。该网络是多层的,仅使用完全连接的层(无卷积)。在他们最成功的网络中,隐藏的层分别包含2500、2000、1500、1000和500个神经元。他们使用类似的想法来扩展训练数据。但是除此之外,他们还应用了其他技巧,包括缺乏卷积层:这是最简单的香草网络,如果有足够的耐心和适当的计算机功能,可以在1980年代(如果那时存在MNIST的话)就可以教它。他们达到了99.65%的分类准确率,与我们的大致吻合。他们工作的主要内容是使用超大型且深度的网络,以及使用GPU加速学习。这使他们学习了许多时代。他们还利用了较长的培训间隔时间,并将学习速度从10逐渐降低-3至10 -6。尝试使用类似的架构来达到类似的结果是一个有趣的练习。我们为什么要学习?
在上一章中,我们看到了学习深度多层NS的基本障碍。特别是,我们看到渐变变得非常不稳定:当从输出层移动到先前的渐变时,渐变易于消失(渐变消失的问题)或爆炸性增长(爆炸性梯度增长的问题)。由于梯度是我们用于训练的信号,因此会引起问题。我们如何设法避免它们?答案自然是这样的:我们无法避免它们。取而代之的是,尽管如此,我们做了一些让我们继续工作的事情。特别是:(1)卷积层的使用大大减少了其中包含的参数的数量,极大地促进了学习问题; (2)使用更有效的正则化技术(排除层和卷积层); (3)使用ReLU代替乙状神经元来加速学习-根据经验可达到3-5倍; (4)GPU的使用和随着时间的推移而学习的能力。特别是在最近的实验中,我们使用比标准MNIST训练数据大5倍的数据集研究了40个时代。在本书的前面,我们主要使用标准训练数据研究了30个时代。因素(3)和(4)的组合会产生这样的效果,好像我们的学习时间比以前多了30倍。您可能会说:“就这些吗?”这是训练深度神经网络所需的全部吗?又因为什么大惊小怪起火了?”当然,我们使用了其他想法:足够大的数据集(以帮助避免重新训练);正确的成本函数(以避免学习放慢);良好的权重初始化(也避免了由于神经元饱和而导致学习速度减慢);训练数据集的算法扩展。我们在前面的章节中讨论了这些以及其他想法,并且通常我们在本章中有机会以一些小注释重用它们。从所有迹象看,这是一组相当简单的想法。简单,但是,在复杂环境中使用时,可以发挥很多作用。事实证明,深度学习入门非常容易!?
如果我们将卷积/池化层视为一个层,那么在我们的最终体系结构中将有4个隐藏层。这样的网络是否值得冠名?自然地,4个隐藏层比我们之前研究的浅层网络要多得多。大多数网络都有一个隐藏层,有时是2。另一方面,现代高级网络有时也有几十个隐藏层。有时我遇到一些人,他们认为网络越深入越好,并且如果您不使用足够多的隐藏层,则意味着您并不是在真正地进行深度学习。我不这么认为,尤其是因为这种方法将深度学习的定义变成了依赖于瞬时结果的过程。这一领域的真正突破是超越具有一两个隐藏层的网络的实用性的想法,在2000年代中期盛行。这是真正的突破,为具有更多表现力模型的研究领域开辟了道路。好吧,特定数量的层并不是基本的关注点。深度网络的使用是实现其他目标(例如提高分类准确性)的工具。程序问题
在本节中,我们从具有一个隐藏层的浅层网络平稳地转换为多层卷积网络。一切似乎都很简单!我们进行了更改并得到了改善。如果您开始尝试,我保证通常情况下一切都不会如此顺利。我向您介绍了一个精妙的故事,省略了许多实验,包括未成功的实验。我希望这个精妙的故事将有助于您更好地理解基本思想。但是他冒着传达不完整印象的风险。要获得一个良好的,有效的网络,需要大量的反复试验,并充满挫败感。在实践中,您可以期待大量的实验。为了加快该过程,第3章中有关网络超参数选择的信息以及此处提到的其他文献可以为您提供帮助。卷积网络代码
好了,现在让我们来看一下network3.py程序的代码。从结构上讲,它类似于我们在第3章中开发的network2.py,但是由于使用了Theano库,因此细节有所不同。让我们从FullyConnectedLayer类开始,类似于我们之前研究的层。 class FullyConnectedLayer(object): def __init__(self, n_in, n_out, activation_fn=sigmoid, p_dropout=0.0): self.n_in = n_in self.n_out = n_out self.activation_fn = activation_fn self.p_dropout = p_dropout
