上一次,我们讨论了
对象级锁 ,特别是关系上的锁。 今天,我们将了解PostgreSQL中行锁的排列方式以及它们如何与对象锁一起使用,让我们讨论等待队列以及那些不合时宜的人。
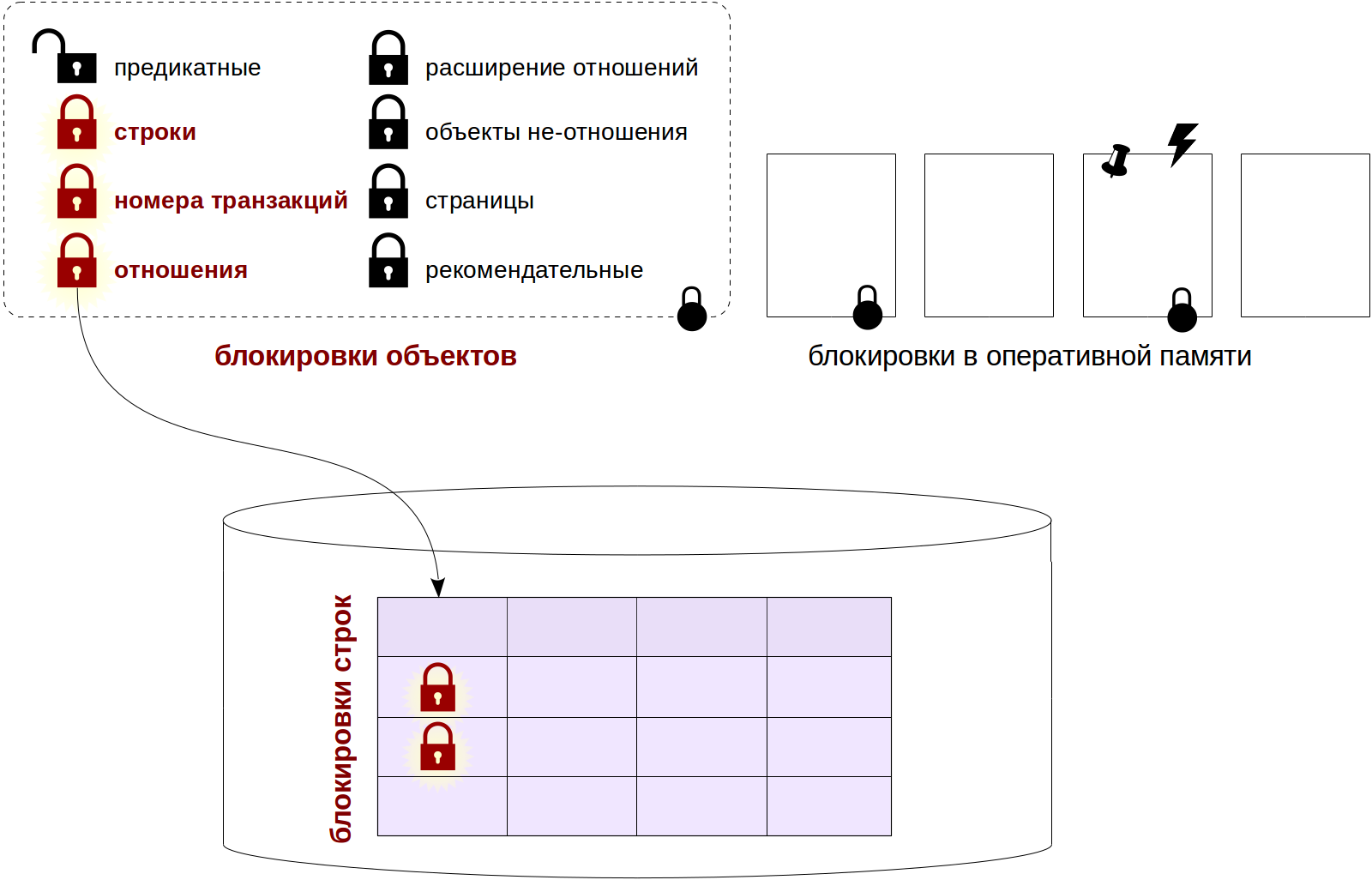
行锁
装置
让我提醒您上一篇文章的几个重要结论。
- 服务器共享内存中必须存在某个锁。
- 锁的粒度越高,同时运行的进程之间的竞争(争用)就越少。
- 另一方面,粒度越高,锁占用的内存空间就越大。
我们当然希望更改一行不阻塞同一表的其他行。 但是我们不能以自己的锁开始每一行。
有多种方法可以解决此问题。 在某些DBMS中,锁的级别有所增加:如果行级别的锁太多,则将它们替换为另一个普通的锁(例如,页面级或整个表)。
稍后我们将看到,PostgreSQL也使用这种机制,但仅用于谓词锁定。 线路锁不同。
在PostgreSQL中,行被锁定的信息仅排他地存储在数据页内的
行版本中 (而不存储在RAM中)。 也就是说,从通常意义上讲,这根本不是一个障碍,而只是一个信号。 该符号实际上是xmax事务编号以及其他信息位的组合。 稍后,我们将详细了解其工作原理。
优点是我们可以在不占用任何资源的情况下根据需要阻塞任意多行。
但是有一个
缺点 :由于关于锁的信息没有显示在RAM中,因此其他进程无法排队。 而且没有监视的可能性(要计算锁,您需要读取整个表)。
很好,监视很好,但是需要对队列进行一些操作。 为此,您仍然必须使用“常规”锁。 实际上,如果我们需要等到行被释放后,我们就必须等到阻塞事务结束时,即在提交或回滚时释放所有锁。 为此,您可以请求阻止交易的阻止编号(我记得,该交易由交易本身以特殊模式持有)。 因此,使用的锁数与同时运行的进程数成正比,而不与要更改的行数成正比。
特殊模式
总共有4种可以锁定线路的模式。 其中,两种模式代表
排他锁,一次只能拥有一个事务。
- FOR UPDATE模式意味着一行的完整更改(或删除)。
- FOR NO KEY UPDATE模式-仅更改不包含在唯一索引中的那些字段(换句话说,进行这样的更改,所有外键均保持不变)。
UPDATE命令本身会选择最小的适当锁定模式。 通常行以FOR NO KEY UPDATE模式锁定。
记得您在删除或更改行时,当前交易版本号被写入当前当前版本的xmax字段中。 它显示该事务已删除该行的版本。 因此,相同的xmax数用作阻止的标志。 实际上,如果该行版本中的xmax对应于一个活动(尚未完成)的事务,并且我们要更新该特定行,则我们必须等待该事务完成,因此不需要其他符号。
让我们看看。 创建一个帐户表,与上一篇文章相同。
=> CREATE TABLE accounts( acc_no integer PRIMARY KEY, amount numeric ); => INSERT INTO accounts VALUES (1, 100.00), (2, 200.00), (3, 300.00);
当然,要查看页面,我们需要已经熟悉的pageinspect扩展。
=> CREATE EXTENSION pageinspect;
为了方便起见,创建一个仅显示我们感兴趣的信息的视图:xmax和一些信息位。
=> CREATE VIEW accounts_v AS SELECT '(0,'||lp||')' AS ctid, t_xmax as xmax, CASE WHEN (t_infomask & 128) > 0 THEN 't' END AS lock_only, CASE WHEN (t_infomask & 4096) > 0 THEN 't' END AS is_multi, CASE WHEN (t_infomask2 & 8192) > 0 THEN 't' END AS keys_upd, CASE WHEN (t_infomask & 16) > 0 THEN 't' END AS keyshr_lock, CASE WHEN (t_infomask & 16+64) = 16+64 THEN 't' END AS shr_lock FROM heap_page_items(get_raw_page('accounts',0)) ORDER BY lp;
