
在上
一篇文章中,我简要介绍了DublGIS内部和外部产品的开发历史。 今天,我们深入探讨其中一种产品的开发细节,即数据导出。 我将讨论项目的体系结构和各个技术解决方案,这些技术使我们能够逐步开发项目并使之适应不断变化的需求。
上一篇文章的简要摘要
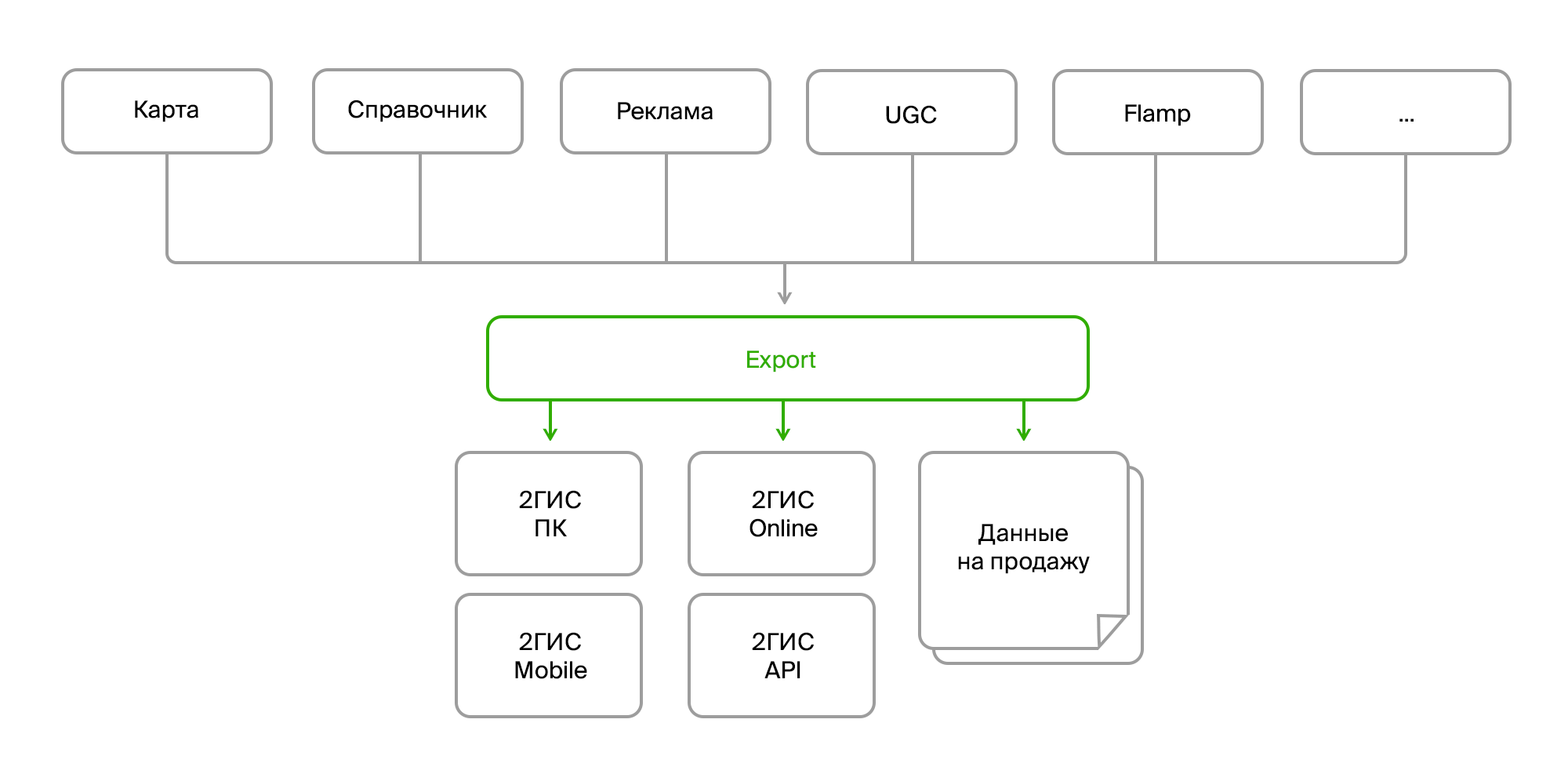
有几种内部产品可收集大量地图数据,组织目录,广告,用户反馈,评论,照片以及各种分析。 这些产品通过数据总线或Rest Api相互通信。 并且有一个单独的导出过程,将所有这些数据收集到一个堆中,以所需的格式进行处理和分解,打包并形成一个现成的“捆绑包”,以交付给最终产品。 交付既可以通过PC和移动版本的更新服务器进行,也可以通过在线后端(实际上是2GIS的在线版本)进行。
源数据
因此,在入口处,我们有:
- 相同数据的多个来源;
- 不同的交付方式(Firebird,总线,FTP,RestAPI);
- 同一对象的结构不同;
- 数据结构不断变化;
- 不同的格式(数据库中的原始数据,XML,JSON)。
从消费者的角度来看:
- 再次,不同的格式(它们用于不同版本产品的数据格式,用于销售的单独格式);
- 格式不断变化;
- 汇总数据(您需要将不同的对象组合为一个对象,从所有分支机构收集有关公司的数据,并通过指向照片,评论,最近的站点等的链接对其进行补充);
- 复杂的预处理和后处理(在其他数据的基础上更新某些数据,转换数据,生成丢失的数据,例如,在建筑物上放置微型徽标,删除或纠正错误的数据);
- 数据一致性和有效性要求;
- 需要所有数据。
