验证码主题并不新鲜,包括Habr。 但是,验证码算法及其解决方案的算法正在发生变化。 因此,建议记住旧版本并使用以下版本的验证码:

沿途了解实际中简单神经网络的工作,并改善其结果。
立即提出一个保留意见,即我们不会陷入有关神经元如何工作以及如何处理所有这些问题的思考,这篇文章并不声称是科学的,而只是提供了一个小教程。
在炉子上跳舞。 而不是加入
也许有人的话会重复出现,但是有关深度学习的大多数书籍实际上都是从向读者提供了他可以开始使用的预先准备好的数据这一事实开始的。 MNIST不知何故-60,000个手写数字,CIFAR-10等。 阅读后,一个人出来……准备好这些数据集。 尚不清楚如何使用数据,最重要的是,在构建自己的神经网络时如何改进某些东西。
这就是为什么
pyimagesearch.com上有关如何使用您自己的数据及其
翻译的文章非常方便的原因。
但是正如他们所说,萝卜辣根并不甜:即使翻译了喀拉拉邦嚼过的文章,也有很多盲点。 同样,只提供了猫,狗和熊猫的预先准备好的数据集。 必须自己填补空白。
但是,本文和代码将作为基础。
我们在验证码上收集数据
这里没有新内容。 我们需要验证码样本,因为 网络将在我们的指导下向他们学习。 您可以自己开采验证码,也可以在此处购买
29,000个验证码 。 现在,您需要减少每个验证码的数字。 不必全部削减29,000个验证码,尤其是因为1个验证码可以提供5位数字。 500个验证码将绰绰有余。
怎么切? 在Photoshop中可以,但最好使用一把更好的刀。
这是python刀的代码
下载 。 (对于Windows。首先创建文件夹C:\ 1 \ test和C:\ 1 \ test-out)。
输出将是从1到9的数字转储(验证码中没有零)。
接下来,您需要将这些障碍从数字解析到1到9的文件夹中,并按相应的数字放入每个文件夹中。 马马虎虎的职业。 但是一天之内最多只能输入1000个数字。
如果在选择一个数字时不确定哪个数字,最好删除此样本。 如果数字嘈杂或输入的数字不完整,也可以:


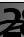
您需要在每个文件夹中收集200个每个数字的样本。 您可以将这项工作委派给第三方服务,但是最好自己动手做,以免以后找不到不匹配的数字。
神经网络。 测验
,,我们的网把死人拖了在开始使用自己的数据之前,最好阅读上面的文章并运行代码,以了解所有组件(keras,tensorflow等)均已安装并正常工作。
我们将使用一个简单的网络,其启动语法来自命令(!)行:
python train_simple_nn.py --dataset animals --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
* Tensorflow可以在处理其自身文件和过时的方法中的错误时进行编写,您可以手动修复它,也可以简单地忽略它。
最主要的是,在编写完程序之后,两个文件会出现在项目项目文件夹中:simple_nn_lb.pickle和simple_nn.model,并显示带有铭文和识别率的动物图像,例如:

神经网络-自己的数据
现在,网络健康测试已通过验证,您可以连接自己的数据并开始训练网络。
将dat文件夹放入包含每个数字包含选定样本的数字的文件夹中。
为了方便起见,我们将dat文件夹放置在项目文件夹中(例如,动物文件夹旁边)。
现在,开始网络学习的语法将是:
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
但是,现在开始培训还为时过早。
您需要修复train_simple_nn.py文件。
1.在文件末尾:
这将添加信息。
2。
image = cv2.resize(image, (32, 32)).flatten()
更改为
image = cv2.resize(image, (16, 37)).flatten()
在这里,我们调整输入图像的大小。 为什么要这么大? 因为大多数切碎的数字要么都是这个大小,要么就是缩小了。 如果缩放到32x32像素,图片将失真。 是的,为什么呢?