因此,我们开始交易并更新第一个帐户的金额(密钥不变)和第二个帐户的编号(密钥改变):
=> BEGIN; => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1; => UPDATE accounts SET acc_no = 20 WHERE acc_no = 2;
我们调查一下视图:
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock -------+--------+-----------+----------+----------+-------------+---------- (0,1) | 530492 | | | | | (0,2) | 530492 | | | t | | (2 rows)
锁定模式由keys_updated信息位确定。
当使用SELECT FOR UPDATE命令锁定行时,也会使用相同的xmax字段,但是在这种情况下,会放下一个附加的信息位(xmax_lock_only),这表明该行的版本仅被锁定,而未被删除,并且仍然相关。
=> ROLLBACK; => BEGIN; => SELECT * FROM accounts WHERE acc_no = 1 FOR NO KEY UPDATE; => SELECT * FROM accounts WHERE acc_no = 2 FOR UPDATE;
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock -------+--------+-----------+----------+----------+-------------+---------- (0,1) | 530493 | t | | | | (0,2) | 530493 | t | | t | | (2 rows)
=> ROLLBACK;
共享模式
另外两种模式表示可以由多个事务持有的共享锁。
- 当您需要读取字符串时,可以使用FOR SHARE模式,但是您不能允许其他事务以任何方式更改它。
- FOR KEY SHARE模式允许更改字符串,但只能更改非关键字段。 PostgreSQL在检查外键时会自动使用此模式。
让我们看看。
=> BEGIN; => SELECT * FROM accounts WHERE acc_no = 1 FOR KEY SHARE; => SELECT * FROM accounts WHERE acc_no = 2 FOR SHARE;
在行版本中,我们看到:
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock -------+--------+-----------+----------+----------+-------------+---------- (0,1) | 530494 | t | | | t | (0,2) | 530494 | t | | | t | t (2 rows)
在这两种情况下,keyshr_lock位置1,并且可以通过再查看一个信息位来识别SHARE模式。
通用模式兼容性矩阵如下所示。
它表明:
- 例外模式相互冲突;
- 共享模式彼此兼容;
- 共享的FOR KEY SHARE模式与独占的FOR NO KEY UPDATE模式兼容(也就是说,您可以同时更新非关键字段,并确保关键不变。)
