时间序列数据或时间序列是随时间变化的数据。 货币报价,运输运动的遥测,服务器访问或CPU负载的统计信息是时间序列数据。 要存储它们,需要特定的工具-临时数据库。 有许多工具,例如InfluxDB或ClickHouse。 但是,即使最好的时间序列存储解决方案也有缺点。 所有时间序列存储都是低级的,仅适用于时间序列数据,运行和注入当前堆栈非常昂贵且痛苦。

但是,如果您拥有PostgreSQL堆栈,则可以忽略InfluxDB和所有其他时态数据库。 安装两个扩展,TimescaleDB和PipelineDB,并直接在PostgreSQL生态系统中存储,处理和分析时间序列数据。 没有引入第三方解决方案,没有临时存储的缺点,也没有运行它们的问题。 这些扩展是什么,它们的优点和功能是什么,将告诉“第一监控公司”开发部主管
Ivan Muratov( binakot ) 。
什么是时间序列数据或时间序列?
这是关于他生命中不同阶段收集的过程的数据。
例如,汽车的位置:速度,坐标,方向或服务器上资源的使用以及CPU上的负载,已使用的RAM和可用磁盘空间上的数据。
时间序列具有多个功能。
- 在固定带上 。 任何时间序列记录都有一个带有时间戳的字段,在该字段上记录了该值。
- 过程的特征,称为序列的级别 :速度,坐标,负载数据。
- 几乎总是使用此类数据,它们以仅追加模式工作 。 这意味着新数据不会替代旧数据。 仅删除过时的数据。
- 条目不能彼此分开考虑 。 数据仅集体用于时间窗口,间隔或时间段。
流行的存储解决方案
我从
db-engines.com拍摄的图表显示了过去两年中各种存储模型的流行。
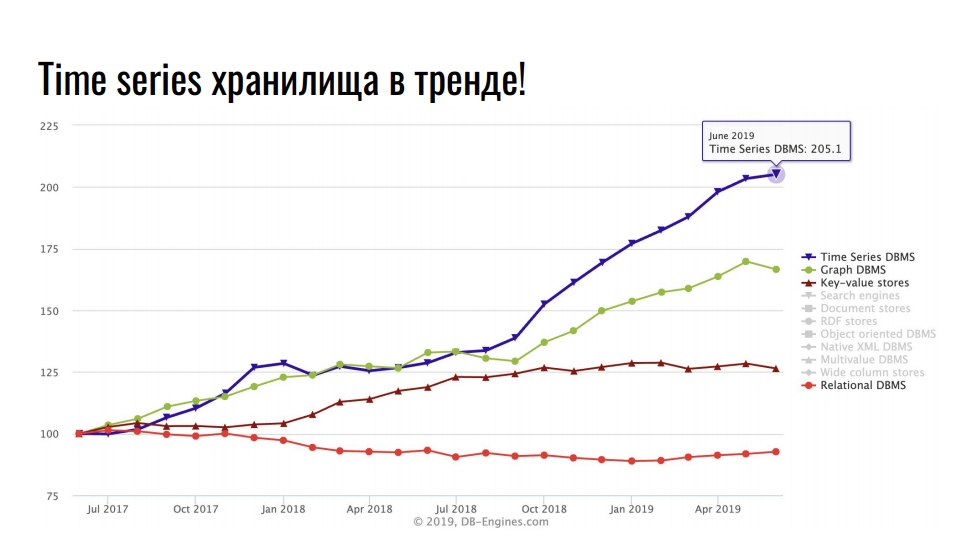
领先的是时间序列存储,其次是图形数据库,然后是键值数据库和关系数据库。 专用存储库的普及与信息技术集成的快速增长相关:大数据,社交网络,物联网,高负载基础架构的监视。 除了有用的业务数据,甚至日志和指标也占用了大量资源。
流行的时间序列数据存储解决方案
该图显示了用于存储时间序列数据的专用解决方案。 比例是对数的。
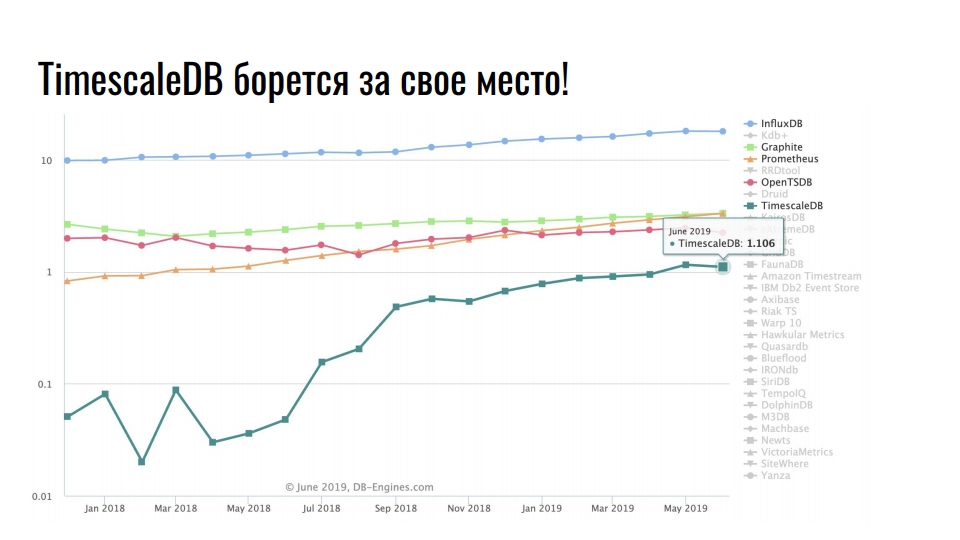
稳定的领导者InfluxDB。 接触时间序列数据的每个人都听说过该产品。 但是该图显示TimescaleDB增长了十倍-关系DBMS的扩展正在争夺最初根据时间序列开发的产品在阳光下的地位。
PostgreSQL不仅是一个很好的数据库,还是一个用于开发专用解决方案的可扩展平台。
Postgres,Postgis和TimescaleDB
第一监视公司使用卫星监视车辆的行驶。 我们跟踪20,000辆汽车,并存储两年的行驶数据。 总共,我们有10 TB的当前遥测数据。 平均而言,每辆车在行驶时每分钟会发送5条遥测记录。 数据通过导航设备发送到我们的远程信息处理服务器。 他们每秒接收500个导航数据包。