另外,我们将此更改推入尝试:
try: image = cv2.resize(image, (16, 37)).flatten() except: continue
因为 该程序无法消化某些图片,并且没有问题,因此将其跳过。
3.现在最重要的事情。 代码中有注释的地方
用Keras定义架构3072-1024-512-3
本文中的网络体系结构定义为3072-1024-512-3。 这意味着网络在输入处接收到3072(32像素* 32像素* 3),然后在图层1024,图层512和输出3个选项(猫,狗或熊猫)上接收。
在我们的例子中,输入为1776(16像素* 37像素* 3),然后是9个数字变体的输出处的第1024层,第512层。
因此我们的代码:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid"))model.add(Dense(512, activation="sigmoid"))
* 9个输出不需要额外指出,因为 程序本身根据数据集中的文件夹数确定退出次数。
我们启动
python train_simple_nn.py --dataset dat --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --plot output/simple_nn_plot.png
由于带有数字的图片很小,因此即使在硬件较弱的情况下,仅使用CPU,网络也可以很快(5-10分钟)学习。
在命令行中运行程序后,请查看结果:
这意味着在训练集上,达到了保真度-82.19%,在对照组上达到-75.6%,在测试上达到-75.59%。
在大多数情况下,我们需要关注后者。 为什么其他原因也很重要,将在后面说明。
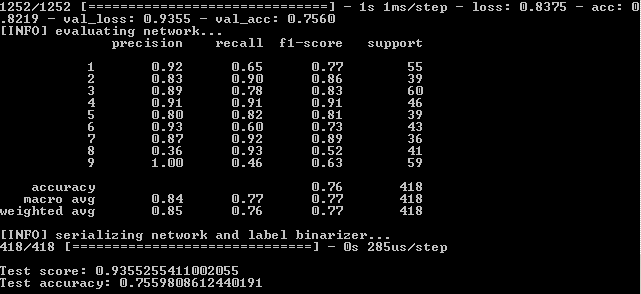
我们还要看一下神经网络工作的图形部分。 它在simple_nn_plot.png项目的输出文件夹中:
更快,更高,更强。 改善结果
有关设置神经网络的详细信息,请参见
此处 。
真实选项如下。
添加时代。
在代码中我们更改
EPOCHS = 75
在
EPOCHS = 200
增加网络将接受训练的“次数”。
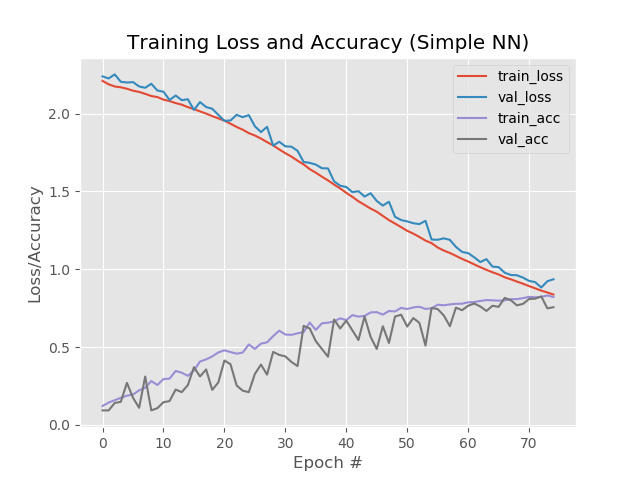