多重交易
到目前为止,我们认为锁定由xmax字段中阻止事务的数量表示。 但是共享锁可以由多个事务持有,并且不能将多个数字写入同一xmax字段。 如何成为
对于共享锁,使用了所谓的
多事务(MultiXact)。 这是一个分配了单独编号的交易组。 该编号与常规交易编号具有相同的维度,但是编号是独立分配的(也就是说,系统可以具有相同的交易编号和多交易编号)。 为了彼此区分,使用了另一个信息位(xmax_is_multi),有关该组成员和锁定模式的详细信息位于$ PGDATA / pg_multixact /目录中的文件中。 当然,最后使用的数据存储在服务器共享内存的缓冲区中,以加快访问速度。
在现有锁中添加另一个由另一个事务执行的例外锁(我们可以这样做,因为FOR KEY SHARE和FOR NO KEY UPDATE模式彼此兼容):
| => BEGIN; | => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
=> SELECT * FROM accounts_v LIMIT 2;
ctid | xmax | lock_only | is_multi | keys_upd | keyshr_lock | shr_lock -------+--------+-----------+----------+----------+-------------+---------- (0,1) | 61 | | t | | | (0,2) | 530494 | t | | | t | t (2 rows)
在第一行中,我们看到通常的数字已由多事务处理数字代替-xmax_is_multi位证明了这一点。
为了不深入研究多事务实现的内部,可以使用另一个扩展,该扩展允许您方便地查看有关所有类型的行锁的所有信息。
=> CREATE EXTENSION pgrowlocks; => SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]----------------------------- locked_row | (0,1) locker | 61 multi | t xids | {530494,530495} modes | {"Key Share","No Key Update"} pids | {5892,5928} -[ RECORD 2 ]----------------------------- locked_row | (0,2) locker | 530494 multi | f xids | {530494} modes | {"For Share"} pids | {5892}
=> COMMIT;
| => ROLLBACK;
冻结设定
由于将单独的数字分配给写在行版本的xmax字段中的多重事务,由于计数器位容量的限制,它们遇到与常规数字相同的xid环绕
问题 。
因此,对于多笔交易编号,还必须执行冻结的模拟-用新的编号替换旧的编号(如果冻结时仅由一个交易持有,则用常规的交易编号替换)。
请注意,仅对xmin字段执行普通交易编号的冻结(因为该行的版本具有非空的xmax字段,那么它要么是不相关的版本,它将被清除,或者xmax交易被取消并且其编号对我们不感兴趣)。 但是对于多重事务,我们正在谈论该行当前版本的xmax字段,该字段可以保持相关,但是在共享模式下,它经常被不同事务阻塞。
对于多
事务冻结,与通常冻结的参数类似的参数
负责 :
vacuum_multixact_freeze_min_age ,
vacuum_multixact_freeze_table_age ,
autovacuum_multixact_freeze_max_age 。
谁是极端?
