SQL Server中的分区(“分区”)看似简单(“在那里-您按文件组分布表和索引,并从管理和性能中获利”)是一个相当广泛的主题。 下面,我将尝试描述如何创建和应用函数和分区方案以及您可能遇到的问题。 除了一件事-切换部分,当您立即从表中删除一个巨大的数据集时,我将不谈这些好处。反之亦然-立即将一个同样巨大的数据集加载到表中。
如
msdn所言:“分区表和索引的数据分为多个块,这些块可以分布在数据库中的多个文件组中。 数据是水平分区的,因此行组被映射到各个部分。 相同索引或表的所有部分必须位于同一数据库中。 在对数据执行查询或更新时,表或索引被视为单个逻辑实体。”
此处还列出了主要优点:
- 快速高效地传输和访问数据子集,同时保持数据集的完整性
- 一个或多个部分可以更快地执行维护操作;
- 您可以提高查询执行的速度,具体取决于硬件配置中经常执行的查询。
换句话说,分区用于水平缩放。 表/索引由不同的文件组“散布”,这些文件组可以位于不同的物理磁盘上,这显着增加了管理的便利性,并且从理论上讲,提高了对该数据的查询性能-您可以只读取所需的部分(较少的数据),或者读取所有内容并行(设备不同,读取速度快)。 实际上,一切都有些复杂,并且仅当查询使用分区依据的字段进行选择时,提高对分区表的查询的性能才能起作用。 如果您还没有分区表的经验,请记住,查询的性能可能不会改变,但是在对表进行分区后,性能可能会下降。
让我们谈谈您肯定会与分区相处的绝对优势(但是您还需要使用分区)-这肯定会提高管理数据库的便利性。 例如,您有一个包含十亿条记录的表,其中有9亿条来自旧(“封闭”)期间,并且是只读的。 在分区的帮助下,您可以将旧数据传输到一个单独的只读文件组中,进行备份,而不再将其拖到您的所有日常备份中-创建备份副本的速度将增加,大小将减小。 您可以不在整个表上而是在选定的部分上重建索引。 此外,数据库的可用性正在增长-如果包含具有该部分的文件组的设备之一发生故障,则其他设备仍然可用。
为了获得剩余的好处(立即切换部分;提高生产率)-您需要专门设计数据结构并编写查询。
我想我已经足够使读者难堪了,现在我可以继续练习。
首先,创建一个包含4个文件组的数据库,我们将在其中进行实验:
create database [PartitionTest] on primary (name ='PTestPrimary', filename = 'E:\data\partitionTestPrimary.mdf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg1] (name ='PTestFG1', filename = 'E:\data\partitionTestFG1.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg2] (name ='PTestFG2', filename = 'E:\data\partitionTestFG2.ndf', size = 8092KB, filegrowth = 1024KB) , filegroup [fg3] (name ='PTestFG3', filename = 'E:\data\partitionTestFG3.ndf', size = 8092KB, filegrowth = 1024KB) log on (name = 'PTest_Log', filename = 'E:\data\partitionTest_log.ldf', size = 2048KB, filegrowth = 1024KB); go alter database [PartitionTest] set recovery simple; go use partitionTest;
创建一个我们将折磨的桌子。
create table ptest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000));
并填写一年的数据:
;with nums as ( select 0 n union all select 1 union all select 2 union all select 3 union all select 4 union all select 5 union all select 6 union all select 7 union all select 8 union all select 9 ) insert into ptest(dt, dummy_int, dummy_char) select dateadd(hh, rn-1, '20180101') dt, rn dummy_int, 'dummy char column #' + cast(rn as varchar) from ( select row_number() over(order by (select (null))) rn from nums n1, nums n2, nums n3, nums n4 )t where rn < 8761
现在pTest表包含2018年每小时的一条记录。
现在,您需要创建一个分区函数,该函数描述将数据划分为多个部分的边界条件。 SQL Server仅支持范围分区。
我们将根据dt(日期时间)列对表进行分区,以便每个部分包含4个月的数据(实际上,我在这里搞砸了-实际上,第一部分将包含3的数据,第二部分包含4的数据,第三部分包含5个月的数据,但是出于演示目的-这不是问题)
create partition function pfTest (datetime) as range for values ('20180401', '20180801')
一切似乎都很正常,但是我在这里故意犯了一个“错误”。 如果查看
msdn中的语法,您将看到在创建过程中可以指定指定边框所属的部分-左侧或右侧。 默认情况下,由于某种未知的原因,指定的边框指的是“左侧”部分,因此对于我来说,创建分区函数如下是正确的:
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
当我实际执行时:
create partition function pfTest (datetime) as range left for values ('20180401', '20180801')
但是,我们稍后将返回到此并重新创建分区功能。 同时,我们继续进行所发生的事情,以了解所发生的事情以及为什么它对我们不是很好。
创建分区功能后,需要创建一个分区方案。 它清楚地将节绑定到文件组:
create partition scheme psTest as partition pfTest to ([FG1], [FG2], [FG3])
如您所见,我们的所有三个部分都位于不同的文件组中。 现在是时候对我们的表进行分区了。 为此,我们需要创建一个聚集索引,而不是指定应该位于其中的文件组,而是指定分区方案:
create clustered index cix_pTest_id on pTest(id) on psTest(dt)
在这里,我在当前方案中也犯了一个“错误”,我很可能在此列上创建了唯一的聚集索引,但是,当创建唯一索引时,用于分区的列应包括在索引中。 我想展示一下这种配置可以遇到的情况。
现在,让我们看看在当前配置中得到了什么(
请求从此处获取 ):
SELECT sc.name + N'.' + so.name as [Schema.Table], si.index_id as [Index ID], si.type_desc as [Structure], si.name as [Index], stat.row_count AS [Rows], stat.in_row_reserved_page_count * 8./1024./1024. as [In-Row GB], stat.lob_reserved_page_count * 8./1024./1024. as [LOB GB], p.partition_number AS [Partition

