在密码学领域,有许多简单的方法可以加密消息。 他们每个人都有自己的优点。 将讨论其中之一。
伊尔舒·舒格科夫(Ylchu Schzzkgow)
或从“凯撒的密码”翻译成俄文- 凯撒的密码 。

-它的本质是什么?
-他对消息进行编码,将每个字母移动N点。 凯撒的经典密码将字母向前移动了三步。 简而言之-它是“ abv”,它变成了“ where”。
“但是字母结尾的字母呢?” 那空间呢?
他们没事。 如果移动字母,则密码超出了字母的范围-它再次开始重新计数。 即,字母“ Eyuya”变成“ abv”。 空间仍然是空间。
-N是否必须等于3?
一点也不。 N可以不同于3。 允许[1:M-1]之间的任何N,其中M是字母表中字母的数目。
如果您知道这种密码的存在,则很容易解密。 但是吸引我的不是他的“可靠性”,而是其他。
领带
我想知道一个夏日:
- 但是,如果我使用凯撒(Caesar)加密单词,并且在输出中得到一个现有单词,该怎么办?
- “ shifters”有多少个这样的词?
- 如果改变N,会有规律吗?
我在同一分钟内开始寻找这些问题的答案。
任务:找到所有单词
撤退。 从Mikhail Zadornov的音乐会和个人经验中,我了解两件事:
- 俄国喜剧演员的讲话并不冒犯美国人。
- 俄语是强大的。 里面有很多话。
因此,我决定以英语为基础。 此外,曾几何时,会说英语的人能够拼凑出完整的英语单词词典。 是什么促使我找到了这样的数据集。
搜寻迟缓的第一行将我带到这个存储库 。 作者承诺以方便的格式提供47.9万个英语单词。 我喜欢json文件,其中所有单词均以方便的形式进行布局,以便加载到Python字典中。
进行第一次尸检后,发现字数较少-370 101件。 我想:“但这没关系,因为一个很好的例子就足够了。”
words = json.load(open('words_dictionary.json', 'r')) len(words.keys()) >> 370101
首先,您需要创建一个字母。 我决定以最方便的方式将其列出。 还需要记住字母表中字母的数量:
abc = list('abcdefghijklmnopqrstuvwxyz') abc_len = len(abc)
首先,实现将单词翻译成加密的功能很有趣。 这是发生了什么:
我决定对所有单词进行一个大循环,然后开始逐一翻译。 但是遇到了一个问题。 事实证明,某些单词包含“-”符号,这是令人惊讶的,同时又很自然。
不用三思而后行,我数了数这样的单词,结果发现只有两个。 之后,他将两者都删除了,因为这几乎不会影响结果。 为了帮助我,此功能诞生了:
字典看起来像:
{'a': 1, 'aa': 1, 'aaa': 1, 'aah': 1, ... }
因此,我决定不聪明,用编码的单词代替那些。 为此,编写了一个函数:
当然,我们需要一个大循环,遍历所有词,找到词移位器并保存结果。 这是:
您可能已经注意到,该函数的参数为“ min_len = 0”。 将来将需要他。 因为该数据集的特殊性是一组“奇怪”的单词。 如:“ aa”,“ aah”和类似的组合。 是他们给了第一个结果-660字移位器。
因此,我必须限制五个字符(至少五个字符),以使这些单词令人耳目一新,并且与现有单词相似。
words_result = check_all(words_cesar, min_len=5) words_result >> {'abime': 'delph', 'biabo': 'elder', 'bifer': 'elihu', 'cobra': 'freud', 'colob': 'frore', 'oxime': 'ralph', 'pelta': 'showd', 'primero': 'sulphur', 'teloi': 'whorl', 'xerox': 'ahura'}
是的,由于该算法,发现了十个翻转词。 我最喜欢的组合:
底漆[第一]→硫[硫]。 Google翻译器无法识别其他大多数对。
在这个阶段,我部分地消除了对知识的渴望。 但是前面有类似的问题:“另一个N呢?”
并使用此功能,我找到了答案:
周期在10-15秒内完成。 剩下的只是看结果。 但是,我认为有时间表的时候会更有趣。 这是最后一个函数,它将向我们显示结果:
总结
开始时回答问题
“如果我使用凯撒(Caesar)加密单词,并且在输出中得到现有单词怎么办?”
-这是可能的,甚至非常可能。 一些N比其他词多得多。
-那里有多少个这样的单词“ shifters”?
-取决于N,最小长度,当然也取决于数据集。 在我的情况下,当N = 3时,最小字长0和5是字数:分别为660和10。
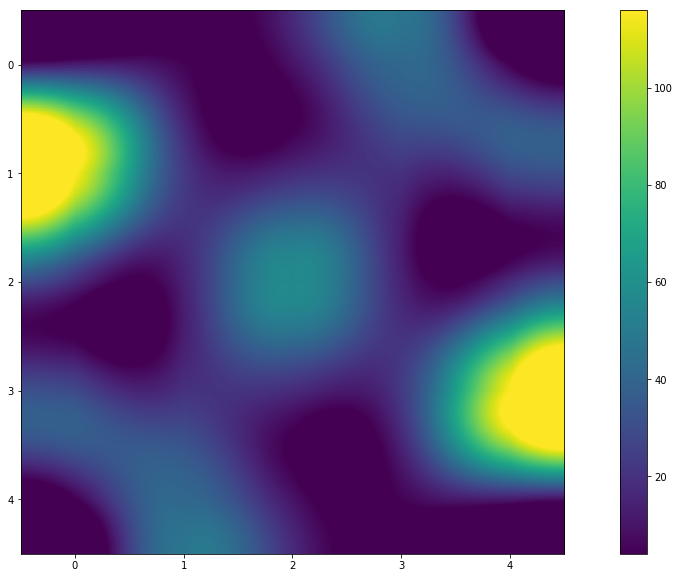
-如果您更改N,会有规律吗?
-显然是的! 从图表(或热图)中,您可以看到颜色是对称的。 结果矩阵中的值表明了这一点。 以及“为什么会这样?”这个问题的答案。 我将它留给读者。
这项工作的缺点
- 数据集不太正确。 许多单词并不明显。 虽然可能是这样。 这些是英语中的“ 全部 ”单词。
- 代号
总是 可以改善。 - “凯撒代码”是“雅典代码”的特例,其公式为:
对于“凯撒的密码”,A =1。顺便说一句,他有更多细微差别,这意味着更有趣。
我的工作文件及其结果和翻转词列表位于此存储库中
Efzp zzhgl!