不久前,我们决定在全球范围内升级基础架构,并从整体迁移到微服务。 我们称这种新系统为Waliot,它已经在生产中-90%的车辆都转移到了该系统上。
基础架构发生了很多变化,但是中央链接保持不变-这是PostgreSQL数据库。 现在,我们正在开发版本10,并准备升级到11。除了PostgreSQL作为主要存储之外,在堆栈中,我们还使用PostGIS进行地理空间计算,并使用TimescaleDB来存储大量时间序列数据。
为什么选择PostgreSQL?
为什么我们要使用关系数据库来存储时间序列,而不是
使用针对这种数据类型的
ClickHouse专用解决方案? 因为在积累专业知识和使用PostgreSQL的印象的背景下,我们不想将未知的解决方案用作主要存储。
切换到新的解决方案是有风险的。
有许多用于存储和处理时间序列数据的专业解决方案。 文档并不总是足够的,并且很多解决方案也不总是很好。 似乎每个新产品的开发人员都希望从头开始编写所有内容,因为在以前的解决方案中有些不愉快。 要了解到底不喜欢什么,您必须查找信息,进行分析和比较。 各种各样的
top ,
评级和
比较比刺激尝试有些吓人。 您将不得不花费大量时间自行尝试所有解决方案。 我们承受不起几个月只能适应一种解决方案的负担。 这是一项艰巨的任务,所花费的时间永远也无法回报。 因此,我们选择了PostgreSQL扩展。
在Waliot基础架构的开发阶段,我们认为InfluxDB是主要的遥测存储库。 但是,当我遇到TimescaleDB并对其进行测试时,对选择没有任何疑问。 具有TimescaleDB扩展名的PostgreSQL允许您在同一PostGIS或PipelineDB存储中使用其他扩展名。 我们不需要提取数据,进行转换,进行分析并通过网络传输它们。 一切都位于一台服务器或群集系统中-无需拖动数据。 所有计算均在同一级别上进行。
最近,postgresmen帐户的作者
Nikolay Samokhvalov 发布了一篇有趣的文章
的链接 ,该文章有关使用SQL进行流数据处理。 本文的六分之五的作者参与了各种Apache产品的开发并使用流处理。 因此,本文提到了Confluent的Apache Spark,Apache Flink,Apache Beam,Apache Calcite和KSQL。
但是,并不是文章本身很有趣,而是
讨论了Hacker News上的
主题 。 该主题的作者根据该文章写道,他几乎实现了所有基于PostgreSQL 11的想法。他使用CitusDB扩展进行水平缩放和分片,使用PipelineDB进行流计算和实例化视图,使用TimescaleDB来存储时间序列数据和分段。 他还使用了多个外部数据包装器。
PostgreSQL及其扩展的疯狂组合再次证实PostgreSQL不仅仅是一个DBMS,它还是一个平台。
当可插拔存储设备交付时……...!
