
在本文中,我想使用Scala的函数式编程概念提供一种替代传统测试设计样式的方法。 这种方法的灵感来自数十个数百次跌落测试的支持,以及长达数月的痛苦,并且他们迫切希望使它们更容易理解。
尽管该代码是用Scala编写的,但所提出的思想对于所有支持功能编程范例的语言的开发人员和测试人员都是有意义的。 您可以在本文末尾找到指向Github的链接以及完整的解决方案和示例。
问题
如果您曾经处理过测试(没关系-单元测试,集成或功能),则很可能它们是作为一组顺序指令编写的。 例如:
对于大多数(不需要开发)描述测试的方法,这是首选方法。 我们的项目有大约1000个不同级别的测试(单元测试,集成测试,端到端),并且直到最近,所有这些都是以相似的风格编写的。 随着项目的发展,在此类测试的支持下,我们开始感到严重的问题和放缓:将测试整理好比编写与业务相关的代码花费的时间更少。
在编写新测试时,您总是必须从头开始思考如何准备数据。 通常是从邻近测试复制粘贴步骤。 结果,当应用程序中的数据模型发生更改时,纸牌屋就崩溃了,每次测试都必须以新的方式收集:最好的情况下,助手功能只会发生变化,最坏的情况是-完全沉浸在测试中并重写它。
当测试诚实地崩溃时(即是由于业务逻辑中的错误,而不是由于测试本身存在问题),就不可能在没有调试的情况下弄明白哪里出了问题。 由于花了很长时间才能理解测试,因此没有人完全了解需求-系统在特定条件下应如何运行。
所有这些痛苦是此设计的两个更深层问题的症状:
- 测试内容不得过于宽松。 每个测试都是独一无二的,就像雪花一样。 需要阅读测试的详细信息会花费很多时间,并且会降低动力。 不重要的细节会分散主要内容-测试验证的要求。 复制粘贴已成为编写新测试用例的主要方法。
- 测试不能帮助开发人员定位错误,而只能表示问题。 要了解测试的执行状态,您需要将其恢复到头脑中或与调试器连接。
造型
我们可以做得更好吗? (扰流器:我们可以。)让我们看看该测试的内容。
val db: Database = Database.forURL(TestConfig.generateNewUrl()) migrateDb(db) insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
通常,经过测试的代码将等待输入一些明确的参数-标识符,大小,体积,过滤器等。此外,它通常需要来自真实世界的数据-我们看到该应用程序引用了菜单和菜单模板数据库。 为了可靠地执行测试,我们需要确定-测试开始之前系统和/或数据提供程序应处于的状态以及通常与该状态相关的输入参数。
我们将使用此固定装置准备依赖项 -填充数据库(队列,外部服务等)。 利用准备好的依赖关系,我们初始化测试的类(服务,模块,存储库等)。