在这里值得关注最后一段。 如您所知,2GIS的主要功能是脱机工作。 也就是说,您在PC版和移动版中看到的大多数数据都位于设备上。 但这是一个庞大的数组:数十万个地理对象(海洋,森林,河流,道路,建筑物,入口,门廊,签名,平面图,3D模型),成千上万的公司及其分支机构以及联系人,工作时间,其他属性例如平均费用和Wi-Fi可用性。 并且,当然,广告文字和图片。
一切都在不断变化,添加,删除。
为了避免淹没在这无休止的变化中,在开发出口体系结构时,我们必须专注于几个主要领域:
我们从不同的来源和数据格式中提取
不同来源带来以下困难:
- 它们以不同的格式给出相同的数据;
- 具有一组不同的实体或属性,需要将它们简化为单个域对象。
这是一个相当标准的问题,已作为标准解决。 我们只需要创建一个用于接收数据的接口,并且已经在需要的地方实现了特定的实现,并且将以我们需要的形式获取数据。

接口示例:
public interface ISource : IDisposable { ISourceReader GetDeletedRows(); ISourceReader GetInsertedOrUpdatedRows(); byte[] GetDataVersion(); } public interface ISourceReader : IDisposable { bool Read(); object this[string columnName] { get; } }
实现获取公司的示例:
internal class FirmSetSource : ISource { public ISourceReader GetDeletedRows() { if(_lastDataVersion == null) return null; var query = DataContext.ExecuteObject<EsbFirmDeleted>(_lastDataVersion); return