我叫Oleg Ermakov,我在Yandex.Taxi应用程序的后端开发团队中工作。 我们习惯于每天做站立式站立训练,每个人谈论在一天中完成的任务。 这是怎么回事...
员工的姓名可能会更改,但是任务是真实的!在12:45,整个团队聚集在会议室。 第一个词是受训的开发人员Ivan所为。
伊万:
我的工作是显示所有可能的选项,以供乘客以已知的出行费用支付给驾驶员。 该任务是众所周知的-称为“硬币更换”。 考虑到细节,他为算法增加了一些优化。 我是在前天提出合并审核请求的,但从那时起,我一直在纠正评论。
通过安娜满意的笑容,伊万更正了谁的话。
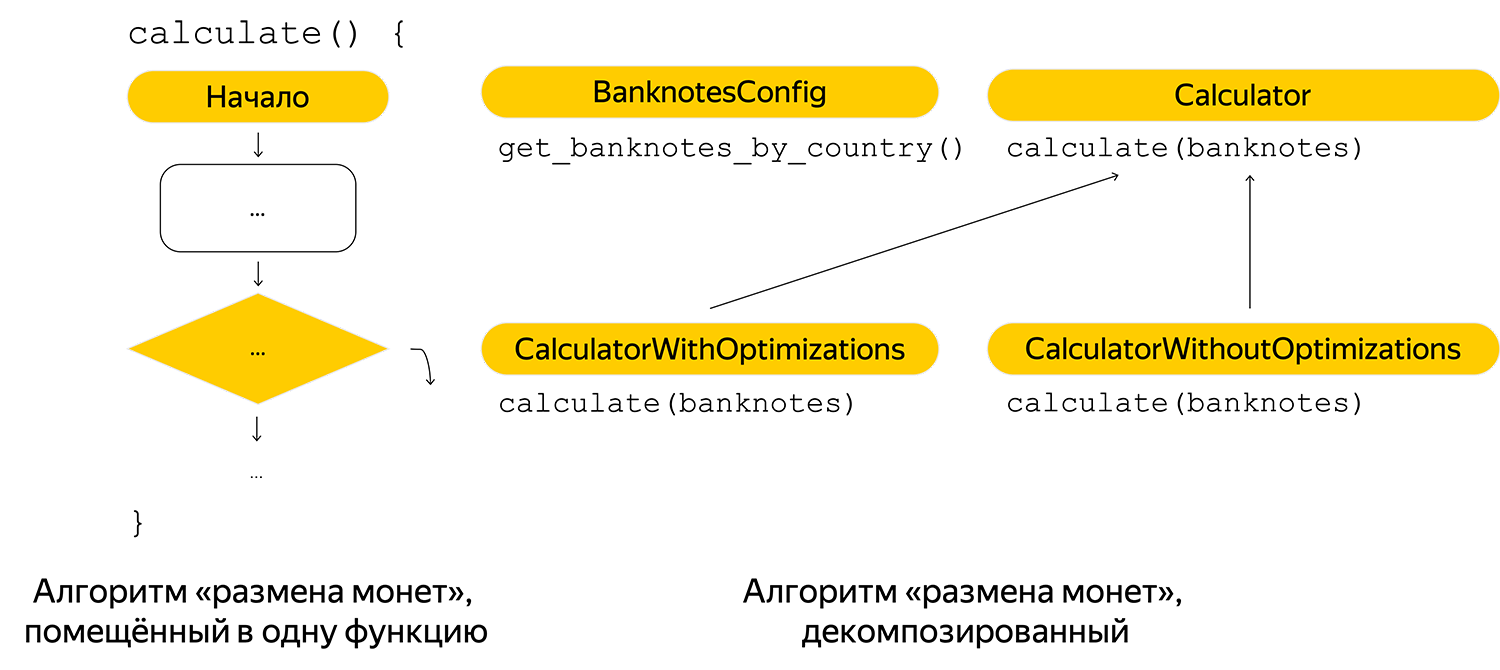
首先,他对算法进行了最小化分解,并且他正在巧妙地接收钞票。 在第一种实现中,可能的纸币已在代码中注册,因此,按国家将其取出到配置中。
添加了对未来的评论,以便任何读者都可以快速了解算法:
for exception in self.exceptions[banknote]: exc_value = value + exception.delta if exc_value - cost >= banknote: continue if exc_value > cost >= exception.banknote: banknote_results.append(exc_value)
好吧,当然,我将剩下的时间用在测试的整个代码上。
RUB = [1, 2, 5, 10, 50, 100, 200, 500, 1000, 2000, 5000] CUSTOM_BANKNOTES = [1, 3, 7, 11] @pytest.mark.parametrize( 'cost, banknotes, expected_changes', [
除了在项目的每个版本上运行的常规测试之外,他还编写了使用没有优化算法的测试(将其视为完全失败)。 该算法针对前一万个案例的每笔帐单的结果放入文件中,并在优化后单独运行该算法,以确保它确实正确运行。
让我们花点时间分散注意力,总结一下伊凡说的所有本地结果。 编写代码时,主要目标是确保其性能。 为了实现这个目标,您必须完成以下任务:
- 将业务逻辑分解为原子片段。 当查看用一个函数编写的代码画布时,可读性很复杂。
- 在代码的“特别复杂”部分添加注释。 我们的团队采用以下方法:如果在代码审阅中询问您有关实现的问题(要求您解释算法),则需要添加注释。 更好的是,事先考虑一下并自己添加。
- 编写覆盖算法执行主要分支的测试。 测试不仅是验证代码运行状况的一种方法。 它们仍然充当使用模块的示例。
,即使是具有多年经验的专家,也不一定总是在工作中使用这些方法。 在我们现在正在从事
的后端开发学校中,学生将获得编写架构上高质量代码的实践技能。 我们的另一个目标是传播项目的测试覆盖率实践。
但是回到站起来。 伊万之后,安娜讲话。
安娜:
我正在开发一种用于返回促销图像的微服务。 您还记得,该服务最初提供了静态数据存根。 然后测试人员要求对其进行自定义,然后将它们放入配置中,现在我正在执行“诚实”的实现,并从数据库中返回数据(PostgreSQL 10.9)。 最初制定的分解对我有很大帮助,在该框架的框架内,用于更改业务逻辑中的数据的接口没有更改,每个新的源(无论是配置,数据库还是外部微服务)仅实现了自己的逻辑。

我检查了负载下的书面系统,测试表明当我们进入数据库时,手柄开始急剧制动。 根据解释,我看到该索引未使用。 直到我弄清楚如何解决它。