val svc = new SomeProductionLogic(db) val result = svc.calculatePrice(packageId = 1)
通过在某些输入参数上执行测试代码,我们获得了业务上有意义的结果 ( 输出 )-显式(由方法返回)和隐式-臭名昭著的状态变化:数据库,外部服务等。
result shouldBe 90
最后,我们验证结果是否与预期完全一致,并用一个或多个断言对测试进行总结。
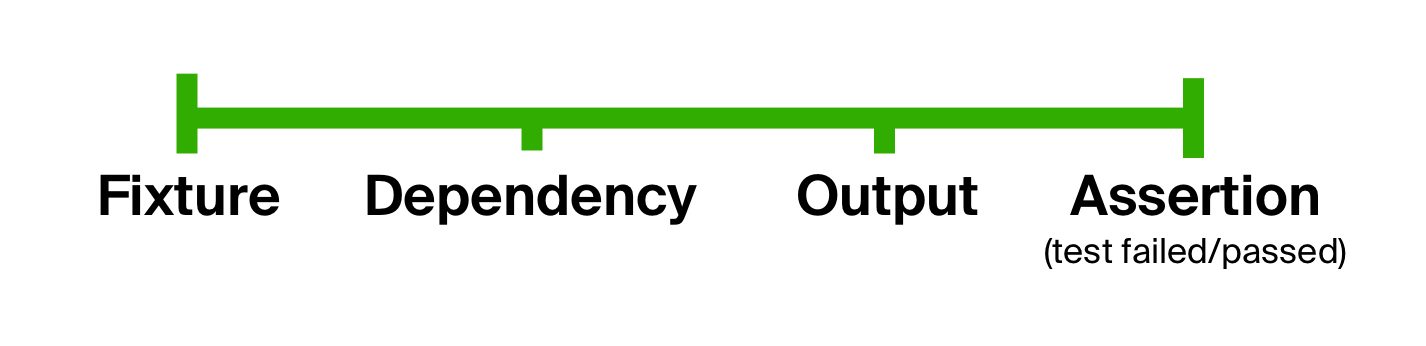
可以得出结论,通常,测试包括相同的阶段:准备输入参数,在输入参数上执行测试代码以及将结果与预期参数进行比较。 我们可以利用这一事实来消除测试中的第一个问题 -过于宽松的形式,将测试明确划分为多个阶段。 这个想法并不是什么新鲜事物,并且早已在BDD样式( 行为驱动的开发 )的测试中使用。
可扩展性如何? 测试过程中的任何步骤都可以包含任意多个中间步骤。 展望未来,我们可以形成一个固定装置,首先创建一种人类可读的结构,然后将其转换为填充数据库的对象。 测试过程可以无限扩展,但是最终,它始终可以归结为主要阶段。

运行测试
让我们尝试实现将测试划分为多个阶段的想法,但是首先我们确定如何查看最终结果。
总的来说,我们希望使编写和支持测试的工作量减少,工作过程变得更轻松。 测试主体中不太明确的非唯一(在其他地方重复)的指令,在更改合同或重构后需要对测试进行的更改更少,并且读取测试所需的时间也更少。 测试的设计应鼓励重用经常使用的代码段,并防止不必要的复制。 如果测试具有统一的外观,那就太好了。 可预测性提高了可读性并节省了时间-想象一下,如果物理学生用自由形式的单词而不是数学语言来描述它们,那么掌握每个新公式将花费多少时间。
因此,我们的目标是隐藏所有分散注意力和多余的信息,只保留对于理解应用程序至关重要的信息:测试什么,输入期望什么以及输出期望什么。
让我们回到测试设备的模型。 从技术上讲,此图上的每个点都可以由一种数据类型表示,并且可以从一个功能转换为另一个功能。 通过将以下函数一个接一个地应用于上一个的结果,可以从初始数据类型到最终数据类型。 换句话说,使用功能的组合 :准备数据(我们称其为prepare ),执行测试代码( execute )和检查预期结果( check )。 我们将图表的第一点(夹具)传递到此组合的输入。 所得的高阶函数称为测试生命周期函数 。
生命周期功能 def runTestCycle[FX, DEP, OUT, F[_]]( fixture: FX, prepare: FX => DEP, execute: DEP => OUT, check: OUT => F[Assertion] ): F[Assertion] =