逐渐接近甜头。 让我们看看几个事务将更新同一行时的锁情况。
让我们首先在pg_locks上构建一个视图。 首先,我们将得出的结论更为紧凑,其次,我们将自己限制在有趣的锁上(实际上,我们将放弃虚拟交易编号,帐户表上的索引,pg_locks和视图本身的锁),通常,所有不相关的内容以及只分散注意力)。
=> CREATE VIEW locks_v AS SELECT pid, locktype, CASE locktype WHEN 'relation' THEN relation::regclass::text WHEN 'transactionid' THEN transactionid::text WHEN 'tuple' THEN relation::regclass::text||':'||tuple::text END AS lockid, mode, granted FROM pg_locks WHERE locktype in ('relation','transactionid','tuple') AND (locktype != 'relation' OR relation = 'accounts'::regclass);
现在开始第一个事务并更新该行。
=> BEGIN; => SELECT txid_current(), pg_backend_pid();
txid_current | pg_backend_pid --------------+---------------- 530497 | 5892 (1 row)
=> UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
UPDATE 1
那锁呢?
=> SELECT * FROM locks_v WHERE pid = 5892;
pid | locktype | lockid | mode | granted ------+---------------+----------+------------------+--------- 5892 | relation | accounts | RowExclusiveLock | t 5892 | transactionid | 530497 | ExclusiveLock | t (2 rows)
事务保存表和自己的数字锁。 到目前为止,一切都可以期待。
我们开始第二笔交易,并尝试更新同一行。
| => BEGIN; | => SELECT txid_current(), pg_backend_pid();
| txid_current | pg_backend_pid | --------------+---------------- | 530498 | 5928 | (1 row)
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
那第二笔交易锁呢?
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted ------+---------------+------------+------------------+--------- 5928 | relation | accounts | RowExclusiveLock | t 5928 | transactionid | 530498 | ExclusiveLock | t 5928 | transactionid | 530497 | ShareLock | f 5928 | tuple | accounts:1 | ExclusiveLock | t (4 rows)
这里更有趣。 除了锁定表和自己的号码外,我们还会看到两个锁。 第二笔交易发现该行被首先锁定,并“挂起”等待其编号(已授予= f)。 但是,行版本锁(locktype = tuple)的来源和来源为何?
不要混淆行版本锁(元组锁)和行锁(行锁)。 第一个是常规元组类型锁,在pg_locks中可见。 第二个是数据页中的标记:xmax和信息位。
当事务要更改行时,它将执行以下操作序列:
- 在字符串(元组)的可变版本上捕获排他锁。
- 如果xmax和信息位指示该行已锁定,则它要求锁定xmax事务号。
- 规定其xmax和必要的信息位。
- 释放行版本锁。
当该行由第一个事务更新时,它也抓住了行版本锁(步骤1),但立即释放了它(步骤4)。
当第二笔交易到达时,她捕获了行版本锁(项目1),但被迫要求对第一笔交易(项目2)的编号进行锁定并挂起。
如果出现第三次类似的交易会怎样? 她将尝试捕获该行版本的锁(项目1),并且将在此步骤中挂起。 看看吧。
|| => BEGIN; || => SELECT txid_current(), pg_backend_pid();
|| txid_current | pg_backend_pid || --------------+---------------- || 530499 | 5964 || (1 row)
|| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
=> SELECT * FROM locks_v WHERE pid = 5964;
pid | locktype | lockid | mode | granted ------+---------------+------------+------------------+--------- 5964 | relation | accounts | RowExclusiveLock | t 5964 | tuple | accounts:1 | ExclusiveLock | f 5964 | transactionid | 530499 | ExclusiveLock | t (3 rows)
希望更新同一行的第四,第五个等事务与事务3不会有任何不同,它们都将“挂起”在同一行版本锁上。
将另一个事务添加到堆。
||| => BEGIN; ||| => SELECT txid_current(), pg_backend_pid();
