
计算语言学协会(ACL)的年会是最重要的自然语言处理会议。 它自1962年以来就组织起来。 在加拿大和澳大利亚之后,她回到欧洲并在佛罗伦萨游行。 因此,与类似的EMNLP相比,今年它在欧洲研究人员中更受欢迎。
今年发表了2900篇论文中的660篇。 数量巨大。 几乎不可能对会议的内容进行某种客观的审查。 因此,我将从这次事件中告诉我主观感受。
我参加了此次会议,在海报发布会上展示了Kaggle竞赛对Google的
性别代词解析 做出的决定 。 我们的解决方案在很大程度上依赖于使用预
训练的BERT模型 。 而且,事实证明,我们并不孤单。
词源学

有太多基于BERT的作品描述了它的属性并将其用作基础,甚至出现了术语Bertology。 的确,BERT模型非常成功,以至于甚至大型研究小组也将其模型与BERT进行了比较。
因此,在6月初,有关
XLNet的工作出现了。 在会议之前
-ERNIE 2.0和
RoBERTaFacebook的罗伯塔
当XLNet模型首次引入时,一些研究人员认为,不仅由于其体系结构和训练原理,它还取得了更好的结果。 她还研究了比BERT大的身体(几乎10倍)和更长的时间(迭代4倍)。
Facebook的研究人员表明,BERT尚未达到最大值。 他们提出了一种用于教授BERT模型的优化方法-RoBERTa(严格优化的BERT方法)。
在不改变模型架构的情况下,他们改变了训练过程:
- 我们增加了训练的身体,批次的大小,序列的长度和训练的持续时间。
- 预测下一个句子的任务已从训练中删除。
- 他们开始动态生成MASK令牌(模型在预训练期间尝试预测的令牌)。
百度的ERNIE 2.0
像所有最近流行的模型(BERT,GPT,XLM,RoBERTa,XLNet)一样,ERNIE基于具有自注意机制的变压器的概念。 它与其他模型的区别在于多任务学习和连续学习的概念。
ERNIE学习不同的任务,并不断更新其语言模型的内部表示形式。 与其他模型一样,这些任务具有自我学习(自我监督和弱监督)的目标。 此类任务的示例:
- 恢复句子中正确的单词顺序。
- 大写单词。
- 屏蔽词的定义。
在这些任务上,模型按顺序学习,返回到先前训练的任务。
罗伯塔vs埃涅
在出版物中,RoBERTa和ERNIE没有相互比较,因为它们几乎同时出现。 将它们与BERT和XLNet进行比较。 但是,在这里进行比较并不容易。 例如,在流行的
基准测试中,GLUE XLNet由一组模型表示。 来自百度的研究人员对比较单个模型更感兴趣。 此外,由于百度是一家中国公司,所以他们也有兴趣比较使用中文的结果。 最近,出现了一个新的基准:
SuperGLUE 。 解决方案还不多,但RoBERTa在这里排在首位。
但总体而言,RoBERTa和ERNIE的性能均优于XLNet,并且显着优于BERT。 反过来,RoBERTa的性能比ERNIE略好。
知识图
致力于将两种方法结合起来的工作很多:预先训练的网络和以知识图形式(知识图,KG)使用规则。
例如:
ERNIE:具有信息实体的增强语言表示 。 本文重点介绍了在BERT语言模型上知识图的使用。 这样一来,您可以在确定实体类型(
实体类型)和关系分类 。