具有讽刺意味的是,在研究解决方案时,我们发现了
Outflux(TimescaleDB团队的发展),他们于4月1日发布了该出版物。 你觉得她做什么? 这是一个实用程序,可在一个命令中从InfluxDB迁移到TimescaleDB ...
Postgres大肆宣传!
不要小看炒作的力量! 我们经常开玩笑说“发展是由炒作驱动的”,因为它会影响我们对调优和基础架构组件的看法。 在
HighLoad ++上,我们对PostgreSQL,ClickHouse,Tarantool进行了很多讨论-这些都是炒作。 只是不要说这不会影响您对基础架构的偏好和解决方案的选择...当然,这不是主要因素,但是有什么效果吗?
我已经使用PostgreSQL已有5年了。 我喜欢这个解决方案。 他几乎用力解决了我所有的任务。 每当这个基地出现问题时,我的双手都应该怪罪。 因此,选择是预定的。
TimescaleDB VS PipelineDB
让我们继续扩展TimescaleDB和PipelineDB。 他们的创作者对扩展有何评价?
TimescaleDB是一个开源
时间序列数据库 ,已针对快速插入和复杂查询进行了优化。
PipelineDB是一种高性能扩展,旨在
对时间序列数据运行连续的SQL查询。
除了使用时间序列数据外,它们都有类似的故事。 Timescale成立于2015年,Pipeline成立于2013年。第一个工作版本分别于2017年和2015年出现。 团队花了两年时间才发布最低功能。 这两个扩展的生产版本于去年10月发布,相差一个星期。 显然,彼此匆忙。
GitHub上有一堆星星和叉子,像往常一样,它们不是单个提交。 这就是开放源代码的工作方式,无需执行任何操作。 但是有很多明星,
TimescaleDB比
PipelineDB还要多,甚至比PostgreSQL本身还要多。
扩展似乎是相似的,但是它们的位置不同。
TimescaleDB声称每秒插入数百万条记录,并存储了数千亿行和数十兆兆字节的数据。 该扩展比InfluxDB,Cassandra,MongoDB或Vanilla PostgreSQL更快。 支持流复制和备份工具。 TimescaleDB是扩展,而不是PostgreSQL的分支。
PipelineDB仅存储流计算的结果,而无需存储原始数据进行计算。 该扩展能够在实时数据流上连续聚合,并与常规表结合以在域域的上下文中进行计算。 PipelineDB是一个扩展,不是一个fork,但最初是一个fork。
时间刻度
现在详细介绍扩展。 让我们从TimescaleDB开始。 我和他一起工作了将近两年。 在发行版本之前将其拖到生产中。 让我们看一下如何应用它的示例。
存储基础结构指标 。 我们有Docker容器资源消耗指标,指标提交时间,容器标识符和资源消耗字段,例如空闲内存。 我们需要显示所有容器的统计信息,这些容器的平均可用内存窗口数为10秒。 您看到的查询解决了此问题,TimescaleDB可用作基础结构指标的存储库。
SELECT time_bucket('10 seconds', time) AS period, container_id, avg(free_mem) FROM metrics WHERE time < now() - interval '10 minutes' GROUP BY period, container_id ORDER BY period DESC, container_id;
period | container_id | avg -----------------------+--------------+--- 2019-06-24 12:01:00+00 | 16 | 72202 2019-06-24 12:01:00+00 | 73 | 837725 2019-06-24 12:01:00+00 | 96 | 412237 2019-06-24 12:00:50+00 | 16 | 1173393 2019-06-24 12:00:50+00 | 73 | 90104 2019-06-24 12:00:50+00 | 96 | 784596
用于计算 。 我们需要按天数计算离开克拉斯诺达尔的卡车数量及其总吨位。
SELECT time_bucket('1 day', time) AS day, count(*) AS trucks_exiting, sum(weight) / 1000 AS tonnage FROM vehicles INNER JOIN cities ON cities.name = 'Krasnodar' WHERE ST_Within(last_location, ST_Polygon(cities.geom, 4326)) AND NOT ST_Within(current_location, ST_Polygon(cities.geom, 4326)) GROUP BY day ORDER BY day DESC LIMIT 3;
它还使用PostGIS扩展程序中的函数来计算离开城市的交通量,而不仅仅是在城市中行驶。
货币汇率监测 。 第三个例子是关于加密货币的。 该请求使您可以显示以太坊的价格在过去两周中相对于比特币和美元的变化。
SELECT time_bucket('14 days', c.time) AS period, last(c.closing_price, c.time) AS closing_price_btc, last(c.closing_price, c.time) * last(b.closing_price, c.time) filter (WHERE b.currency_code = 'USD') AS closing_price_usd FROM crypto_prices c JOIN btc_prices b ON time_bucket('1 day', c.time) = time_bucket('1 day', b.time) WHERE c.currency_code = 'ETH' GROUP BY period ORDER BY period DESC;
对于我们的SQL来说,这一切都是同样清晰和方便的。
TimescaleDB有什么很棒的地方?