瓦迪姆:
什么样的要求?
安雅:
OR下的两个条件:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val' OR table_1.attr2 IN ('val1', 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
查询说明表明,它不对表_2的attr1属性和表_1的attr2使用索引之一。
瓦迪姆:
面对MySQL中类似的行为,问题恰恰在于OR的条件,因为它仅使用一个索引,例如attr2。 第二种条件是使用seq扫描-完全通过表。 该请求可以分为两个独立的请求。 (可选)在后端拆分和冻结查询结果。 但是随后您需要考虑将这两个请求包装在一个事务中,或者使用UNION组合它们-实际上是在基础方面:
SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_2.attr1 = 'val') AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at SELECT * FROM table_1 JOIN table_2 ON table_1.some_id = table_2.some_id WHERE (table_1.attr2 IN ('val1' , 'val2')) AND table_1.deleted_at IS NULL AND table_2.deleted_at IS NULL ORDER BY table_2.created_at
安雅:
谢谢,我会尝试^ _ ^
再次总结一下:
- 几乎所有产品开发任务都与从外部源(服务或数据库)获取记录有关。 您需要仔细解决卸载数据的类分解的问题。 正确设计的类将使您能够编写测试并修改数据源而不会出现问题。
- 为了有效使用数据库,您需要了解查询执行的功能,例如,了解说明。
处理信息和组织数据流是任何后端开发人员任务的组成部分。 学校将介绍服务(和数据源)交互的体系结构。 学生将学习在架构和操作(数据迁移和测试)方面使用数据库。
最后讲的是瓦迪姆。
瓦迪姆:
我值勤了一个星期,弄清了事件的发生顺序。 代码中的一个荒谬错误花费了很长时间:尽管产品的创建是用代码编写的,但产品中没有按需记录。
通过所有在场人员的悲哀沉默,很明显-每个人都已经以某种方式面临这个问题 。
为了将所有日志作为请求的一部分,使用了request_id,该请求以以下形式抛出到所有记录中:
log_extra是具有请求的元信息的字典,其键和值将被写入日志。 如果不将log_extra传递给日志记录功能,则该记录将不会与所有其他日志关联,因为它将没有request_id。
我必须修复服务中的错误,将其重新推出,然后再处理该事件。 这不是第一次发生这种情况。 为了防止再次发生这种情况,我尝试在全球范围内解决此问题并摆脱log_extra。
首先,我为请求的标准执行编写了一个包装器:
async def handle(self, request, handler): log_extra = request['log_extra'] log_extra_manager.set_log_extra(log_extra) return await handler(request)
