没有比来自未知号码的意外电话更令人讨厌的了。 在我们的通讯和通讯时代,与一个陌生的电话号码的通信在智能手机的屏幕上不祥地闪烁可能至少会引起一些兴奋。 当一个呼叫不仅突然到达(例如,这些呼叫),而且在您不方便的时间到达时,这真是令人烦恼。 例如,当您还没有真正起床时(反之亦然),经过漫长的一天之后,您已经在这种诱人的床上忙得不可开交。 在晚上或晚上九点之后的周末,有些企业会打电话给别人,通常这不是善事。

顺便说一下,关于我。 我的名字叫娜塔莎(Natasha),我在Skyeng担任数据科学家,并参与公司各种产品的开发。 我为什么要谈论突然的电话? 与只想开始或由于某种原因突然中断培训的客户进行语音通信是该公司工作模式的一部分。 呼吁帮助使人们参与并使他们回到学习语言的过程中,或者直接找出问题所在。 我的最后一项任务是分析我们的呼叫中心的工作。 我帮助他们选择了与俄罗斯和独联体国家的学生取得联系的最佳时间:因为没人喜欢一天中的随机时间打电话,而激怒我自己的用户才是最后一件事。
在这样的通话过程中,人们的心情对我们来说非常重要,因为它直接影响转换。 因此,让我详细介绍一下Skyeng如何称呼学生以及我建立了什么预测模型,以使我们的客户感到舒适和舒适,我们的转化率达到60-70%。
除非您是通灵人士,否则从身体上不可能猜测出某个人的便利时间。 赞扬进展,以找出统计数据时发现的这种模式,其正负模型将适合绝大多数用户。
在对我们的CRM记录进行分析之后,该记录记录了呼叫中心的活动,确认了在工作时间以外进行商务呼叫的假设以及仅需遵循常识的要求。 因此,事实证明,最好在周一至周四的10到18个小时(突然之间!)打电话给人们。 正是在这段时间里,人们最有可能进行联系,并且通话持续15秒钟以上,也就是说,我们被认为是成功的。
首先,我们决定确定人为因素对转换的影响,即考察呼叫中心接线员的成功之处:
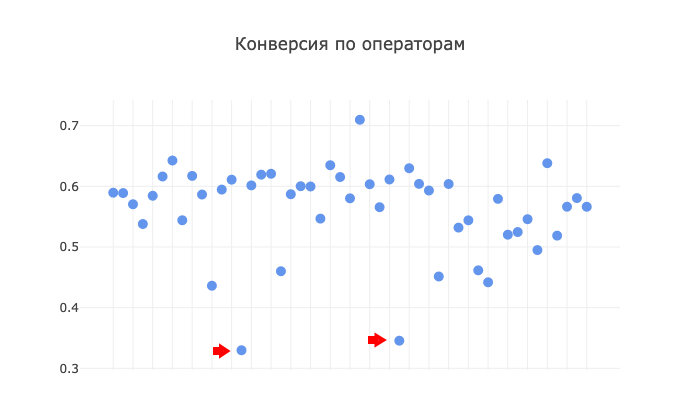
您不必成为侦探即可在此图表上看到两个“锚点”。 这两个异常是操作员,效率极低。 我们如何处理异常数据,其性质很可能取决于人为因素? 我相信我们会从模型中完全排除此类数据,以实现后续的纯度和结果准确性。 我实际上做了什么。 好吧,实际上,这两个操作员,或者说他们的结果,在呼叫中心都不在话下,我绝对可以确定这不是工作流程,而是员工本身。 也许它们是新来者,这也使我们有理由将它们排除在外。