为什么不使用内置的表分区工具? 为什么还要打碎桌子? 显而易见的答案是
在此类数据库中的插入速度 。 该图显示了不带分区的常规原始表格PostgreSQL 10与TimescaleDB超表之间每秒行数插入率的实际测量值。
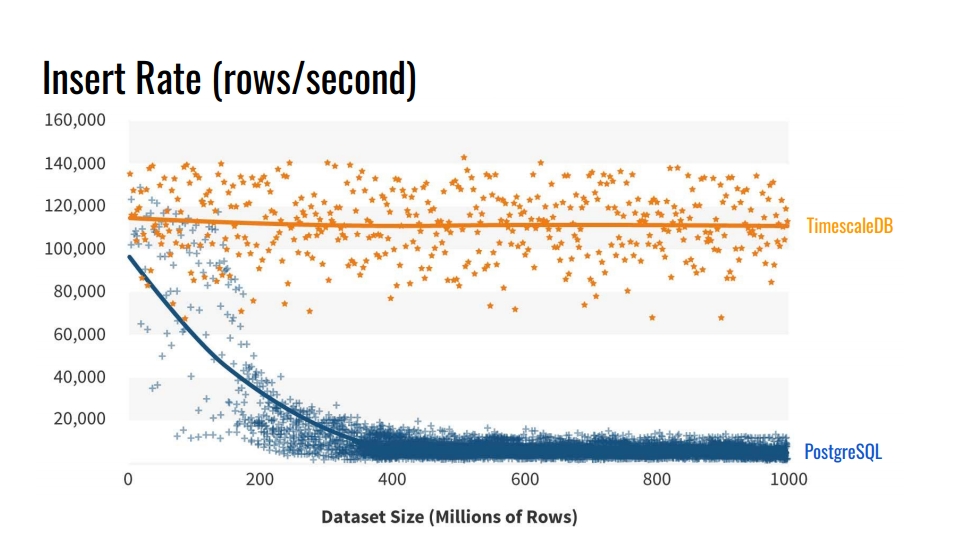
该基准测试在一台机器上写入了10亿行,模拟了从基础架构收集指标的场景。 该记录包含时间,基础结构组件的标识符和10个指标。 该基准测试在具有8个内核和28 GB RAM的Azure VM以及网络SSD驱动器上运行。 批量执行了1万条记录。
PostgreSQL性能的这种下降是从哪里来的? 因为在插入时,还需要更新表索引。 当它们不适合缓存时,我们开始加载磁盘。 如果将我们要插入数据的部分的索引放在RAM中,则分区可以解决此问题。
让我们看下面的图表。 这比较了PostgreSQL 10中内置的声明性分区系统和TimescaleDB超表。 在水平轴上,截面数。
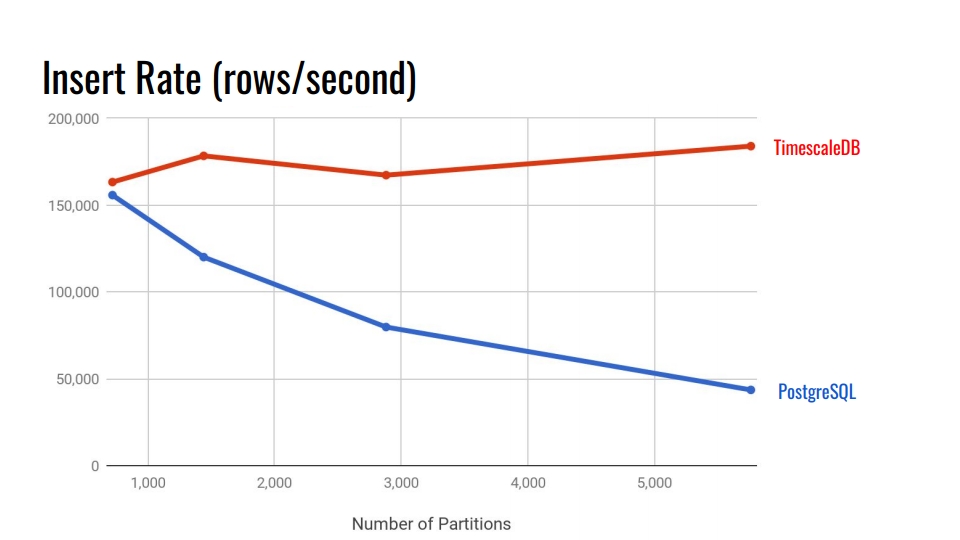
在TimescaleDB中,随着节数的增加,降级可以忽略不计。 扩展开发人员声称他们在一个PostgreSQL实例中可以处理10,000个部分。
在PostgreSQL中,本机实现在3,000之后会大大降低,一般来说,PostgreSQL中的声明式分区是向前迈出的一大步,但仅适用于负载较小的表。 例如,对于商品,买方和其他进入系统的域实体,其强度不如度量标准。
在PostgreSQL的11和12版本中,将显示本机分区支持,您可以尝试对具有新版本的时间序列数据进行比较测试。 但是,在我看来,TimescaleDB仍然更好。 TimescaleDB的所有基准都可以在其
github上找到并尝试。
主要特点
希望您已经对该扩展感兴趣。 让我们看一下TimescaleDB的主要功能,以巩固这种感觉。
通过超表进行分区 。 对于已应用了create_hypertable()函数的表,TimescaleDB使用术语“超速”。 之后,该表将成为所有继承节(块)的父项。 父表本身将不包含任何数据,但在自动创建新节时将成为所有查询的入口点和模板。 所有部分都不存储在数据的主要方案中,而是存储在特殊方案中。 这很方便,因为在数据模式中看不到成千上万的这些部分。
该扩展已集成到调度程序和查询执行程序中 。 通过PostgreSQL中的特殊钩子,TimescaleDB可以了解何时访问超表。 TimescaleDB分析查询,并根据SQL调用本身中的指定条件将查询仅重定向到必要的部分。 这使您可以在提取大量数据的过程中将工作与各部分并行化。
扩展不对SQL施加限制 。 您可以自由使用联合,聚合,窗口函数,CTE和其他索引。 如果您看到了内置分区系统的限制列表,则应该满意。
特定于时间序列数据的
其他有用功能 :
- “ Time_bucket”-健康人的“date_trun”;
- 直方图-使用插值或最近的已知值填充错过的时间间隔;
- 后台工作者的服务-允许您执行后台操作的服务:清理旧部分,重新组织。
TimescaleDB允许您停留在功能强大的PostgreSQL生态系统中 。 此扩展不会破坏PostgreSQL,因此所有高可用性解决方案,备份系统,监视工具将继续起作用。 TimescaleDB和Grafana,Periscope,Prometheus,Telegraf,Zabbix,Kubernetes,Kafka,Seeq,JackDB是朋友。