大部分__init__方法都能说明问题,但是一些注释可以帮助澄清代码。与往常一样,我们使用具有适当标准偏差的正常随机值随机初始化权重和偏移量。这些行看起来有点难以理解。但是,大多数奇怪的代码都将权重和偏移量加载到Theano库称为共享变量的位置。这样可以确保可以在GPU上处理变量(如果有)。我们不会深入研究这个问题-如果有兴趣,请阅读Theano的文档。还要注意,权重和偏移的这种初始化是针对S型激活函数的。理想情况下,对于双曲正切和ReLU之类的函数,我们将以不同的方式初始化权重和偏移量。在以后的任务中将讨论此问题。__init__方法以语句self.params = [self.w,self.b]结尾。这是将与图层关联的所有学习参数汇总在一起的便捷方法。 Network.SGD稍后使用params属性来找出可以训练Network类实例中的哪些变量。set_inpt方法用于将输入传递到图层并计算相应的输出。我写inpt而不是输入,因为输入是内置的python函数,如果您使用它们,这会导致程序行为无法预测,并且难以诊断错误。实际上,我们以两种方式传递输入:通过self.inpt和self.inpt_dropout。这样做是因为我们可能希望在训练期间使用异常。然后,我们将需要删除部分self.p_dropout神经元。这就是set_inpt方法的倒数第二行中的dropout_layer函数的作用。因此,在训练期间使用self.inpt_dropout和self.output_dropout,并将self.inpt和self.output用于所有其他目的,例如,评估验证和测试数据的准确性。ConvPoolLayer和SoftmaxLayer的类定义与FullyConnectedLayer相似。非常相似,我什至不会引用代码。如果您有兴趣,可以在本章后面研究程序的完整代码。值得一提的是几个不同的细节。显然,在ConvPoolLayer和SoftmaxLayer中,我们以适合图层类型的方式计算输出激活。幸运的是,Theano易于实现,它具有用于计算卷积,最大池化和softmax函数的内置操作。如何在softmax层中初始化权重和偏移量不太明显-我们没有讨论这一点。我们提到对于S型权重层,有必要初始化适当参数化的正态随机分布。但是,这种启发式论点适用于乙状结肠神经元(以及经过较小的修正也适用于糖神经元)。但是,没有特别的理由将此参数应用于softmax层。因此,没有理由先验地再次应用此初始化。相反,我将所有权重和偏移量都初始化为0。该选项是自发的,但在实践中效果很好。因此,我们研究了所有类别的图层。网络类呢?让我们从探索__init__方法开始: class Network(object): def __init__(self, layers, mini_batch_size): """ layers, , mini_batch_size """ self.layers = layers self.mini_batch_size = mini_batch_size self.params = [param for layer in self.layers for param in layer.params] self.x = T.matrix("x") self.y = T.ivector("y") init_layer = self.layers[0] init_layer.set_inpt(self.x, self.x, self.mini_batch_size) for j in xrange(1, len(self.layers)): prev_layer, layer = self.layers[j-1], self.layers[j] layer.set_inpt( prev_layer.output, prev_layer.output_dropout, self.mini_batch_size) self.output = self.layers[-1].output self.output_dropout = self.layers[-1].output_dropout