问题是,内部功能来自哪里? 我们将以有限的方式准备数据-填充数据库,弄湿数据库等-因此,prepare功能的选项对于所有测试都是通用的。 结果,更容易制作专门的生命周期功能来隐藏数据准备的特定实现。 由于对于每个测试调用被检查代码和检查代码的方法相对唯一,因此将显式提供execute和check 。
通过将所有管理上的细微差别委派给生命周期功能,我们有机会扩展测试过程,而无需进行任何已编写的测试。 由于组成原因,我们可以渗透到过程中的任何地方,在那里提取或添加数据。
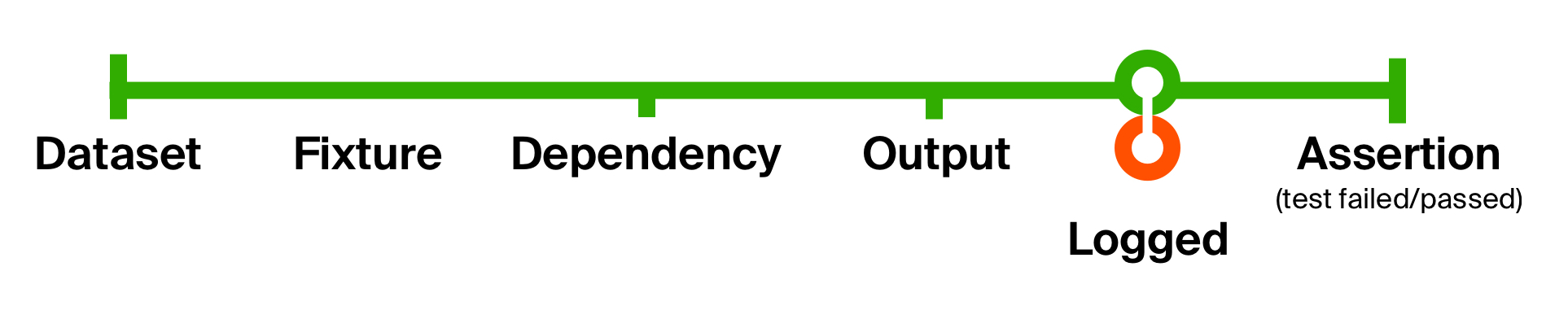
为了更好地说明这种方法的可能性,我们将解决初始测试的第二个问题 -缺乏支持信息以定位问题。 从测试方法收到响应时,添加日志记录。 我们的日志记录不会更改数据类型,而只会产生副作用 -在控制台上显示一条消息。 因此,在产生副作用之后,我们将按原样返回它。
记录生命周期功能 def logged[T](implicit loggedT: Logged[T]): T => T = (that: T) => {
通过如此简单的动作,我们在每个测试中添加了返回结果的日志记录和数据库状态。 这些小功能的优点是易于理解,易于重用,并且在不再需要它们时也很容易摆脱。

结果,我们的测试将如下所示:
val fixture: SomeMagicalFixture = ???
测试的主体已经变得简洁,固定装置和检查可以在其他测试中重复使用,我们不会在其他任何地方手动准备数据库。 只剩下一个问题...
治具准备
在上面的代码中,我们使用了以下假设:固定装置将来自现成的地方,并且只需要转移到生命周期函数中即可。 由于数据是简单且受支持的测试中的关键要素,因此我们不得不谈谈如何形成数据。
假设我们的测试存储区有一个典型的中型数据库(为简单起见,示例包含4个表,但实际上可能有数百个)。 部分包含背景信息,部分包含直接业务,并且所有这些都可以连接到多个成熟的逻辑实体中。 表通过键( 外键 )互连-要创建Bonus实体,您需要Package实体,然后是User 。 依此类推。

电路受限的情况和各种故障会导致不一致,并因此测试不稳定和令人兴奋的调试时间。 因此,我们将诚实地填充数据库。
我们可以使用军事方法来填补,但即使对此概念进行了表面研究,仍然出现了许多困难的问题。 如何为这些方法本身准备测试数据? 如果合同发生变化,是否需要重写测试? 如果数据是由未经测试的应用程序交付的(例如,由其他人导入)怎么办? 为了创建依赖于许多其他实体的实体,必须执行多少个不同的查询?
