大家好 在机器学习课程开始之前,还有一个多星期的时间。 鉴于课程开始,我们准备了有用的翻译,我们的学生和所有博客读者都将对此感兴趣。 让我们开始吧。

现在是时候摆脱黑匣子,树立对机器学习的信心了!Christoph Molnar在他的著作
《可解释的机器学习》中使用以下示例完美地突出了机器学习的解释:假设您是一名数据科学专家,并在您的业余时间根据来自Facebook和推特。 因此,如果预测正确,那么您的朋友会认为您是可以看到未来的向导。 如果预测错误,那么除了您作为分析师的声誉以外,它不会对您造成任何损害。 现在想象一下,这不仅是一个有趣的项目,而且吸引了投资。 假设您想投资于您的朋友可能放松的房地产。 如果模型预测失败,会发生什么? 你会赔钱的。 只要该模型没有重大影响,它的可解释性就没有多大关系,但是当模型的预测与财务或社会后果相关时,其可解释性就具有完全不同的含义。
解释机器学习
解释是用可以理解的术语进行解释或显示。 在ML系统的上下文中,可解释性是解释其行为或以
人类可读形式显示它的能力。
许多人将机器学习模型称为“黑匣子”。 这意味着尽管我们可以从它们那里得到准确的预测,但我们不能清楚地解释或理解它们的编译逻辑。 但是如何从模型中提取见解? 应该记住什么事情,我们需要什么工具来做到这一点? 这些是有关模型可解释性的重要问题。
可解释性的重要性
有人问的问题是,
为什么不仅仅为我们能从模型工作中得到具体结果而感到高兴,为什么知道如何做出决定如此重要? 答案在于,该模型可能会对现实世界中的后续事件产生一定的影响。 对于设计用于推荐影片的模型而言,与用于预测药物作用的模型相比,可解释性将不那么重要。
“问题在于,只有一个度量标准(如分类准确性)不足以描述大多数现实世界中的任务。” (
Doshi Veles和Kim 2017 )