new DeletedIdsSourceReader<long>( query.Select(x => x.Id).GetEnumerator()); } public ISourceReader GetInsertedOrUpdatedRows() { return new EnumeratorSourceReader(typeof(FirmSet), GetNewOrChangedRows().GetEnumerator()); } public virtual byte[] GetDataVersion() { return DataContext.ExecuteObject<EsbFirm>().Max(x => x.RowVersion); } }
这种抽象部分地使我们能够解决领域模型存在差异的问题,但不能完全解决。 一个重要的限制是需要增量接收数据,即仅接收其更新,而不是每次都吸收全部内容。 在这种情况下,跟踪数据之间的关系以收集一些汇总非常不便。 而且,要想一无所有,就很难做到每一件事。 因此,我们决定在这一阶段将一对一地从源中提取数据,并且将在不同级别上解决域模型的问题。
领域模型
为了不依赖数据集及其数据源结构的更改,导出数据库的表列表相对稳定,最终归我们所有。 如果源1缺少实体A的某些属性(下图中的数据对象),则它们要么接收默认值,要么是可选的。 而且,如果实体B是某种形式的源数据的集合,甚至是不同源的集合,则可以分别获取每个部分,然后在下一阶段将其整体组装。

我们从数据传递方法中抽象出来
实际上,在导出中拥有自己的数据库以及
ISourceReader接口的外观已经解决了此问题。 但是有一个未解决的问题:数据采集模型略有不同。 在一种情况下,我们在当前时刻提取快照并获取快照,在另一种情况下-在总线上变化的增量变化,在第三种情况下-也是请求时的当前状态,但包含有关上一个请求时刻已删除对象的信息。
