单元测试很棒,但是还不够。 通常,您还需要确保正在运行的应用程序可以正常运行。 集成测试可助您一臂之力。 它正越来越多地用于测试服务,而Docker使您可以方便地管理测试环境。 但是,与往常一样,当存在更多微服务和依赖项时,事情就变得不那么简单了。
RIT ++的Yuri Badalyants讲述了他们如何在2GIS中测试大量服务和整个技术动物园。 削减后,在演讲者的精心监督下,对本报告的版本进行了补充和更新:您尝试了哪些选择,您做了什么,现在不需要解决哪些问题。 它将涉及Docker,Testcontainers以及Scala。
关于演讲者: Yuri Badalyants(
@LMnet )于2011年开始他的职业生涯,当时是Web开发人员,曾使用PHP,JavaScript和Java。 现在,他在2GIS中编写Scala。
娱乐场
2GIS一直提供便捷的城市地图和公司目录已有20年了,最近我们有了一个
新版本,其中包含俄罗斯的无限地图。 我将向您介绍我在赌场团队工作期间获得的经验。 该团队涉及三个主要领域:
- 广告-显示哪些广告商,隐藏哪些广告商,提高哪些广告商以及如何降低评级。
- BigData与广告及其个性化以及分析和指标构建有关。
- 搜寻器是一个程序,可在Internet上搜索组织以将其自动添加到数据库中。
这三个区域是主要任务,而这些任务又具有大量子任务。 当前,有超过25种用Scala编写的微服务。 这完全是我们的代码,但是我们也使用第三方系统,例如PostgreSQL,Cassandra和Kafka。 我们将数据存储在Hadoop中,并在Spark中进行处理。 另外,我们使用数据科学团队提供的机器学习方法。
结果,我们拥有大量的服务和微服务,大量的依赖关系,当然,所有这些都需要以某种方式进行测试。
当然,我们编写单元测试。 但是,即使所有测试都是绿色的,也并不意味着一切正常。 在组件或微服务的集成阶段可能出了点问题。 因此,我们编写了集成测试。
整合测试
Casino团队开发的每个微服务都可以解决其业务问题,并位于GitLab中的单独存储库中。 本文将重点介绍具有锁定依赖项的此类存储库(微服务)中的集成测试,这是开发人员自己的责任。 质量检查团队正在测试微服务的交互,因此我不会涉及这个话题。
当我第一次加入团队时,在2016年底,大约有以下集成测试方案:
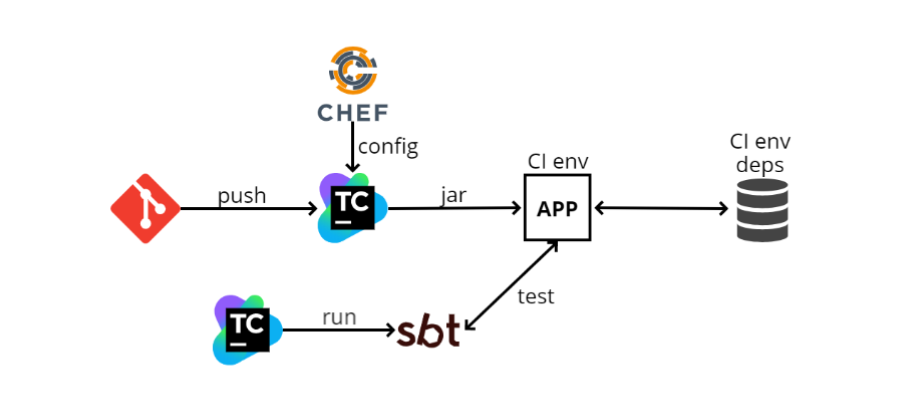
- 开发人员将他的代码推送到GIT中,之后微服务代码进入TeamCity。 TeamCity开始构建代码并运行测试。
- TeamCity从Chef(一个与Ansible类似的配置管理系统,仅用Ruby编写)中获取配置文件(config)。 Chef还可以自动执行部署。 当我有100台计算机时,我不想转到每台计算机上并在SSH上安装我需要的东西,而Chef允许我自动进行此操作。
- TeamCity收集jar文件(因为我们是在Scala中编写的,因此发布的工件就是jar),然后程序将其加载到CI环境中。 我们的应用程序部署在那里,也有一些依赖性。 在该图中,依赖项之一被描述为数据库。 可以有尽可能多的此类依赖项,感谢Chef,我们的应用程序知道了这些依赖项并开始与它们进行交互。
- 接下来,TeamCity启动SBT (这是我们的构建系统,在其中运行编译和测试)并自行运行测试。 它们与单元测试相对类似,但是它们主要基于以下原理工作:通过http到达特定地址,检查某种方法并查看返回的内容; 或进行一些准备,然后查看是否已返回所需的信息。
这样的计划可以说些什么? 最重要的是,它有效。 完成所有设置后,运行测试很容易,因为它们看起来像单元测试。 但是优点就到此为止。
缺点开始了。
CI环境始终处于开启状态 ,这是对资源的额外浪费。 由于Chef是静态配置,因此您应该始终拥有某种机器,在该机器上将配置所有依赖项,并在其中独立部署应用程序。 由于不时运行测试,因此这样的机器将消耗额外的资源,并且机器必须始终处于就绪状态。 此外,CI环境包含在所有依赖项中。
不可能同时在两个分支上运行测试 。 这是从上一段得出的:由于我们只有一个环境,因此我们无法并行运行它们。
无法测试启动,停止和重新启动 。 我将解释为什么这样做是必要的:我们所有的应用程序都遵循所谓的