Grafana已经对
TimescaleDB作为数据源提供了本地支持。 Grafana开箱即用地了解PostscreSQL具有TimescaleDB。 仪表盘上Grafana中的查询构建器可以理解其他TimescaleDB函数,例如“ time_bucket”,“ first”,“ last”。 您可以使用这些时间序列函数直接从关系数据库中构建图,而无需进行大量查询。
Prometheus有一个适配器,允许您合并其中的数据并将TimescaleDB用作可靠的数据仓库。 使用适配器多年来不会在Prometheus中存储数据。
还有一个
Telegraf插件 。 该解决方案使您可以完全删除Prometheus。 基础结构数据立即传输到TimescaleDB并通过Telegraf读取。
许可证和新闻
不久前,该公司转用了新的许可模式。 大多数代码在Apache 2.0下获得许可。 一小部分可免费使用,但已获得TSL的许可。
有一个带有商业许可证的企业版。 不用担心,不是企业版中的所有优点。 基本上,存在自动化,例如自动删除过时的块,这可以通过简单的“ cron”和类似的操作来完成。
现在,该公司正在积极研究集群解决方案。 也许它将落入企业版。 对于希望在投资者资金用尽之前设法进入市场的初创企业,还有一个云版本。
来自新闻:
- 在过去的一年半中,下载量达到了一百万;
- 投资3100万美元;
- 与MS Azure就物联网解决方案进行积极合作。
总结一下
TimescaleDB旨在存储时间序列数据。 与PostgreSQL中的本机分区相比,这是一个功能强大的分区系统,具有最小的限制。
不幸的是,该扩展程序还没有多节点版本。 如果您需要多主机或分片,则必须使用CitusDB,例如。 如果要逻辑复制,将很受伤。 但这总是伤害着她。
管道数据库
现在让我们讨论第二个扩展。 不幸的是,我们无法在战斗中对其进行适当的测试。 现在它正在经历我们系统的适应阶段。 没错,我将在最后谈到一个问题。
与前面的情况一样,我们从实际示例开始。 容易理解扩展程序的好处以及使用它的动机。
统计收集 。 想象一下,我们收集了有关访问我们网站的统计信息。 我们需要分析最受欢迎的页面,唯一身份用户的数量以及一些资源延迟的想法。 所有这些都应该实时更新。 但是我们不想每次都触摸数据表并建立查询,或者更新表顶部的视图。
CREATE CONTINUOUS VIEW v AS SELECT url::text, count(*) AS total_count, count(DISTINCT cookie::text) AS uniques, percentile_cont(0.99) WITHIN GROUP (ORDER BY latency::integer) AS p99_latency FROM page_views GROUP BY url;
url | total_count | uniques | p99_latency -----------+-------------+---------+------------ some/url/0 | 633 | 51 | 178 some/url/1 | 688 | 37 | 139 some/url/2 | 508 | 88 | 121 some/url/3 | 848 | 36 | 59 some/url/4 | 126 | 64 | 159