这是有关可解释的机器学习的全景。 从某种意义上说,我们捕获了世界(或者更确切地说,是来自世界的信息),收集了原始数据并将其用于进一步的预测。 本质上,可解释性只是模型的另一层,可帮助人们理解整个过程。
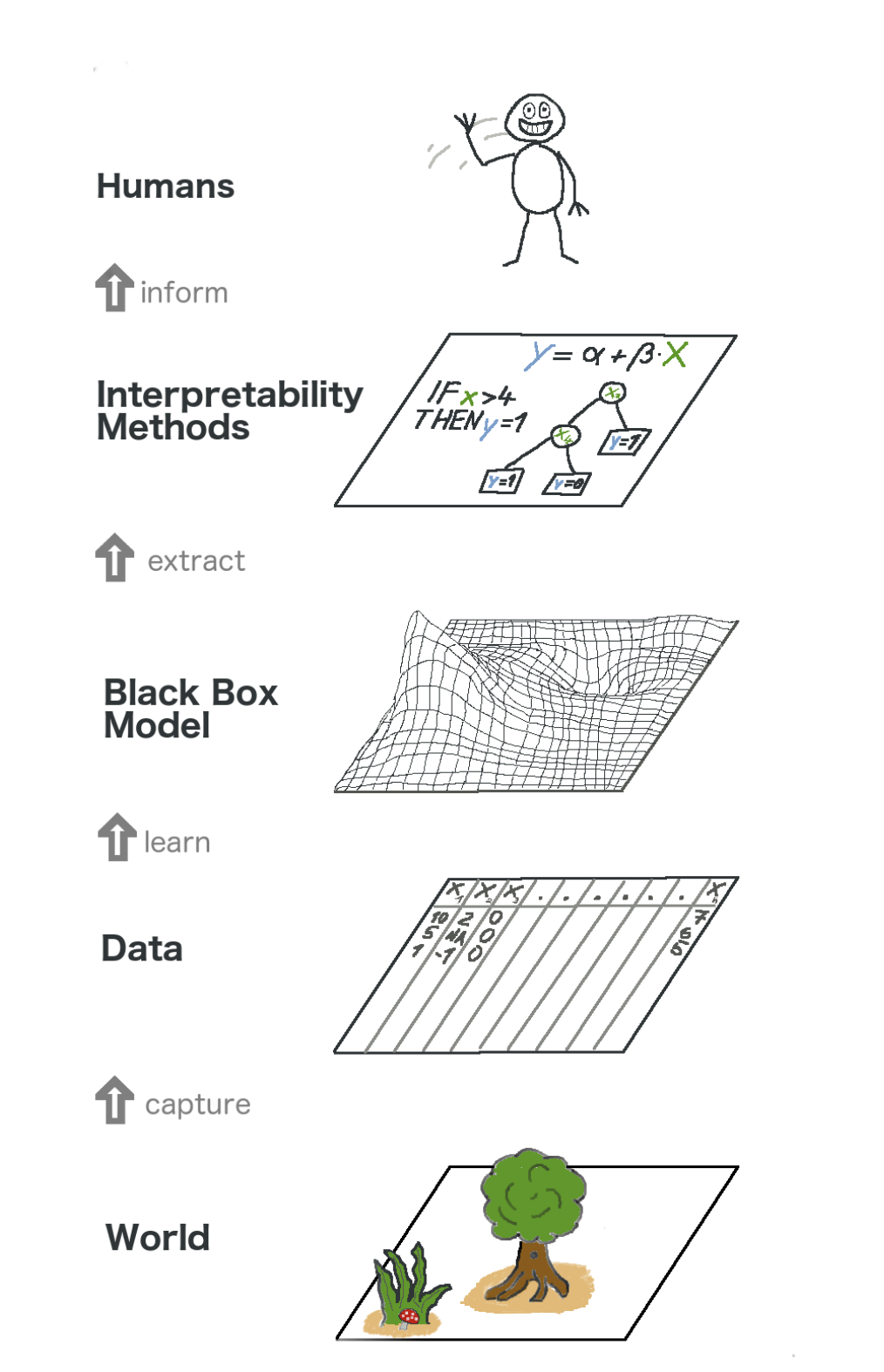 图像中从下到上的文本:世界->获取信息->数据->训练->黑匣子模型->提取->解释方法->人
图像中从下到上的文本:世界->获取信息->数据->训练->黑匣子模型->提取->解释方法->人可解释性带来的一些
好处是:
- 可靠度
- 调试方便;
- 工程特征信息;
- 管理特征数据收集
- 决策信息;
- 建立信任。
模型解释方法
一个理论只有在我们可以付诸实践的情况下才有意义。 如果您确实要处理此主题,则可以尝试从Kaggle上机器学习说明课程。 在其中,您将找到理论和代码之间的正确关联,以便理解概念并能够将模型的可解释性(可解释性)概念付诸实践。
单击下面的屏幕截图,直接进入课程页面。 如果您想首先获得该主题的概述,请继续阅读。
可以从模型中提取的见解
要了解该模型,我们需要以下洞察力:
- 模型中最重要的功能;
- 对于模型的任何特定预测,每个单独属性对特定预测的影响。
- 每个功能对大量可能的预测的影响。
让我们讨论一些有助于从模型中提取上述见解的方法:
排列重要性
该模型认为哪些功能很重要? 哪些症状影响最大? 这个概念称为特征重要性,而置换重要性是一种广泛用于计算特征重要性的方法。 它可以帮助我们查看模型在什么时候产生了意外的结果,还可以帮助我们向其他人表明我们的模型完全可以正常工作。
排列重要性适用于许多scikit学习评估。 这个想法很简单:在验证数据集中任意重新排列或随机排列一列,而保留所有其他列不变。 如果模型的准确性下降并且其变化导致误差增加,则认为符号“重要”。 另一方面,如果将特征的值改组不影响模型的准确性,则认为该特征“不重要”。
如何运作?