平稳关机的逻辑,也就是说,当我们获得SIGTERM时,我们不会在中间停止进程,而是会拦截该信号并了解我们需要关闭程序。 在这一点上,某些逻辑已打开,例如,处理了“进行中”的HTTP请求,或者如果我们与Kafka一起工作,我们将全力以赴-换句话说,我们将执行某些操作,以便我们可以安全地完成工作,并且然后,当一切完成后,关闭电源。
这种逻辑并不总是那么简单,您只能使用这种方案手动进行测试,因为从测试中我们无法控制应用程序的生命周期。 事实证明,TeamCity通过某种方式通过Chef部署了一些东西,而测试处于不同阶段,并且不知道如何部署应用程序。
下一个缺点是,
很难在本地配置所有这些 。 也就是说,有许多依赖项,它们具有自己的配置,需要在本地计算机上引发它们。 应用程序本身也有其自己的配置文件,其中有许多值。 测试本身具有一个配置,需要与应用程序配置匹配,并且可能还有多个配置值。 似乎所有这些听起来并不可怕,例如“在三个地方去修复配置”,但实际上,新员工可能要花几个小时才能做到这一点。
亚搏体育app CI + Docker
随着时间的流逝,该方案已转变为另一个方案:
GitLab CI和
Docker 。 发生这种情况不是因为以前的方案不理想,而是因为公司在行政组织方面略有改变。
以前,每个团队都有我们想要的或尽可能做到的很多人,并部署了其工作。 例如,我们有TeamCity,Chef,其他团队可以使用Jenkins或Ansible。
现在,我们正在向本地云和Kubernetes迁移,并且有一个单独的团队来管理所有这一切,包括GitLab CI和Kubernetes。 其他团队只是将其用作服务。 因为您不需要手动管理所有这些,所以这更加方便。
使用Kubernetes,我们部署了以下方案:

- 现在使用Gitlab CI代替TeamCity。
- GitLab CI构建一个Docker映像并将其部署到Kubernetes。 现在,配置直接存储在存储库中,而不是分别存储在Chef中,因此对于部署,您不需要使用第三方配置服务。
- 依赖关系也在Kubernetes中提前提出。
- 然后,GitLab CI启动SBT并在单独的步骤中进行测试。
一切都与先前的方案非常相似,并且与之根本没有区别,也就是说,即使优缺点也将完全相同,但是Docker出现了。
使用docker,您可以做更多有趣的事情,其中之一就是docker-compose。
Docker组成
这是Docker上的一种“覆盖”,它允许您将多个docker-images作为一个实体运行。
docker-compose确实可以帮上忙的一个很好的例子是Kafka。 她需要ZooKeeper才能运行。 如果您在没有docker-compose的情况下提升Kafka和ZooKeeper,则需要分别在docker中(Kafka)分别提升ZooKeeper,并使这两个docker容器保持一致。 这不是很方便,docker-compose允许您在一个docker-compose.yml文件中描述两个容器,并使用简单的docker
docker-compose run Kafka引发Kafka和ZooKeeper。
您可以在docker-compose上构建集成测试。 让我们看看它的外观。

- 同样,将所有内容推入GitLab。
- GitLab CI启动docker-compose。
- 在docker-compose中,应用程序启动,所有依赖项和SBT都启动,并且SBT驱动该应用程序的测试-一切都在docker-compose内部进行。
由于采用了这种方案,因此无需保留单独的环境和依赖项,因为一切都直接进入了GitLab CI运行程序,而docker和docker-compose则必须放在其中。 在开始过程中,他将抽取必要的图像并运行它们。
另外,您可以同时测试不同的分支,因为一切都在运行器上发生。
现在
,在本地配置环境
更加容易 ,但是您仍然需要协调多个位置。 问题是,现在,当我们进行本地配置时,我们不需要将所有内容都放在本地计算机上,所有内容都写入docker-compose.yml文件中。 因此,您必须在两个不同的地方进行配置-这是docker-compose.yml和测试的配置。
至于缺点,
仍然无法测试启动,停止和重新启动 ,因为从SBT到测试,我们无法控制应用程序的生命周期。 它由docker-compose运行,运行SBT,测试在SBT内部运行。 因此,没有完整的应用程序生命周期管理。 推出还有很多困难,我想多谈一谈。