大多数代码可以说明一切。 self.params = [...中的层的参数]行将每个层的所有参数收集到一个列表中。如前所述,Network.SGD方法使用self.params来确定网络可以从中学习哪些参数。 self.x = T.matrix(“ x”)和self.y = T.ivector(“ y”)行定义Theano x和y符号变量。它们将代表网络的输入和所需的输出。这不是有关使用Theano的教程,因此,我将不讨论符号变量的含义(请参阅文档,以及其中的一个教程))粗略地说,它们表示数学变量,而不是特定的变量。使用它们,您可以执行许多常规操作:加,减,乘,应用函数,等等。 Theano为处理此类符号变量,卷积,最大拉动等提供了许多可能性。但是,最主要的是,可以使用反向传播算法的非常通用的形式快速进行符号微分。这对于将随机梯度下降应用于各种网络体系结构非常有用。特别是,以下几行代码定义了网络的符号输出。我们首先将输入分配给第一层: init_layer.set_inpt(self.x, self.x, self.mini_batch_size)
输入数据一次只发送一个小数据包,因此在此指示其大小。我们两次传递self.x的输入:事实是我们可以两种不同的方式使用网络(有或没有例外)。 for循环通过网络层传播符号变量self.x。这使我们能够定义最终属性output和output_dropout,它们象征性地表示Network的输出。在处理了Network的初始化之后,让我们看一下SGD方法的训练。该代码看起来很长,但是其结构非常简单。解释遵循以下代码: def SGD(self, training_data, epochs, mini_batch_size, eta, validation_data, test_data, lmbda=0.0): """ - .""" training_x, training_y = training_data validation_x, validation_y = validation_data test_x, test_y = test_data
第一行很清楚,它们将数据集分为分量x和y,并计算每个数据集中使用的微型数据包的数量。以下几行更加有趣,它们说明了为什么与Theano库一起工作如此有趣。我在这里引用它们:
在这些行中,我们基于对数似然函数象征性地定义正则化成本函数,计算梯度函数中的相应导数,以及相应的参数更新。 Theano允许我们在短短几行中完成所有这些操作。唯一隐藏的是,成本的计算涉及为输出层调用成本方法。此代码位于network3.py中的其他位置。但这很简短。有了所有这些的定义,一切就绪,就可以定义train_mb函数了,Theano符号函数使用更新通过微型数据包索引来更新网络参数。同样,validate_mb_accuracy和test_mb_accuracy函数可在任何给定的验证或验证数据小数据包上计算网络准确性。平均这些功能,我们可以计算整个验证和验证数据集的准确性。SGD方法的其余部分是不言而喻的-我们只需依次经历各个时期,就训练数据的微型数据包一次又一次地训练网络,并计算确认和验证的准确性。现在,我们了解了network3.py这一年中最重要的部分。让我们简要介绍一下整个程序。不必详细研究所有内容,但您可能想翻阅最高记录,并可能会研究一些特别喜欢的文章。但是,当然,理解程序的最佳方法是更改程序,添加新内容,重构那些您认为可以改进的部分。在代码之后,我提出了一些任务,其中包含一些有关可以在此处完成的工作的初步建议。这是代码。 """network3.py ~~~~~~~~~~~~~~ Theano . (, , -, softmax) (, , ReLU; ). CPU , network.py network2.py. , , GPU, . Theano, network.py network2.py. , . , API network2.py. , , . , , . Theano (http://deeplearning.net/tutorial/lenet.html ), (https://github.com/mdenil/dropout ) (http://colah.imtqy.com ). Theano 0.6 0.7, . """
任务
- SGD . , . network3.py , .
- Network , .
- SGD , η ( , , , ).
- , . network3.py, . , , . .
- .
- – . , , , ? .
- ReLU , ( -) . . , ReLU ( ). , c>0 c L−1 , L – . , softmax? ReLU? ? , , . , ReLU.
- . , ReLU? , ? : «» . – , - - .