本文介绍了使用上下文无关语法和LR分析算法解析俄语句子的过程。
自然语言处理是人工智能和数学语言学的总体方向。 它研究计算机分析和自然语言合成的问题。
通常,分析自然语言句子的过程如下:(1)将句子分为句法单位-单词和短语; (2)确定每个单元的语法参数; (3)单元间句法关系的定义。 输出是一个抽象的解析树。
1.将句子分成句法单元
自然语言的句子由单词形式和强词组组成。 给定单词的许多单词形式称为范例。
举个例子
"": [, , , , , ]
短语-复合连接词,谓词或稳定表达式-不会改变,也不能分解成较小的单元而不会失去意义。 此外,单词是指任何语法单位-单词形式或短语。
句子中的每个单词都由三元组确定:
- 字形/字串(“写”)
- 单词的正常形式(“写”)
- 一组语法参数(['VERB','sing','musc','tran','past'])
因此,“
显然,他不会参加会议 ”这句话的细分将具有以下形式:
[' ', '', '', '', '', ''] ' ' - ,
2.语法参数(语法)的定义
语法是语法类别的元素; 同一类别的不同克是互斥的,不能一起表达。 对于每种单词形式,我们定义一组七个语法:
[ , , , , , , ]
作为来源,我们将使用
OpenCorpora字典及其接口
pymorphy2 。 要在语法中搜索给定的一组克规则,我们将以一般形式将其呈现:
'' [NOUN,plur,neut,accs] -> [NOUN,?numb,?per,?gend,accs,None,None] '?' ,
3.词间句法关系的定义
为了确定单词之间的句法关系,我们将使用上下文无关的语法和LR分析。
语法和LR分析
形式语法是一种以所谓的产物形式描述语言的方式。 例如:
a -> ab | ac
表示规则“ a”产生“ ab”或“ ac”。
非终结符是表示语言本质的所有对象(句子,公式等)。
终端 -直接用与语法相对应的语言表示的对象,具有特定的,不变的含义(字母,单词,公式等)。 与上下文无关的语法是所有产品的左侧都是单个非终结符的语法。
为了描述俄语,我们将使用成分语法理论(
短语结构语法 ),该理论声称任何复杂的语法单元都由两个更简单且不相交的单元组成,称为直接成分。 区分以下组件:
(1)标称组(NP) NP[case='nomn'] -> N[case='nomn'] | ADJ[case='nomn'] NP[case='nomn'] | …
即,名词性名词短语是名词性格中的名词或名词性格中的形容词+名词性名词短语或另一个。
(2)口头小组(VP) VP[tran] -> V[tran] NP[case='ablt'] | ADJ VP[tran] | …
换句话说,及物动词组是及物动词+烧蚀名词组或简短的形容词+及物动词组或另一个。
(3)介词组(PP) PP -> PREP NP[case='datv'] | ...
介词组是介词+名词性组或另一个。
(4)全部报价(S) S -> NP[case='nomn'] VP[tran]
当且仅当名词和动词组在数量,人物和性别上匹配时,完整句子才存在。
def agreement(self, node_left, node_right): ... if (numb1 and numb2): if (numb1 != numb2): return False; if (per1 and per2): if (per1 != per2): return False; if (gend1 and gend2): if (gend1 != gend2): return False; return True;
不完整的句子是省略了标称部分的句子。 通常,在此类句子中,动词组由非人称动词表达。 例如,“
我想走路 ”,“它
越来越亮” 。 椭圆句是省略了动词部分的句子,由短划线代替。 例如,“
后面的后面是一片森林。右边和左边是沼泽” 。
为了确定该句子是否属于语法语言,我们将使用LR分析算法。 该算法涉及从下至上(从叶到根)构建解析树。 该算法的关键要素是“转移卷积”方法(英文
shift-reduce ):
(1)我们读取输入行的字符,直到找到一个与任何规则右侧匹配的链,然后将找到的链放入堆栈中(转移);
(2)替换从语法(卷积)中的规则中找到的链。
如果所有的字符串链都已被包装,则该句子属于语法语言,并且至少存在一个解析树。
树为了表示句法联系,该句子使用二叉树,其中叶子是带有一组克的单词(终端),节点是规则(终端)。 词根是句子(非结尾)。
树节点的定义如下:
class Node: def __init__(self, word=None, tag=None, grammemes=None, leaf=False): self.word = word;
树木的构造始于叶子,叶子被分配了一系列单词或短语以及一组语法。
def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)
接下来,进行LR分析。 每个卷积对应于一个共同祖先下的两个节点或叶子的并集。 祖先节点被分配了一个与语法规则相对应的前置词尾标签,此外,祖先还接受了该组主要成员的语法,例如,在动词组V [tran] PRCL中(例如,
“愿意” ),符号将取自及物动词V [tran]。不是来自PRCL的粒子; 在名词组NP [case ='nomn'] NP [case ='gent'](例如
“孩子的父亲” )中,符号应取自名词中的名词。
重要的是要注意,卷积按既定顺序发生:
def reduce(self): self.reduce_ADJ() # self.reduce_NP() # self.reduce_PP() # self.reduce_VP() # self.reduce_S() #
此顺序很重要,因为它排除了“错过”提案中某些成员的可能性。 首先,形容词与修饰语(例如,
疯狂的美丽 )一起形成,然后是名词性的组,介词的,最后是言语的。 之后,将搜索完整/不完整的句子,如果没有,则树没有根,这意味着该句子不属于语法语言。
考虑构建树的条件示例:
sent = " " def build(self, sent): for word in sent: new_node = Node(word[0], word[1], word[2], leaf=True) self.nodes.append(new_node)