码头工人组成2
在docker-compose 2时代,docker-compose.yml文件看起来像这样:
version: '2.1' services: web: build: . depends_on: db: condition: service_healthy redis: condition: service_started redis: image: redis db: image: db healthcheck: test: "some test here"
服务已在此处注册,即我们将在此docker-compose中提出的内容。 在这种情况下,我只是从docker-compose文档中举了一个例子。 提供三种服务:Web,Redis和db(数据库)。
Web是我们的应用程序,而redis和db是某种依赖性。
Web块中有一个名为
depends_on 。 这表明该Web应用程序依赖于其他一些容器,并在下面进行了描述:来自数据库和Redis。
另外,还有一个
condition子句。 对于redis,这是
service_started ,这意味着在redis启动之前,容器将不会尝试启动Web应用程序。
对于数据库,其条件为
service_healthy ,运行状况检查如下所述。 也就是说,我们不仅需要启动docker容器,还需要执行一定的运行状况检查。 它可以是任何自定义逻辑。
例如,我们使用PostgreSQL,后者使用PostGIS扩展,并且需要一些时间来初始化。 启动docker容器时,我们无法立即使用postgis扩展-我们需要等待扩展初始化。 因此,我们只
SELECT PostGIS_Version();查询
SELECT PostGIS_Version();到
SELECT PostGIS_Version(); 。 在扩展名初始化之前,请求将引发错误,并且在扩展名初始化后,它将开始返回版本。 这非常方便且合乎逻辑-
首先我们将提出所有依赖关系,然后提出应用程序 。
码头工人组成3
当docker-compose 3发布时,我们开始使用它。
但是在有关它的文档中,出现了一项更改depends_on逻辑的项目。 docker开发人员认为对依赖关系图的描述就足够了。 这意味着,当您启动
docker-compose run web ,应用程序本身及其依赖的数据库将同时启动。

文档的下一个段落说,depends_on不再是条件。
因此,如果您仍然想获得第二个版本中使用的功能,则必须自己掌握一切。
“
控制启动顺序”页面提供了几种解决方案。 第一种选择是使用
wait-for-it.sh 。
现在docker-compose.yml看起来有点不同:
version: '3' services: web: build: . depends_on: [ db, redis ] redis: image: redis command: [ "./wait-for-it.sh", ... ] db: image: redis command: [ "./wait-for-db.sh", ... ]
depends_on只是一个数组,没有条件。
在我们的依赖项中,我们重新定义命令,即在docker-compose中,您可以附加一个命令以启动Docker容器。
在那里,我们应该编写wait-for-it.sh,以及其他内容。 代替上面示例中的三点,我们应该编写需要等待的内容以及启动docker容器的原始命令。
为此,您需要找到docker文件,从那里复制redis命令并将其粘贴,数据库也是如此。 最大的缺点是
抽象崩溃了 -我不想知道哪个命令启动了Docker容器。 这些命令可能很简单,也很复杂,但是我不想打扰,我只想输入
docker run 。
我个人并不真的喜欢这种解决方案,但是我们有一些可以像这样工作的服务。
docker-compose之上的脚本
然后我认为是时候进行“自行车
建造 ”了,我有了
docker-compose-run.sh :
version: '3' services: postgres: ... my_service: depends_on: [ postgres ] ... sbt: depends_on: [ my_service ] ...