但是,其他六个转化率低于0.5的运算符的数据仍保留在模型中。 我相信不可能有像人一样的理想情况,因此这六个人将使我们的进一步计算与其余五十名员工的样本保持平衡。
时区,地区和星期几
我们在时区方面遇到困难。 现在,我们正在收集足够的信息,以确定该学生来自何处以及何时最好与他联系。 但这远非总是如此。 正是这些古老但仍在起作用的信息层为我们的用户和呼叫中心运营商带来了许多不便。 为了处理这些旧数据,我根据其他间接数据(通过电话号码,区域和有关我们应用程序使用的信息)编写了用户区域的单独计算。
如果您开始更深入地研究CRM统计信息,您仍然可以获得完整的有用信息层来创建有效的模型。 首先,我为一周中的某几天制定了一个转化时间表,以确认最初的假设,那就是最好在工作日(周五除外)致电。 实际上,我的假设是正确的:
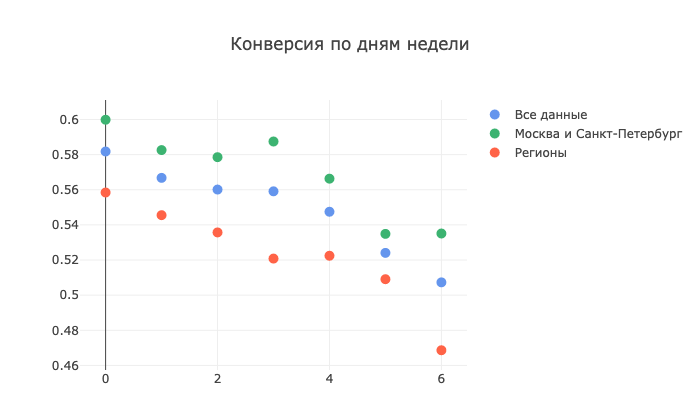
如此划分莫斯科,圣彼得堡和其他城市的原因恰恰是因为在确定时区方面存在疑问。 对于零日,我们分别选择星期一为第六个-星期日。 上图清楚地显示了周末各区域的转化率下降,这证实了呼叫中心运营商关注的时区问题的假设。
莫斯科和彼得好一点。 也许是因为这些城市的居民习惯了更高的生活节奏。 但是,即使莫斯科内维斯人和涅瓦河上的城市居民持坚决态度,这些数字仍说:“从周五到周日,没有什么可呼唤的。”
我们的目标0.6的下限仅在星期一达到一次,这令人惊讶,这是令人惊讶的,因为人们普遍认为这一天是最艰难的,人们不愿在星期一解决任何附带问题,因为他们专注于在下班后恢复工作节奏周末。 不,不,再也不是-数字不会说谎。 一周之后,我们或多或少会顺利进行,经济衰退仅在周四开始。
更有趣的是按时钟分解呼叫时的图片:
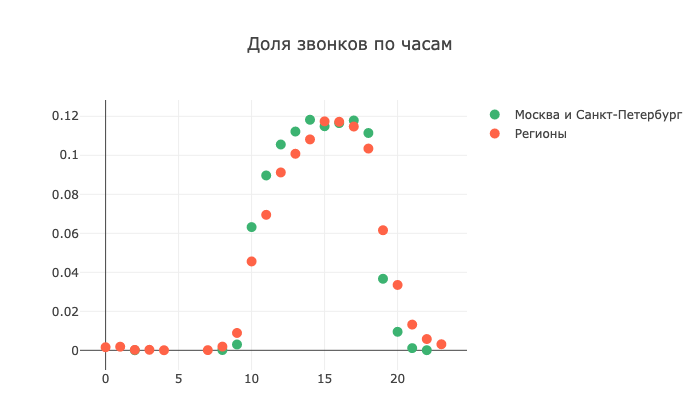 请注意该区域左侧的强尾巴。 由于错误定义的时区,这些呼叫很可能在不可接受的时间进行
请注意该区域左侧的强尾巴。 由于错误定义的时区,这些呼叫很可能在不可接受的时间进行现在,让我们看一下一周中某些天的转换:
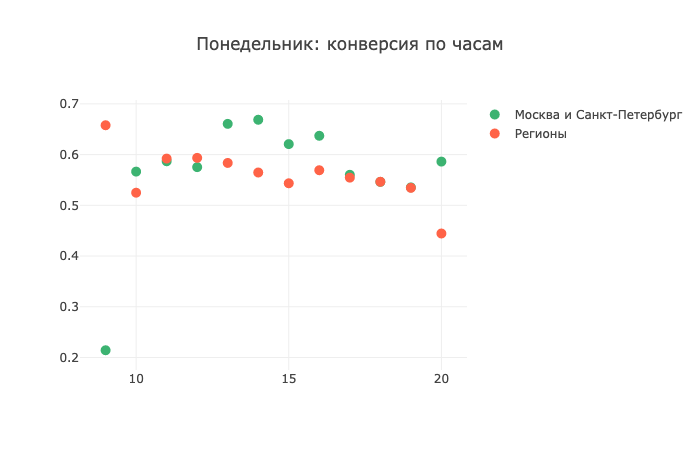
这是我们星期一冠军日的数据。 在图表的开头,“区域”被向前推。 中午前后,局势趋于平缓。 顺便说一下,请注意图表在15和16小时左右的对称运动; 首都,各地区此时显示的动作完全相同。
但是在星期二,情况开始改变:
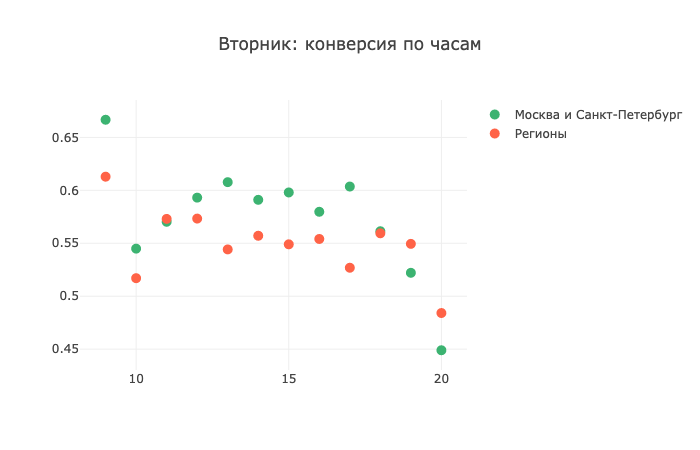
并且在星期四,这些地区表示不愿意接听电话:
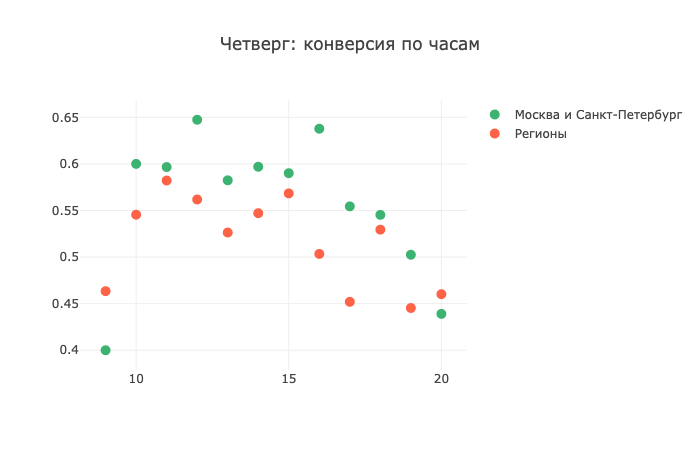
还记得我说过周末打电话是邪恶的吗? 通常,统计图片证实了我的话,但只有一个“ but”。 简而言之,亲自看看:
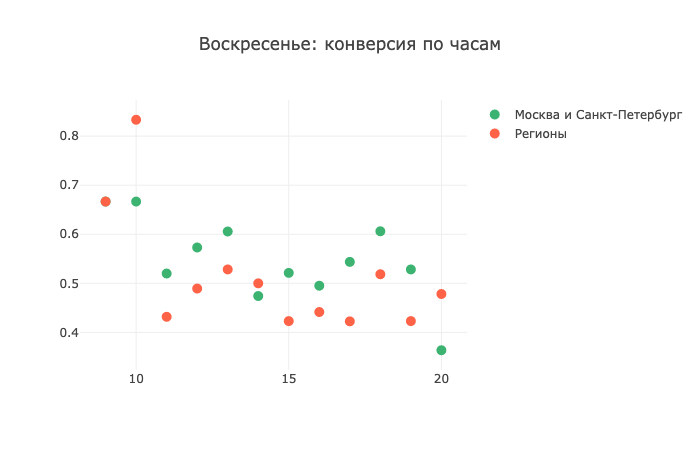
早上9时10分,该地区的转换就结束了! 而且已经在上午11点了-它几乎没有脱离0.4点,即下垂了两次。 我不知道它是如何工作的以及为什么会发生,所以我可以在评论中分享我的理论,我很乐意阅读。
如果汇总所有数据,则可以为“成功”调用导出以下规则:
- 星期一:13点至17点;
- 星期二:12点至18点;
- 星期三:11到12和15到17;
- 星期四:10到17;
- 星期五:10点至12点;
- 星期六:16点至18点;
- 星期日:13至14和18至19。
实际上,所有内容都符合常识框架。 在周一至周四的工作日-打电话至晚上五至六点,以及周五下午解决任何问题几乎是不可能的。 周末的统计数字有些“浮动”,重点是下午,再加上之前提到的星期日上午10点的异常高峰,这是无法想象的。 因此,一切都保持稳定。
我所做的一切以及建立的模型
在建立呼叫中心模型之前,有必要得出几个结论。 首先,这完全取决于通话时间。 但是这里我们有问题。
我们唯一可以跟踪的是电话号码的注册区域,从这些信息中我们已经可以从呼叫中心的建设开始。 但是,在很多情况下,我们无法确切确定所指示的数字来自哪个区域。
正是这一点,而不是该地区的一些虚构的懒惰,导致了这样一个事实,即在莫斯科环城公路和环城公路以外的用户转化的总体指标相对于首都而言有所下降。 在这种情况下我们该怎么办?