通常,用芝麻街的角色名称来选择模型名称的方式会导致有趣的后果。 例如,这个ERNIE与我上面写的百度的ERNIE 2.0没有关系。

关于生成新知识的另一项有趣的工作是:
COMET:用于自动知识图构建的常识变压器 。 本文考虑了使用基于变压器的新架构来培训基于知识的网络的可能性。 简化形式的知识库有许多三元组:主题,态度和对象。 他们采用了两个知识库数据集:ATOMIC和ConceptNet。 并且他们训练了基于GPT(可预训练变压器)模型的网络。 输入主题和态度,并尝试预测对象。 因此,他们得到了一个通过输入主题和关系生成对象的模型。
指标
会议上另一个有趣的话题是选择指标的问题。 通常很难在自然语言处理任务中评估模型的质量,这会减慢该机器学习领域的进展。
在
《适当的评分范围 》
中的“研究汇总评估指标”中 ,Maxim Peyar讨论了文本汇总问题中各种指标的使用。 这些度量标准并不总是相互关联良好,这会干扰各种算法的客观比较。
或者这是一项有趣的工作:
多句子文本的自动评估 。 在其中,作者提出了一个指标,该指标可以代替需要评估多个句子的文本的任务的BLEU和ROUGE。
BLEU指标可以表示为“精度”-目标中包含模型响应中的多少个单词(或n克)。 ROUGE是Recall-模型的响应中包含来自目标的几个单词(或n-gram)。
本文中提出的度量标准基于WMD(单词移动器的距离)度量标准-两个文档之间的距离。 它等于两个句子中单词之间的最小距离,在这些单词的矢量表示空间内。 在教程中可以找到有关WMD的更多信息,该教程使用
了Word2Vec和
GloVe的WMD 。
在他们的文章中,他们提供了一个新的指标:WMS(Word Mover的相似性)。
WMS(A, B) = exp(−WMD(A, B))
然后,他们定义SMS(句子移动器的相似性)。 它使用类似于WMS的方法。 作为句子的向量表示,它们采用句子单词的平均向量。
在计算WMS时,单词会根据其在文档中的频率进行归一化。 在计算SMS句子时,将根据句子中的单词数对其进行归一化。
最后,S + WMS指标是WMS和SMS的组合。 他们在文章中指出,他们的指标与个人的人工评估更好地相关。
聊天机器人
我认为这次会议最有用的部分是张贴会议。 并非所有报告都很有趣,但是如果您开始听一些报告,您将不会在报告中间离开。 海报是另一回事。 在发布会上有几十个。 您可以选择自己喜欢的选项,通常可以直接与开发人员讨论技术细节。 顺便说一下,有一个有趣的站点,上面
放着会议海报 。 的确,那里有两次会议的海报,目前尚不清楚该网站是否会更新。
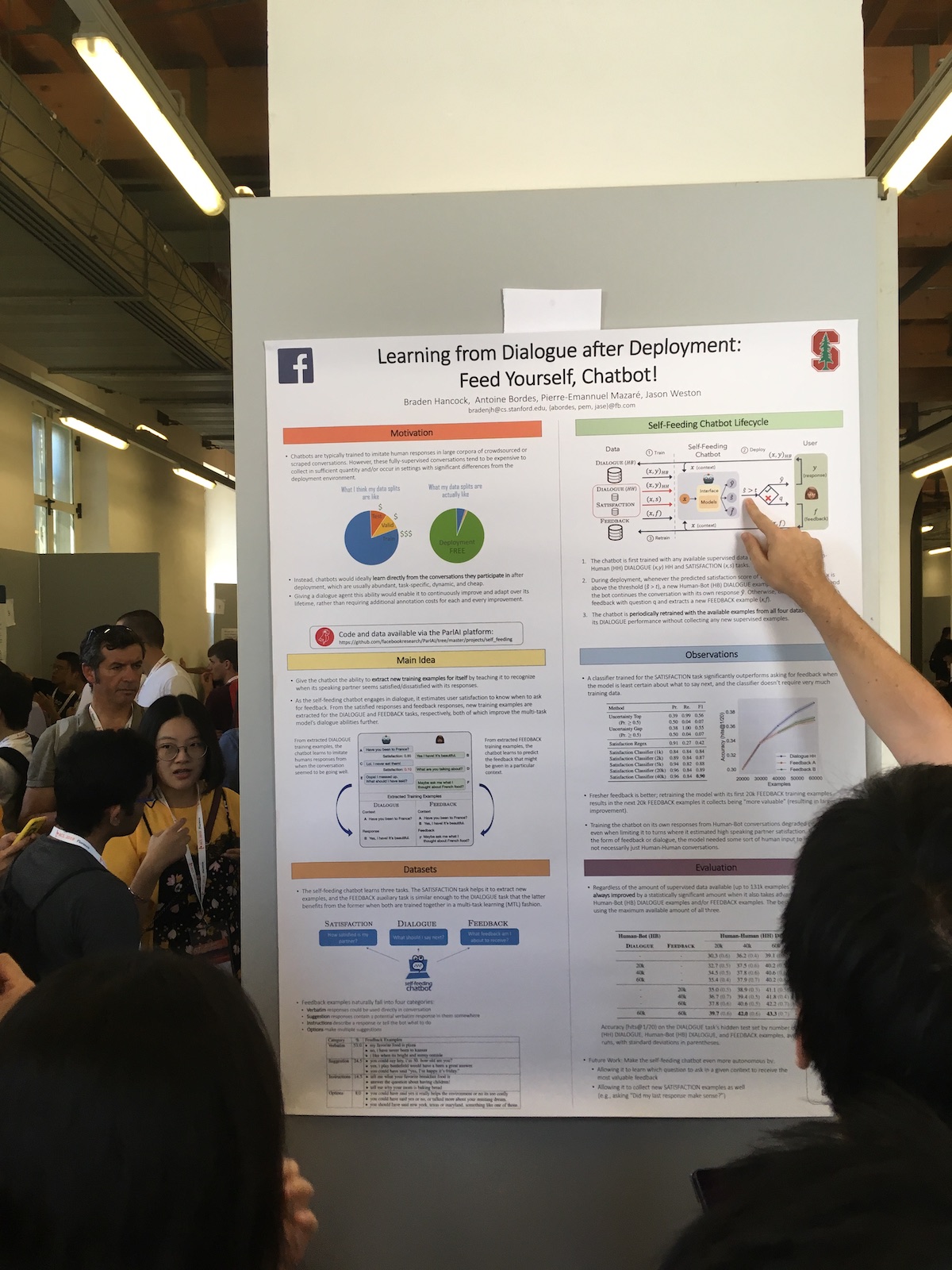
在发布会上,大型公司经常展示有趣的作品。 例如,这是Facebook上的文章
:部署后从对话中学习:自给自足,聊天机器人! 。
他们系统的独特之处在于用户响应的扩展使用。 他们有一个分类器,用于评估用户对对话的满意度。 他们将这些信息用于不同的任务:
- 使用满意度的度量作为质量度量。
- 他们训练模型,从而采用了持续学习的方法(Continuous Learning)。
- 直接在对话框中使用。 如果用户满意,请表达一些人情味。 或者他们问如果用户不满意怎么办。
在报告中,有一个关于Microsoft的中文聊天机器人的有趣故事。