在初始测试中填充基础 insertUser(db, id = 1, name = "test", role = "customer") insertPackage(db, id = 1, name = "test", userId = 1, status = "new") insertPackageItems(db, id = 1, packageId = 1, name = "test", price = 30) insertPackageItems(db, id = 2, packageId = 1, name = "test", price = 20) insertPackageItems(db, id = 3, packageId = 1, name = "test", price = 40)
就像原始示例中那样,分散的帮助程序方法是相同的问题,但是酱汁不同。 他们将管理依赖对象及其与自己之间的关系的责任分配给我们,我们希望避免这种情况。
理想情况下,我希望拥有这种类型的数据,乍一看就足以大致了解测试期间系统将处于何种状态。 状态可视化的最佳候选者之一是表(PHP和Python中的la 数据集 ),其中除了对业务逻辑至关重要的字段外,没有任何多余的东西。 如果功能中的业务逻辑发生变化,则所有测试支持都将减少,从而无法更新数据集中的单元格。 例如:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) )
从我们的表中,我们将生成键 -按ID的实体关系。 在这种情况下,如果实体依赖于另一个实体,则将为该依赖关系形成一个密钥。 可能会发生两个不同的实体生成具有相同标识符的依赖关系,这可能导致违反对数据库主键 ( primary key )的限制。 但是在这一点上,重复数据删除非常便宜-由于密钥仅包含标识符,因此我们可以将其放入提供重复数据删除的集合中,例如Set 。 如果事实证明这还不够的话,我们总是可以以编译为生命周期函数的附加函数的形式进行更智能的重复数据删除。
关键例子 sealed trait Key case class PackageKey(id: Int, userId: Int) extends Key case class PackageItemKey(id: Int, packageId: Int) extends Key case class UserKey(id: Int) extends Key case class BonusKey(id: Int, packageId: Int) extends Key
我们将伪造内容的生成委托给单独类的字段(例如,名称)。 然后,借助此类的帮助以及转换键的规则,我们得到直接用于插入数据库的字符串对象。
行示例 object SampleData { def name: String = "test name" def role: String = "customer" def price: Int = 1000 def bonusAmount: Int = 0 def status: String = "new" } sealed trait Row case class PackageRow(id: Int, name: String, userId: Int, status: String) extends Row case class PackageItemRow(id: Int, packageId: Int, name: String, price: Int) extends Row case class UserRow(id: Int, name: String, role: String) extends Row case class BonusRow(id: Int, packageId: Int, bonusAmount: Int) extends Row
通常,默认的伪造数据对我们来说是不够的,因此我们将需要能够重新定义特定字段。 我们可以使用镜头 -遍历所有创建的行,并仅更改需要的字段。 由于最后的镜片是普通功能,因此可以将它们合成,这就是它们的用处。
镜头示例 def changeUserRole(userId: Int, newRole: String): Set[Row] => Set[Row] = (rows: Set[Row]) => rows.modifyAll(_.each.when[UserRow]) .using(r => if (r.id == userId) r.modify(_.role).setTo(newRole) else r)
由于结构的原因,我们可以在整个过程中进行各种优化和改进-例如,对表中的行进行分组,以便可以一次insert ,减少测试时间或保护数据库的最终状态以简化捕获问题。
治具整形功能 def makeFixture[STATE, FX, ROW, F[_]]( state: STATE, applyOverrides: F[ROW] => F[ROW] = x => x ): FX = (extractKeys andThen deduplicateKeys andThen enrichWithSampleData andThen applyOverrides andThen logged andThen buildFixture) (state)
总之,这将为我们提供一个满足测试依赖性的固定装置-数据库。 在测试本身中,除了原始数据集之外,什么都看不到-所有细节都将隐藏在函数的组成部分内。

现在,我们的测试套件将如下所示:
val dataTable: Seq[DataRow] = Table( ("Package ID", "Customer's role", "Item prices", "Bonus value", "Expected final price") , (1, "customer", Vector(40, 20, 30) , Vector.empty , 90.0) , (2, "customer", Vector(250) , Vector.empty , 225.0) , (3, "customer", Vector(100, 120, 30) , Vector(40) , 210.0) , (4, "customer", Vector(100, 120, 30, 100) , Vector(20, 20) , 279.0) , (5, "vip" , Vector(100, 120, 30, 100, 50), Vector(10, 20, 10), 252.0) ) " -" - { "'customer'" - { " " - { "< 250 - " - { "(: )" in calculatePriceFor(dataTable, 1) "(: )" in calculatePriceFor(dataTable, 3) } ">= 250 " - { " - 10% " in calculatePriceFor(dataTable, 2) " - 10% " in calculatePriceFor(dataTable, 4) } } } "'vip' - 20% , " in calculatePriceFor(dataTable, 5) }
辅助代码:
在表中添加新的测试用例变得很简单,它使您可以专注于覆盖最大数量的边界条件 ,而不是一个样板。
在其他项目上重用夹具准备代码
好吧,我们写了很多代码在一个特定的项目中准备夹具,为此花了很多时间。 如果我们有几个项目怎么办? 我们是否注定每次都要重新发明轮子并复制粘贴?
