在本文中,我将描述我们将Preply迁移到Kubernetes的经验,我们如何以及为什么这样做,遇到的困难以及获得的好处。

Kubernetes的Kubernetes吗? 不,业务要求!
Kubernetes周围有很多炒作,这是有充分理由的。 许多人说它可以解决所有问题,有些人说您很可能不需要Kubernetes 。 事实当然是介于两者之间。

但是,所有关于在何时何地需要Kubernetes的讨论都值得单独撰写。 现在,我将简单介绍一下我们的业务需求以及在迁移到Kubernetes之前Preply的工作方式:
- 使用Skullcandy flow时 ,我们有很多分支,所有分支都合并到一个称为
stage-rc的公共分支中,并部署到了stage。 QA团队在测试分支在主服务器中处于快乐状态并将主服务器部署到产品之后,对该环境进行了测试。 整个过程大约需要3-4个小时 ,我们每天可以部署0到2次 - 当我们将损坏的代码部署到产品时,我们必须回滚最新版本中包含的所有更改。 也很难找到哪个变化破坏了我们的产品
- 我们使用AWS Elastic Beanstalk托管我们的应用程序。 在我们的案例中,每个Beanstalk部署都花费了45分钟(整个流程以及测试过程都在90分钟内完成 )。 回滚到该应用程序的先前版本需要45分钟
为了改善公司的产品和流程,我们希望:
- 打破整体进入微服务
- 更快更频繁地部署
- 回滚更快
- 更改我们的开发流程,因为我们认为它不再有效
我们的需求
我们改变发展过程
为了用Skullcandy flow实现我们的创新,我们需要为每个分支创建一个动态环境。 在我们使用Elastic Beanstalk中的应用程序配置的方法中,这样做既困难又昂贵。 我们想要创建一个环境,该环境将:
- 快速轻松地部署(最好是容器)
- 在现场实例上工作
- 它们与产品相似
我们决定转向基于主干的开发。 在它的帮助下,每个功能都有一个单独的分支,该分支可以独立于其余分支而合并为母版。 可以随时部署master分支。
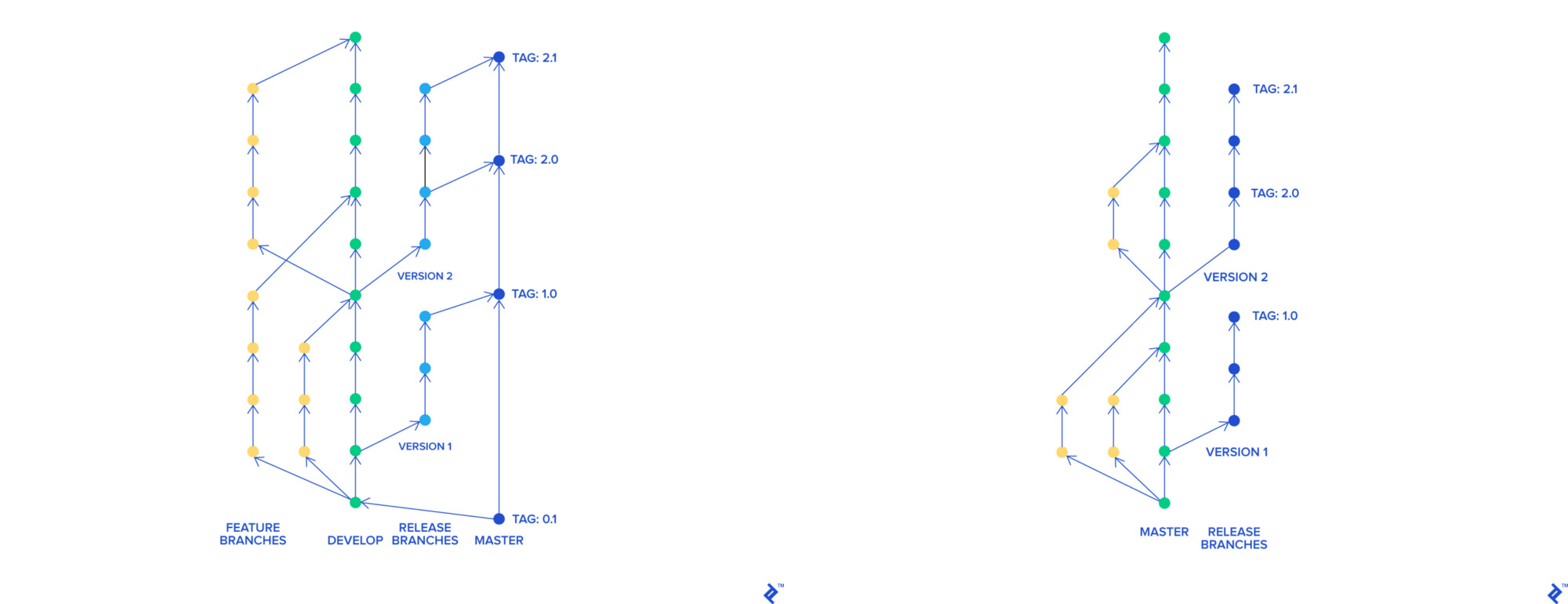
git-flow和基于Trunk的开发
更快更频繁地部署
新的基于Trunk的流程使我们可以更快地将创新转移到主分支。 这极大地帮助了我们在产品中查找损坏的代码并将其回滚的过程。 但是,部署时间仍然是90分钟,回滚时间是45分钟,因此,我们每天不能更频繁地部署4-5次。
在Elastic Beanstalk上使用服务体系结构时,我们也遇到了困难。 最明显的解决方案是使用容器和工具进行编排。 此外,我们已经有使用Docker和docker-compose进行本地开发的经验。
我们的下一步是研究流行的容器协调器:
我们决定留在Kubernetes,这就是原因。 在所讨论的协调器中,每个人都有一些重要的缺陷:ECS是与供应商相关的解决方案,Swarm已经失去了Kubernetes桂冠,Apache Mesos的Zookeeper看起来像我们的太空船。 Nomad看起来很有趣,但是它仅在与其他Hashicorp产品集成时才充分展现出来,令我们感到失望的是Nomad中的名称空间是付费的。
尽管入门门槛很高,但Kubernetes是容器编排的事实上的标准。 大多数主要的云提供商都提供Kubernetes即服务。 乐团正在积极开发中,拥有大量的用户和开发人员社区,并且拥有良好的文档资料。
我们希望在1年内将我们的平台完全迁移到Kubernetes。 两名没有Kubernetes经验的平台工程师参与了部分引导迁移。
使用Kubernetes
我们从概念验证开始,创建了测试集群,并详细记录了我们所做的所有事情。 我们决定使用kops ,因为当时我们的地区仍无法使用EKS(爱尔兰于2018年9月宣布)。
在使用集群时,我们测试了cluster-autoscaler , cert-manager ,Prometheus,与Hashicorp Vault,Jenkins的集成等。 我们“玩弄”滚动更新策略,面临多个网络问题,尤其是DNS ,并增强了我们在集群群集方面的知识。
他们使用竞价型实例来优化基础架构成本。 为了接收有关竞价型问题的通知,他们使用kube-spot-termination-notice-handler , 竞价型 实例顾问可以帮助您选择竞价型 实例的类型。
我们开始从Skullcandy流程迁移到基于Trunk的开发,在此我们为每个pulrequest启动了一个动态阶段,这使我们能够将新功能的交付时间从4-6减少到1-2小时 。
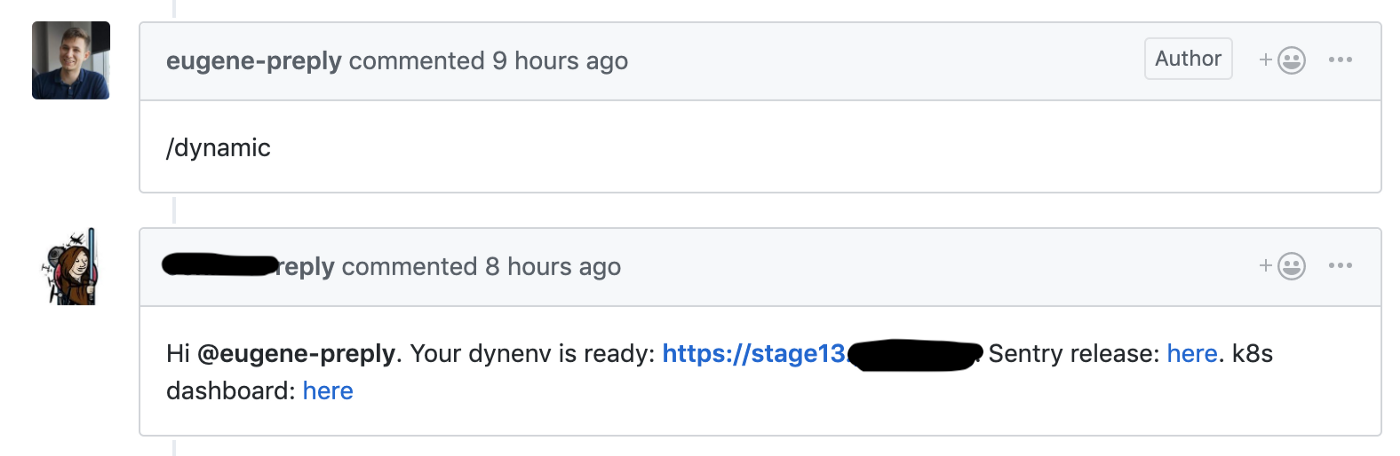
Github钩子启动创建用于拉动请求的动态环境
我们在这些动态环境中使用了测试集群,每个环境都位于单独的命名空间中。 开发人员可以访问Kubernetes仪表板来调试其代码。
我们很高兴在使用Kubernetes仅仅1-2个月后就开始从Kubernetes中受益。
舞台和销售集群
我们针对舞台和产品集群的设置:
在使用集群时,我们遇到了几个问题。 例如,Nginx Ingress和Datadog代理的版本在群集上有所不同,与此相关的是,某些事情在舞台群集上起作用,但不适用于产品。 因此,我们决定完全遵照群集上的软件版本以避免此类情况。
将产品迁移到Kubernetes
阶段和食物群已经准备就绪,我们已经准备好开始迁移。 我们使用具有以下结构的monorepa:
. ├── microservice1 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microservice2 │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── microserviceN │ ├── Dockerfile │ ├── Jenkinsfile │ └── ... ├── helm │ ├── microservice1 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microservice2 │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml │ ├── microserviceN │ │ ├── Chart.yaml │ │ ├── ... │ │ ├── values.prod.yaml │ │ └── values.stage.yaml └── Jenkinsfile
根Jenkinsfile包含一个微服务名称和其代码所在目录之间的对应表。 当开发人员向主服务器提出拉取请求时,会在GitHub中创建一个标签,该标签根据Jenkinsfile使用Jenkins部署到产品中。
helm/目录包含带有两个单独的值文件的HELM图表,用于舞台和销售。 我们使用Skaffold将许多HELM图表部署到舞台上。 我们试图使用伞形图,但面临着难以扩展的事实。
根据十二要素应用程序,产品中的每个新微服务都会将日志写入stdout,从Vault中读取机密,并具有一组基本的警报(检查工作炉膛的数量,五百个错误和入口处的拉滕)。
无论我们是否将新功能导入微服务,在我们的案例中,所有主要功能都在Django整体中,并且该整体仍可在Elastic Beanstalk上运行。

将整体拆分为微服务//奥斯陆的维格兰公园
我们将AWS Cloudfront用作CDN,并在整个迁移过程中使用了Canary部署。 我们开始将整体程序迁移到Kubernetes,并在某些语言版本和网站内部页面(例如管理面板)上对其进行测试。 类似的迁移过程使我们能够捕获产品上的错误,并仅需几次迭代即可完善我们的部署。 在几周的过程中,我们监视了平台的状态,负载和监视,最后,100%的销售流量都切换到了Kubernetes。
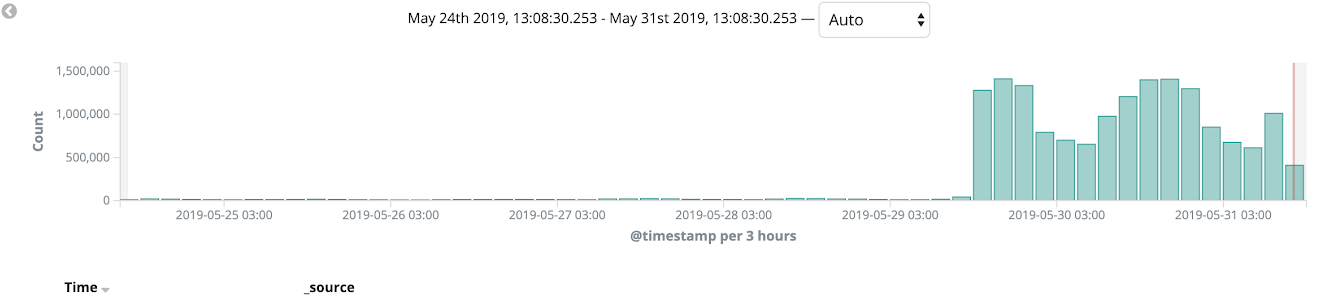
之后,我们完全可以放弃使用Elastic Beanstalk。
总结
如上所述,完全迁移花了我们11个月的时间,我们计划在1年的最后期限之前完成迁移。
实际上,结果很明显:
- 部署时间从90分钟减少到40分钟
- 部署数量从每天0-2增加到每天10-15 (并且还在不断增加!)
- 回滚时间从45 分钟减少至1-2分钟
- 我们可以轻松地向产品交付新的微服务
- 我们整理了监视,日志记录,机密管理的内容,将它们集中化并描述为代码
这是一次非常酷的迁移体验,我们仍在进行许多平台改进。 一定要阅读来自Jura的有关Kubernetes经验的精彩文章 ,他是参与Preply实施Kubernetes的YAML工程师之一。