AntipovSN和MihhaCF
第二部分,Athos拥有所有规则,但是Count de la Fer遗失了一些东西
UPD第一部分在这里
UPD第三部分
作者简介:
下午好 今天,我们继续讨论有关评分和在其中使用图论的系列文章。 您可以在这里熟悉第一篇文章。
所有漫画寓言,插入内容等都旨在略微减轻叙事的影响,并且不允许其陷入乏味的演讲中。 我们向所有不喜欢我们幽默的人致歉
本文的目的:在不超过30分钟的时间内,描述存储图形数据的主要方式,并描述构建我们的借款人评分模型的规则和原则。
术语和定义:
- 哈希表是一种实现关联数组接口的数据结构;它允许您存储对(键,值)并执行三个操作:添加新对的操作,搜索操作和通过键删除对的操作。 平均而言,按哈希表进行搜索的时间为O(1)。
由Korol PJSC聘请的审核员评估“全民所有制”的信誉度遇到了一些问题。 一方面,描述10-15家公司的交互方案并进行公司间交互的初步评估非常简单,手头上有一张纸和一支笔就足够了。 但是,如果您掌握了数以万计的公司之间的互动信息,该怎么办? 例如,如果您需要描述Aramis与他所有激情的互动,或者描述D'artagnan与他与之作战的每个人的互动?
如何存储有关这些交互的数据?
使用什么数据结构和方法?
审计师将不得不为这项工作安排整个修道院僧侣。
我们不会这样做,而是会向审计师提供未来的知识和技术( 我们将以T-800的形式将Prometheus发送给他们,这将为他们提供知识的光芒 )。
好吧,让我们开始回答提出的问题。 让它发光!
正如我们在此处编写和绘制的,图形是2套的比率-一组节点和一组边。 存储图形的最佳方法是什么?
在回答如何存储图形的问题之前,您需要确定我们要存储什么以及以什么形式存储。
根据图论,图节点可以是具有任何参数集的任何对象(这一事实将在以后对我们有用,对于用于计算得分球的高级/自适应模型)。
那么我们需要存储什么?
至少,该节点的标识符及其邻居(与之关联的邻居)的标识符。 这些数据的存在已经使您可以搜索宽度和深度。
我需要存储图形边缘数据吗? 是的,如果我们正在处理加权图。 在我们的案例中,我们正在处理一个加权图,在第一篇文章中,我们绘制了这样一个图。
这些信息够吗? 不行
肋骨从哪里来? 在教科书中,这些信息就在那儿,有人在我们之前收集并处理了这些信息。 在我们的中世纪晚期(那时火枪手还活着),没有人费心计算计数的边缘的权重。 我们必须自己做。 在本文和下一篇文章中,我们将不介绍计算边缘权重的具体方法;这将在第4条中完成。 现在,对于我们而言,决定要存储的图形信息非常重要。
因此,在我们的案例中,我们需要了解三个关键参数才能正确计算得分:
- 节点的内部评估-包括表征节点的指标(周转率,债务,罚款等)。 在我们的示例中,这些将是:
- 评估-与NPO“一个人人都享有”有关的好坏;
- 节点等级-国王等级最高,博纳基厄斯-最低等级;
- 资金量,换句话说,就是生存能力。
- 肋骨的评估。 在我们的示例中,连接评估将针对每个节点-这意味着Bonacieux-Constance关系可能不等于Constance-Bonacieux连接,因为 他们有互相影响的不同可能性。
- 节点级别-将不会存储,但是是一个重要的指标。
D'artanyan认为,不要问这些数字在哪里都来自模型。 在现实生活中,这些指标也不会由我们来计算(贸易,债务,罚款等,我们从现有资源中获取,我们不在中世纪之类)。
从以上所有结果可以看出,除了节点的标识符之外,我们还必须存储每个节点的参数以及基于节点参数的集合获得的边缘权重。
总计,以下信息可能会存储:
太好了! 我们弄清楚需要存储什么。 现在-如何存储。
再有一个小题外话。
评分过程将以简化形式显示:
- 对象数据收集;
- 将描述图形模型的对象的形成。 我们将在此设施进行所有计分操作。
基于这两个步骤,我们有三个选择:
- 我们将有关评分对象的数据存储在SQL / NoSQL服务器上。 与计算,算法等有关的所有操作都直接在服务器上执行;
- 我们将有关评分对象的数据存储在SQL / NoSQL服务器上。 根据这些数据,我们创建一个单独的对象(例如,哈希表),通过该对象我们可以执行所有基本计算;
- 有关计分对象的数据存储在RAM中。 基于此数据,我们创建一个单独的对象(例如,哈希表),并使用该对象执行所有基本计算。