考虑一个模型,该模型根据某些参数来预测足球队是否将获得“游戏人”奖。 该奖项颁发给表现出最佳游戏技能的玩家。
训练模型后计算置换重要性。 因此,让我们在训练数据上训练并准备
RandomForestClassifier模型。
使用
ELI5库计算置换重要性。 ELI5是Python中的一个库,可让您使用统一的API可视化和调试各种机器学习模型。 它具有对多个ML框架的内置支持,并提供了解释黑盒模型的方法。
使用ELI5库计算和显示重要性:
(此处
val_X ,
val_y分别表示验证集)
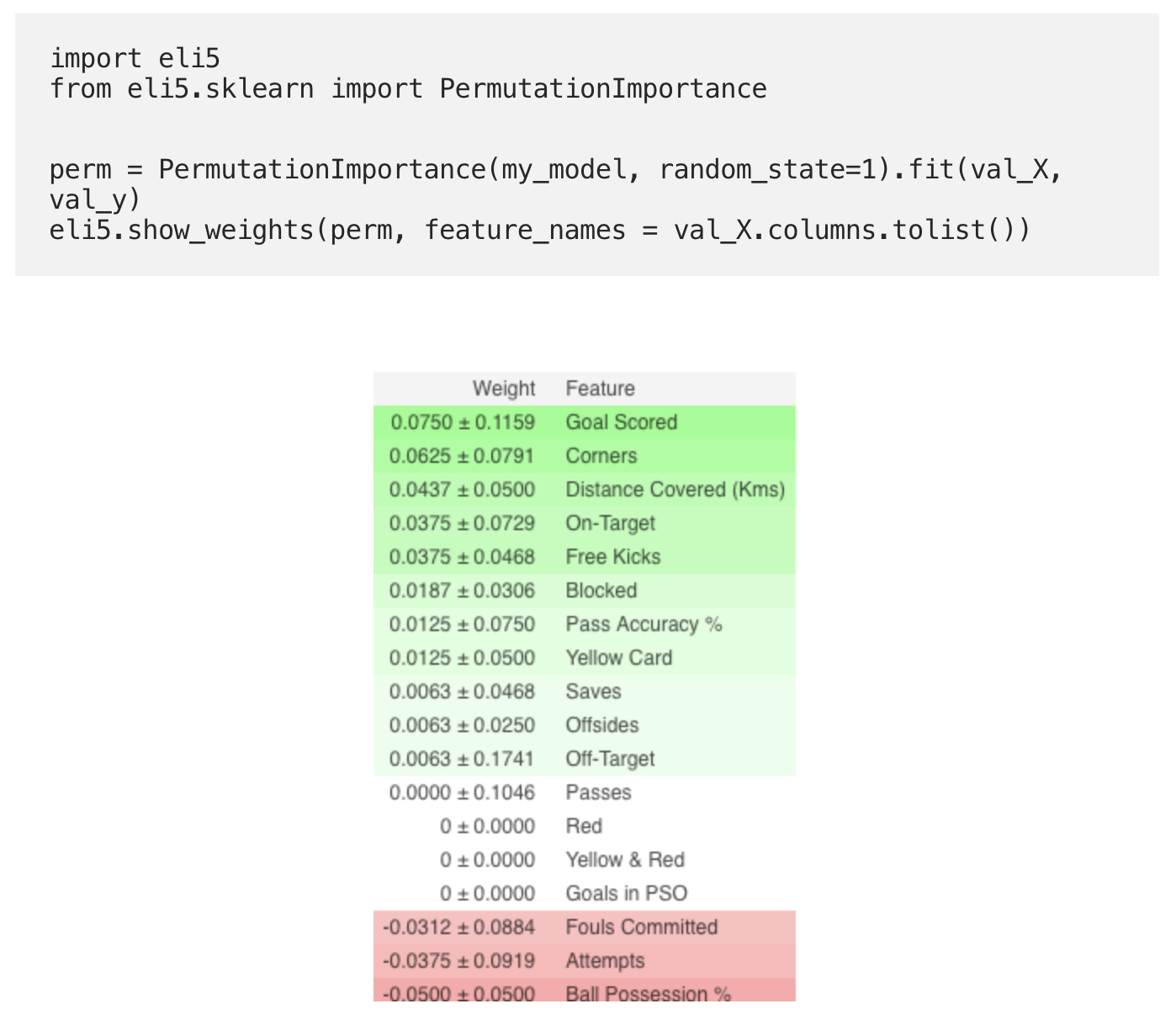
口译
- 上面的标志最重要,下面的标志最少。 对于此示例,最重要的标志是进球。
- ±后面的数字反映了生产率是如何从一个排列更改为另一个排列的。
- 一些权重为负。 这是由于这样的事实,在这些情况下,经过改组的数据的预测结果比实际数据更准确。
练习
现在,要查看完整的示例并检查您是否正确理解了所有内容,请使用
链接转到Kaggle页面。
这样翻译的第一部分就结束了。 写您的评论并参加课程!
阅读第二部分 。