让我给您举一个半现实的例子:docker-compose.yml中有postgres,my_service应用程序(取决于postgres)和SBT(在其中运行测试并取决于我的服务)。
我不是通过docker run运行程序,而是通过docker-compose-run.sh脚本运行程序。
首先,它首先启动最深的依赖关系,在我的例子中是postgres。 该脚本以“守护程序”模式启动依赖关系,也就是说,它不会阻止终端:
docker-compose up -d postgres
然后,我等待wait_until函数满足条件。 可以说,这几乎与wait-for-it.sh相同。 当PostGIS初始化时,终端被阻塞,也就是说,程序也将等待,如果不等待,则会引发错误并停止测试。
wait_until 10 2 docker-compose exec -T postgres psql
初始化PostGIS后,请继续执行下一步,并对服务进行相同的操作。 对他来说,测试要简单一些:应该绑定端口80。
docker-compose up -d my_service wait_until 10 2 docker-compose exec -T \ my_service sh -c "netstat -ntlp | grep 80 || exit 1"
最后一步是通过运行命令运行SBT,在其中运行测试。
docker-compose run sbt down $?
因此,一切都以正确的顺序进行,但要手动进行。
最后,调用
down函数,该函数接受上一个命令的结果。 如果它是“ 0”,那么测试已经通过,我们只是关闭了docker-compose; 否则,我们首先“吐出”日志以找出问题所在,然后关闭docker-compose。
function down { echo "Exiting with code $1" if [[ $1 -eq 0 ]]; then docker-compose down exit $1 else docker-compose logs -t postgres my_service docker-compose down exit $1 fi }
这样的方案有效,但伸缩性不好。 每个服务都必须使用自己的逻辑描述其docker-compose-run.sh。 另外,启动配置在docker-compose-run.sh和docker-compose.yml之间扩展。 好吧,通常来说,我们似乎没有在使用docker-compose,但正在努力克服其缺点。
从代码运行docker
创建之前的方案时,我想:如果我已经在docker中拥有所有内容,那为什么不从代码中运行它。 我开始寻找解决方案,并找到了几种选择。
第一种选择是简单地
使用docker客户端 。 JVM世界中有两个主要的docker客户端:
docker-java和
spotify docker-client 。
Docker客户端允许您使用API直接从代码中运行docker命令。 也就是说,除了连接字符串以构建诸如
`docker run ...`类的命令外,您只需在代码中形成这样的命令并运行它即可。 它更加方便。
这种方法效果很好,而且可以肯定的是,他们可以做所有事情,但是这是一个很低的水平。 我将不得不创建自己的docker-compose类似物,这是一项非常艰巨的任务。
下一个选项是
docker-it-scala库 ,该
库包装了这两个客户端,并允许您选择要使用的后端。 她可以运行您需要的容器。
但是该库的缺点是它没有非常灵活的API,并且没有生命周期控制。
我也不喜欢这个选项,我继续搜索并找到了
Testcontainers 。 我想告诉您更多有关此的信息。
测试容器
这是一种用于启动和测试Docker容器的Java库。 有一个Scala外观,testcontainers-scala。 开箱即用,有许多流行的服务,例如PostgreSQL,MySQL,Nginx,Kafka,Selenium。 您可以运行任何其他容器。 该库具有相当简单和灵活的API,我将在后面详细介绍。
预定义的容器
因此,如何使用库中的预定义容器:实际上,一切都很简单,因为容器以对象的形式表示:
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6") pgContainer.start() val pgUrl: String = pgContainer.jdbcUrl val pgPort: Int = pgContainer.mappedPort(5432) pgContainer.stop()
在这种情况下,我们创建
PostgreSQLContainer ,我们可以启动它并开始使用它。 接下来,我们得到
jbdcUrl ,您可以使用它连接到PostgreSQL。 之后,我们得到了
mappedPort 。
这意味着PostgreSQL从docker端口5432伸出,Testcontainers看到该端口并自动分配给某个随机端口。 也就是说,从测试中我们可以看到例如32422。分配是自动进行的。
定制容器
以下视图,即所谓的自定义容器,也非常简单:
class GenericContainer( imageName: String, exposedPorts: Seq[Int] = Seq(), env: Map[String, String] = Map(), command: Seq[String] = Seq(), classpathResourceMapping: Seq[(String, String, BindMode)] = Seq(), waitStrategy: Option[WaitStrategy] = None ) ...