||| txid_current | pg_backend_pid ||| --------------+---------------- ||| 530500 | 6000 ||| (1 row)
||| => UPDATE accounts SET amount = amount - 100.00 WHERE acc_no = 1;
=> SELECT * FROM locks_v WHERE pid = 6000;
pid | locktype | lockid | mode | granted ------+---------------+------------+------------------+--------- 6000 | relation | accounts | RowExclusiveLock | t 6000 | transactionid | 530500 | ExclusiveLock | t 6000 | tuple | accounts:1 | ExclusiveLock | f (3 rows)
可以在pg_stat_activity视图中看到当前期望的一般情况,其中添加了有关阻塞过程的信息:
=> SELECT pid, wait_event_type, wait_event, pg_blocking_pids(pid) FROM pg_stat_activity WHERE backend_type = 'client backend';
pid | wait_event_type | wait_event | pg_blocking_pids ------+-----------------+---------------+------------------ 5892 | | | {} 5928 | Lock | transactionid | {5892} 5964 | Lock | tuple | {5928} 6000 | Lock | tuple | {5928,5964} (4 rows)
事实证明,这是一种“队列”,其中有第一个(保留字符串的锁版本的队列),而所有其他队列都排在第一个后面。
为什么我们需要如此复杂的设计? 假设我们没有该字符串的版本锁。 然后第二个和第三个(依此类推)事务将等待第一个事务的编号阻塞。 在第一个事务完成时,被阻塞的资源消失了(
您在这里做什么,嗯?事务已结束 ),现在这完全取决于操作系统将首先唤醒哪个等待的进程,因此,将有时间锁定该行。 所有其他进程也将被唤醒,但是它们将不得不再次排队-现在在另一个进程之后。
这充满了这样的事实,即某些交易可以无限期地等待交易,如果由于不幸的情况而导致交易总是围绕其他交易进行。 用英语将这种情况称为锁定饥饿。
在我们的例子中,结果大致相同,但还好一点:第二个事务保证了它可以访问下一个资源。 但是接下来(第三和第四)会发生什么呢?
如果第一个事务以回滚结束,一切都会好起来的:传入的事务将按照它们排列的顺序进行。
但是-运气不好-如果第一个事务以一次提交完成,那么不仅事务号消失了,而且行的版本也消失了! 也就是说,该版本当然仍然存在,但不再相关,因此有必要更新(同一行的)完全不同的最新版本。 轮到的资源消失了,每个人都在争夺拥有新资源的机会。
让第一笔交易完成。
=> COMMIT;
第二笔交易将被唤醒并执行段落。 3和4。
| UPDATE 1
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted ------+---------------+----------+------------------+--------- 5928 | relation | accounts | RowExclusiveLock | t 5928 | transactionid | 530498 | ExclusiveLock | t (2 rows)
那第三笔交易呢? 她跳过了步骤1(因为资源已消失),并停留在步骤2:
=> SELECT * FROM locks_v WHERE pid = 5964;
pid | locktype | lockid | mode | granted ------+---------------+----------+------------------+--------- 5964 | relation | accounts | RowExclusiveLock | t 5964 | transactionid | 530498 | ShareLock | f 5964 | transactionid | 530499 | ExclusiveLock | t (3 rows)
同样的事情发生在第四笔交易中:
=> SELECT * FROM locks_v WHERE pid = 6000;
pid | locktype | lockid | mode | granted ------+---------------+----------+------------------+--------- 6000 | relation | accounts | RowExclusiveLock | t 6000 | transactionid | 530498 | ShareLock | f 6000 | transactionid | 530500 | ExclusiveLock | t (3 rows)
也就是说,第三和第四笔交易都在等待第二笔交易的完成。 队伍变成了
南瓜人群。
我们完成了所有已开始的交易。
| => COMMIT;
|| UPDATE 1
|| => COMMIT;
||| UPDATE 1
||| => COMMIT;
有关阻塞字符串的更多详细信息,请参见README.tuplock 。
你不是站在这里
因此,两级阻止方案的思想是减少永恒等待“运气不好”交易的可能性。 然而,正如我们已经看到的那样,这种情况很有可能发生。 而且,如果应用程序使用共享锁,那么一切都会变得更糟。
让第一个事务以共享模式锁定该行。
=> BEGIN; => SELECT txid_current(), pg_backend_pid();
txid_current | pg_backend_pid --------------+---------------- 530501 | 5892 (1 row)