此过程的基本要求:
- 工作速度;
- 可靠度
- 可验证性。
现在让我们谈谈。 我们将像火枪手一样坐下来,坐在他们喝的茶中,例如茶。 最主要的是,我们不会与后卫干涉各种雄鸽。
如果需要长期存储,则可以选择带有相应有效字段的表。 在NoSQL或RAM中,最好以对象列表或目录(哈希表)的形式存储数据。
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000 }
随着山峰或多或少清晰。 代表图形的弧/边的最佳方法是什么? 为此,您需要了解图形上任何分析操作的基本原理-对任何弧/边的访问应非常快地发生,最好访问时间应为O(1)。 立即想到数组或矩阵-一种可以通过索引快速访问任何元素的结构。
[i,j]-矩阵元素表示图的弧线,其中i是初始顶点的标识符,j是最终顶点的标识符,对初始顶点的访问和选择直接由初始顶点的标识符进行。 i和j的交集存储边的权重。
此视图有几个缺点:
- 通常,结构是多余的,特别是在图形稀疏(少量边)的情况下,有许多空值指示没有连接。
- 为了找到顶点的所有邻居,有必要对关系矩阵第i行的所有元素的数组进行排序。
- 具有许多列的矩阵无法存储在数据库中。
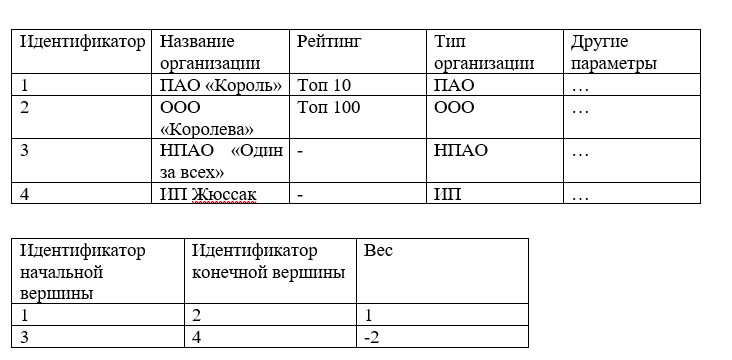
存储弧/边的下一个选项是表格,即一组列和行。
例如:

这样的结构可以很容易地存储在关系数据库中,并在执行SQL查询时选择必要的值,但是当涉及RAM时,查找顶点所有边的复杂性会增加,通常情况下需要O(n),其中n是图的所有边数。
几乎没有所有缺点,还有几乎所有系统都可以使用的另一种非常好的图形存储方法-这是键值引用或哈希表。 以O(1)速度获得所需顶点的所有边缘。
一个重要的缺点是,并非所有的编程语言都支持该设计。
在不同的系统中,如何想象一个类似的结构?
在关系数据库中,您可以实现对象表和边表的关系(上一段)
NoSQL
{ 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
通过对象的键访问对象时,我们立即获得了一组连接。 如果我们有一个非加权图,而不是对象数组,则可以传递邻居关系标识符的数组。[3,4,... n]。 以引用的形式,键是值,此选项类似于上一个。 在目录中,键-值可以存储与上一个示例相同的对象,键当然是顶点的标识符(可能有数字,可能有字符串等,这允许使用特定的开发系统)。 同样,在目录中,您只能将链接数组以及有关顶点的信息存储在另一个目录中。
Graf[1] = { 'Id': 1, 'Title': ' ', 'Rang': 4, 'Type': '', 'Profit': 10000, 'Relations': [{3,2}, {4,5}, … {n, -5}] }
或
graf['one_for_all'] = 'Relations': [{3,2}, {4,5}, … {n, -5}]
对于我们的示例,我们选择了将数据存储在RAM中的选项,并创建了一个用于对数据进行评分的哈希表。 中间结果将被写入服务器上的文件。
我们的存储结构定义不尽人意,现在是时候找出从哪里开始构建我们的分析模型了。 让我们从一个简单的例子开始-我们定义与最近的邻居以及邻居的邻居(朋友的朋友)的交互。
因此,可以确定与所有互连顶点的交互。 根据我们的观察,仅在特殊情况下才与比2级更深的邻居交互,并且通过其他方法进行计算。 此计算的复杂度非常大0(2 ^ n)。
为了计算球,我们将使用略微修改的深度搜索算法。
细化如下:
- 对于我们的问题n = 2,我们不需要找到一个特定的顶点,而是将所有顶点排序到n的深度。
- 我们不应存储不必要的信息,而应假定可以对图中的任何节点进行计算,因此该节点的级别将不会存储在图中。
- 如果有2条或更多条路径通向顶部,则将评估所有路径,因为 我们正在处理双向通信,因此有必要全面评估节点的交互。
- 您需要能够确定特定计算的任何顶点的嵌套级别。
好吧,好吧,即使对某些人来说似乎简单而过时,也已经进行了基本的理论计算。 但是对于我们加斯康来说,这一切都是重要且有趣的,几乎与进入皇家火枪手相同。
我们通过实际实施。 一劳永逸,一劳永逸!
我会见你! 我们一定会见面的! 也许10年或20年! 但是见面!
下一篇文章即将结束!