结果:
因此,分别为93.5%,92.6%,92.6%。
在图片中:
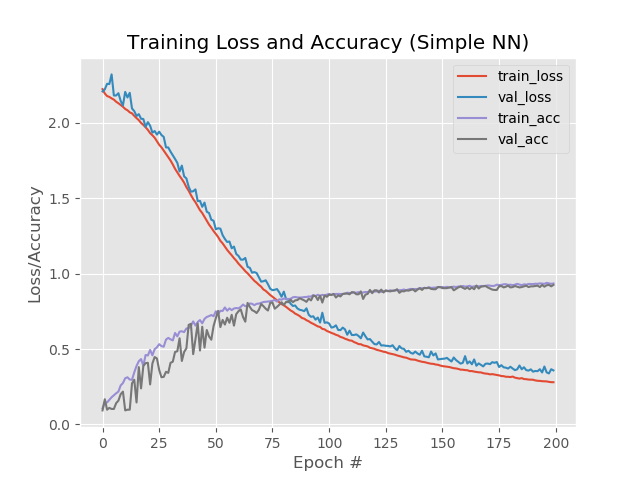
在这里值得注意的是,第130个时代之后的蓝线和红线开始相互分散,这意味着纪元数的进一步增加将行不通。 检查一下。
在代码中我们更改
EPOCHS = 200
在
EPOCHS = 500
再跑开
结果:
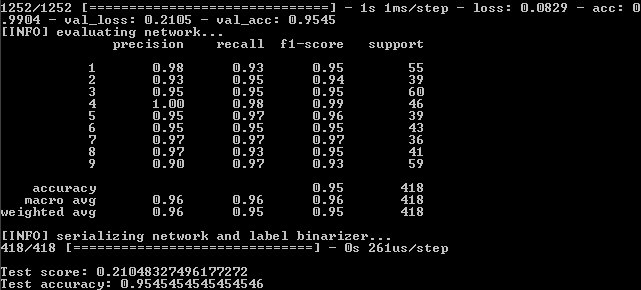
因此,我们有:
99%,95.5%,95.5%。
在图表上:
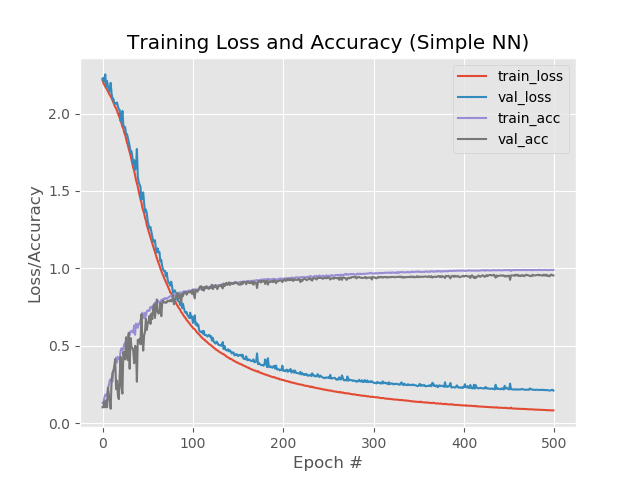
好吧,时代的增长显然已经到了网络。 但是,此结果具有误导性。
让我们使用一个真实的例子来检查网络操作。
为此,predict.py脚本位于项目文件夹中。 开始之前,请准备。
在项目的图片文件夹中,我们将文件和验证码中的数字图像放入文件中,而该网络以前在学习过程中并未遇到过。 即 有必要从dat数据集dat中获取数字。
在文件本身中,我们修复了默认图像大小的两行:
ap.add_argument("-w", "--width", type=int, default=16, help="target spatial dimension width") ap.add_argument("-e", "--height", type=int, default=37, help="target spatial dimension height")
从命令行运行:
python predict.py --image images/1.jpg --model output/simple_nn.model --label-bin output/simple_nn_lb.pickle --flatten 1
我们看到了结果:
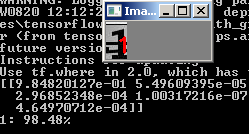
另一张图片:
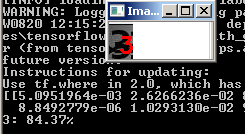
但是,它不适用于所有嘈杂的号码:
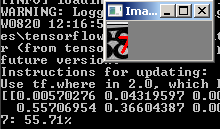
在这里可以做什么?