流处理和PipelineDB扩展可助您一臂之力。 该扩展添加了CONTINUES VIEW抽象。 在俄语版本中,这听起来像是“连续演示”。 将视图插入访问表后,此视图将自动更新,而只是基于新数据,而不会预先读取已记录的记录。
数据流 。 PipelineDB不仅限于新的视图类型。 假设我们进行A / B测试并收集有关新业务解决方案有效性的实时分析。 但是我们不想将数据存储在用户操作本身上。 我们只对结果感兴趣-哪个组的转化次数最多。
为了避免直接存储原始数据以进行流计算,我们需要诸如
streams-data stream这样的抽象。 PipelineDB引入了此功能。 您可以创建类似于常规表的流。 在幕后,它将是基于ZeroMQ队列的“ FOREIGN TABLE”,扩展名是我们故意使用的。 数据进入ZeroMQ内部队列并触发对连续视图的更新。
CREATE STREAM ab_event_stream ( name text, ab_group text, event_type varchar(1), cookie varchar(32) ); CREATE CONTINUOUS VIEW ab_test_monitor AS SELECT name, ab_group, sum(CASE WHENevent_type = 'v' THEN 1 ELSE 0 END) AS view_count, sum(CASE WHENevent_type = 'c' THEN 1 ELSE 0 END) AS conversion_count, count(DISTINCT cookie) AS uniques FROM ab_event_stream GROUP BY name, ab_group;
然后,我们根据先前创建的流中的数据创建“连续视图”。 当数据到达流中时,将基于此数据更新视图。 之后,数据将被简单地丢弃,不会保存在任何地方并且不会占用磁盘空间。 这使您可以在几乎无限量的数据上进行分析,将其加载到PipelineDB数据流中,并从连续视图中读取计算结果。
流计算 创建数据流和连续视图之后,就可以使用流计算了。 看起来像这样。
INSERT INTO ab_event_stream (name, ab_group, event_type, cookie) SELECT round(random() * 2) AS name, round(random() * 4) AS ab_group, (CASE WHENrandom() > 0.4 THEN 'v' ELSE 'c' END) AS event_type, md5(random()::text) AS cookie FROM generate_series(0, 100000); SELECT ab_group, uniques FROM ab_test_monitor; SELECT ab_group, view_count * 100 / (conversion_count + view_count) AS conversion_rate FROM ab_test_monitor;
第一个“ SELECT”给出组“ ab”和唯一身份访问者的数量。 第二个-给出组之间的比率-转化。 这就是对关系数据库中五个SQL调用的所有A / B测试。