=> SELECT * FROM accounts WHERE acc_no = 1 FOR SHARE;
acc_no | amount --------+-------- 1 | 100.00 (1 row)
第二个事务尝试更新同一行,但不能-SHARE和NO KEY UPDATE模式不兼容。
| => BEGIN; | => SELECT txid_current(), pg_backend_pid();
| txid_current | pg_backend_pid | --------------+---------------- | 530502 | 5928 | (1 row)
| => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
第二个事务等待第一个事务完成,并保持行版本锁定-现在,一切都像上次一样。
=> SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted ------+---------------+-------------+------------------+--------- 5928 | relation | accounts | RowExclusiveLock | t 5928 | tuple | accounts:10 | ExclusiveLock | t 5928 | transactionid | 530501 | ShareLock | f 5928 | transactionid | 530502 | ExclusiveLock | t (4 rows)
然后出现第三个需要共享锁的事务。 问题在于它不会尝试捕获行版本的锁(因为它不会更改行),而只是不按顺序爬网-与第一个事务兼容。
|| BEGIN || => SELECT txid_current(), pg_backend_pid();
|| txid_current | pg_backend_pid || --------------+---------------- || 530503 | 5964 || (1 row)
|| => SELECT * FROM accounts WHERE acc_no = 1 FOR SHARE;
|| acc_no | amount || --------+-------- || 1 | 100.00 || (1 row)
现在有两个事务阻止了该行:
=> SELECT * FROM pgrowlocks('accounts') \gx
-[ RECORD 1 ]--------------- locked_row | (0,10) locker | 62 multi | t xids | {530501,530503} modes | {Share,Share} pids | {5892,5964}
当第一笔交易完成后,现在会发生什么? 第二笔交易将被唤醒,但是将看到行锁在任何地方都没有消失,并且将再次处于“队列”中-这次是第三笔交易:
=> COMMIT; => SELECT * FROM locks_v WHERE pid = 5928;
pid | locktype | lockid | mode | granted ------+---------------+-------------+------------------+--------- 5928 | relation | accounts | RowExclusiveLock | t 5928 | tuple | accounts:10 | ExclusiveLock | t 5928 | transactionid | 530503 | ShareLock | f 5928 | transactionid | 530502 | ExclusiveLock | t (4 rows)
并且只有在第三个事务完成时(并且如果在此期间没有其他共享锁出现),第二个事务就可以执行更新。
|| => COMMIT;
| UPDATE 1
| => ROLLBACK;
也许是时候得出一些实际结论了。
- 在许多并行进程中同时更新表中的同一行并不是一个好主意。
- 如果在应用程序中使用SHARE类型的共享锁,请谨慎使用。
- 检查外键应该不会造成干扰,因为键字段通常不会更改,并且KEY SHARE和NO KEY UPDATE模式兼容。
要求不要借
通常,SQL命令期望释放所需的资源。 但是,有时如果无法立即获得锁定,则希望拒绝执行该命令。 为此,可以使用诸如SELECT,LOCK,ALTER之类的命令来使用短语NOWAIT。
例如:
=> BEGIN; => UPDATE accounts SET amount = amount + 100.00 WHERE acc_no = 1;
| => SELECT * FROM accounts FOR UPDATE NOWAIT;
| ERROR: could not obtain lock on row in relation "accounts"
如果资源繁忙,该命令将立即失败。 在应用程序代码中,这样的错误可以被拦截和处理。
您不能为UPDATE和DELETE命令指定NOWAIT短语,但是您可以首先执行SELECT FOR UPDATE NOWAIT,然后,如果可能的话,更新或删除该行。
还有一个不等待的选项-将SELECT FOR命令与短语SKIP LOCKED一起使用。 这样的命令将跳过锁定的行,但处理自由行。
| => BEGIN; | => DECLARE c CURSOR FOR | SELECT * FROM accounts ORDER BY acc_no FOR UPDATE SKIP LOCKED; | => FETCH c;
| acc_no | amount | --------+-------- | 2 | 200.00 | (1 row)
在此示例中,第一行(被阻止)被跳过,我们立即收到(并被阻止)第二行。
实际上,这使您可以组织队列的多线程处理。 您不应该为该命令提供另一个应用程序-如果您想使用它,那么很可能您将看不到一些更简单的解决方案。
=> ROLLBACK;
| => ROLLBACK;
待续 。