几个月前,我遇到了一个问题,我的基于机器学习算法的模型根本无法正常工作。 我想了很长时间,想如何解决这个问题,在某个时候,我意识到我的知识非常有限,我的想法很匮乏。 我知道几十个模型,这只是那些非常有用的作品的很小一部分。
首先想到的是,如果我了解和理解更多模型,那么作为研究人员和工程师的整体素质将会提高。 这个想法促使我研究了最近的机器学习会议上的文章。 构造此类信息非常困难,并且有必要记录方法之间的依赖关系。 我不想以表或列表的形式呈现依赖关系,但我想要更自然的东西。 结果,我意识到拥有一个在模型及其组件之间具有边缘的三维图形看起来非常有趣。
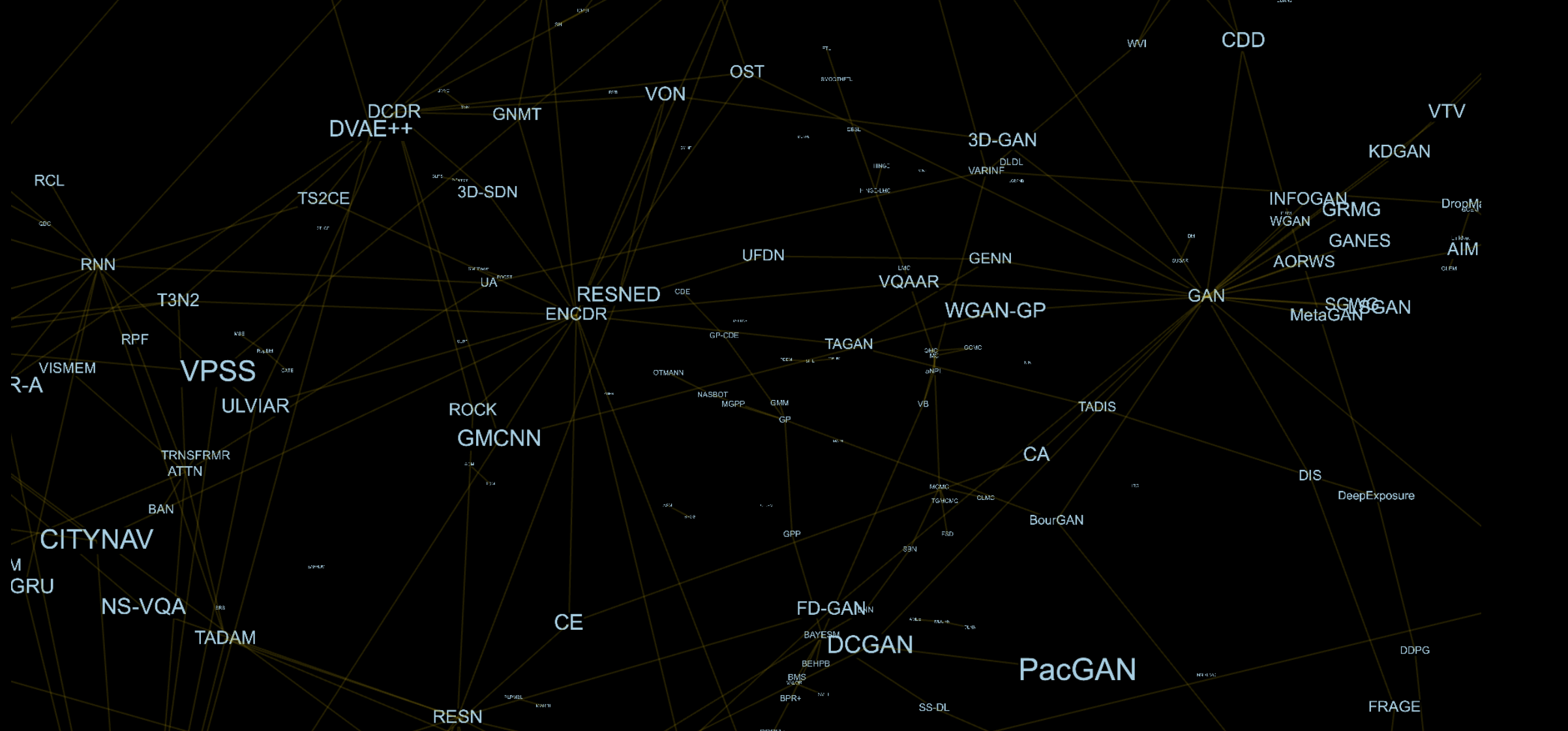
例如,在架构上GAN [1]由生成器(GEN)和鉴别器(DIS)组成,对抗自动编码器(AAE)[2]由自动编码器(AE)[3]和DIS组成。 在此图中,每个分量都是单独的顶点,因此对于AAE,我们将具有AE和DIS的边。
我一步一步地分析了这些文章,写出了它们所包含的方法,在哪些主题领域中应用,在哪些数据上进行了测试等等。 在此过程中,我意识到有多少非常有趣的解决方案仍然未知,并且找不到它们的应用。
机器学习分为主题领域,其中每个领域都尝试使用特定方法解决特定问题。 近年来,边界几乎被消除了,实际上很难识别仅在特定区域中使用的组件。 这种趋势通常会导致结果改善,但是问题在于,随着文章数量的增加,许多有趣的方法被忽略了。 造成这种情况的原因有很多,大公司仅在某些地区的普及在其中起着重要作用。 意识到这一点,以前被严格定义为个人的图形便成为公开且开放的图形。
自然,我进行了研究,并试图找到与我所做的类似的事情。 有足够的服务可让您监视此区域中新文章的出现。 但是所有这些方法的主要目的是简化知识的获取,而不是帮助创造新的想法。 创造力比经验更重要,而可以帮助您从不同方向思考并获得更完整图片的工具,在我看来,这应该成为研究过程中不可或缺的一部分。