因此,我们得到了三个不太成功的部分-第一个部分从时间开始存储数据,直到04/01/2018 00:00:00,包括第二个-从01/01/2018 00:00:01到08/01/2018 00:00:00,包括从08/01/2018 00:00:01到世界末日的第三个(我故意错过了几分之一秒,因为我不记得SQL Server将这些分数写到哪个等级,但含义已正确传输)。
现在,在dummy_int字段上创建一个非聚集索引,根据相同的分区方案“对齐”。
为什么我们需要一个统一的索引?我们需要一个对齐的索引,以便我们可以执行切换部分(切换)的操作-这是其中的一项操作,而这些操作通常会困扰于分区。 如果表中至少有一个未对齐索引,则无法切换该部分
create nonclustered index nix_pTest_dummyINT on pTest(dummy_int) on psTest(dt);
让我们看看为什么我说过在实现分段后您的查询可能会变慢。 运行请求:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 SET STATISTICS TIME, IO OFF;
让我们看看执行统计信息:
Table 'ptest'. Scan count 3, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
以及实施计划:

由于索引是按节“对齐”的,因此有条件地,每个节都有自己的索引,该索引与其他节的索引“不相连”。 我们没有在分区索引的字段上强加条件,因此SQL Server被迫在每个部分中执行索引查找,实际上是3个索引查找而不是一个。
让我们尝试排除一个部分:
SET STATISTICS TIME, IO ON; select id from pTest where dummy_int = 54 and dt < '20180801' SET STATISTICS TIME, IO OFF;
让我们看看执行统计信息:
Table 'ptest'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
是的,排除了一个部分,仅在两个部分中进行了所需值的搜索。
在决定分区时,必须记住这一点。 如果查询中没有对表分区的字段进行限制,则可能有问题。
我们不再需要非聚集索引,因此我将其删除
drop index nix_pTest_dummyINT on pTest;
为什么需要非集群索引?总的来说,我不需要它,我可以使用集群索引显示相同的内容,我不知道为什么创建它,但是由于已经创建并制作了屏幕截图,所以请不要消失
现在考虑以下情况:我们每4个月从此表中存档一次数据-我们删除旧数据并为接下来的4个月添加一个部分(“滑动窗口”的组织在msdn和博客堆中都有描述)。
我们将任务分为可理解的小子任务:
- 添加一节以获取01/01/2019至04/01/2019的数据
- 创建一个空的舞台表
- 在阶段表中切换数据部分直到04/01/2018
- 摆脱空白部分
出发:
1.我们宣布将在FG1文件组中创建新部分,因为它将很快从我们手中释放出来:
alter partition scheme psTest next used [FG1];
并通过添加新边框来更改分区功能:
SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
我们看一下统计数据:
Table 'ptest'. Scan count 1, logical reads 76171, physical reads 0, read-ahead reads 753, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 7440, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
该表中有8809页(集群索引),因此,读数的数量当然是多有好处。 让我们在各节中看看现在有什么。