NP[case='nomn'] -> NPRO[case='nomn'] NP[case='accs'] -> N[case='accs'] NP[case='datv'] -> ADJ[case='datv'] NP[case='datv']

VP[tran] -> V[tran] NP[case='accs']

VP[tran] -> VP[tran] NP[case='datv']

S -> NP[case='nomn'] VP[tran]
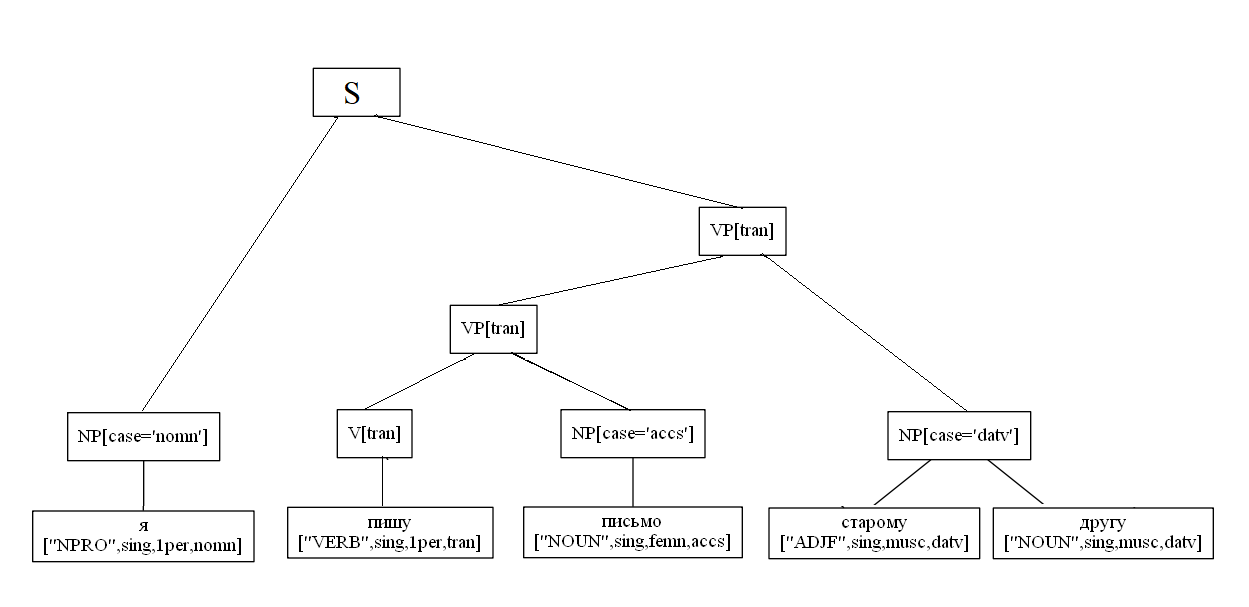
一个由两部分组成的句子的解析示例:
import analyzer parser = analyzer.Parser() sent = " , ." t = parser.parse(sent) t[0].display() S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres'] NP[case='datv'] ['NOUN', 'sing', 'datv'] S NP[case='nomn'] ['NOUN', 'sing', 'femn', 'nomn'] VP[tran] PP PREP ['PREP'] NP[case='ablt'] ['NOUN', 'sing', 'femn', 'ablt'] VP[tran] ['VERB', 'sing', '3per', 'tran', 'pres']
问题所在
自然语言是模棱两可的,它的理解取决于许多因素-语言的语法结构特征,民族文化,说话者等。 我们列出了机器语言处理的主要问题。
- 照应的披露。 活着的人会根据常识和上下文理解照应,但是对于计算机而言,这显然并不总是那么容易。
- 同义是语言单元的声音和拼写中的巧合,其含义彼此无关。 一种解决方案是概率方法。 在“ 我非常了解”这句话中,“ this ”是代词而不是质点的可能性会更大。 这种方法需要足够大的外壳。
- 单词的自由顺序导致句子的解释可能不明确。 例如,“ 存在决定意识 ”-什么决定什么? 在俄语中,自由词顺序由已发展的形态,服务词和标点符号来补偿,但是在大多数情况下,对于计算机,这带来了另一个问题。
- 并非所有人都能正确书写。 在网上,人们倾向于使用缩写,新词,省略号和其他可能与文学规范相抵触的东西。 因此,并非总是可以使用无上下文语法和字典。
结论
该项目
可供使用和编辑。 它包含分析器本身,语法分析树,俄语语法和俄语语法以及OpenCorpora词典中没有的小小的复合联合和谓词词典。 目前,对于较长的复杂句子,解析器可以找到3棵或更多棵树,以解决此问题,对语法进行了更改,并且还计划使用概率方法。