我们拥有使实验,启动和评估模型更加容易的工具,但没有使我们快速生成和评估想法的方法。
在短短的几个月内,我整理了上次NeurIPS会议上的约250篇文章,以及它们所基于的约250篇其他文章。 大多数领域对我来说都是完全陌生的,花了几天的时间才了解它们。 有时,我只是找不到模型的正确描述以及它们组成的组件。 从此开始,第二个合乎逻辑的步骤是为作者提供了自己在图中添加和更改方法的可能性,因为除本文作者之外,没有人知道如何以最佳方式解析和描述他们的方法。
结果提供了一个示例。
我希望这个项目对某人有用,也许仅仅是因为它可能使某人获得可以带来新的有趣想法的联想。 当我听到生成竞争性网络的想法是如何建立时,我感到很惊讶。 在MIT机器智能播客[4]中,Yan Goodfellow说对抗网络的思想与Boltzman机器[5]的“正”和“负”训练阶段有关。
该项目是社区驱动的。 我想开发它,并激励更多的人在此添加有关其方法的信息,或编辑已完成的工作。 我相信,更准确的方法信息和更好的可视化技术将真正帮助使其成为一个有用的工具。
从改进可视化本身开始,到可以构建单个图形的能力,最终有可能获得改进方法建议的能力,项目的开发空间很大。
一些技术
细节可以在这里找到 。
[1] Ian J. Goodfellow,Jean Pouget-Abadie,Mehdi Mirza,Bing Xu,David Warde-Farley,Sherjil Ozair,Aaron Courville,Yoshua Bengio。 生成对抗网。[2] Alireza Makhzani,Jonathon Shlens,Navdeep Jaitly,Ian Goodfellow,Brendan Frey。 对抗性自动编码器。[3] Dana H. Ballard。 自动编码器。[4] Ian J. Goodfellow:麻省理工学院的人工智能播客。[5] Ruslan Salakhutdinov,杰弗里·欣顿。 深博茨曼机器