为了使该动物园具有统一性,我们将再添加一个数据库,我们将合并所有来源的所有数据。
你得到这样的照片。
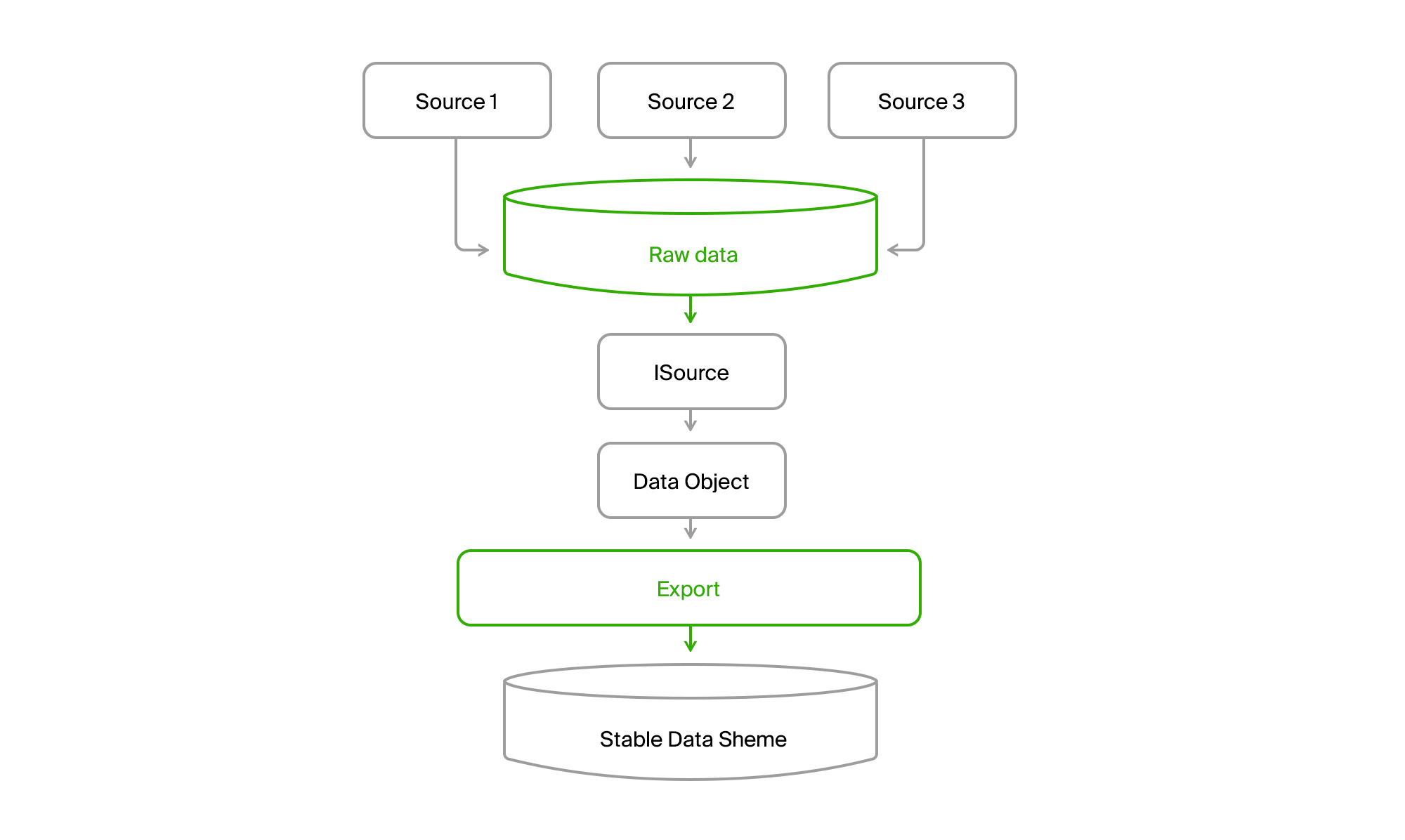
结果,我们从所有城市中任何渠道的所有数据读取到中央数据库。 交付几乎总是增量的,也就是说,只有变化来了。 旧的DGPP仍然存在,但仍然是替代来源。 能够将数据从一个DBMS泵送到另一个DBMS的情况并非如此。
此外,通过ISource进行的导出将来自DGPP或EMDB的城市数据提取到其稳定的同步数据库中,并将其转换为其域模型。
然后剩下的只是处理它们并以消费者格式上载它们。
从数据准备算法中提取
在这里又出现了另一个困难。 首先,不同的消费者想要其格式的数据。 而且,他们想要不同的数据集。 在附件中,离线数据应尽可能紧凑和结构化,以便可以快速读取它们。 结果,我们得到了由最终产品团队开发的二进制格式。 这些人在完全不同的技术堆栈上工作。 我们对开发.NET后端(有时是Java)非常熟悉和钟爱,他们主要使用C ++和python。
一般来说,是一个技术动物园。
在快速发展的曙光中,当我们只有DGPP(请参阅上
一篇文章 )和PC版本的2GIS时,最终数据的格式是二进制,由使用C ++编写的特殊库编写并包装在COM对象中。 似乎不是异构代码的集成。 我们连接引用,生成.NET接口,并将其驱动。 这是我们第一次这样做。
但是,像往常一样,出现了一些问题。
- 我们的数据开始迅速增长。 出现了新的数据类型,如莫斯科这样的新大城市。
- X64位操作系统开始积极传播。
- COM中的问题需要以某种方式进行调试。
让我们仔细分析这些要点。