- 增加文件夹中用于培训的数字的副本数。
- 尝试其他方法。
让我们尝试其他方法
从上一张图可以看出,蓝色和红色线条在第130个时代前后发生了分歧。 这意味着130年代以后的学习是无效的。 我们将结果固定在第130个时代:89.3%,88%,88%,并查看是否有其他方法可以改善网络工作。
降低学习速度。 INIT_LR = 0.01
在
INIT_LR = 0.001
结果:
41%,39%,39%
好吧,靠。
添加其他隐藏层。 model.add(Dense(512, activation="sigmoid"))
在
model.add(Dense(512, activation="sigmoid")) model.add(Dense(258, activation="sigmoid"))
结果:
56%,62%,62%
更好,但是没有。
但是,如果您将时代数增加到250:
84%,83%,83%
同时,在第130个时代之后,红线和蓝线并没有相互脱离:
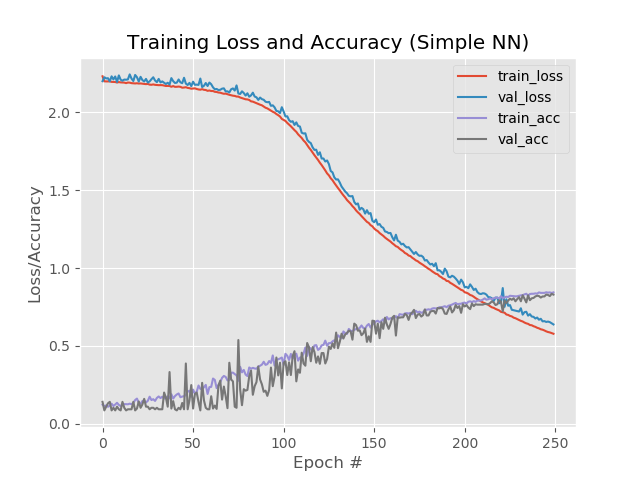 保存250个时代并应用细化
保存250个时代并应用细化 :
from keras.layers.core import Dropout
在各层之间插入细化:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid")) model.add(Dropout(0.3))
结果:
53%,65%,65%
第一个值低于其他值,这表明网络没有学习。 为此,建议增加时代数。
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3))
结果:
88%,92%,92%
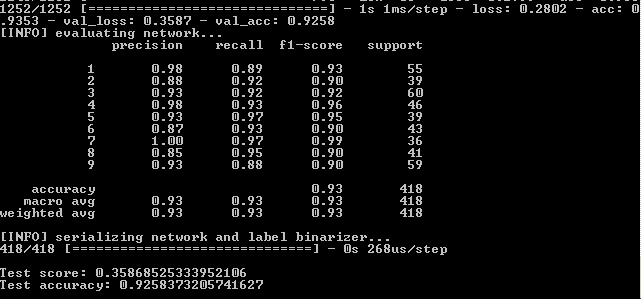
额外增加1层,细化和500个时代:
model.add(Dense(1024, input_shape=(1776,), activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(512, activation="sigmoid")) model.add(Dropout(0.3)) model.add(Dense(258, activation="sigmoid"))
结果:
92.4%,92.6%,92.58%
尽管与将时代简单增加到500年相比,百分比较低,但该图看起来更加均匀:
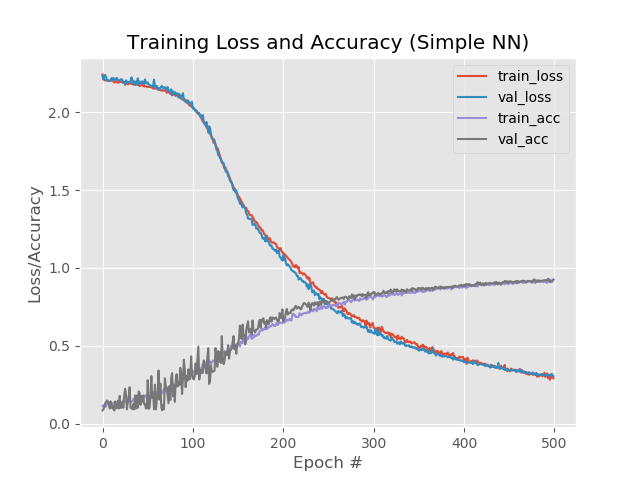
网络处理以前掉落的图像:
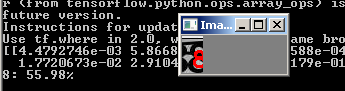
现在我们将所有内容收集到一个文件中,该文件会将带有输入验证码的图像切成5位数字,通过神经网络运行每个数字并将结果输出到python解释器。
这里比较简单。 在从验证码中截取数字的文件中,添加处理预测的文件。
现在,该程序不仅将验证码分为5个部分,而且还在解释器中显示了所有可识别的数字:

同样,必须牢记该程序不能给出结果的100%,并且通常5位数字之一是不正确的。 但这是一个很好的结果,考虑到训练集中每个数字只有170-200份。
验证码识别在中功率计算机上可持续3-5秒。
您还可以尝试如何改善网络?您可以在“ Keras Library-深度学习工具”一书中阅读A. Dzhulli,S. Pala。
剪切验证码并识别的最终脚本
在这里 。
它开始时没有参数。
用于
培训和
测试网络的再生脚本。
验证码,包括误报-
在此处 。
工作模型在
这里 。
文件夹中的数字在
这里 。