您需要从
GenericContainer继承并覆盖多个字段。 确保仅设置
imageName这是我们要创建的容器的名称。
您可以设置
exposedPorts端口:容器将伸出的那些端口。 在env中,您可以设置环境变量;也可以将
command设置为运行。
classpathResourceMapping允许您将资源从类路径扔到docker容器中。 例如,如果应用程序配置直接位于测试资源中,则这非常方便。 您只需在内部进行映射,泊坞窗内的应用程序即可访问此配置。
waitStrategy是
waitStrategy -compose 3中缺少的一个非常方便的东西,实际上是HealthCheck。 有几个预定义的
waitStrategy ,例如,您可以等待端口绑定发生,或者特定的http方法将返回200。但是您可以编写任何HealthCheck。
由于您仅在代码中编写HealthCheck,因此,您可以首先使用普通语言而不是bash,其次,可以使用代码中可用的任何库:如果要在Cassandra中进行自定义HealthCheck,请使用驱动程序并编写任何健康检查。
运行测试
现在有关如何运行测试的一些知识:
class PostgresqlSpec extends FlatSpec with ForAllTestContainer { override val container = PostgreSQLContainer() "PostgreSQL container" should "be started" in { Class.forName(container.driverClassName) val connection = DriverManager .getConnection(container.jdbcUrl, container.username, container.password) // test some stuff } }
我将讨论
ScalaTest ,这是Scala世界中的实际测试标准。
例如,我们要为Postgres编写测试。 创建一个
PostgresqlSpec测试,并从
ForAllTestContainer继承它。 这是图书馆提供的特征。 它会在所有测试之前启动必要的容器,并在所有测试之后停止它们。 或者,您可以使用
ForeachTestContainer ,然后容器在每次测试之前启动,在每个测试之后停止。
然后,您需要重新定义容器。 这可以通过重写
container属性来完成。 就我而言,我正在使用
PostgreSQLContainer 。
然后我们编写测试。 在示例中,我创建一个连接,使用jdbcUrl,用户名,密码,编写特定的测试,发送请求。
通常,集成测试需要几个容器。 我可以使用
MultipleContainers创建它们:
val pgContainer = PostgreSQLContainer() val myContainer = MyContainer() override val container = MultipleContainers(pgContainer, myContainer)
也就是说,我创建了容器,将它们添加到
MultipleContainers ,并将其用作
container 。
使用Testcontainers运行测试的方案如下:

- 在GitLa中推送代码。
- GitLab CI运行程序启动了SBT。
- SBT运行测试。 在测试内部,将启动我们的应用程序和依赖项。
该方案的优点:
- 无需保留单独的环境和依赖项,一切都在运行程序上发生。
- 您可以同时测试不同的分支。
- 您可以测试启动,停止和重新启动,因为我们可以控制应用程序的生命周期(一切都从测试代码开始)。
- 十分缺乏灵活的健康检查。
- 存储库中没有* .sh文件,您可以根据需要灵活地在应用程序中配置测试。
- 感谢classpathResource Mapping,您可以在测试和应用程序中使用相同的配置。
- 您可以从代码配置测试。
- 所有这些都可以在CI和本地上同样轻松地运行,因为这些只是作为单元测试看起来和运行的测试,因此只有所有内容都在docker容器中运行。
事实证明一切都很顺利和良好,但这只是乍一看,实际上,我们遇到了许多问题。
依赖容器
我们遇到的第一个问题是
从属容器 。 假设有某种测试:
class MySpec extends FlatSpec with ForAllTestContainer { val pgCont = PostgreSQLContainer() val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override val container = MultipleContainers(appCont, pgCont) // tests here }
它运行postgres和AppContainer。 来自postgres的appContainer传递了jdbcUrl,即连接的用户名和密码。 接下来,创建MultipleContainers并描述测试本身。
我运行程序并看到错误:
Exception encountered when invoking run on a nested suite - Mapped port can only be obtained after the container is started
关键是要在容器启动之前才能使用分配的端口。 为什么会这样呢?