我们产品完全需要的数据增长导致了这样的事实,即它们的处理开始消耗大量的RAM。 将COM库连接到我们的.NET进程x86后,我们会自动接收x86进程,即,最多3Gb的操作员具有增加的地址空间。 团队没有对x64资源的库支持,但是库本身具有使用磁盘而不是内存的能力,这在某种程度上缓解了该问题。
但是调试仍然非常困难。 必须开始导出,等待它准备数据,然后开始将这些数据添加到库中。 在出现错误之后,您需要从日志中了解出了什么问题,然后再次重复该过程。 不好,很糟糕。
溶液通常在表面上。 将所有外来代码带入一个单独的进程,并以简单的二进制或文本格式通过中间文件建立通信就足够了。
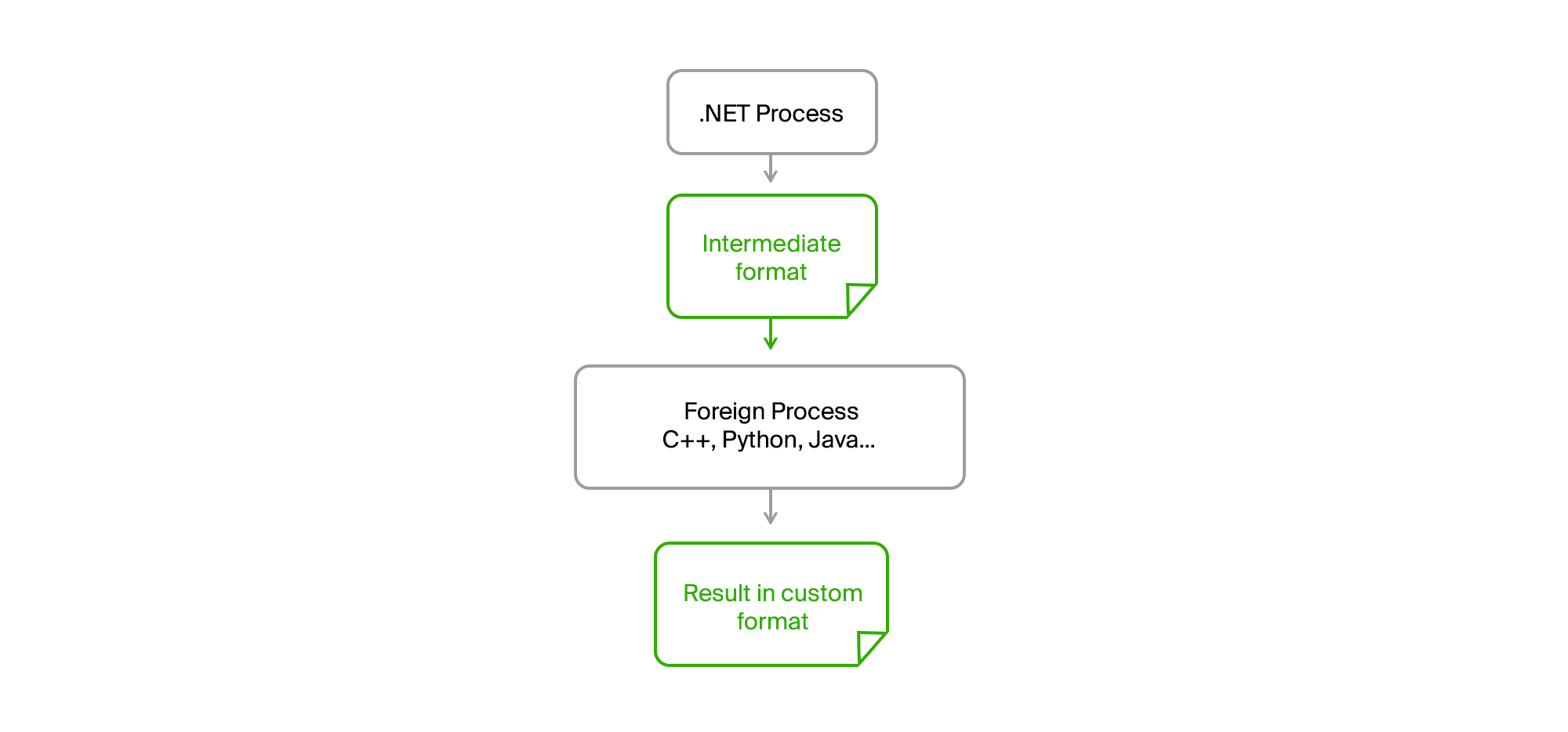
结果,我们原始的.NET进程完全变成了任何CPU。 没有内存泄漏或第三方代码中的严重错误不再影响它。 导出准备了数据,将其上传到中间文件,将其馈送到实用程序,并以文件的形式从中接收结果。 第三方团队的人用他们的语言(C ++或Python)编写算法,并且可以在实际数据上调试它们,以防机器上出现错误而无需开始导出。
我们只需要在运行时提供的实用程序接口上达成协议,就所需的参数达成一致的清单,并以所需的格式在标准输出中显示参考消息和错误。
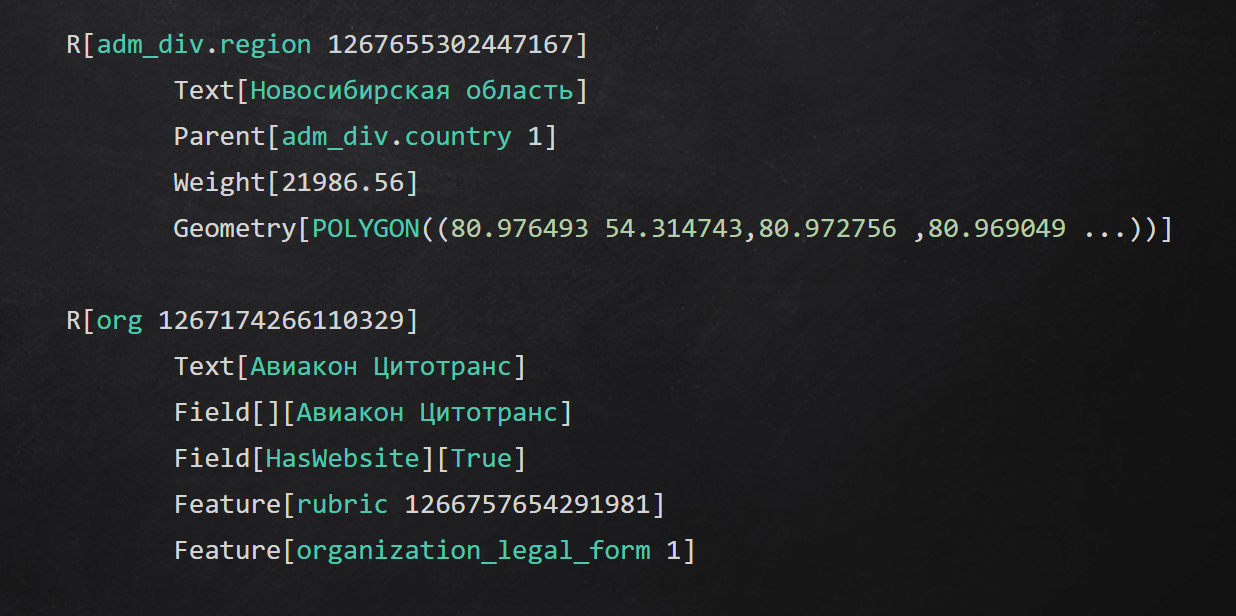 中间文本格式示例
中间文本格式示例总结
在本文中,我讨论了在应用程序的不同级别上用于隔离数据准备过程的一些方法:
- 隐藏在接口后面访问数据源的详细信息;
- 使用中间存储从数据传递渠道中提取摘要;
- 使您的稳定域,并将原始数据转换为它;
- 将数据处理的各个阶段执行到流程中,并使用其他语言使用代码。
感谢您的结束。 我会回答评论中的所有问题,一定要问。