视图是动态更新的。 您不能等待整个数据阵列的处理,而是读取已经处理的中间结果。 视图的读取方式与常规PostgreSQL相同。 您还可以将视图与表或什至其他视图组合。 没有任何限制。
拓扑结构
Kafka接收遥测,Kafka中的主题将该数据发送到PostgreSQL,我们将其进一步汇总。 例如,我们结合一些普通表并将数据重定向到流。 此外,他引发了相应连续演示的更新,数据库客户端可以从中读取完成的数据。
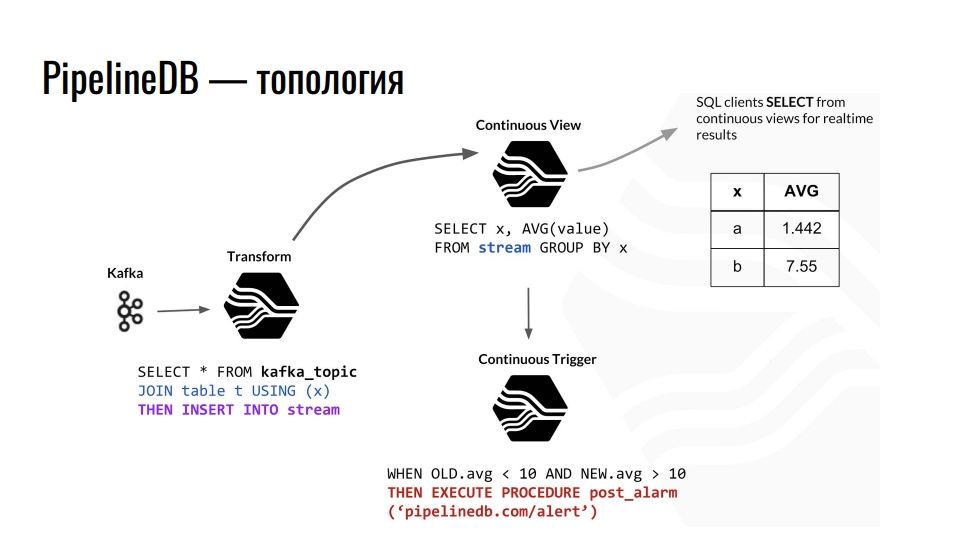 PostgreSQL内部PipelineDB组件的拓扑示例。 该电路借鉴了德里克·尼尔森( Derek Nelson)的演讲 。
PostgreSQL内部PipelineDB组件的拓扑示例。 该电路借鉴了德里克·尼尔森( Derek Nelson)的演讲 。除了流和视图之外,该扩展还提供了“转换”的抽象-转换器或增变器。 该视图旨在将传入的数据流转换为修改后的输出。 使用这些转换器,您可以更改数据的表示形式或对其进行过滤。 从增变器,所有这些都将进入“连续视图”视图。 我们已经在其中查询业务了。 任何熟悉函数式编程的人都应该理解这个想法。
在PipelineDB中,我们可以将触发器挂在视图上并执行操作,例如“警报”。 通过所有这些计算,我们永远不会自己存储原始数据,而我们都是以此为基础进行计算的。 这些可以是TB,我们可以按顺序将其上载到具有100 GB磁盘的服务器上。 毕竟,我们只对计算结果感兴趣。
主要特点
PipelineDB扩展比TimescaleDB难学习。 在TimescaleDB中,我们创建一个表,告诉她她是一个超表,并使用扩展提供的其他一些功能来享受生活。
PipelineDB解决了关系数据库中的流计算问题 。 就集成和使用而言,流数据处理的任务比分区要复杂得多。 但是,并非每个人都有海量数据和数十亿行。 如果有PipelineDB,为什么还要使基础架构复杂化? 该扩展提供了自己的表示,流,转换器和聚合的实现,用于流处理。 它还
集成到查询计划器中,查询执行器允许在关系数据库中实现流计算的概念。
与TimescaleDB一样,PipelineDB扩展
在PostgreSQL中没有施加SQL限制 。 有几个功能,例如,您不能合并两个流,但这不是必需的。
支持概率数据结构和算法 。 该扩展直接在SQL中将Bloom Filter用于SELECT DISTINCT,将HyperLogLog用于COUNT(DISTINCT),将T-Digest用于percentile_count()。 这提高了生产率。
生态系统 该扩展允许您使用常规的高可用性解决方案,监视工具以及PostgreSQL中熟悉的所有其他功能。
鉴于流计算的细节,PipelineDB
与Apache Kafka和实时分析服务Amazon Kinesis
集成在一起 。 由于PipelineDB不再是分支,而是扩展,因此与动物园其余部分的集成也应该是开箱即用的。 必须的,但我们并不生活在理想的世界中,一切都值得检查。
许可证和新闻
所有代码均在Apache 2.0下获得许可。 付费订阅可以支持不同的摄影画廊,以及具有商业许可的集群版本。 该公司基于PipelineDB提供Stride分析服务。
在开始讨论扩展名之前,我说过一个“但是”。 现在该谈论他了。 在2019年5月1日,PipelineDB团队宣布它现已成为Confluent的一部分。 这是一家开发KSQL的公司,KSQL是一种使用SQL语法在Kafka中流式传输数据的引擎。 现在,播客Debriefing的联合创始人Victor Gamov正在那里工作。