事实是,
ForAllTestContainer或
ForEachTestContainer在测试之前而不是在创建容器实例时
ForEachTestContainer启动容器。 事实证明,当我创建AppContainer时,尚未打开
PostgreSQLContainer ,这意味着我无法从中获取分配的端口,并且需要它来形成
jdbcUrl 。
问题在于容器的本质是可变的:它具有几种状态。 例如,可以将其关闭和打开。
如何解决这个问题? 我将第一种方法称为“惰性”。
class MyTest extends FreeSpec with BeforeAndAfterAll { lazy val pgCont = PostgreSQLContainer() lazy val appCont = AppContainer(pgCont.jdbcUrl, pgCont.username, pgCont.password) override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() } // tests here }
主要思想是使用
lazy val创建容器。 然后它们将不会在测试构造函数中立即初始化,而是将等待第一个调用。 我们将在
beforeAll和
afterAll初始化,这是ScalaTest提供的BeforeAndAfterAll
BeforeAndAfterAll 。 在
beforeAll容器启动,在
afterAll ,它们关闭。 由于容器被声明为惰性容器,因此在beforeAll中调用start方法时,将创建,初始化和启动它们。
但是,仍然出现错误,我无法加入本地主机:32787:
org.postgresql.util.PSQLException: Connection to localhost:32787 refused. Check that the hostname and port are correct and that the postmaster is accepting TCP/IP connections.
似乎我们使用了jdbcUrl,为什么本地主机出现? 让我们看看jdbcUrl是如何工作的:
@Override public String getJdbcUrl() { return "jdbc:postgresql://" + getContainerIpAddress() + ":" + getMappedPort(POSTGRESQL_PORT) + "/" + databaseName; }
它只是一个字符串连接。 一切都是常数,它们是清晰的;它们不能破坏。
getMappedPort应该工作,因为我们已经修复了它。
databaseName是一个硬编码的常量。 但是使用
getContainerIpAddress更有趣。 按名称,我们可以假定它应该返回容器的IP地址。 但是,如果运行此代码,事实证明它始终返回localhost。 事实证明,此方法不适用于容器间交互:
getContainerIpAddress 提供来自容器内部测试的交互 。
Testcontainers开发人员建议:
创建一个用于容器间通信的自定义网络 。 Docker-compose的工作原理如下:创建网络并自行解决所有问题。
因此,您需要创建一个网络。
class MyTest extends FreeSpec with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override def beforeAll(): Unit = { super.beforeAll() pgCont.start() appCont.start() } override def afterAll(): Unit = { super.afterAll() appCont.stop() pgCont.stop() network.close() } // tests here }
现在,我们必须手动配置jdbcUrl。 我们还需要在网络中启用我们的容器,并为PostgreSQLContainer设置别名,以便可以通过某些域名在网络中访问它。 最后,您必须记住要“杀死”网络。
最后,这样的程序将起作用。
在最新版本的testcontainers-scala中,开箱即用地支持惰性容器初始化:
class MyTest extends FreeSpec with ForAllTestContainer with BeforeAndAfterAll { val network: Network = Network.newNetwork() val dbName = "some_db" val pgContainerAlias = "postgres" val jdbcUrl = s"jdbc:postgresql://$pgContainerAlias:5432/$dbName" lazy val pgCont = { val c = PostgreSQLContainer("postgres:9.6") c.container.withNetwork(network) c.container.withNetworkAliases(pgContainerAlias) c.container.withDatabaseName(dbName) c } lazy val appCont = { val c = AppContainer(jdbcUrl, pgCont.username, pgCont.password) c.container.withNetwork(network) c } override val container = MultipleContainers(pgCont, appCont) override def afterAll(): Unit = { super.afterAll() network.close() } // tests here }
您可以再次使用
ForAllTestContainer和