善解人意的社交聊天机器人XiaoIce的设计与实现中国已经是引入人工智能技术的领导者之一。 但是,在中国经常发生的事情在欧洲并不为人所知。 小冰是一个了不起的项目。 它已经存在了五年。 这个年龄的聊天机器人目前还没有很多。 在2018年,它已经有6.6亿用户。
该系统同时具有聊天机器人和技能系统。 该机器人已经拥有230项技能,也就是说,他们每周大约增加一项技能。
为了评估聊天机器人的质量,他们使用了对话的持续时间。 而不是像通常那样在几分钟内完成,而是在对话中复制的数量。 他们称此为“每次会话转化次数(CPS)”,并写道,目前其平均值为23,这是同类系统中最好的指标。
总的来说,该项目在中国很受欢迎。 除了机器人本身之外,该系统还可以编写诗歌,绘画,
发布衣服 ,唱歌等。
机器翻译
在我参加的所有演讲中,最活跃的是代表百度研究的梁煌的
同声传译报告。
他谈到了现代同声翻译中的此类困难:
- 世界上只有3,000名经过认证的同声传译员。
- 译员只能连续工作15-20分钟。
- 仅翻译了大约60%的源文本。
整个句子的翻译已经达到了很高的水平,但是对于同声翻译来说,仍有改进的空间。 例如,他列举了他们的同声传译系统,该系统在百度世界会议上发挥了作用。 与2017年相比,2018年的翻译延迟从10秒减少到3秒。
这样做的团队并不多,并且几乎没有工作系统。 例如,当Google翻译您在线上写的短语时,它会不断重新制作最终的短语。 这不是同步翻译,因为使用同步翻译我们无法更改已经说过的单词。

在他们的系统中,他们使用前缀翻译-短语的一部分。 也就是说,他们等了几句话然后开始翻译,试图猜测在源代码中将出现什么。 这种移位的大小以字为单位,并且是自适应的。 在每个步骤之后,系统都会决定是否值得等待,或者是否已经可以翻译。 为了评估此延迟,他们引入了以下度量:
平均滞后(AL)度量 。
同声翻译的主要困难是语言中的单词顺序不同。 上下文有助于解决这一问题。 例如,您经常需要翻译政治家的讲话,而且他们的陈规定型观念。 但是也有问题。 然后,演讲者对特朗普开玩笑。 因此,他说,如果布什飞往莫斯科,那么很可能与普京会面。 如果特朗普飞往,那么他可以见面打高尔夫球。 通常,在翻译时,人们经常会想出自己要加的东西。 可以说,如果您需要翻译某种笑话,而他们却不能马上翻译,他们可以说:“这里说的是个笑话,只是笑。”
还有一篇有关机器翻译的文章获得了“最佳长篇论文”奖:
弥合神经机器翻译在训练和推理之间的鸿沟 。
它描述了这样的机器翻译问题。 在学习过程中,我们根据已知单词的上下文生成逐词翻译。 在使用模型的过程中,我们依赖于新生成的单词的上下文。 在训练模型和使用模型之间存在差异。
为了减少这种差异,作者建议在训练阶段的上下文中混合训练过程中模型预测的单词。 本文讨论了此类生成词的最佳选择。
结论
当然,会议不仅仅是文章和报告。 它还是通信,约会和其他网络。 另外,会议组织者正在设法以某种方式招待参与者。 在ACL的主要聚会上,都有男高音演奏,毕竟是意大利。 总而言之,其他会议的组织者也发布了公告。 与会者中最猛烈的反应是来自EMNLP组织者的消息,即今年的主要聚会将在香港迪士尼乐园举行,2020年的会议将在多米尼加共和国举行。