我们可以从特定领域模型中抽象出夹具的准备。 在FP领域中,有一个typeclass的概念。 简而言之,类型类不是OOP中的类,而是类似接口的类,它们定义了一些类型组行为。 根本的区别在于,这组类型不是由类继承决定的,而是由实例化决定的,就像普通变量一样。 与继承一样,在编译阶段静态 地解析类型类的实例(通过隐式 )。 为简单起见,出于我们的目的,可以将类型类视为Kotlin和C#的 扩展 。
要质押一个对象,我们不需要知道该对象内部具有什么,它具有哪些字段和方法。 对我们而言,唯一重要的是为其定义具有特定签名的log行为。 在每个类中实现特定的Logged接口会很Logged ,而且并非总是可能的-例如,在库或标准类中。 对于类型类,一切都简单得多。 我们可以为设备创建Logged Logged的实例,并以可读的形式显示它。 对于所有其他类型,请为Any类型创建一个实例,并使用标准toString方法免费记录其内部表示形式中的任何对象。
Tagged类及其实例的示例 trait Logged[A] { def log(a: A)(implicit logger: Logger): A }
除了日志记录,我们还可以将此方法扩展到准备夹具的整个过程。 测试解决方案将提供其自己的时间类以及基于它们的功能的抽象实现。 使用它的项目的责任是为类型编写自己的类型类实例。
在设计夹具生成器时,我专注于编程原理和SOLID设计的实现,以表明其稳定性和对不同系统的适应性:
- 单一职责原则 :每个类型类仅描述类型行为的一个方面。
- 开放式封闭原则 :我们不会修改测试的现有战斗类型,而是使用tyclass实例进行扩展。
- Liskov替代原则在这种情况下无关紧要,因为我们不使用继承。
- 接口隔离原则 :我们使用许多专门的时间类,而不是一个全局的时间类。
- 依赖倒置原则 :夹具生成器的实现不依赖于特定的战斗类型,而是依赖于抽象的时间类。
在确保所有原则都得到满足之后,可以说我们的解决方案看起来得到了足够的支持和扩展,可以在不同的项目中使用它。
编写了生命周期,固定装置的生成以及将数据集转换为固定装置的功能,以及从应用程序的特定领域模型中抽象出来的功能,我们终于可以将解决方案扩展到所有测试。
总结
我们从传统的(逐步的)测试设计风格转变为实用的测试设计风格。 在早期和小型项目中,循序渐进的风格是好的,因为它不需要额外的劳力,也不会限制开发人员,但是当在项目上进行大量测试时,它就会开始丢失。 功能样式并不是为了解决测试中的所有问题而设计的,但是它可以极大地方便数量成千上万的项目中测试的扩展和支持。 功能样式测试更紧凑,并且专注于真正重要的内容(数据,测试代码和预期结果),而不是中间步骤。
另外,我们看了一个生动的例子,说明了组合和类型类的概念在函数式编程中的功能多么强大。 在他们的帮助下,易于设计解决方案,其中不可或缺的一部分是可扩展性和可重用性。
, , , . , , , -. , . !
: Github