有必要决定如何在单个请求中存储log_extra。 有两种选择。 第一个是从asyncio更改eventloop的task_factory:
class LogExtraManager: __init__(self, context: Any, settings: typing.Optional[Dict[str, dict]], activations_parameters: list) -> None: loop = asyncio.get_event_loop() task_factory = loop.get_task_factory() if task_factory is None: task_factory = _default_task_factory @functools.wraps(task_factory) def log_extrad_factory(ev_loop, coro): child_task = task_factory(ev_loop, coro) parent_task = asyncio.Task.current_task(loop=ev_loop) log_extra = getattr(parent_task, LOG_EXTRA_CONTEXT_KEY, None) setattr(child_task, LOG_EXTRA_CONTEXT_KEY, log_extra) return child_task
第二个选项是通过Infrastructure命令使用contextvars “推送”到Python 3.7的转换:
log_extra_var = contextvars.ContextVar(LOG_EXTRA_CONTEXT_KEY) class LogExtraManager: def set_log_extra(log_extra: dict): log_extra_var.set(log_extra)
很好,而且进一步有必要在logger中转发存储在log_extra上下文中。
class LogExtraFactory(logging.LogRecord):
总结:
- 在Yandex.Taxi(以及Yandex中的任何地方)中,都积极使用asyncio。 重要的是不仅要能够使用它,而且要了解其内部结构。
- 养成阅读所有新版本语言的变更日志的习惯,考虑如何借助创新使自己和同事的生活更轻松。
- 使用标准库时,不要害怕爬入其源代码并了解其设备。 这是一项非常有用的技能,可让您更好地了解模块的操作,并为实现功能开辟新的可能性。
后端学校的老师吃了超过
一磅的盐,并且在服务的异步操作中充满了许多麻烦。 他们将向学生介绍Python异步操作的功能-无论是在实践层面还是在对程序包内部进行分析时。
书籍和链接
学习Python可以帮助您:
为了更深入地了解体系结构,请阅读以下书籍:
- “高负荷的应用程序 。 ” 此处,详细描述了与数据交互的问题(数据编码,使用分布式数据,复制,分区,事务等)。
- “微服务。 开发和重构模式 。 ” 本书展示了微服务架构的基本方法,描述了从整体式服务向微服务转换时必须面对的缺点和问题。 帖子中几乎没有关于它们的任何内容,但我仍然建议您阅读本书。 您将开始了解建筑体系结构的趋势,并学习代码分解的基本实践。
您可以不断发展的另一项最重要的技能是阅读他人的代码。 如果您突然意识到自己很少阅读别人的代码,建议您养成定期观看新的热门
存储库的习惯。
站立结束,每个人都去上班。