- 如果我们没有足够的数据,请坚持使用已识别的热点区域来拨打电话。
- 我们需要寻找工具来更准确地确定用户的位置,以免打空电话打扰到他。
第二点尤其重要。 正是这种差异降低了整体转化率,仍然吸引着客户。
但是,让我们继续构建模型。 这是我确定与症状有关的一般症状:
- hour-通话时间(从0到23的分类符号)。
- 工作日-星期几(从0到6的分类符号)。
- 年龄-学生的年龄。
- 生命周期-通话时学生的生命周期(以课程为单位)。
- app_hour_ {k}-每天使用应用程序的季节性。 对于每个小时,k被确定为该小时内应用程序中的操作数占应用程序中操作总数的比例(k = 0,...,23)。
- app_weekday_ {k}-每周使用一次应用程序的季节性。 对于一周中的每一天,将k确定为应用程序在该周的这一天的那一天(k = 0,...,6)在操作总数中所占的比例。
- class_hour_ {k}-每天的课程季节性。 对于每个小时,k被确定为该小时在该小时的课程总数(k = 0,...,23)中所占的比例。
- class_weekday_ {k}-每周使用一次应用程序的季节性。 对于一周中的每一天,将k确定为一周中某天在课程总数中所占的百分比(k = 0,...,6)。
- is_ru-如果学生所在的国家是俄罗斯,则为1,否则为0。
- last_payment_amount-上次付款的金额。
- days_last_lesson-上一堂课开始的天数(如果没有上一堂课,请替换为-100)。
- days_last_payment-自上次付款以来的天数(如果没有上一次付款,我们将其替换为-100)。
最初大约有一百个标志,但是计算和测试表明它们不影响最终结果,因此将它们排除在外是无益的(例如,课程强度,学生的性别,他的水平等)。 作为二元分类的模型,使用了CatBoost决策树上的梯度提升库。
这是我模型的质量(在控制样本中):
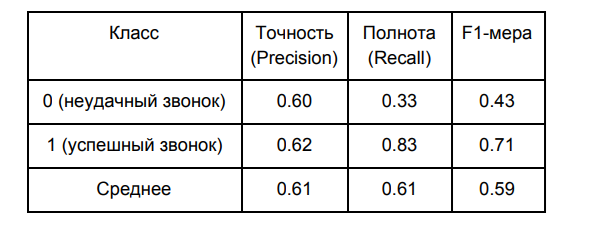
对于默认值为0.5的类分离边界,获得了这些结果。 我们根据ROC曲线(接收机工作特性)确定最佳的类别分离边界。
为此,我们根据分隔类的边界的各种值构造诸如完整性和特异性之类的特征的依赖性:
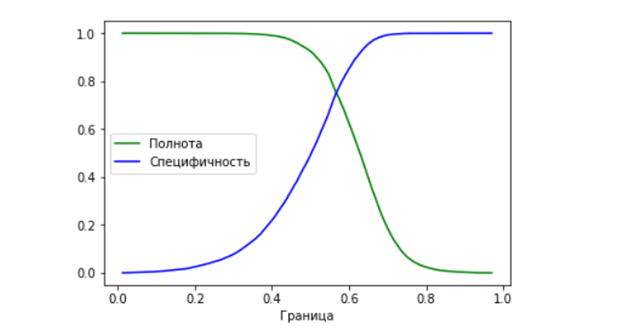
边界的最佳值将是我们在同一时间获得最大可能的完整性和特异性的值(即,在这种情况下,图形相交)。 对于生成的模型,最佳边界为0.56717。
具有最佳边界的模型的质量如下:
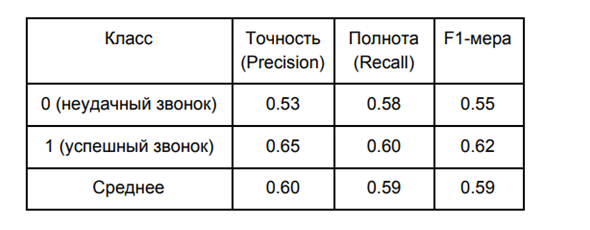
在我们的情况下,模型的准确性比完整性更重要。 准确性的提高使我们能够减少错误肯定的预测的数量,也就是说,它使我们能够减少等待成功呼叫时的情况数量,但结果却没有成功。
如果要总结模型的机制:
- 对于每位学生一天中的每个小时和一周中的一天中的每个小时,在考虑到其特性和当地时间后计算出拨号的可能性;
- 为了进一步存储,每周的每天从9到20个小时中选择一个时间(该时间根据学生所在的时区选择);
- 在保存之前,时间将转换为莫斯科时间,因为将在莫斯科时区进行拨号。
- 结果保存在数据库中。
因此,现在呼叫中心运营商已经预测了有关每个用户以及每周的每小时和每天的拨号可能性的数据。 如果呼叫不紧急,则操作员可以选择一周中最佳的时段,在极端情况下(如果无法再推迟呼叫)则是当前工作日中最成功的时刻。
当然,在引入模型之后,有必要暂停一下,然后再次进行所有这些工作,但要使用新数据。 我可以无休止地进行一些抽象计算,计算概率并向模型中添加新变量,但是直到实时统计数据证实了我的观点,现在回答这个问题还为时过早。
如果您愿意的话,过一会儿,我会介绍引入预测模型后获得的新数据。