随之而来的是什么? PipelineDB在1.0.0版上冻结。 除了修复关键错误外,没有任何计划。 由于这项收购,我们希望Uber将Kafka与PostgreSQL集成。 也许是基于可插拔存储的Confluent会做一些很棒的事情。
怎么办 转到TimescaleDB。 在最新版本中,他们使用二十一点制作了“连续视图”。 当然,现在的功能不如PipelineDB那样酷,但这只是时间问题。
总结一下
PipelineDB专为高性能流数据处理而设计。 它使您可以对大型数据集执行计算,而不必保存数据本身。
使用PipelineDB,当我们以流的形式将数据流发送到PostgreSQL时,我们认为它们是虚拟的。 我们不保存数据,而是汇总,计算和丢弃。 您可以创建一个200 GB的服务器,并通过流输出TB级的数据。 我们将得到结果,但是数据本身将被丢弃。
如果出于某种原因,TimescaleDB的“连续视图”对您来说还不够,请尝试使用PipelineDB。 这是Apache许可下的一个开源项目。 尽管不再积极开发它,但它不会走到任何地方。 但是情况可能会改变,Confluent尚未撰写有关扩展计划的文章。
使用TimescaleDB和PipelineDB
使用PostgreSQL和两个扩展,
我们可以存储和处理大量时间序列数据 。 您可以想到许多应用程序。 让我们从我的学科领域来看一个例子-车辆监控。

导航设备不断将遥测记录发送到我们的服务器。 他们将各种文本和二进制协议解析为通用格式,并以特殊主题将数据发送到Kafka。 从那里,他们通过与PipelineDB集成到PostgreSQL内部的遥测数据流中。 该流更新了车辆当前状态和整个车队分析的视图,并基于触发器触发了在TimescaleDB超表中记录遥测记录。
通过扩展,我们具有三个优点。
- 实时分析。
- 存储时间序列数据。
- 减少存储的遥测量。 使用PipelineDB增幅器,我们可以汇总数据(例如,在一分钟内),以计算平均值。
Grafana具有对TimescaleDB功能的内置支持。 因此,有可能直接从框中根据业务度量标准构建图形,直到按坐标在地图上的轨迹进行构建。 分析部门会很高兴。
要自己“接触”所有内容,请查看
GitHub上的演示并运行
Docker映像 -在最新PostgreSQL,TimescaleDB和PipelineDB的程序集中。
合计
PostgreSQL允许您组合各种扩展,以及添加自己的数据类型和函数来解决特定问题。 在我们的案例中,使用TimescaleDB和PostGIS扩展几乎可以完全满足存储时间序列数据和地理空间计算的需求。 借助PipelineDB扩展,我们可以对各种分析和统计数据执行连续的计算,并且使用JSONB列允许我们在关系数据库中存储结构较弱的数据。 头脑风暴足以解决开源问题-我们不使用商业解决方案。
这些扩展实际上并不限制PostgreSQL周围的生态系统,例如高可用性解决方案,备份系统,监视和日志分析工具。 如果有JSONB列,则不需要MongoDB;如果有TimescaleDB,则不需要InfluxDB。
您是否喜欢伊凡(Ivan)的故事并希望分享类似的内容? 在9月7日之前在莫斯科的HighLoad ++上申请。 该计划正在逐步填补。 , , , , . , !