MultipleContainers 。 在
beforeAll不再需要手动
beforeAll开始顺序。 现在,
MultipleContainers可以使用lazy val并以正确的顺序运行它们,并且在创建时不会立即进行严格的初始化。 同时,使用自定义网络和jdbcUrl的操作也需要手动完成。
嘲弄
但是,仍然存在问题。 例如moki。 有时在Docker容器中创建某种依赖关系不是很方便。 我们使用Spark JobServer,它创建Spark作业并在Spark中控制其生命周期。 我们使用它的两种方法:“创建”和“给予状态”。
在docker内部运行Spark JobServer 有必要提高Spark,直到最近为止,它根本没有docker容器,必须自己组装它。 此外,Spark JobServer使用PostgreSQL存储状态。 结果,当您实际上只需要两个带有简单API的方法时,就必须做很多困难的工作。
但是,您可以查看Spark JobServer的实现,并创建行为相同的模拟,但不需要原始Spark JobServer的依赖项。
看起来像这样(在示例中为简化的伪代码):
val hostIp = ??? AppContainer(sparkJobServerMockHost = hostIp) val sparkJobServerMock = new SparkJobServerMock() sparkJobServerMock.init(someData) val apiResult = appApi.callMethod() assert(apiResult == someData)
http- API Spark JobServer. - , . , , , mock.
- , . : «» config; , host.
SparkJobServerMock , host-, docker-, , , docker-.
? docker-, , gateway , docker-.
, Testcontainers API. , Testcontainers docker-java-, . «» docker-:
val client: com.github.dockerjava.api.DockerClient = DockerClientFactory .instance .client val networkInfo: com.github.dockerjava.api.model.Network = client .inspectNetworkCmd() .withNetworkId(network.getId) .exec() val hostIp: String = networkInfo .getIpam .getConfig .get(0) .getGateway
-,
DockerClient . Testcontainers
DockerClientFactory . c
inspectNetworkCmd . , info, gateway.
, , .
— . Docker : Windows, Mac, . Linux. , , Linux .
, Testcontainers . , docker-. :
Testcontainers.exposeHostPorts(sparkJobServerMockPort)
,
. docker-.
`host.testcontainers.internal` .
, :
val sparkJobServerMockHost = "host.testcontainers.internal" val sparkJobServerMockPort = 33333 Testcontainers.exposeHostPorts(sparkJobServerPort) AppContainer(sparkJobServerMockHost, sparkJobServerMockPort)
Testcontainers
, , Testcontainers , . Java-, Scala-. :
- . , testcontainers-java JUnit, testcontainers-scala ScalaTest, testcontainers-java . Scala- .
- Scala . . , . , predefined Java-. , .
- API . API, . , . , , .
总结
. Docker , , , , network gateway.
Testcontainers — , . API , .
Java-, . — . .
, docker-, .
— , , , . .?, .
— - ?Kubernetes, . end-to-end , , , , .
, , unit-, .
— Kubernetes ?-, , -, , , , Spark Kubernetes ; , .
, , unit-, , , break point , , .
, , , CI , .
, minicube — Mac, . , , , , .
— ? : master? , - , , 2.1, 2.2, ?ImageName, Postgres 9.6.
val pgContainer: PostgreSQLContainer = PostgreSQLContainer("postgres:9.6")
9.6, 10. [ ], .
Image tag — , — , . , latest .
— , ?, CI , GitLab CI , , Branch Name.
— , , , ? - , ? 20- , ?-, , . , , , , , .
- , , full-time , , , .
commit', , , , Android, iOS . . , , , , — .
, , -: - , - . , - .
Scala – ScalaConf . – HighLoad++ 7-8 .
, , , , .