总的来说,一切都按预期进行-出现了一个具有上限的新部分(请记住我们的边界条件属于左侧部分)01/01/2019和一个空白部分,其中将有其他日期较长的数据。
一切似乎都很好,但是为什么会有这么多读数? 我们仔细查看上图,发现FG3中来自第三部分的数据以FG1结尾,但下一部分为FG3。
2.创建一个阶段表。
要将一个部分切换(切换)到一个表,反之亦然,我们需要一个空表,在其中创建所有与分区表相同的限制和索引。 该表应与我们要在其中“切换”的部分位于同一文件组中。 第一个(归档的)部分位于FG1中,因此我们在同一位置创建一个表和一个簇索引:
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id) on [FG1];
您无需对该表进行分区。
3.现在我们准备切换:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
这是我们得到的:
4947, 16, 1, 59 ALTER TABLE SWITCH statement failed. There is no identical index in source table 'PartitionTest.dbo.pTest' for the index 'cix_stageTest_id' in target table 'PartitionTest.dbo.stageTest' .
有趣的是,让我们看看索引中的内容:
select o.name tblName, i.name indexName, c.name columnName, ic.is_included_column from sys.indexes i join sys.objects o on i.object_id = o.object_id join sys.index_columns ic on ic.object_id = i.object_id and ic.index_id = i.index_id join sys.columns c on ic.column_id = c.column_id and o.object_id = c.object_id where o.name in ('pTest', 'stageTest')
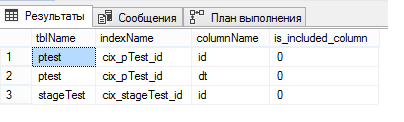
还记得我写过的,有必要在分区表上创建唯一的聚集索引吗? 这就是为什么有必要的原因。 当创建唯一的聚集索引时,SQL Server将要求显式地包括在索引中对表进行分区的列,因此他自己添加了该列,而忘记了。 我真的不明白为什么。
但是,总的来说,这个问题是可以理解的,我们在舞台表上重新创建集群索引。
create clustered index cix_stageTest_id on stageTest(id, dt) with (drop_existing = on) on [FG1];
现在,我们再次尝试切换该部分:
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
塔坝! 该部分已切换,请看它花了我们多少钱:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 3 ms.
但是什么都没有。 将节切换到空表,反之亦然(将整个表切换到空节)是仅对元数据的操作,这正是分区是非常非常酷的事情的原因。
让我们看一下我们的部分:

他们的一切都很好。 在第一部分中,剩下的记录为零,它们安全地保留在stageTest表中。 我们可以继续前进
4.我们剩下的就是删除我们空白的第一部分。 让我们来看看会发生什么:
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
在我们的例子中,这也是仅对元数据的操作。 我们查看以下部分:

到目前为止,我们只有3个部分,每个部分都在自己的文件组中。 任务完成。 这里有什么可以改进的? 好吧,首先,我希望边界值引用“正确的”部分,以便这些部分包含4个月的所有数据。 而且我希望看到创建新部分的成本更低。 读取数据的次数是表本身的十倍-破产。
我们现在无法对第一个进行任何操作,但是对于第二个我们将尝试。 让我们创建一个新部分,其中将包含从01/01/2019到04/01/2019的数据,并且直到时间结束:
alter partition scheme psTest next used [FG2]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190401'); SET STATISTICS TIME, IO OFF;
我们看到:
SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
哈! 因此,此操作仅针对元数据吗? 是的,如果您“划分”空白部分-这仅是对元数据的操作,因此,保留左侧和右侧保证的空白部分都是正确的决定,并在必要时选择一个新部分-从此处“剪切”它们。
现在让我们看看如果我想将数据从阶段表返回到分区表会发生什么。 为此,我需要:
- 在左侧创建一个新部分以获取数据
- 将表格切换到此部分
我们尝试(并记住FG1中的stageTest):
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20180401'); SET STATISTICS TIME, IO OFF;
我们看到:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 2939, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
好吧,还不错。 仅阅读左侧部分(我们将其划分)即可。 好吧 要将非分区的非空表切换到分区表部分,源表必须具有限制,以便SQL Server知道一切都会好起来,并且可以通过对元数据的操作来进行切换(而不是读取行中的所有内容并检查该部分是否符合条件) ):
alter table stageTest add constraint check_dt check (dt <= '20180401')
尝试切换:
SET STATISTICS TIME, IO ON; alter table stageTest switch to pTest partition 1 SET STATISTICS TIME, IO OFF;
统计资料:
SQL Server Execution Times: CPU time = 15 ms, elapsed time = 39 ms.
同样,该操作仅针对元数据。 我们看一下各节的内容:

好吧 似乎已经整理好了。 现在,我们将尝试重新创建函数和分区方案(我删除了分区方案和函数,使用新的分区方案重新创建并重新填充了表,并重新创建了群集索引):
create partition function pfTest (datetime) as range right for values ('20180401', '20180801')
让我们看看我们现在有哪些部分:

好了,现在我们有三个“逻辑”部分-从时间开始到04/01/2018 00:00:00(不包括),从04/01/2018 00:00:00(包括)到08/01/2018 00:00:00( (不包括)和第三项,即大于或等于01/01/2018 00:00:00的所有内容。
现在,让我们尝试执行与使用上一个分区功能执行的数据存档任务相同的任务。
1.添加一个新部分:
alter partition scheme psTest next used [FG1]; SET STATISTICS TIME, IO ON; alter partition function pfTest() split range ('20190101'); SET STATISTICS TIME, IO OFF;
我们看一下统计数据:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'ptest'. Scan count 1, logical reads 3685, physical reads 0, read-ahead reads 4, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 1, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
不错,至少是合理的-仅阅读最后一部分。 我们在以下各节中介绍一下:

请注意,现在,完整的第三节保留在FG3中,而新的空白部分已在FG1中创建。
2.我们创建一个阶段表并在其上创建正确的集群索引
create table stageTest (id int identity(1,1), dt datetime, dummy_int int, dummy_char char(6000)) ; create clustered index cix_stageTest_id on stageTest(id, dt) on [FG1];
3.开关部分
SET STATISTICS TIME, IO ON; alter table pTest switch partition 1 to stageTest SET STATISTICS TIME, IO OFF;
统计数据表明,元数据操作为:
SQL Server Execution Times: CPU time = 0 ms, elapsed time = 5 ms.
现在,一切都没有惊喜。
4.删除不必要的部分
SET STATISTICS TIME, IO ON; alter partition function pfTest() merge range ('20180401'); SET STATISTICS TIME, IO OFF;
在这里,我们有一个惊喜:
Table 'ptest'. Scan count 1, logical reads 27057, physical reads 0, read-ahead reads 251, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0.
我们看一下各节的内容:

这很清楚:我们的第2节从fg2文件组移到了fg1文件组。 类。 我们可以做些什么吗?
也许我们只需要始终有一个空白部分,并“销毁”“永远空白”的左部分和我们“切换”到另一个表的部分之间的边界。
结论:- 使用完整的语法创建分区功能,不要依赖默认值-您可能无法获得所需的内容。
- 将左右保持在空白区域-在组织“滑动窗口”时它们将对您非常有用。
- 拆分并合并非空部分-总是很麻烦,请尽可能避免这种情况。
- 检查您的查询-如果它们不按计划对表进行分区的列使用筛选器,并且您需要切换部分的能力-它们的性能可能会大大降低。
- 如果您想做某事,请先进行生产测试。
希望该材料对您有所帮助。 也许事实证明它是弄皱的,如果您认为所声明的内容未公开,请写,我将尽力完成它。 谢谢您的关注。